 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
TAP: Text-Aware Pre-training for Text-VQA and Text-Caption
Dec 08, 2020
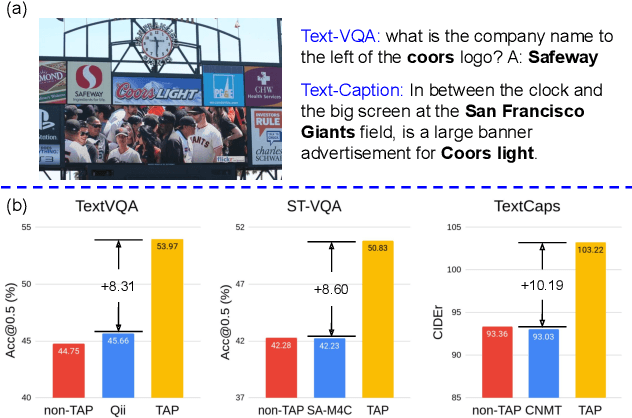
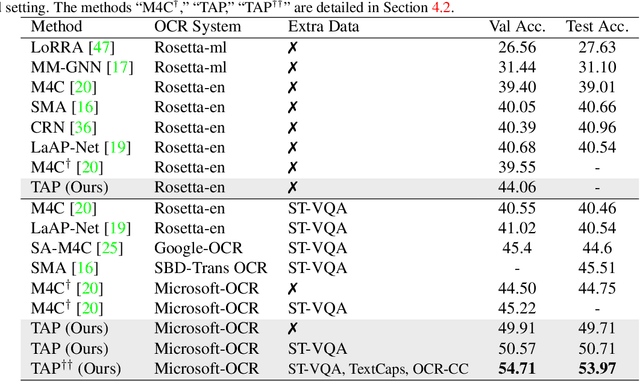
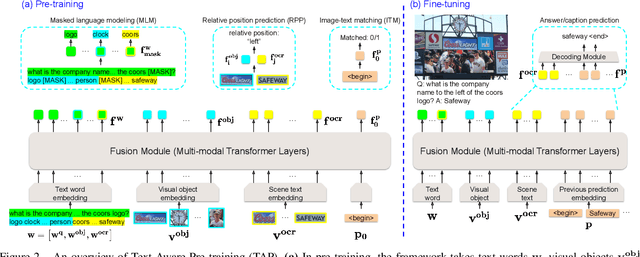
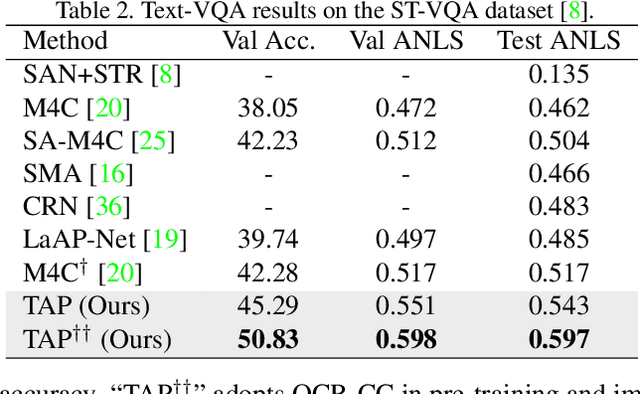
In this paper, we propose Text-Aware Pre-training (TAP) for Text-VQA and Text-Caption tasks. These two tasks aim at reading and understanding scene text in images for question answering and image caption generation, respectively. In contrast to the conventional vision-language pre-training that fails to capture scene text and its relationship with the visual and text modalities, TAP explicitly incorporates scene text (generated from OCR engines) in pre-training. With three pre-training tasks, including masked language modeling (MLM), image-text (contrastive) matching (ITM), and relative (spatial) position prediction (RPP), TAP effectively helps the model learn a better aligned representation among the three modalities: text word, visual object, and scene text. Due to this aligned representation learning, even pre-trained on the same downstream task dataset, TAP already boosts the absolute accuracy on the TextVQA dataset by +5.4%, compared with a non-TAP baseline. To further improve the performance, we build a large-scale dataset based on the Conceptual Caption dataset, named OCR-CC, which contains 1.4 million scene text-related image-text pairs. Pre-trained on this OCR-CC dataset, our approach outperforms the state of the art by large margins on multiple tasks, i.e., +8.3% accuracy on TextVQA, +8.6% accuracy on ST-VQA, and +10.2 CIDEr score on TextCaps.
