 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A fusion method for multi-valued data
Jan 25, 2021
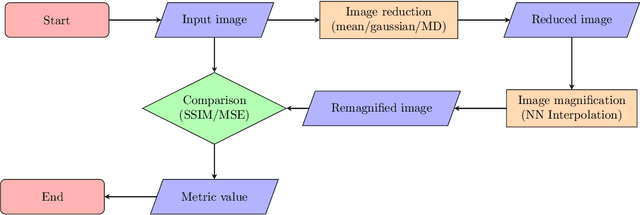
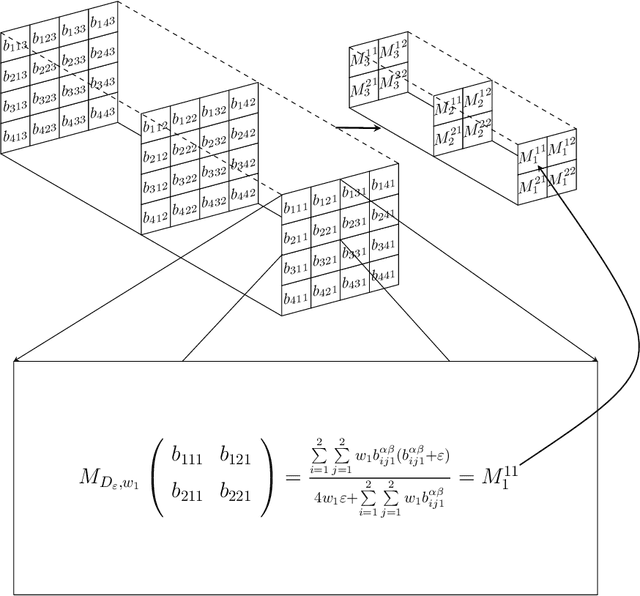
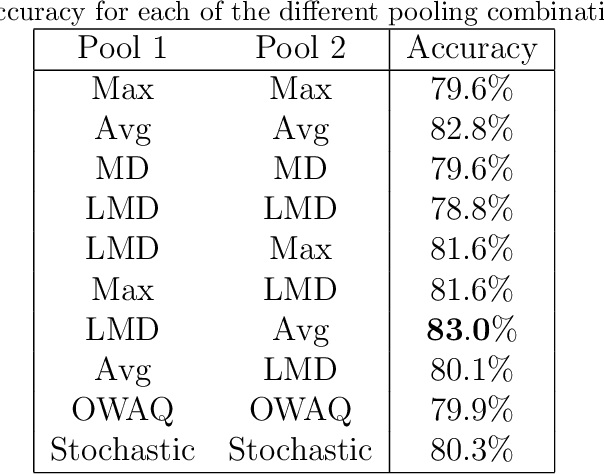
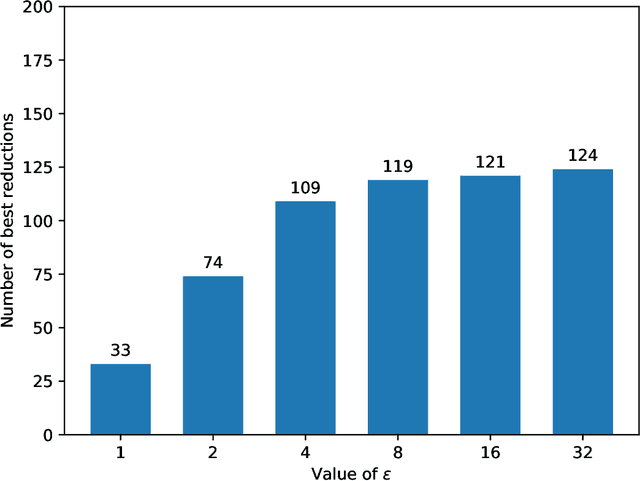
In this paper we propose an extension of the notion of deviation-based aggregation function tailored to aggregate multidimensional data. Our objective is both to improve the results obtained by other methods that try to select the best aggregation function for a particular set of data, such as penalty functions, and to reduce the temporal complexity required by such approaches. We discuss how this notion can be defined and present three illustrative examples of the applicability of our new proposal in areas where temporal constraints can be strict, such as image processing, deep learning and decision making, obtaining favourable results in the process.
