 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Diverse and Controllable Image Captioning with Part-of-Speech Guidance
May 31, 2018
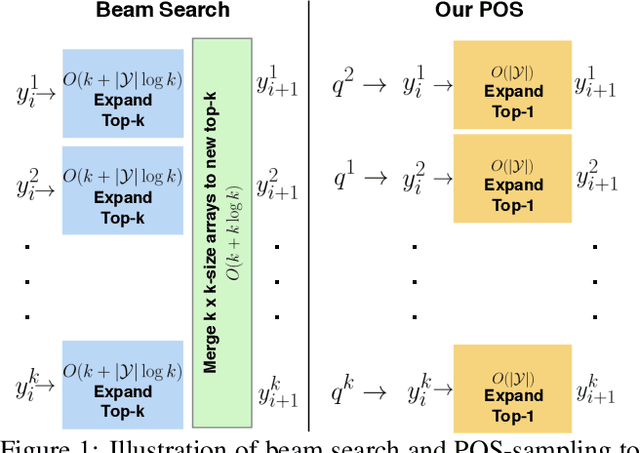
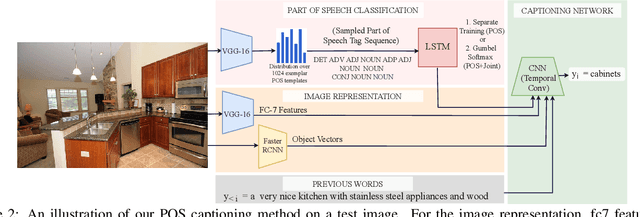
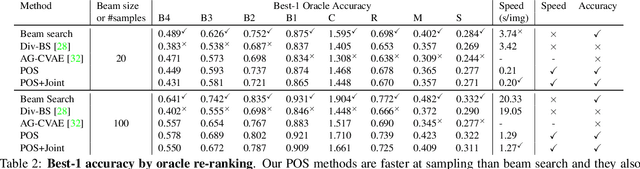
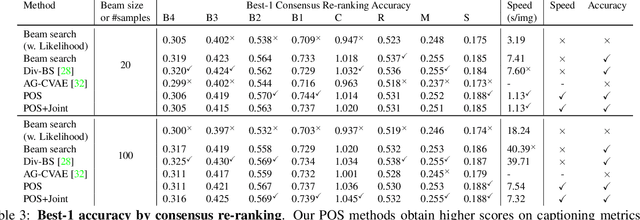
Automatically describing an image is an important capability for virtual assistants. Significant progress has been achieved in recent years on this task of image captioning. However, classical prediction techniques based on maximum likelihood trained LSTM nets don't embrace the inherent ambiguity of image captioning. To address this concern, recent variational auto-encoder and generative adversarial network based methods produce a set of captions by sampling from an abstract latent space. But, this latent space has limited interpretability and therefore, a control mechanism for captioning remains an open problem. This paper proposes a captioning technique conditioned on part-of-speech. Our method provides human interpretable control in form of part-of-speech. Importantly, part-of-speech is a language prior, and conditioning on it provides: (i) more diversity as evaluated by counting n-grams and the novel sentences generated, (ii) achieves high accuracy for the diverse captions on standard captioning metrics.