Learning to synthesize: splitting and recombining low and high spatial frequencies for image recovery
Nov 19, 2018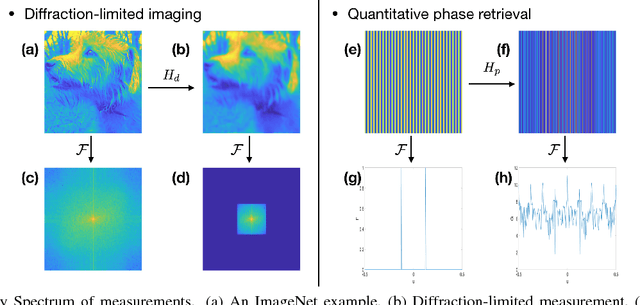

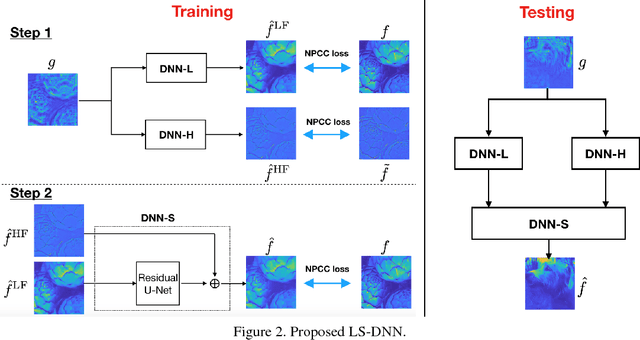

Deep Neural Network (DNN)-based image reconstruction, despite many successes, often exhibits uneven fidelity between high and low spatial frequency bands. In this paper we propose the Learning Synthesis by DNN (LS-DNN) approach where two DNNs process the low and high spatial frequencies, respectively, and, improving over [30], the two DNNs are trained separately and a third DNN combines them into an image with high fidelity at all bands. We demonstrate LS-DNN in two canonical inverse problems: super-resolution (SR) in diffraction-limited imaging (DLI), and quantitative phase retrieval (QPR). Our results also show comparable or improved performance over perceptual-loss based SR [21], and can be generalized to a wider range of image recovery problems.
Why do deep convolutional networks generalize so poorly to small image transformations?