Characterization of Covid-19 Dataset using Complex Networks and Image Processing
Sep 24, 2020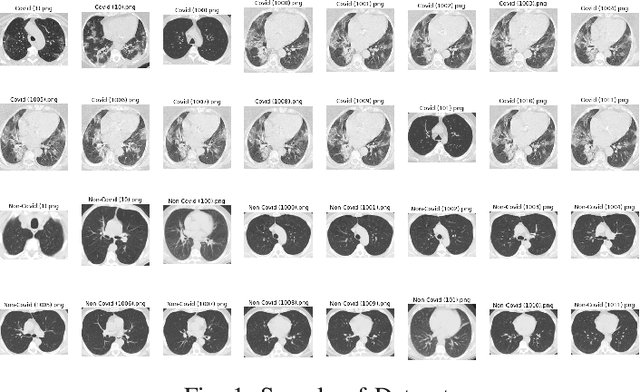
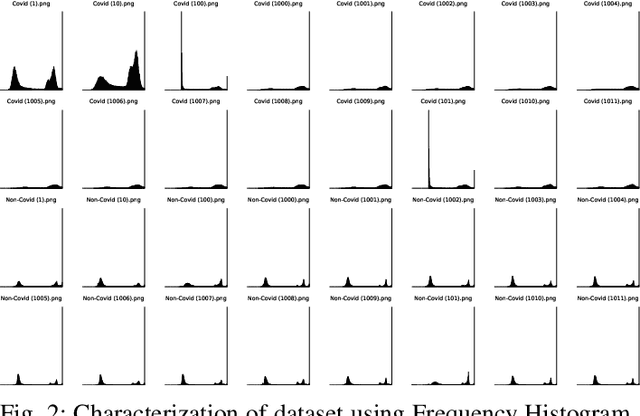
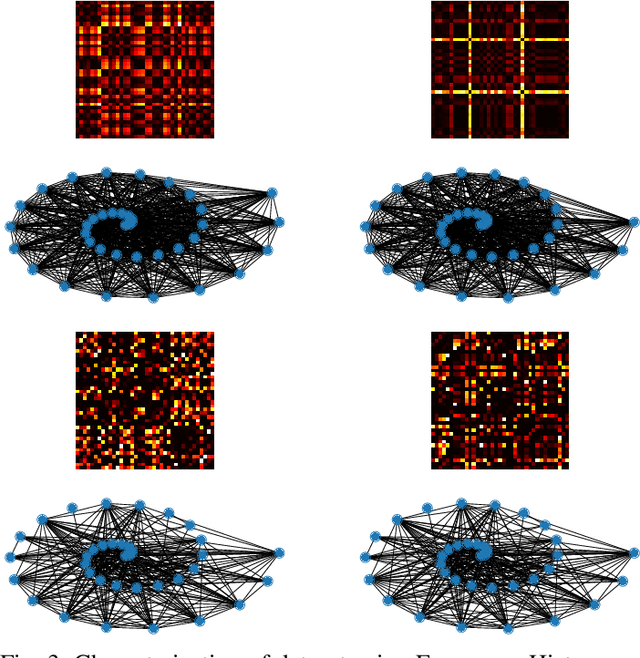

This paper aims to explore the structure of pattern behind covid-19 dataset. The dataset includes medical images with positive and negative cases. A sample of 100 sample is chosen, 50 per each class. An histogram frequency is calculated to get features using statistical measurements, besides a feature extraction using Grey Level Co-Occurrence Matrix (GLCM). Using both features are build Complex Networks respectively to analyze the adjacency matrices and check the presence of patterns. Initial experiments introduces the evidence of hidden patterns in the dataset for each class, which are visible using Complex Networks representation.