Attention-gated convolutional neural networks for off-resonance correction of spiral real-time MRI
Feb 14, 2021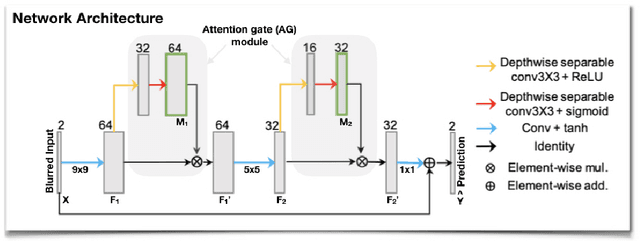
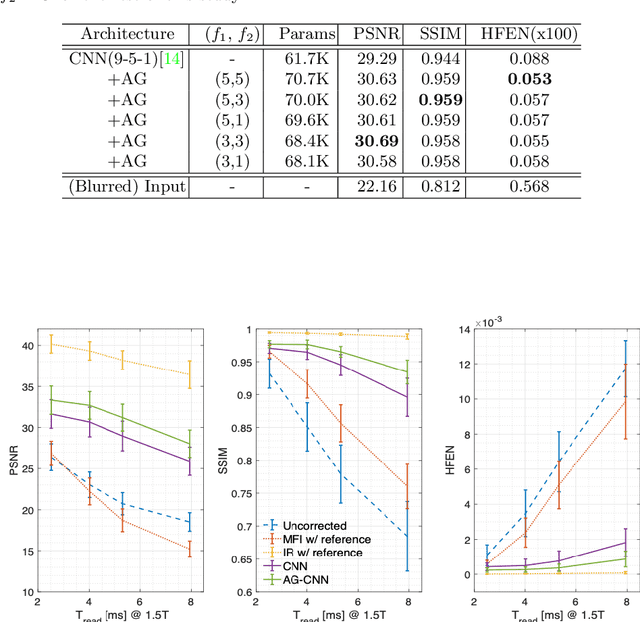

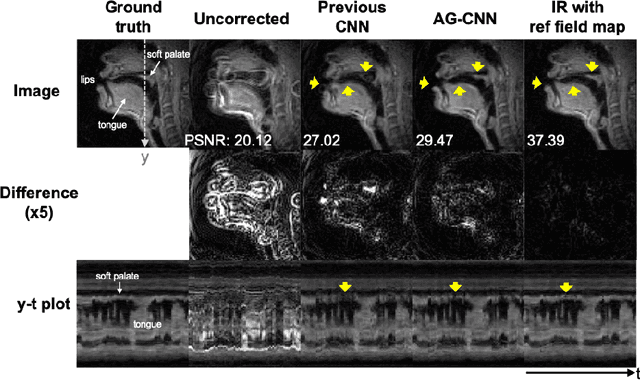
Spiral acquisitions are preferred in real-time MRI because of their efficiency, which has made it possible to capture vocal tract dynamics during natural speech. A fundamental limitation of spirals is blurring and signal loss due to off-resonance, which degrades image quality at air-tissue boundaries. Here, we present a new CNN-based off-resonance correction method that incorporates an attention-gate mechanism. This leverages spatial and channel relationships of filtered outputs and improves the expressiveness of the networks. We demonstrate improved performance with the attention-gate, on 1.5 Tesla spiral speech RT-MRI, compared to existing off-resonance correction methods.
* 8 pages, 4 figures, 1 table
Scale-aware Automatic Augmentation for Object Detection
Mar 31, 2021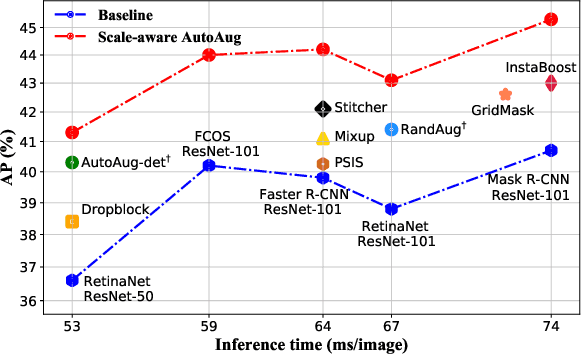
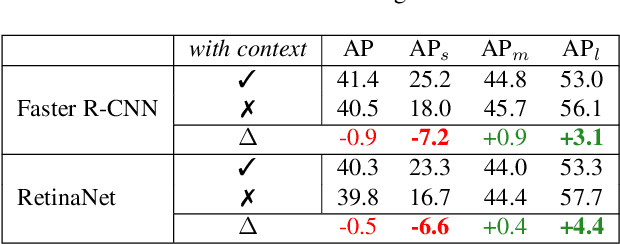
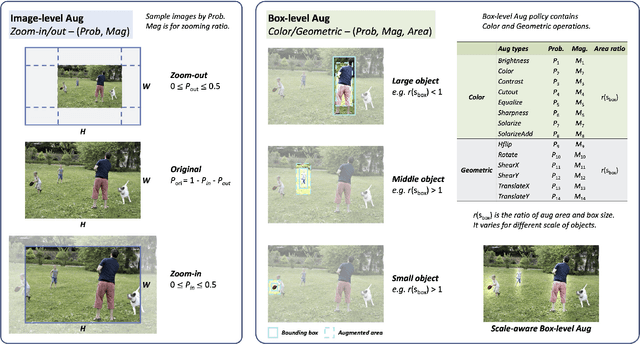

We propose Scale-aware AutoAug to learn data augmentation policies for object detection. We define a new scale-aware search space, where both image- and box-level augmentations are designed for maintaining scale invariance. Upon this search space, we propose a new search metric, termed Pareto Scale Balance, to facilitate search with high efficiency. In experiments, Scale-aware AutoAug yields significant and consistent improvement on various object detectors (e.g., RetinaNet, Faster R-CNN, Mask R-CNN, and FCOS), even compared with strong multi-scale training baselines. Our searched augmentation policies are transferable to other datasets and box-level tasks beyond object detection (e.g., instance segmentation and keypoint estimation) to improve performance. The search cost is much less than previous automated augmentation approaches for object detection. It is notable that our searched policies have meaningful patterns, which intuitively provide valuable insight for human data augmentation design. Code and models will be available at https://github.com/Jia-Research-Lab/SA-AutoAug.
