 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeONCOPILOT: A Promptable CT Foundation Model For Solid Tumor Evaluation
Oct 10, 2024



Carcinogenesis is a proteiform phenomenon, with tumors emerging in various locations and displaying complex, diverse shapes. At the crucial intersection of research and clinical practice, it demands precise and flexible assessment. However, current biomarkers, such as RECIST 1.1's long and short axis measurements, fall short of capturing this complexity, offering an approximate estimate of tumor burden and a simplistic representation of a more intricate process. Additionally, existing supervised AI models face challenges in addressing the variability in tumor presentations, limiting their clinical utility. These limitations arise from the scarcity of annotations and the models' focus on narrowly defined tasks. To address these challenges, we developed ONCOPILOT, an interactive radiological foundation model trained on approximately 7,500 CT scans covering the whole body, from both normal anatomy and a wide range of oncological cases. ONCOPILOT performs 3D tumor segmentation using visual prompts like point-click and bounding boxes, outperforming state-of-the-art models (e.g., nnUnet) and achieving radiologist-level accuracy in RECIST 1.1 measurements. The key advantage of this foundation model is its ability to surpass state-of-the-art performance while keeping the radiologist in the loop, a capability that previous models could not achieve. When radiologists interactively refine the segmentations, accuracy improves further. ONCOPILOT also accelerates measurement processes and reduces inter-reader variability, facilitating volumetric analysis and unlocking new biomarkers for deeper insights. This AI assistant is expected to enhance the precision of RECIST 1.1 measurements, unlock the potential of volumetric biomarkers, and improve patient stratification and clinical care, while seamlessly integrating into the radiological workflow.
Efficient Medical Question Answering with Knowledge-Augmented Question Generation
May 23, 2024In the expanding field of language model applications, medical knowledge representation remains a significant challenge due to the specialized nature of the domain. Large language models, such as GPT-4, obtain reasonable scores on medical question answering tasks, but smaller models are far behind. In this work, we introduce a method to improve the proficiency of a small language model in the medical domain by employing a two-fold approach. We first fine-tune the model on a corpus of medical textbooks. Then, we use GPT-4 to generate questions similar to the downstream task, prompted with textbook knowledge, and use them to fine-tune the model. Additionally, we introduce ECN-QA, a novel medical question answering dataset containing ``progressive questions'' composed of related sequential questions. We show the benefits of our training strategy on this dataset. The study's findings highlight the potential of small language models in the medical domain when appropriately fine-tuned. The code and weights are available at https://github.com/raidium-med/MQG.
Mind-to-Image: Projecting Visual Mental Imagination of the Brain from fMRI
Apr 15, 2024The reconstruction of images observed by subjects from fMRI data collected during visual stimuli has made significant strides in the past decade, thanks to the availability of extensive fMRI datasets and advancements in generative models for image generation. However, the application of visual reconstruction has remained limited. Reconstructing visual imagination presents a greater challenge, with potentially revolutionary applications ranging from aiding individuals with disabilities to verifying witness accounts in court. The primary hurdles in this field are the absence of data collection protocols for visual imagery and the lack of datasets on the subject. Traditionally, fMRI-to-image relies on data collected from subjects exposed to visual stimuli, which poses issues for generating visual imagery based on the difference of brain activity between visual stimulation and visual imagery. For the first time, we have compiled a substantial dataset (around 6h of scans) on visual imagery along with a proposed data collection protocol. We then train a modified version of an fMRI-to-image model and demonstrate the feasibility of reconstructing images from two modes of imagination: from memory and from pure imagination. This marks an important step towards creating a technology that allow direct reconstruction of visual imagery.
Using StyleGAN for Visual Interpretability of Deep Learning Models on Medical Images
Jan 19, 2021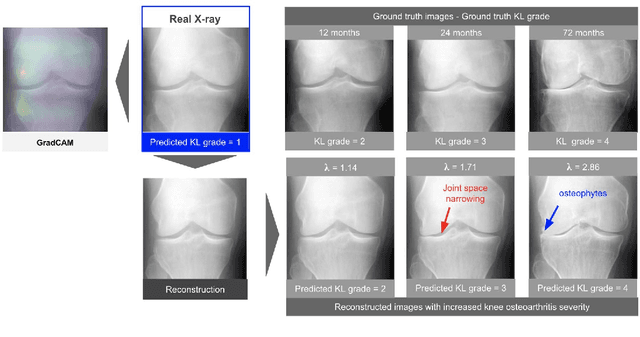
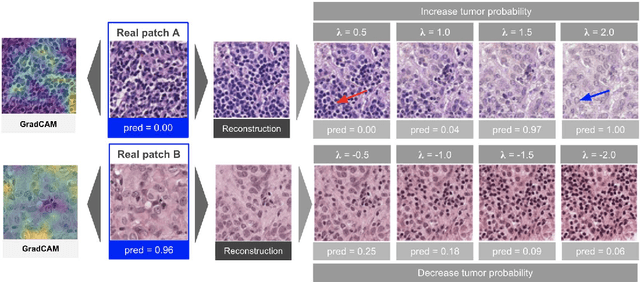
As AI-based medical devices are becoming more common in imaging fields like radiology and histology, interpretability of the underlying predictive models is crucial to expand their use in clinical practice. Existing heatmap-based interpretability methods such as GradCAM only highlight the location of predictive features but do not explain how they contribute to the prediction. In this paper, we propose a new interpretability method that can be used to understand the predictions of any black-box model on images, by showing how the input image would be modified in order to produce different predictions. A StyleGAN is trained on medical images to provide a mapping between latent vectors and images. Our method identifies the optimal direction in the latent space to create a change in the model prediction. By shifting the latent representation of an input image along this direction, we can produce a series of new synthetic images with changed predictions. We validate our approach on histology and radiology images, and demonstrate its ability to provide meaningful explanations that are more informative than GradCAM heatmaps. Our method reveals the patterns learned by the model, which allows clinicians to build trust in the model's predictions, discover new biomarkers and eventually reveal potential biases.