A Front-End for Dense Monocular SLAM using a Learned Outlier Mask Prior
Apr 01, 2021


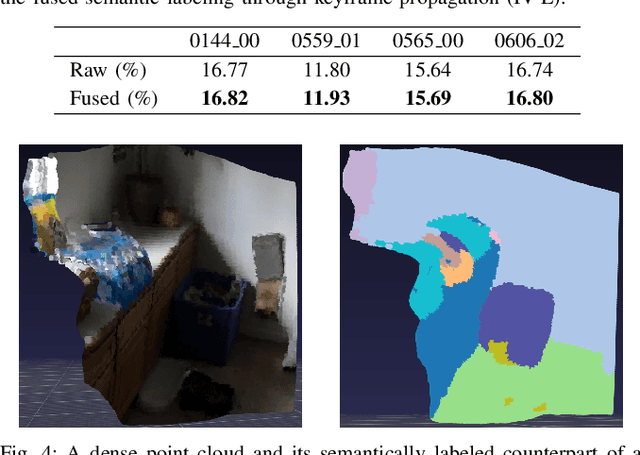
Recent achievements in depth prediction from a single RGB image have powered the new research area of combining convolutional neural networks (CNNs) with classical simultaneous localization and mapping (SLAM) algorithms. The depth prediction from a CNN provides a reasonable initial point in the optimization process in the traditional SLAM algorithms, while the SLAM algorithms further improve the CNN prediction online. However, most of the current CNN-SLAM approaches have only taken advantage of the depth prediction but not yet other products from a CNN. In this work, we explore the use of the outlier mask, a by-product from unsupervised learning of depth from video, as a prior in a classical probability model for depth estimate fusion to step up the outlier-resistant tracking performance of a SLAM front-end. On the other hand, some of the previous CNN-SLAM work builds on feature-based sparse SLAM methods, wasting the per-pixel dense prediction from a CNN. In contrast to these sparse methods, we devise a dense CNN-assisted SLAM front-end that is implementable with TensorFlow and evaluate it on both indoor and outdoor datasets.
Attribute Prototype Network for Zero-Shot Learning
Aug 20, 2020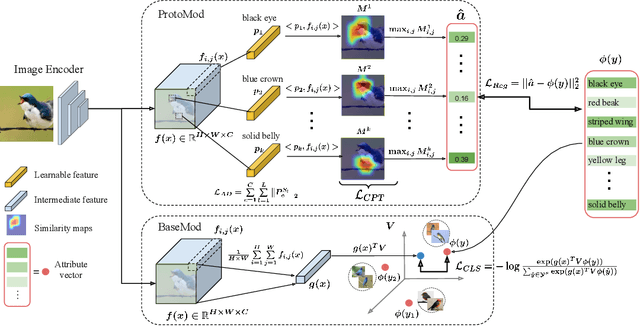
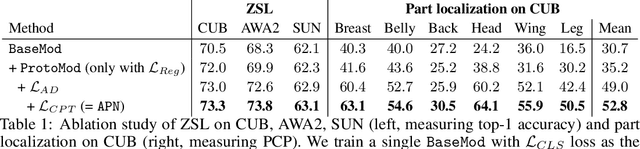
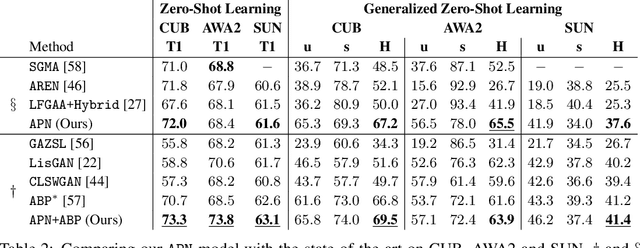
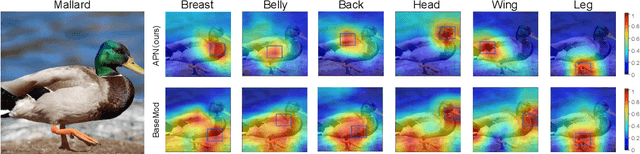
From the beginning of zero-shot learning research, visual attributes have been shown to play an important role. In order to better transfer attribute-based knowledge from known to unknown classes, we argue that an image representation with integrated attribute localization ability would be beneficial for zero-shot learning. To this end, we propose a novel zero-shot representation learning framework that jointly learns discriminative global and local features using only class-level attributes. While a visual-semantic embedding layer learns global features, local features are learned through an attribute prototype network that simultaneously regresses and decorrelates attributes from intermediate features. We show that our locality augmented image representations achieve a new state-of-the-art on three zero-shot learning benchmarks. As an additional benefit, our model points to the visual evidence of the attributes in an image, e.g. for the CUB dataset, confirming the improved attribute localization ability of our image representation. The code will be publicaly available at https://wenjiaxu.github.io/APN-ZSL/.
