 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAligning Learning and Endogenous Decision-Making
Jul 01, 2025Many of the observations we make are biased by our decisions. For instance, the demand of items is impacted by the prices set, and online checkout choices are influenced by the assortments presented. The challenge in decision-making under this setting is the lack of counterfactual information, and the need to learn it instead. We introduce an end-to-end method under endogenous uncertainty to train ML models to be aware of their downstream, enabling their effective use in the decision-making stage. We further introduce a robust optimization variant that accounts for uncertainty in ML models -- specifically by constructing uncertainty sets over the space of ML models and optimizing actions to protect against worst-case predictions. We prove guarantees that this robust approach can capture near-optimal decisions with high probability as a function of data. Besides this, we also introduce a new class of two-stage stochastic optimization problems to the end-to-end learning framework that can now be addressed through our framework. Here, the first stage is an information-gathering problem to decide which random variable to poll and gain information about before making a second-stage decision based off of it. We present several computational experiments for pricing and inventory assortment/recommendation problems. We compare against existing methods in online learning/bandits/offline reinforcement learning and show our approach has consistent improved performance over these. Just as in the endogenous setting, the model's prediction also depends on the first-stage decision made. While this decision does not affect the random variable in this setting, it does affect the correct point forecast that should be made.
Efficient End-to-End Learning for Decision-Making: A Meta-Optimization Approach
May 16, 2025End-to-end learning has become a widely applicable and studied problem in training predictive ML models to be aware of their impact on downstream decision-making tasks. These end-to-end models often outperform traditional methods that separate training from the optimization and only myopically focus on prediction error. However, the computational complexity of end-to-end frameworks poses a significant challenge, particularly for large-scale problems. While training an ML model using gradient descent, each time we need to compute a gradient we must solve an expensive optimization problem. We present a meta-optimization method that learns efficient algorithms to approximate optimization problems, dramatically reducing computational overhead of solving the decision problem in general, an aspect we leverage in the training within the end-to-end framework. Our approach introduces a neural network architecture that near-optimally solves optimization problems while ensuring feasibility constraints through alternate projections. We prove exponential convergence, approximation guarantees, and generalization bounds for our learning method. This method offers superior computational efficiency, producing high-quality approximations faster and scaling better with problem size compared to existing techniques. Our approach applies to a wide range of optimization problems including deterministic, single-stage as well as two-stage stochastic optimization problems. We illustrate how our proposed method applies to (1) an electricity generation problem using real data from an electricity routing company coordinating the movement of electricity throughout 13 states, (2) a shortest path problem with a computer vision task of predicting edge costs from terrain maps, (3) a two-stage multi-warehouse cross-fulfillment newsvendor problem, as well as a variety of other newsvendor-like problems.
CoRe: Coherency Regularization for Hierarchical Time Series
Feb 21, 2025Hierarchical time series forecasting presents unique challenges, particularly when dealing with noisy data that may not perfectly adhere to aggregation constraints. This paper introduces a novel approach to soft coherency in hierarchical time series forecasting using neural networks. We present a network coherency regularization method, which we denote as CoRe (Coherency Regularization), a technique that trains neural networks to produce forecasts that are inherently coherent across hierarchies, without strictly enforcing aggregation constraints. Our method offers several key advantages. (1) It provides theoretical guarantees on the coherency of forecasts, even for out-of-sample data. (2) It is adaptable to scenarios where data may contain errors or missing values, making it more robust than strict coherency methods. (3) It can be easily integrated into existing neural network architectures for time series forecasting. We demonstrate the effectiveness of our approach on multiple benchmark datasets, comparing it against state-of-the-art methods in both coherent and noisy data scenarios. Additionally, our method can be used within existing generative probabilistic forecasting frameworks to generate coherent probabilistic forecasts. Our results show improved generalization and forecast accuracy, particularly in the presence of data inconsistencies. On a variety of datasets, including both strictly hierarchically coherent and noisy data, our training method has either equal or better accuracy at all levels of the hierarchy while being strictly more coherent out-of-sample than existing soft-coherency methods.
Inter-Series Transformer: Attending to Products in Time Series Forecasting
Aug 07, 2024Time series forecasting is an important task in many fields ranging from supply chain management to weather forecasting. Recently, Transformer neural network architectures have shown promising results in forecasting on common time series benchmark datasets. However, application to supply chain demand forecasting, which can have challenging characteristics such as sparsity and cross-series effects, has been limited. In this work, we explore the application of Transformer-based models to supply chain demand forecasting. In particular, we develop a new Transformer-based forecasting approach using a shared, multi-task per-time series network with an initial component applying attention across time series, to capture interactions and help address sparsity. We provide a case study applying our approach to successfully improve demand prediction for a medical device manufacturing company. To further validate our approach, we also apply it to public demand forecasting datasets as well and demonstrate competitive to superior performance compared to a variety of baseline and state-of-the-art forecast methods across the private and public datasets.