May 30, 2018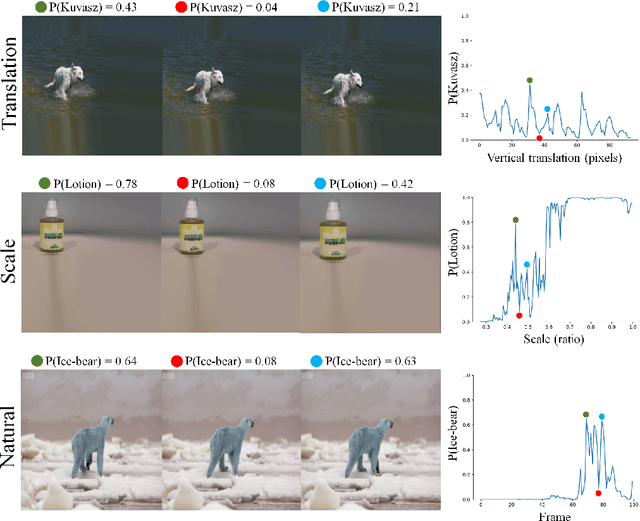

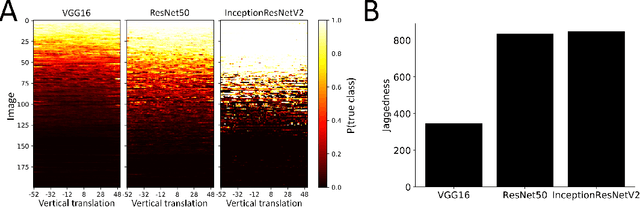
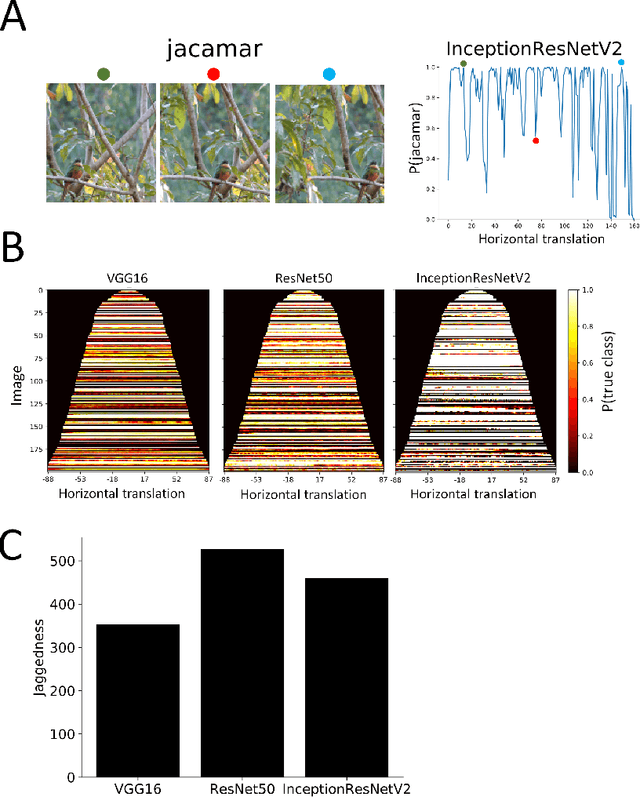
Deep convolutional network architectures are often assumed to guarantee generalization for small image translations and deformations. In this paper we show that modern CNNs (VGG16, ResNet50, and InceptionResNetV2) can drastically change their output when an image is translated in the image plane by a few pixels, and that this failure of generalization also happens with other realistic small image transformations. Furthermore, the deeper the network the more we see these failures to generalize. We show that these failures are related to the fact that the architecture of modern CNNs ignores the classical sampling theorem so that generalization is not guaranteed. We also show that biases in the statistics of commonly used image datasets makes it unlikely that CNNs will learn to be invariant to these transformations. Taken together our results suggest that the performance of CNNs in object recognition falls far short of the generalization capabilities of humans.