Deep learning to estimate the physical proportion of infected region of lung for COVID-19 pneumonia with CT image set
Jun 09, 2020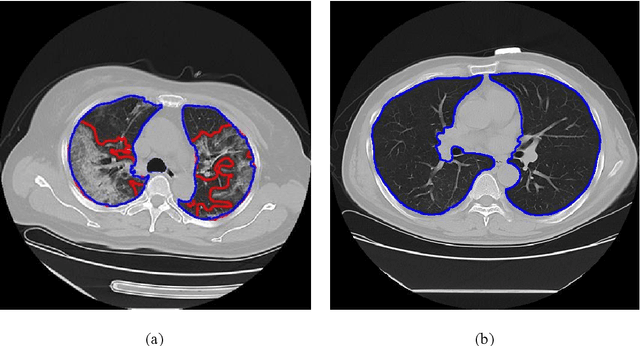
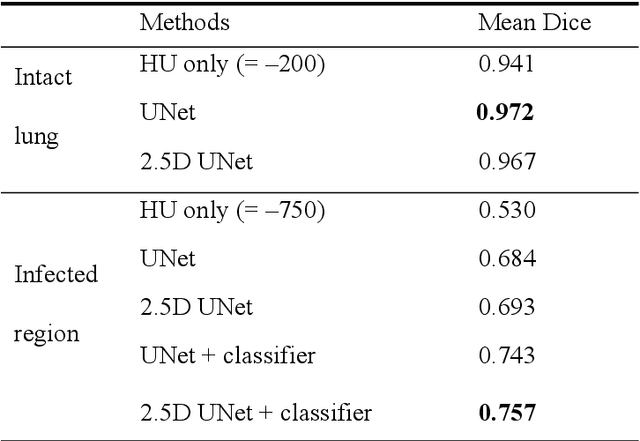
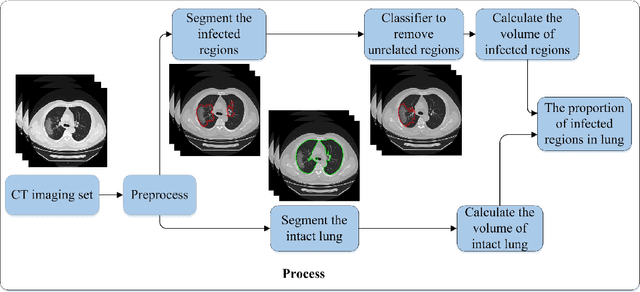
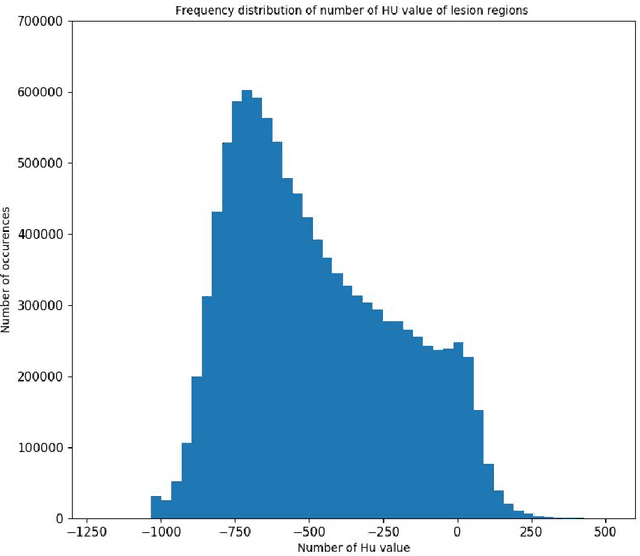
Utilizing computed tomography (CT) images to quickly estimate the severity of cases with COVID-19 is one of the most straightforward and efficacious methods. Two tasks were studied in this present paper. One was to segment the mask of intact lung in case of pneumonia. Another was to generate the masks of regions infected by COVID-19. The masks of these two parts of images then were converted to corresponding volumes to calculate the physical proportion of infected region of lung. A total of 129 CT image set were herein collected and studied. The intrinsic Hounsfiled value of CT images was firstly utilized to generate the initial dirty version of labeled masks both for intact lung and infected regions. Then, the samples were carefully adjusted and improved by two professional radiologists to generate the final training set and test benchmark. Two deep learning models were evaluated: UNet and 2.5D UNet. For the segment of infected regions, a deep learning based classifier was followed to remove unrelated blur-edged regions that were wrongly segmented out such as air tube and blood vessel tissue etc. For the segmented masks of intact lung and infected regions, the best method could achieve 0.972 and 0.757 measure in mean Dice similarity coefficient on our test benchmark. As the