A Survey of Classical And Quantum Sequence Models
Dec 15, 2023Our primary objective is to conduct a brief survey of various classical and quantum neural net sequence models, which includes self-attention and recurrent neural networks, with a focus on recent quantum approaches proposed to work with near-term quantum devices, while exploring some basic enhancements for these quantum models. We re-implement a key representative set of these existing methods, adapting an image classification approach using quantum self-attention to create a quantum hybrid transformer that works for text and image classification, and applying quantum self-attention and quantum recurrent neural networks to natural language processing tasks. We also explore different encoding techniques and introduce positional encoding into quantum self-attention neural networks leading to improved accuracy and faster convergence in text and image classification experiments. This paper also performs a comparative analysis of classical self-attention models and their quantum counterparts, helping shed light on the differences in these models and their performance.
An Optimistic-Robust Approach for Dynamic Positioning of Omnichannel Inventories
Oct 17, 2023



We introduce a new class of data-driven and distribution-free optimistic-robust bimodal inventory optimization (BIO) strategy to effectively allocate inventory across a retail chain to meet time-varying, uncertain omnichannel demand. While prior Robust optimization (RO) methods emphasize the downside, i.e., worst-case adversarial demand, BIO also considers the upside to remain resilient like RO while also reaping the rewards of improved average-case performance by overcoming the presence of endogenous outliers. This bimodal strategy is particularly valuable for balancing the tradeoff between lost sales at the store and the costs of cross-channel e-commerce fulfillment, which is at the core of our inventory optimization model. These factors are asymmetric due to the heterogenous behavior of the channels, with a bias towards the former in terms of lost-sales cost and a dependence on network effects for the latter. We provide structural insights about the BIO solution and how it can be tuned to achieve a preferred tradeoff between robustness and the average-case. Our experiments show that significant benefits can be achieved by rethinking traditional approaches to inventory management, which are siloed by channel and location. Using a real-world dataset from a large American omnichannel retail chain, a business value assessment during a peak period indicates over a 15% profitability gain for BIO over RO and other baselines while also preserving the (practical) worst case performance.
Hierarchy-guided Model Selection for Time Series Forecasting
Nov 28, 2022



Generalizability of time series forecasting models depends on the quality of model selection. Temporal cross validation (TCV) is a standard technique to perform model selection in forecasting tasks. TCV sequentially partitions the training time series into train and validation windows, and performs hyperparameter optmization (HPO) of the forecast model to select the model with the best validation performance. Model selection with TCV often leads to poor test performance when the test data distribution differs from that of the validation data. We propose a novel model selection method, H-Pro that exploits the data hierarchy often associated with a time series dataset. Generally, the aggregated data at the higher levels of the hierarchy show better predictability and more consistency compared to the bottom-level data which is more sparse and (sometimes) intermittent. H-Pro performs the HPO of the lowest-level student model based on the test proxy forecasts obtained from a set of teacher models at higher levels in the hierarchy. The consistency of the teachers' proxy forecasts help select better student models at the lowest-level. We perform extensive empirical studies on multiple datasets to validate the efficacy of the proposed method. H-Pro along with off-the-shelf forecasting models outperform existing state-of-the-art forecasting methods including the winning models of the M5 point-forecasting competition.
Towards Creativity Characterization of Generative Models via Group-based Subset Scanning
Mar 03, 2022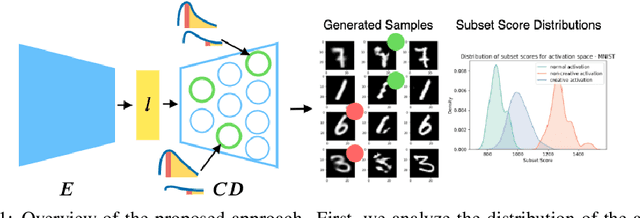
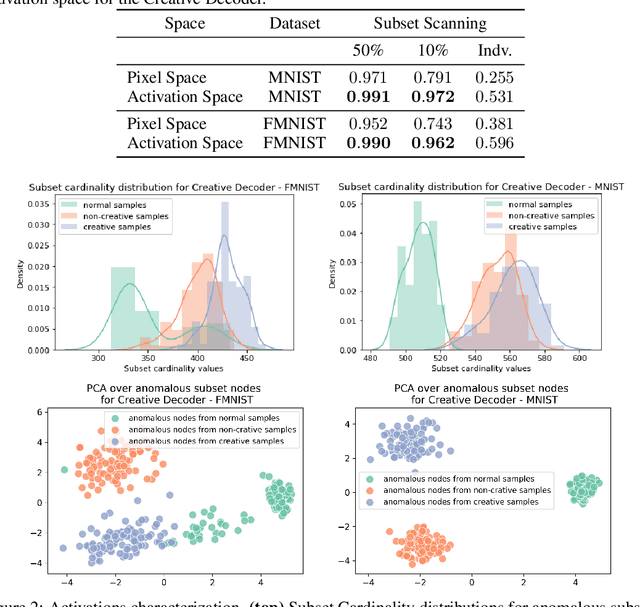
Deep generative models, such as Variational Autoencoders (VAEs) and Generative Adversarial Networks (GANs), have been employed widely in computational creativity research. However, such models discourage out-of-distribution generation to avoid spurious sample generation, thereby limiting their creativity. Thus, incorporating research on human creativity into generative deep learning techniques presents an opportunity to make their outputs more compelling and human-like. As we see the emergence of generative models directed toward creativity research, a need for machine learning-based surrogate metrics to characterize creative output from these models is imperative. We propose group-based subset scanning to identify, quantify, and characterize creative processes by detecting a subset of anomalous node-activations in the hidden layers of the generative models. Our experiments on the standard image benchmarks, and their "creatively generated" variants, reveal that the proposed subset scores distribution is more useful for detecting creative processes in the activation space rather than the pixel space. Further, we found that creative samples generate larger subsets of anomalies than normal or non-creative samples across datasets. The node activations highlighted during the creative decoding process are different from those responsible for the normal sample generation. Lastly, we assess if the images from the subsets selected by our method were also found creative by human evaluators, presenting a link between creativity perception in humans and node activations within deep neural nets.
