 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePANC: Prior-Aware Normalized Cut for Object Segmentation
Feb 06, 2026Fully unsupervised segmentation pipelines naively seek the most salient object, should this be present. As a result, most of the methods reported in the literature deliver non-deterministic partitions that are sensitive to initialization, seed order, and threshold heuristics. We propose PANC, a weakly supervised spectral segmentation framework that uses a minimal set of annotated visual tokens to produce stable, controllable, and reproducible object masks. From the TokenCut approach, we augment the token-token affinity graph with a handful of priors coupled to anchor nodes. By manipulating the graph topology, we bias the spectral eigenspace toward partitions that are consistent with the annotations. Our approach preserves the global grouping enforced by dense self-supervised visual features, trading annotated tokens for significant gains in reproducibility, user control, and segmentation quality. Using 5 to 30 annotations per dataset, our training-free method achieves state-of-the-art performance among weakly and unsupervised approaches on standard benchmarks (e.g., DUTS-TE, ECSSD, MS COCO). Contrarily, it excels in domains where dense labels are costly or intra-class differences are subtle. We report strong and reliable results on homogeneous, fine-grained, and texture-limited domains, achieving 96.8% (+14.43% over SotA), 78.0% (+0.2%), and 78.8% (+0.37%) average mean intersection-over-union (mIoU) on CrackForest (CFD), CUB-200-2011, and HAM10000 datasets, respectively. For multi-object benchmarks, the framework showcases explicit, user-controllable semantic segmentation.
Open-Source System for Multilingual Translation and Cloned Speech Synthesis
Jul 03, 2025We present an open-source system designed for multilingual translation and speech regeneration, addressing challenges in communication and accessibility across diverse linguistic contexts. The system integrates Whisper for speech recognition with Voice Activity Detection (VAD) to identify speaking intervals, followed by a pipeline of Large Language Models (LLMs). For multilingual applications, the first LLM segments speech into coherent, complete sentences, which a second LLM then translates. For speech regeneration, the system uses a text-to-speech (TTS) module with voice cloning capabilities to replicate the original speaker's voice, maintaining naturalness and speaker identity. The system's open-source components can operate locally or via APIs, offering cost-effective deployment across various use cases. These include real-time multilingual translation in Zoom sessions, speech regeneration for public broadcasts, and Bluetooth-enabled multilingual playback through personal devices. By preserving the speaker's voice, the system ensures a seamless and immersive experience, whether translating or regenerating speech. This open-source project is shared with the community to foster innovation and accessibility. We provide a detailed system performance analysis, including latency and word accuracy, demonstrating its potential to enable inclusive, adaptable communication solutions in real-world multilingual scenarios.
Image Denoising with Kernels based on Natural Image Relations
Jan 31, 2016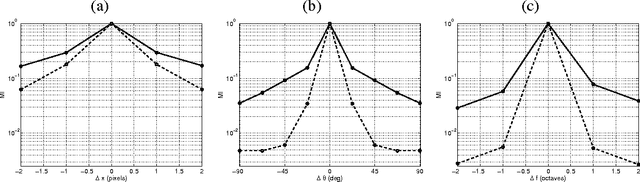
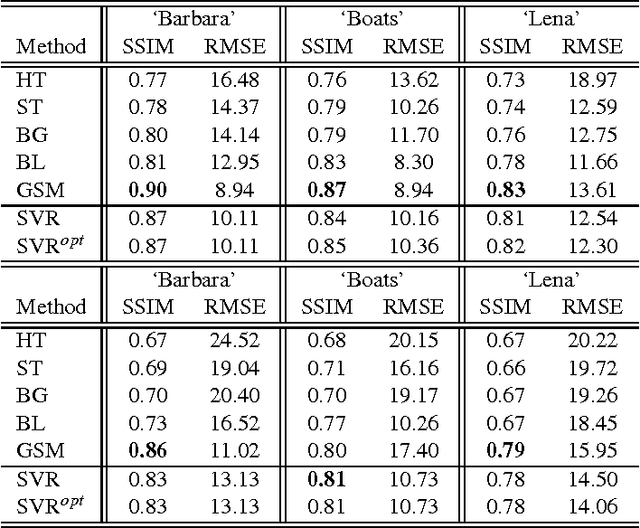
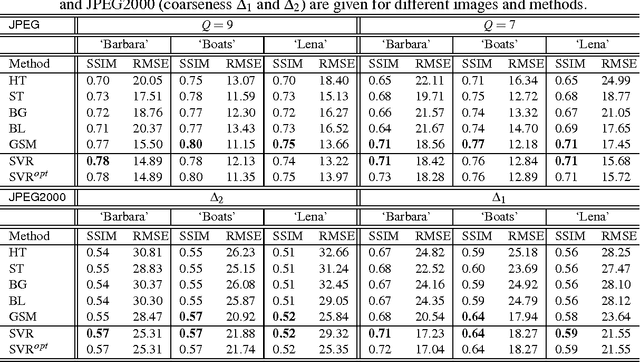
A successful class of image denoising methods is based on Bayesian approaches working in wavelet representations. However, analytical estimates can be obtained only for particular combinations of analytical models of signal and noise, thus precluding its straightforward extension to deal with other arbitrary noise sources. In this paper, we propose an alternative non-explicit way to take into account the relations among natural image wavelet coefficients for denoising: we use support vector regression (SVR) in the wavelet domain to enforce these relations in the estimated signal. Since relations among the coefficients are specific to the signal, the regularization property of SVR is exploited to remove the noise, which does not share this feature. The specific signal relations are encoded in an anisotropic kernel obtained from mutual information measures computed on a representative image database. Training considers minimizing the Kullback-Leibler divergence (KLD) between the estimated and actual probability functions of signal and noise in order to enforce similarity. Due to its non-parametric nature, the method can eventually cope with different noise sources without the need of an explicit re-formulation, as it is strictly necessary under parametric Bayesian formalisms. Results under several noise levels and noise sources show that: (1) the proposed method outperforms conventional wavelet methods that assume coefficient independence, (2) it is similar to state-of-the-art methods that do explicitly include these relations when the noise source is Gaussian, and (3) it gives better numerical and visual performance when more complex, realistic noise sources are considered. Therefore, the proposed machine learning approach can be seen as a more flexible (model-free) alternative to the explicit description of wavelet coefficient relations for image denoising.