overall proportion of infected region of lung, the final result showed 0.961 (Pearson's correlation coefficient) and 11.7% (mean absolute percent error). The instant proportion of infected regions of lung could be used as a visual evidence to assist clinical physician to determine the severity of the case. Furthermore, a quantified report of infected regions can help predict the prognosis for COVID-19 cases which were scanned periodically within the treatment cycle.
Learning to Guide Decoding for Image Captioning
Apr 03, 2018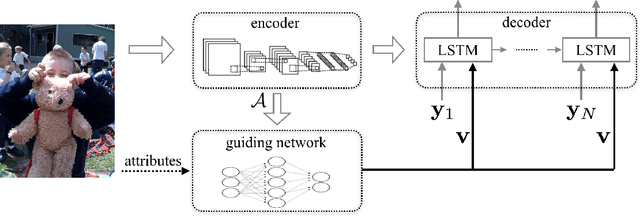
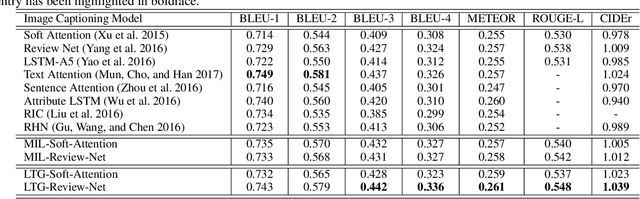
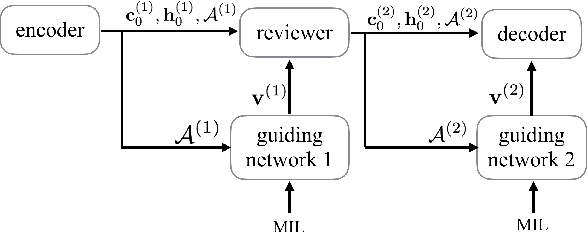
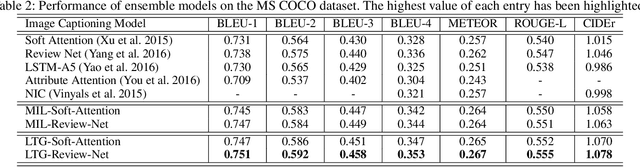
Recently, much advance has been made in image captioning, and an encoder-decoder framework has achieved outstanding performance for this task. In this paper, we propose an extension of the encoder-decoder framework by adding a component called guiding network. The guiding network models the attribute properties of input images, and its output is leveraged to compose the input of the decoder at each time step. The guiding network can be plugged into the current encoder-decoder framework and trained in an end-to-end manner. Hence, the guiding vector can be adaptively learned according to the signal from the decoder, making itself to embed information from both image and language. Additionally, discriminative supervision can be employed to further improve the quality of guidance. The advantages of our proposed approach are verified by experiments carried out on the MS COCO dataset.