Combining Supervised and Un-supervised Learning for Automatic Citrus Segmentation
May 04, 2021
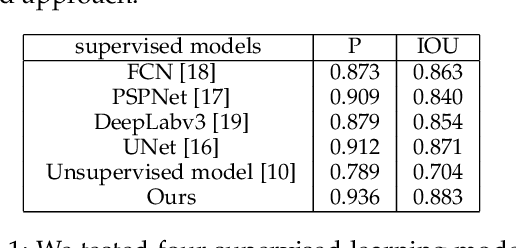
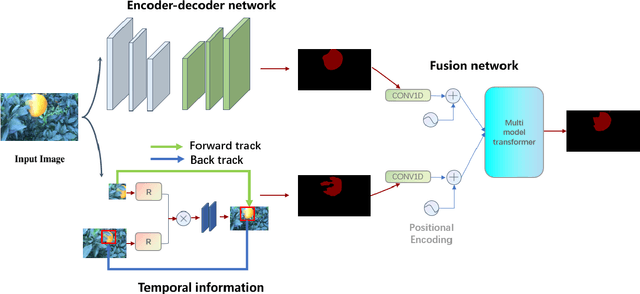

Citrus segmentation is a key step of automatic citrus picking. While most current image segmentation approaches achieve good segmentation results by pixel-wise segmentation, these supervised learning-based methods require a large amount of annotated data, and do not consider the continuous temporal changes of citrus position in real-world applications. In this paper, we first train a simple CNN with a small number of labelled citrus images in a supervised manner, which can roughly predict the citrus location from each frame. Then, we extend a state-of-the-art unsupervised learning approach to pre-learn the citrus's potential movements between frames from unlabelled citrus's videos. To take advantages of both networks, we employ the multimodal transformer to combine supervised learned static information and unsupervised learned movement information. The experimental results show that combing both network allows the prediction accuracy reached at 88.3$\%$ IOU and 93.6$\%$ precision, outperforming the original supervised baseline 1.2$\%$ and 2.4$\%$. Compared with most of the existing citrus segmentation methods, our method uses a small amount of supervised data and a large number of unsupervised data, while learning the pixel level location information and the temporal information of citrus changes to enhance the segmentation effect.
Multimodal Image Captioning for Marketing Analysis
Feb 06, 2018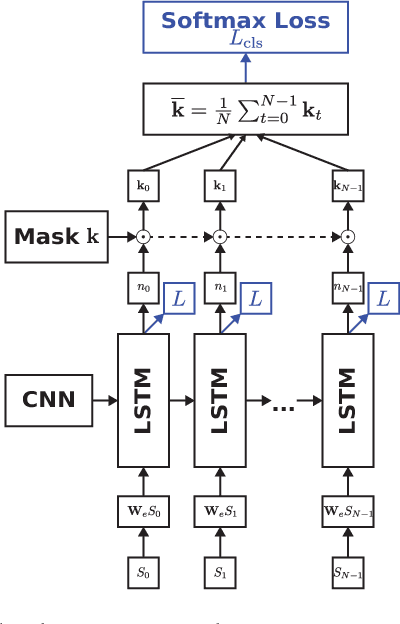
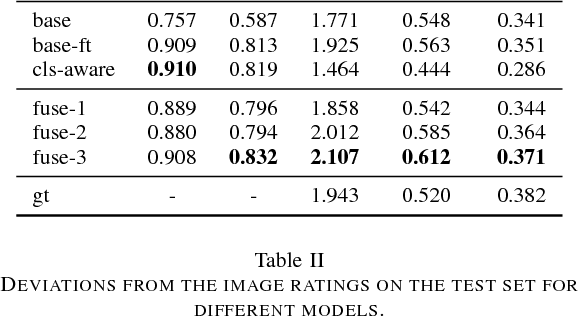
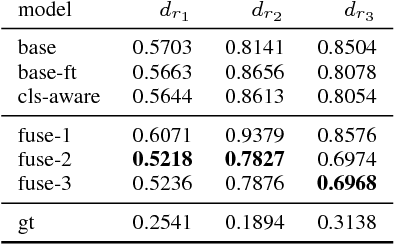
Automatically captioning images with natural language sentences is an important research topic. State of the art models are able to produce human-like sentences. These models typically describe the depicted scene as a whole and do not target specific objects of interest or emotional relationships between these objects in the image. However, marketing companies require to describe these important attributes of a given scene. In our case, objects of interest are consumer goods, which are usually identifiable by a product logo and are associated with certain brands. From a marketing point of view, it is desirable to also evaluate the emotional context of a trademarked product, i.e., whether it appears in a positive or a negative connotation. We address the problem of finding brands in images and deriving corresponding captions by introducing a modified image captioning network. We also add a third output modality, which simultaneously produces real-valued image ratings. Our network is trained using a classification-aware loss function in order to stimulate the generation of sentences with an emphasis on words identifying the brand of a product. We evaluate our model on a dataset of images depicting interactions between humans and branded products. The introduced network improves mean class accuracy by 24.5 percent. Thanks to adding the third output modality, it also considerably improves the quality of generated captions for images depicting branded products.