Weakly- and Self-Supervised Learning for Content-Aware Deep Image Retargeting
Aug 09, 2017

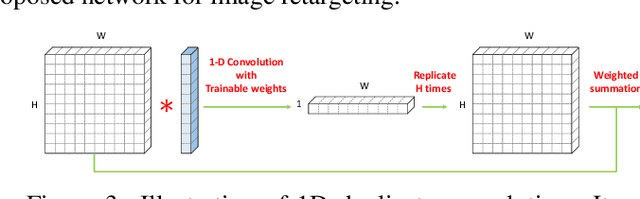

This paper proposes a weakly- and self-supervised deep convolutional neural network (WSSDCNN) for content-aware image retargeting. Our network takes a source image and a target aspect ratio, and then directly outputs a retargeted image. Retargeting is performed through a shift map, which is a pixel-wise mapping from the source to the target grid. Our method implicitly learns an attention map, which leads to a content-aware shift map for image retargeting. As a result, discriminative parts in an image are preserved, while background regions are adjusted seamlessly. In the training phase, pairs of an image and its image-level annotation are used to compute content and structure losses. We demonstrate the effectiveness of our proposed method for a retargeting application with insightful analyses.
Towards creativity characterization of generative models via group-based subset scanning
Apr 01, 2021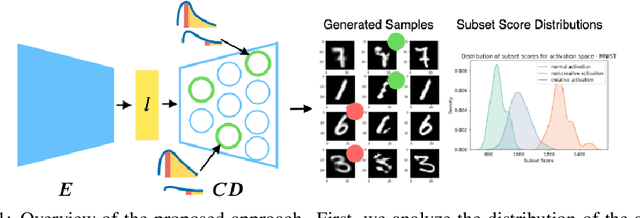
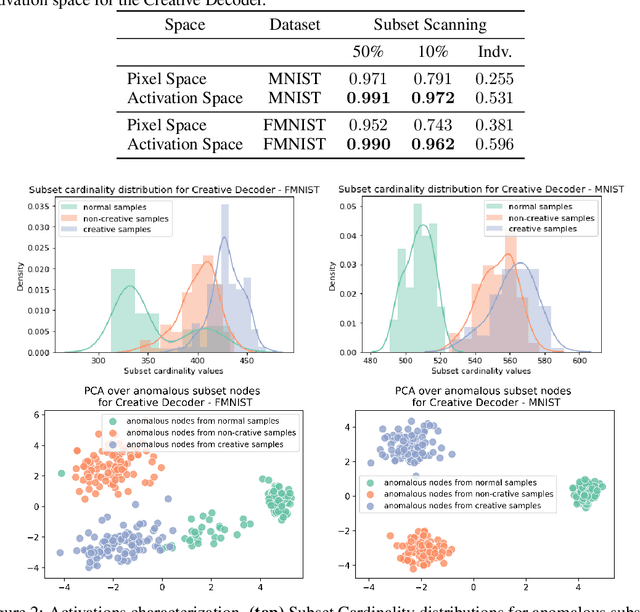
Deep generative models, such as Variational Autoencoders (VAEs), have been employed widely in computational creativity research. However, such models discourage out-of-distribution generation to avoid spurious sample generation, limiting their creativity. Thus, incorporating research on human creativity into generative deep learning techniques presents an opportunity to make their outputs more compelling and human-like. As we see the emergence of generative models directed to creativity research, a need for machine learning-based surrogate metrics to characterize creative output from these models is imperative. We propose group-based subset scanning to quantify, detect, and characterize creative processes by detecting a subset of anomalous node-activations in the hidden layers of generative models. Our experiments on original, typically decoded, and "creatively decoded" (Das et al 2020) image datasets reveal that the proposed subset scores distribution is more useful for detecting creative processes in the activation space rather than the pixel space. Further, we found that creative samples generate larger subsets of anomalies than normal or non-creative samples across datasets. The node activations highlighted during the creative decoding process are different from those responsible for normal sample generation.