von Mises-Fisher Loss: An Exploration of Embedding Geometries for Supervised Learning
Mar 31, 2021
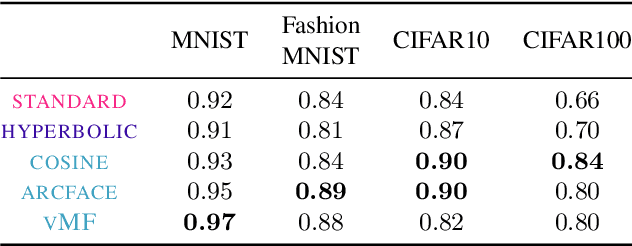
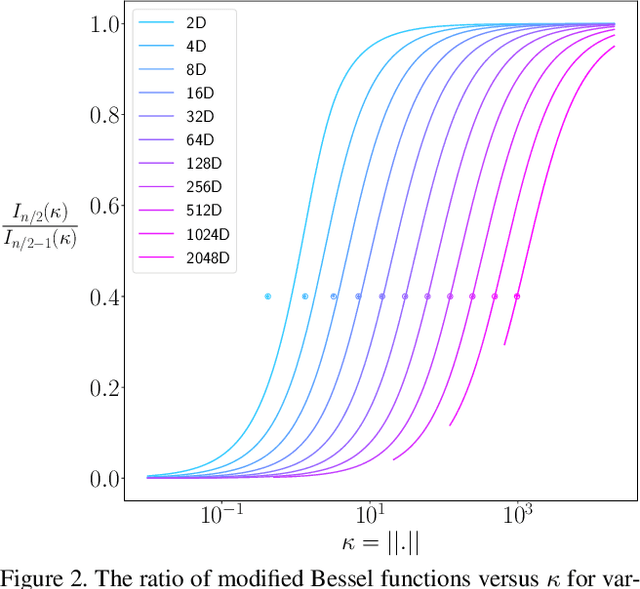
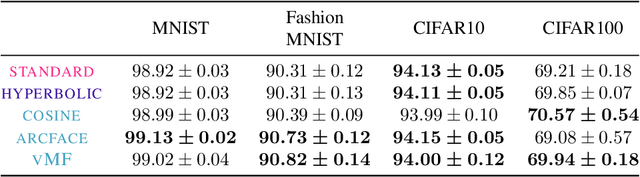
Recent work has argued that classification losses utilizing softmax cross-entropy are superior not only for fixed-set classification tasks, but also by outperforming losses developed specifically for open-set tasks including few-shot learning and retrieval. Softmax classifiers have been studied using different embedding geometries -- Euclidean, hyperbolic, and spherical -- and claims have been made about the superiority of one or another, but they have not been systematically compared with careful controls. We conduct an empirical investigation of embedding geometry on softmax losses for a variety of fixed-set classification and image retrieval tasks. An interesting property observed for the spherical losses lead us to propose a probabilistic classifier based on the von Mises-Fisher distribution, and we show that it is competitive with state-of-the-art methods while producing improved out-of-the-box calibration. We provide guidance regarding the trade-offs between losses and how to choose among them.
Neural Transformation Learning for Deep Anomaly Detection Beyond Images
Mar 31, 2021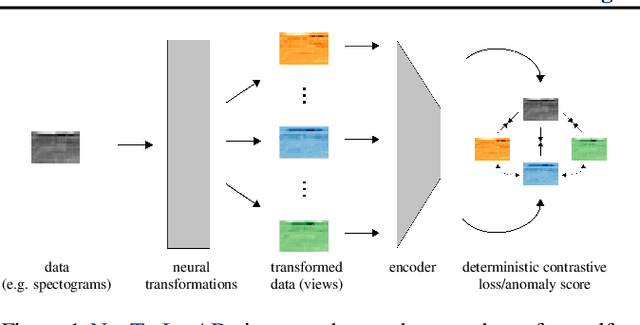

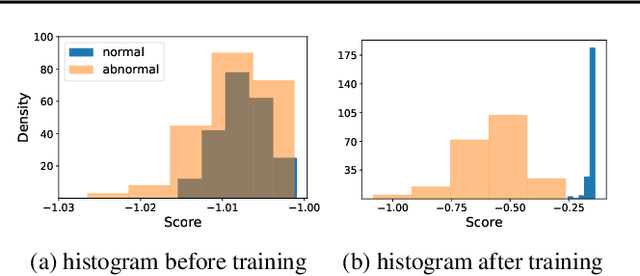
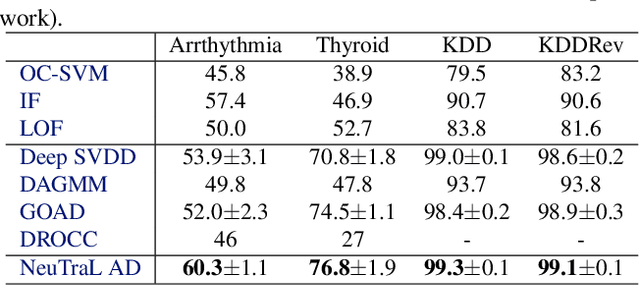
Data transformations (e.g. rotations, reflections, and cropping) play an important role in self-supervised learning. Typically, images are transformed into different views, and neural networks trained on tasks involving these views produce useful feature representations for downstream tasks, including anomaly detection. However, for anomaly detection beyond image data, it is often unclear which transformations to use. Here we present a simple end-to-end procedure for anomaly detection with learnable transformations. The key idea is to embed the transformed data into a semantic space such that the transformed data still resemble their untransformed form, while different transformations are easily distinguishable. Extensive experiments on time series demonstrate that we significantly outperform existing methods on the one-vs.-rest setting but also on the more challenging n-vs.-rest anomaly-detection task. On tabular datasets from the medical and cyber-security domains, our method learns domain-specific transformations and detects anomalies more accurately than previous work.