On the Suitable Domain for SVM Training in Image Coding
Oct 18, 2013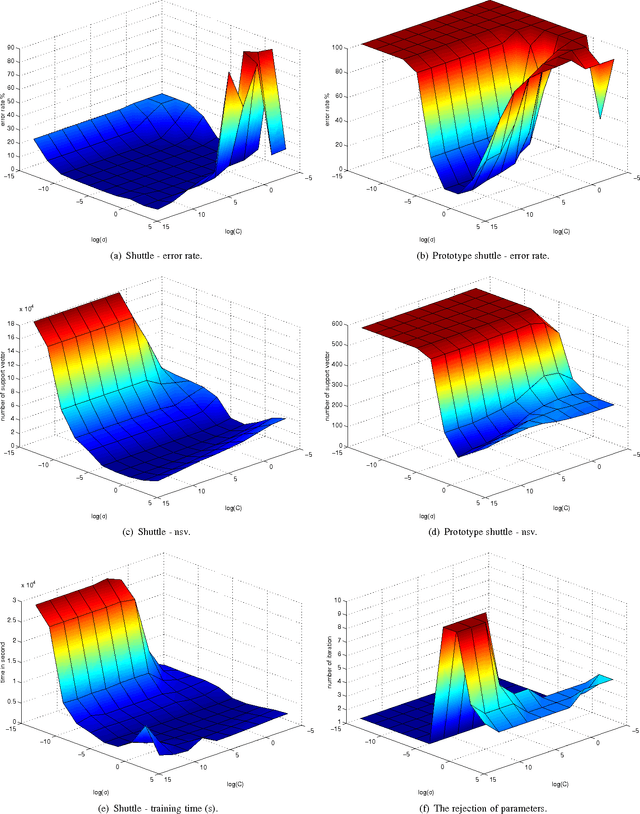
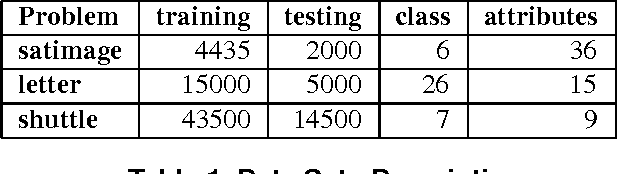
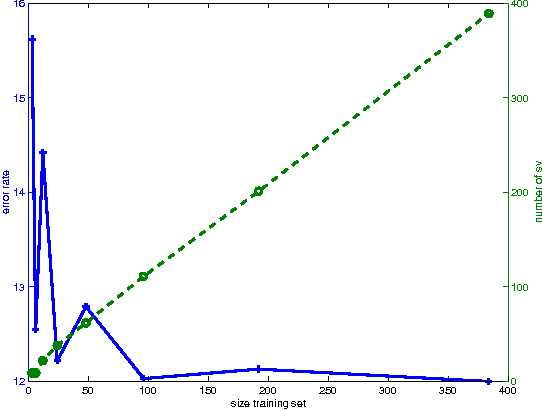

Conventional SVM-based image coding methods are founded on independently restricting the distortion in every image coefficient at some particular image representation. Geometrically, this implies allowing arbitrary signal distortions in an $n$-dimensional rectangle defined by the $\varepsilon$-insensitivity zone in each dimension of the selected image representation domain. Unfortunately, not every image representation domain is well-suited for such a simple, scalar-wise, approach because statistical and/or perceptual interactions between the coefficients may exist. These interactions imply that scalar approaches may induce distortions that do not follow the image statistics and/or are perceptually annoying. Taking into account these relations would imply using non-rectangular $\varepsilon$-insensitivity regions (allowing coupled distortions in different coefficients), which is beyond the conventional SVM formulation. In this paper, we report a condition on the suitable domain for developing efficient SVM image coding schemes. We analytically demonstrate that no linear domain fulfills this condition because of the statistical and perceptual inter-coefficient relations that exist in these domains. This theoretical result is experimentally confirmed by comparing SVM learning in previously reported linear domains and in a recently proposed non-linear perceptual domain that simultaneously reduces the statistical and perceptual relations (so it is closer to fulfilling the proposed condition). These results highlight the relevance of an appropriate choice of the image representation before SVM learning.