Graph-based Thermal-Inertial SLAM with Probabilistic Neural Networks
Apr 18, 2021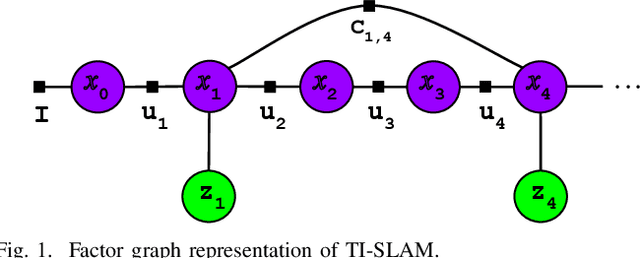
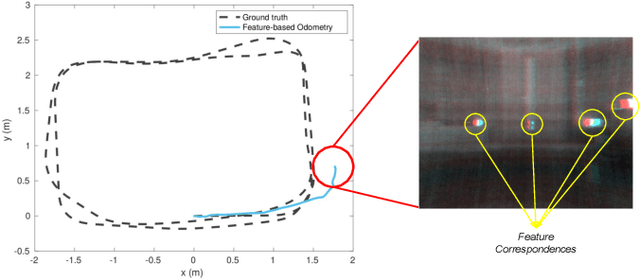
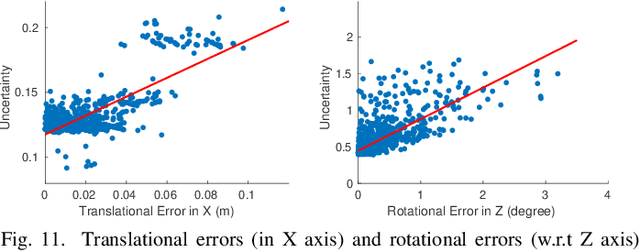
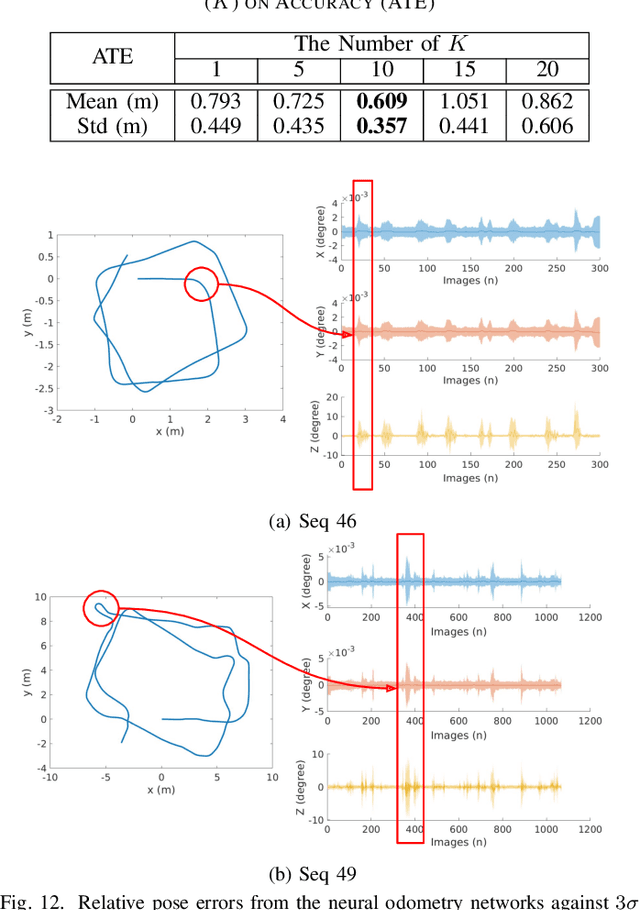
Simultaneous Localization and Mapping (SLAM) system typically employ vision-based sensors to observe the surrounding environment. However, the performance of such systems highly depends on the ambient illumination conditions. In scenarios with adverse visibility or in the presence of airborne particulates (e.g. smoke, dust, etc.), alternative modalities such as those based on thermal imaging and inertial sensors are more promising. In this paper, we propose the first complete thermal-inertial SLAM system which combines neural abstraction in the SLAM front end with robust pose graph optimization in the SLAM back end. We model the sensor abstraction in the front end by employing probabilistic deep learning parameterized by Mixture Density Networks (MDN). Our key strategies to successfully model this encoding from thermal imagery are the usage of normalized 14-bit radiometric data, the incorporation of hallucinated visual (RGB) features, and the inclusion of feature selection to estimate the MDN parameters. To enable a full SLAM system, we also design an efficient global image descriptor which is able to detect loop closures from thermal embedding vectors. We performed extensive experiments and analysis using three datasets, namely self-collected ground robot and handheld data taken in indoor environment, and one public dataset (SubT-tunnel) collected in underground tunnel. Finally, we demonstrate that an accurate thermal-inertial SLAM system can be realized in conditions of both benign and adverse visibility.