Math Programming based Reinforcement Learning for Multi-Echelon Inventory Management
Dec 04, 2021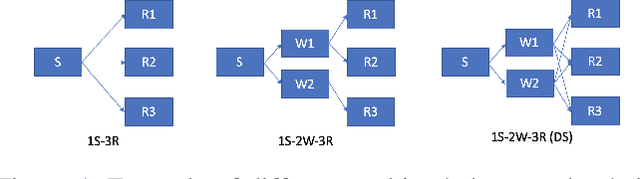
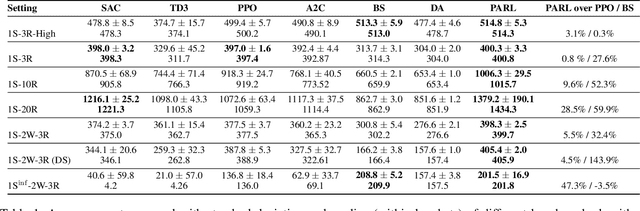
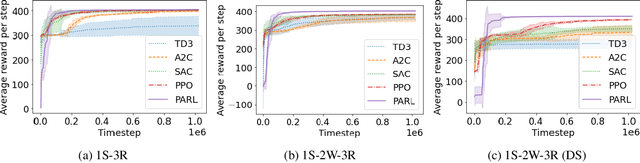

Reinforcement learning has lead to considerable break-throughs in diverse areas such as robotics, games and many others. But the application to RL in complex real-world decision making problems remains limited. Many problems in operations management (inventory and revenue management, for example) are characterized by large action spaces and stochastic system dynamics. These characteristics make the problem considerably harder to solve for existing RL methods that rely on enumeration techniques to solve per step action problems. To resolve these issues, we develop Programmable Actor Reinforcement Learning (PARL), a policy iteration method that uses techniques from integer programming and sample average approximation. Analytically, we show that the for a given critic, the learned policy in each iteration converges to the optimal policy as the underlying samples of the uncertainty go to infinity. Practically, we show that a properly selected discretization of the underlying uncertain distribution can yield near optimal actor policy even with very few samples from the underlying uncertainty. We then apply our algorithm to real-world inventory management problems with complex supply chain structures and show that PARL outperforms state-of-the-art RL and inventory optimization methods in these settings. We find that PARL outperforms commonly used base stock heuristic by 44.7% and the best performing RL method by up to 12.1% on average across different supply chain environments.
Learning to shortcut and shortlist order fulfillment deciding
Oct 04, 2021

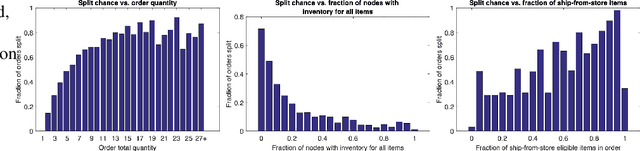
With the increase of order fulfillment options and business objectives taken into consideration in the deciding process, order fulfillment deciding is becoming more and more complex. For example, with the advent of ship from store retailers now have many more fulfillment nodes to consider, and it is now common to take into account many and varied business goals in making fulfillment decisions. With increasing complexity, efficiency of the deciding process can become a real concern. Finding the optimal fulfillment assignments among all possible ones may be too costly to do for every order especially during peak times. In this work, we explore the possibility of exploiting regularity in the fulfillment decision process to reduce the burden on the deciding system. By using data mining we aim to find patterns in past fulfillment decisions that can be used to efficiently predict most likely assignments for future decisions. Essentially, those assignments that can be predicted with high confidence can be used to shortcut, or bypass, the expensive deciding process, or else a set of most likely assignments can be used for shortlisting -- sending a much smaller set of candidates for consideration by the fulfillment deciding system.