Using StyleGAN for Visual Interpretability of Deep Learning Models on Medical Images
Jan 19, 2021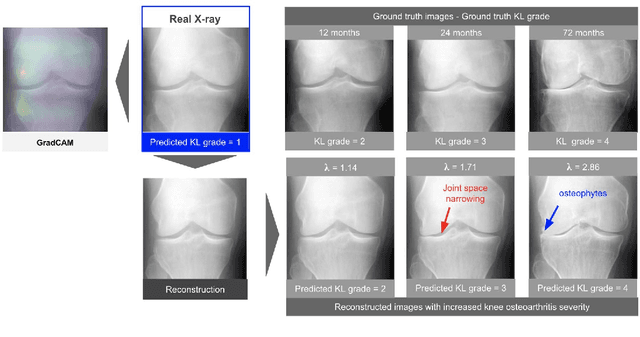
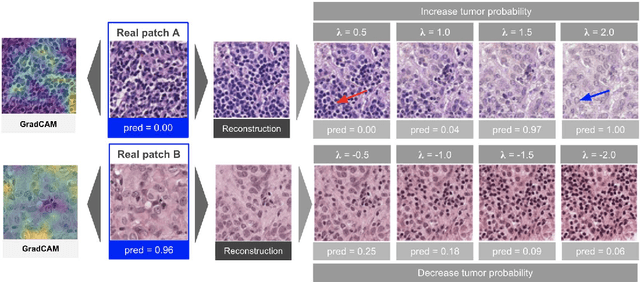
As AI-based medical devices are becoming more common in imaging fields like radiology and histology, interpretability of the underlying predictive models is crucial to expand their use in clinical practice. Existing heatmap-based interpretability methods such as GradCAM only highlight the location of predictive features but do not explain how they contribute to the prediction. In this paper, we propose a new interpretability method that can be used to understand the predictions of any black-box model on images, by showing how the input image would be modified in order to produce different predictions. A StyleGAN is trained on medical images to provide a mapping between latent vectors and images. Our method identifies the optimal direction in the latent space to create a change in the model prediction. By shifting the latent representation of an input image along this direction, we can produce a series of new synthetic images with changed predictions. We validate our approach on histology and radiology images, and demonstrate its ability to provide meaningful explanations that are more informative than GradCAM heatmaps. Our method reveals the patterns learned by the model, which allows clinicians to build trust in the model's predictions, discover new biomarkers and eventually reveal potential biases.
