 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClinical named entity recognition in the Portuguese language: a benchmark of modern BERT models and LLMs
Mar 27, 2026Clinical notes contain valuable unstructured information. Named entity recognition (NER) enables the automatic extraction of medical concepts; however, benchmarks for Portuguese remain scarce. In this study, we aimed to evaluate BERT-based models and large language models (LLMs) for clinical NER in Portuguese and to test strategies for addressing multilabel imbalance. We compared BioBERTpt, BERTimbau, ModernBERT, and mmBERT with LLMs such as GPT-5 and Gemini-2.5, using the public SemClinBr corpus and a private breast cancer dataset. Models were trained under identical conditions and evaluated using precision, recall, and F1-score. Iterative stratification, weighted loss, and oversampling were explored to mitigate class imbalance. The mmBERT-base model achieved the best performance (micro F1 = 0.76), outperforming all other models. Iterative stratification improved class balance and overall performance. Multilingual BERT models, particularly mmBERT, perform strongly for Portuguese clinical NER and can run locally with limited computational resources. Balanced data-splitting strategies further enhance performance.
Improve High Level Classification with a More Sensitive metric and Optimization approach for Complex Network Building
Oct 23, 2021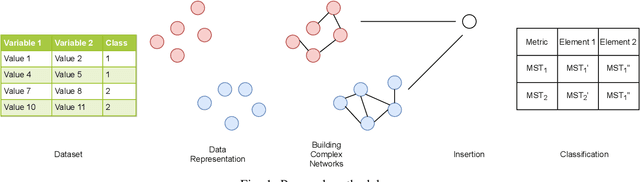


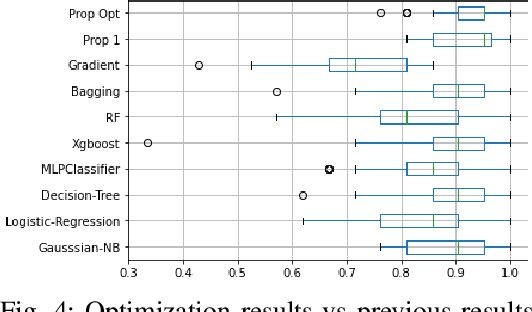
Complex Networks are a good approach to find internal relationships and represent the structure of classes in a dataset then they are used for High Level Classification. Previous works use K-Nearest Neighbors to build each Complex Network considering all the available samples. This paper introduces a different creation of Complex Networks, considering only sample which belongs to each class. And metric is used to analyze the structure of Complex Networks, besides an optimization approach to improve the performance is presented. Experiments are executed considering a cross validation process, the optimization approach is performed using grid search and Genetic Algorithm, this process can improve the results up to 10%.
Characterization of Covid-19 Dataset using Complex Networks and Image Processing
Sep 24, 2020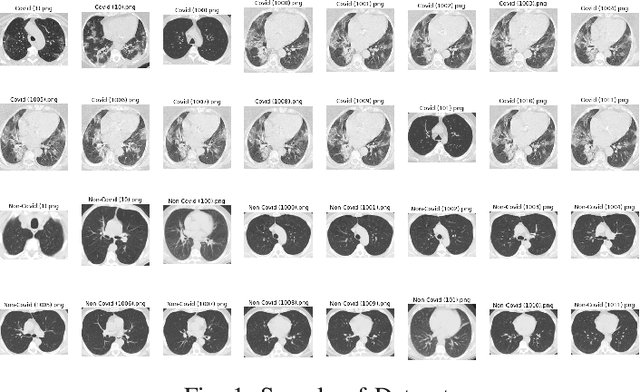
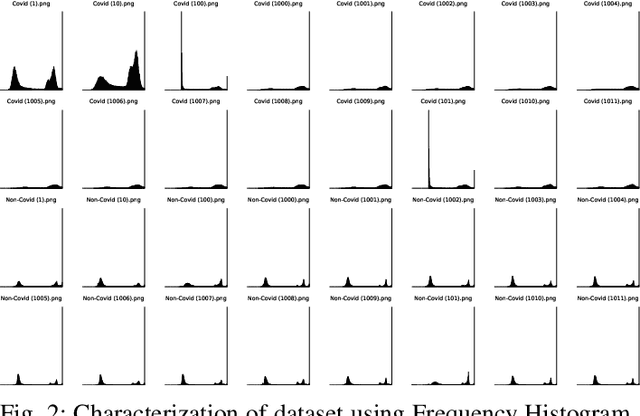
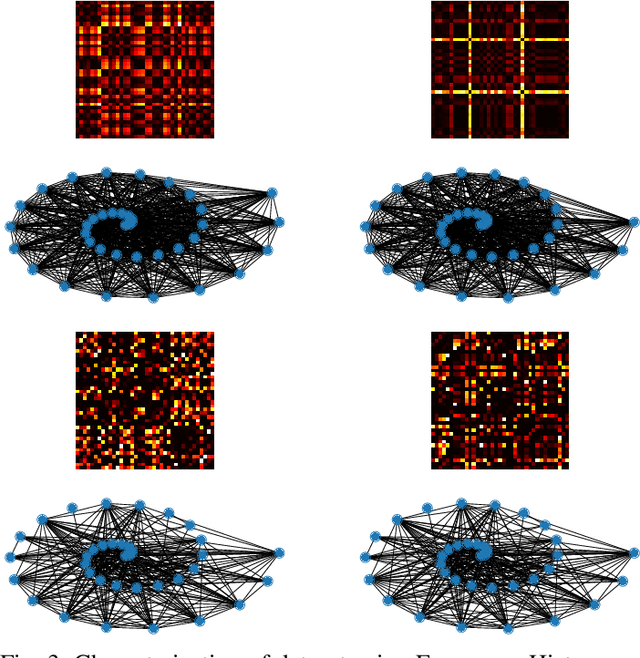

This paper aims to explore the structure of pattern behind covid-19 dataset. The dataset includes medical images with positive and negative cases. A sample of 100 sample is chosen, 50 per each class. An histogram frequency is calculated to get features using statistical measurements, besides a feature extraction using Grey Level Co-Occurrence Matrix (GLCM). Using both features are build Complex Networks respectively to analyze the adjacency matrices and check the presence of patterns. Initial experiments introduces the evidence of hidden patterns in the dataset for each class, which are visible using Complex Networks representation.