Generation of COVID-19 Chest CT Scan Images using Generative Adversarial Networks
May 20, 2021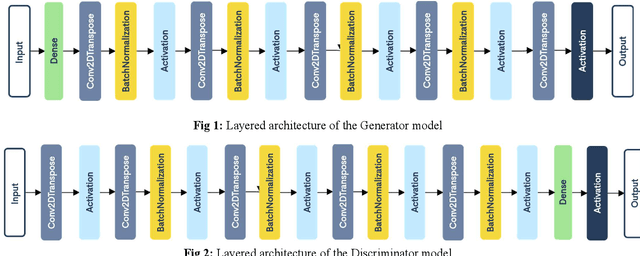
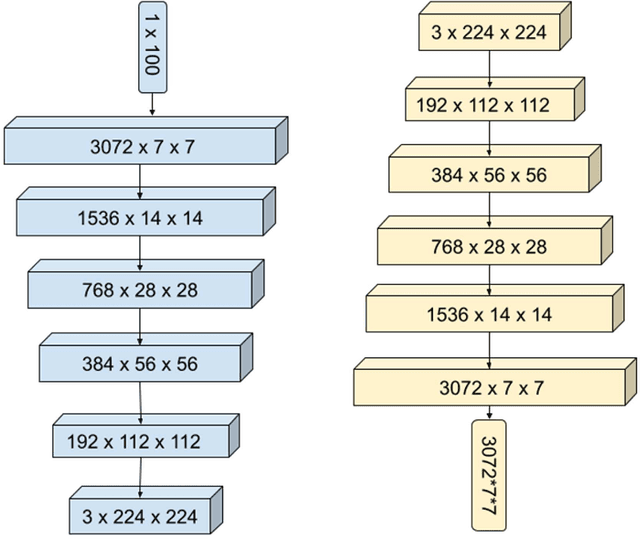
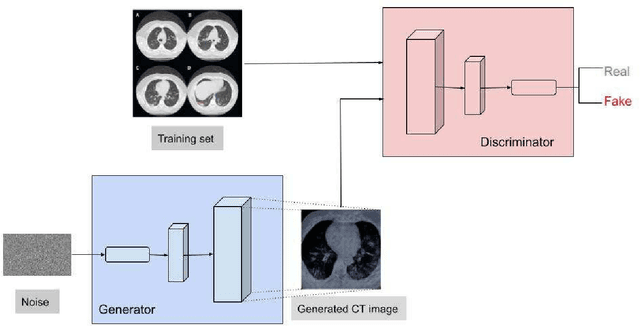
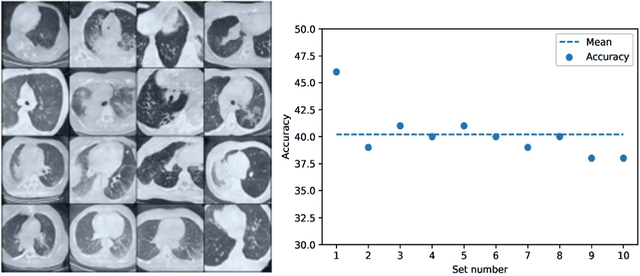
SARS-CoV-2, also known as COVID-19 or Coronavirus, is a viral contagious disease that is infected by a novel coronavirus, and has been rapidly spreading across the globe. It is very important to test and isolate people to reduce spread, and from here comes the need to do this quickly and efficiently. According to some studies, Chest-CT outperforms RT-PCR lab testing, which is the current standard, when diagnosing COVID-19 patients. Due to this, computer vision researchers have developed various deep learning systems that can predict COVID-19 using a Chest-CT scan correctly to a certain degree. The accuracy of these systems is limited since deep learning neural networks such as CNNs (Convolutional Neural Networks) need a significantly large quantity of data for training in order to produce good quality results. Since the disease is relatively recent and more focus has been on CXR (Chest XRay) images, the available chest CT Scan image dataset is much less. We propose a method, by utilizing GANs, to generate synthetic chest CT images of both positive and negative COVID-19 patients. Using a pre-built predictive model, we concluded that around 40% of the generated images are correctly predicted as COVID-19 positive. The dataset thus generated can be used to train a CNN-based classifier which can help determine COVID-19 in a patient with greater accuracy.