Boundary-weighted Domain Adaptive Neural Network for Prostate MR Image Segmentation
Feb 21, 2019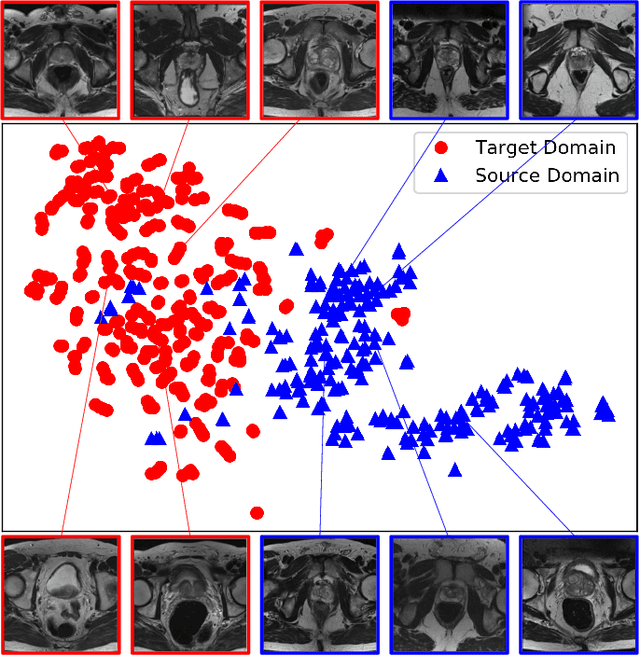
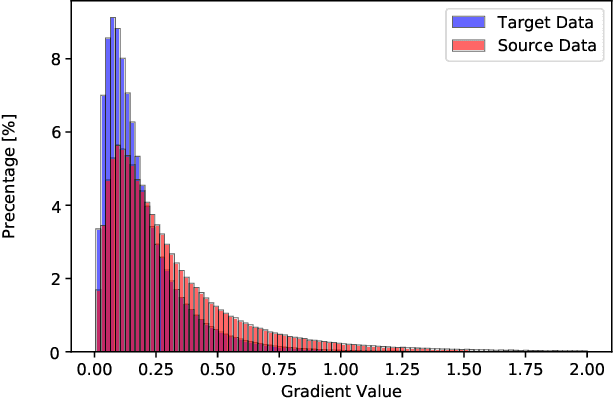
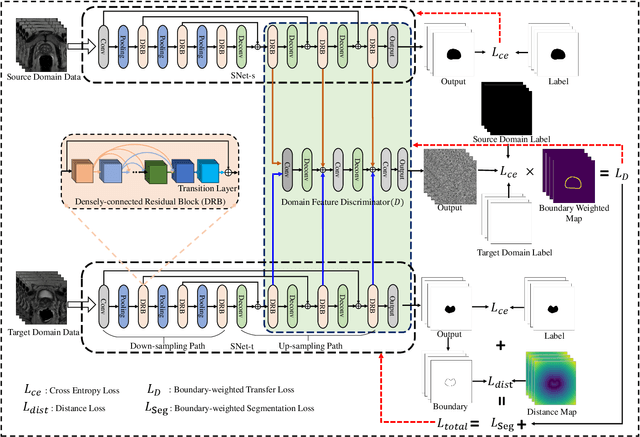
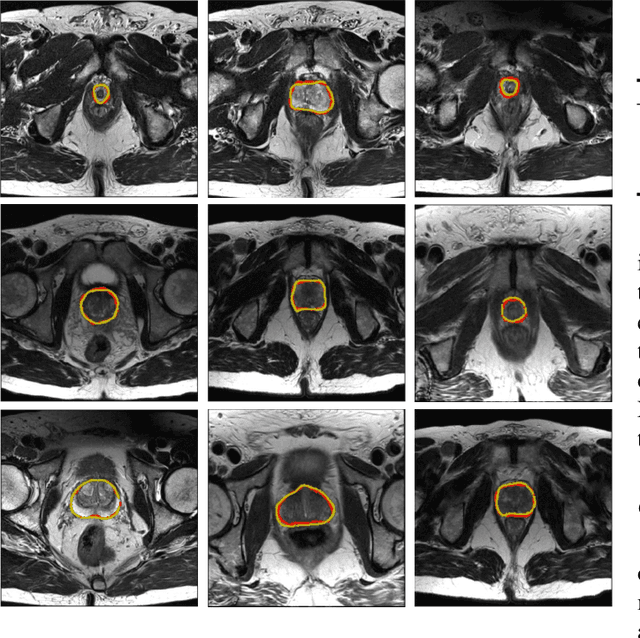
Accurate segmentation of the prostate from magnetic resonance (MR) images provides useful information for prostate cancer diagnosis and treatment. However, automated prostate segmentation from 3D MR images still faces several challenges. For instance, a lack of clear edge between the prostate and other anatomical structures makes it challenging to accurately extract the boundaries. The complex background texture and large variation in size, shape and intensity distribution of the prostate itself make segmentation even further complicated. With deep learning, especially convolutional neural networks (CNNs), emerging as commonly used methods for medical image segmentation, the difficulty in obtaining large number of annotated medical images for training CNNs has become much more pronounced that ever before. Since large-scale dataset is one of the critical components for the success of deep learning, lack of sufficient training data makes it difficult to fully train complex CNNs. To tackle the above challenges, in this paper, we propose a boundary-weighted domain adaptive neural network (BOWDA-Net). To make the network more sensitive to the boundaries during segmentation, a