A Novel Interaction-based Methodology Towards Explainable AI with Better Understanding of Pneumonia Chest X-ray Images
Apr 19, 2021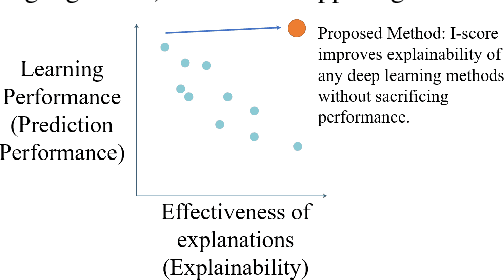
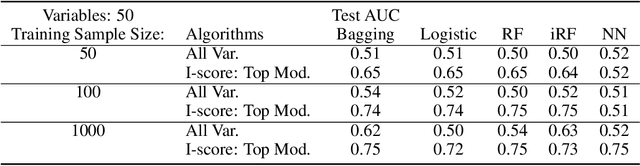
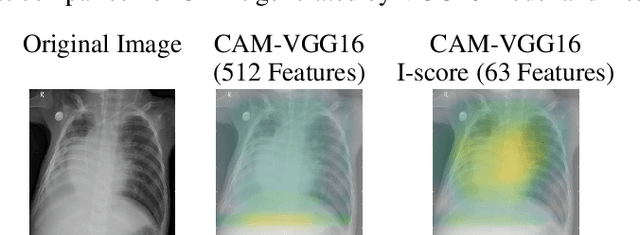
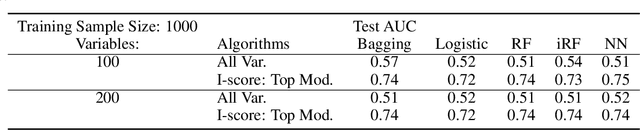
In the field of eXplainable AI (XAI), robust ``blackbox'' algorithms such as Convolutional Neural Networks (CNNs) are known for making high prediction performance. However, the ability to explain and interpret these algorithms still require innovation in the understanding of influential and, more importantly, explainable features that directly or indirectly impact the performance of predictivity. A number of methods existing in literature focus on visualization techniques but the concepts of explainability and interpretability still require rigorous definition. In view of the above needs, this paper proposes an interaction-based methodology -- Influence Score (I-score) -- to screen out the noisy and non-informative variables in the images hence it nourishes an environment with explainable and interpretable features that are directly associated to feature predictivity. We apply the proposed method on a real world application in Pneumonia Chest X-ray Image data set and produced state-of-the-art results. We demonstrate how to apply the proposed approach for more general big data problems by improving the explainability and interpretability without sacrificing the prediction performance. The contribution of this paper opens a novel angle that moves the community closer to the future pipelines of XAI problems.
Scale-recurrent Network for Deep Image Deblurring
Feb 06, 2018
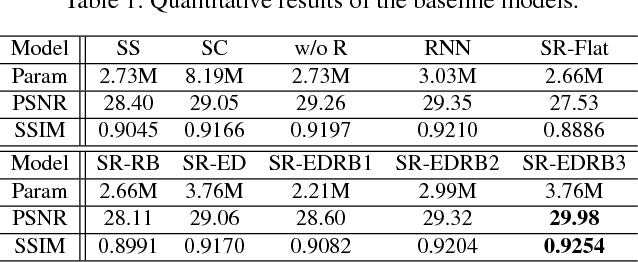
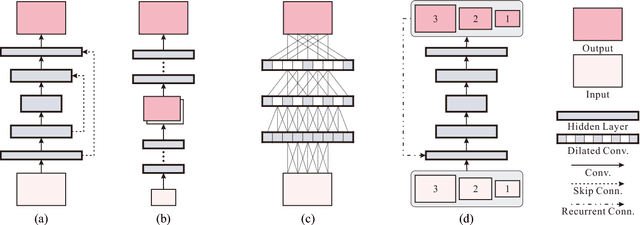
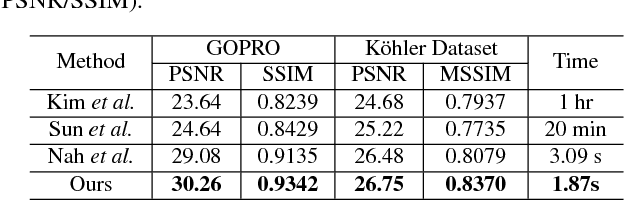
In single image deblurring, the "coarse-to-fine" scheme, i.e. gradually restoring the sharp image on different resolutions in a pyramid, is very successful in both traditional optimization-based methods and recent neural-network-based approaches. In this paper, we investigate this strategy and propose a Scale-recurrent Network (SRN-DeblurNet) for this deblurring task. Compared with the many recent learning-based approaches in [25], it has a simpler network structure, a smaller number of parameters and is easier to train. We evaluate our method on large-scale deblurring datasets with complex motion. Results show that our method can produce better quality results than state-of-the-arts, both quantitatively and qualitatively.