An Effective Two-Branch Model-Based Deep Network for Single Image Deraining
May 14, 2019
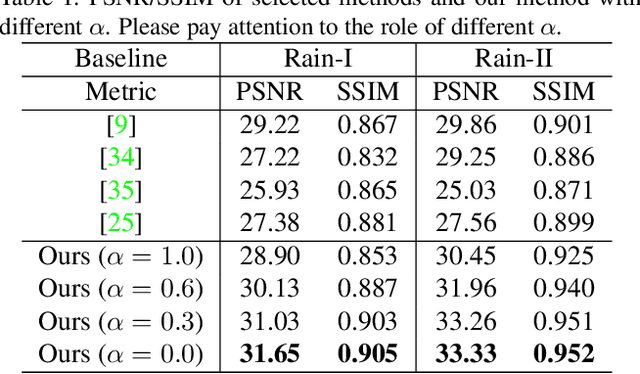
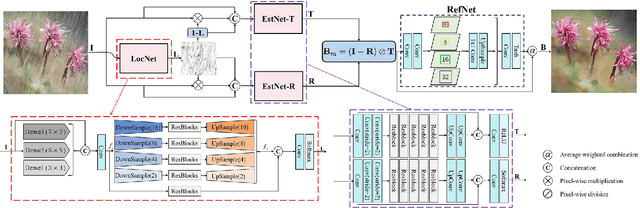
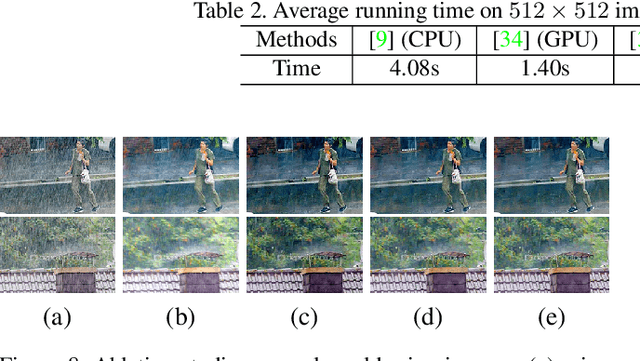
Removing rain effects from an image automatically has many applications such as autonomous driving, drone piloting and photo editing and still draws the attention of many people. Traditional methods use heuristics to handcraft various priors to remove or separate the rain effects from an image. Recently end-to-end deep learning based deraining methods have been proposed to offer more flexibility and effectiveness. However, they tend not to obtain good visual effect when encountered images with heavy rain. Heavy rain brings not only rain streaks but also haze-like effect which is caused by the accumulation of tiny raindrops. Different from previous deraining methods, in this paper we model rainy images with a new rain model to remove not only rain streaks but also haze-like effect. Guided by our model, we design a two-branch network to learn its parameters. Then, an SPP structure is jointly trained to refine the results of our model to control the degree of removing the haze-like effect flexibly. Besides, a subnetwork which can localize the rainy pixels is proposed to guide the training of our network. Extensive experiments on several datasets show that our method outperforms the state-of-the-art in both objectives assessments and visual quality.