boundary-weighted segmentation loss (BWL) is proposed. Furthermore, an advanced boundary-weighted transfer leaning approach is introduced to address the problem of small medical imaging datasets. We evaluate our proposed model on the publicly available MICCAI 2012 Prostate MR Image Segmentation (PROMISE12) challenge dataset. Our experimental results demonstrate that the proposed model is more sensitive to boundary information and outperformed other state-of-the-art methods.
Towards an Understanding of Neural Networks in Natural-Image Spaces
Jan 27, 2018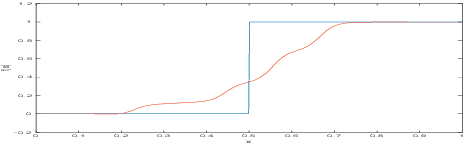
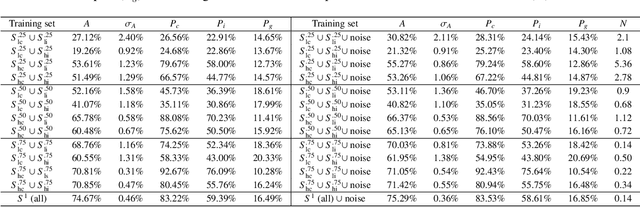
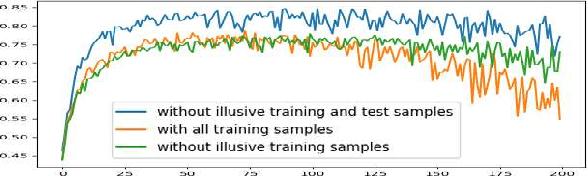
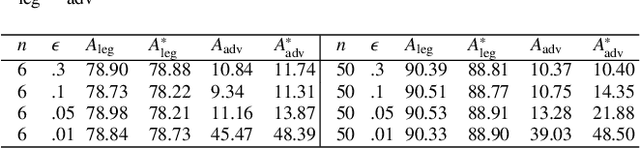
Two major uncertainties, dataset bias and perturbation, prevail in state-of-the-art AI algorithms with deep neural networks. In this paper, we present an intuitive explanation for these issues as well as an interpretation of the performance of deep networks in a natural-image space. The explanation consists of two parts: the philosophy of neural networks and a hypothetic model of natural-image spaces. Following the explanation, we slightly improve the accuracy of a CIFAR-10 classifier by introducing an additional "random-noise" category during training. We hope this paper will stimulate discussion in the community regarding the topological and geometric properties of natural-image spaces to which deep networks are applied.
Unsupervised Learning of Monocular Depth and Ego-Motion Using Multiple Masks
Apr 01, 2021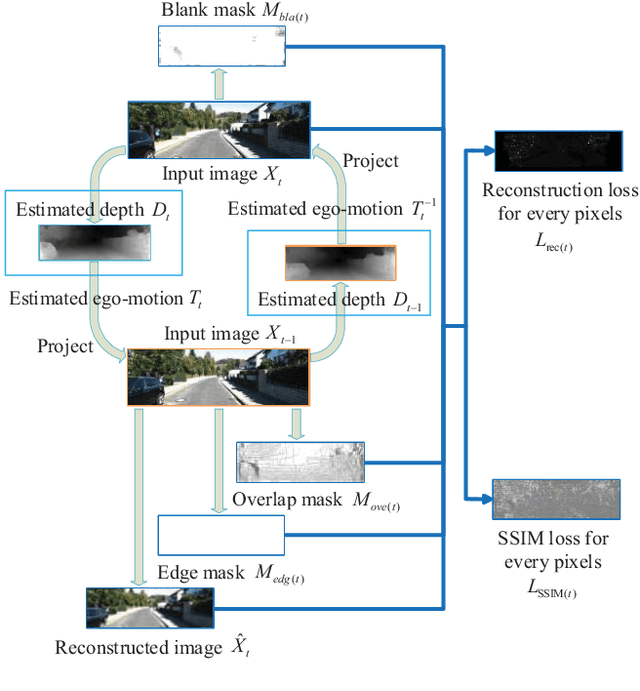
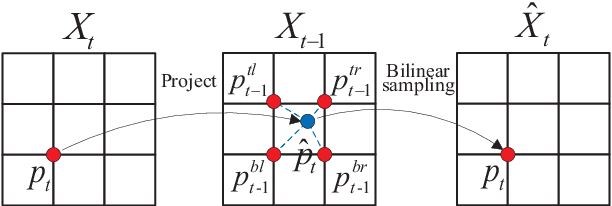
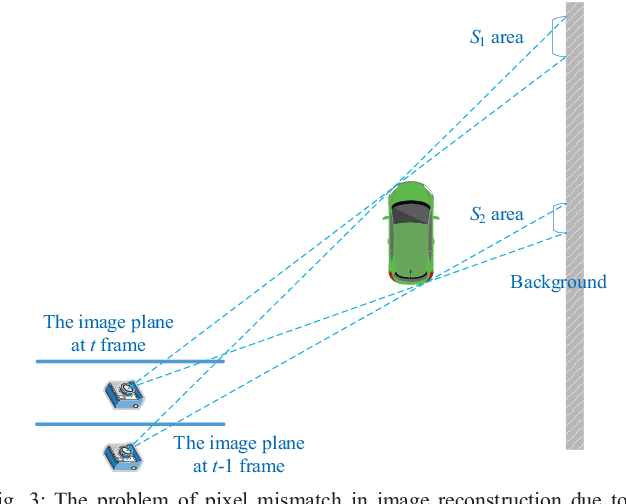
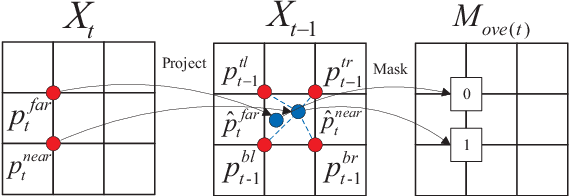
A new unsupervised learning method of depth and ego-motion using multiple masks from monocular video is proposed in this paper. The depth estimation network and the ego-motion estimation network are trained according to the constraints of depth and ego-motion without truth values. The main contribution of our method is to carefully consider the occlusion of the pixels generated when the adjacent frames are projected to each other, and the blank problem generated in the projection target imaging plane. Two fine masks are designed to solve most of the image pixel mismatch caused by the movement of the camera. In addition, some relatively rare circumstances are considered, and repeated masking is proposed. To some extent, the method is to use a geometric relationship to filter the mismatched pixels for training, making unsupervised learning more efficient and accurate. The experiments on KITTI dataset show our method achieves good performance in terms of depth and ego-motion. The generalization capability of our method is demonstrated by training on the low-quality uncalibrated bike video dataset and evaluating on KITTI dataset, and the results are still good.
* Accepted to ICRA 2019