Deep BCD-Net Using Identical Encoding-Decoding CNN Structures for Iterative Image Recovery
Apr 28, 2018
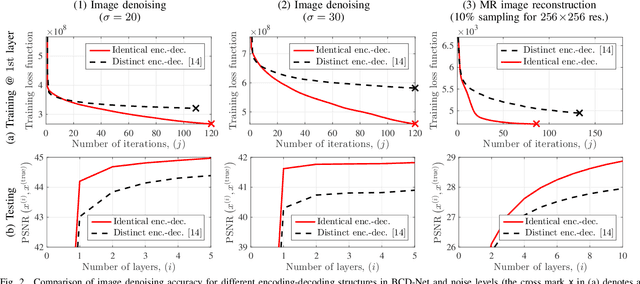
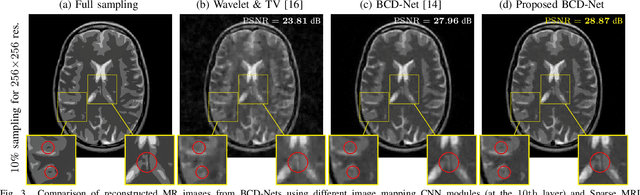
In "extreme" computational imaging that collects extremely undersampled or noisy measurements, obtaining an accurate image within a reasonable computing time is challenging. Incorporating image mapping convolutional neural networks (CNN) into iterative image recovery has great potential to resolve this issue. This paper 1) incorporates image mapping CNN using identical convolutional kernels in both encoders and decoders into a block coordinate descent (BCD) signal recovery method and 2) applies alternating direction method of multipliers to train the aforementioned image mapping CNN. We refer to the proposed recurrent network as BCD-Net using identical encoding-decoding CNN structures. Numerical experiments show that, for a) denoising low signal-to-noise-ratio images and b) extremely undersampled magnetic resonance imaging, the proposed BCD-Net achieves significantly more accurate image recovery, compared to BCD-Net using distinct encoding-decoding structures and/or the conventional image recovery model using both wavelets and total variation.
Toward a Thinking Microscope: Deep Learning in Optical Microscopy and Image Reconstruction
May 23, 2018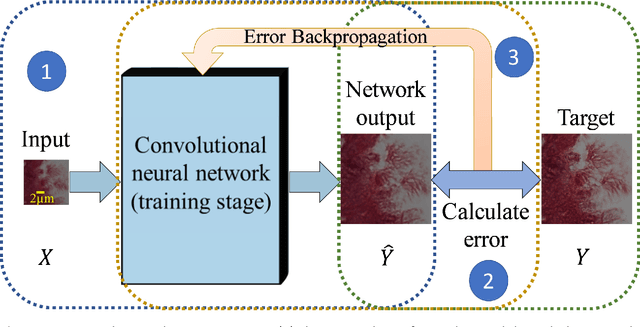
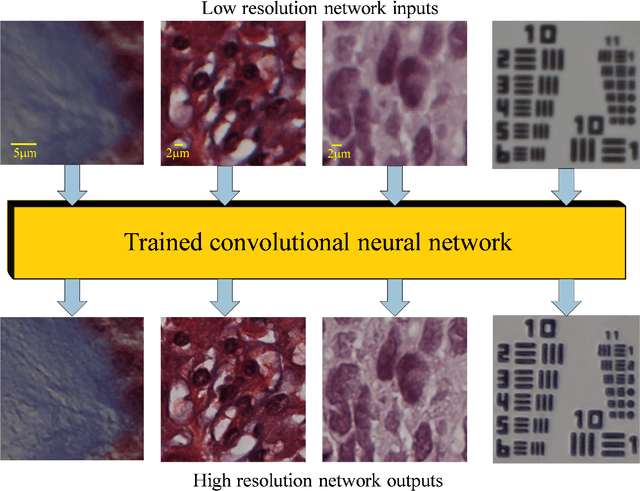
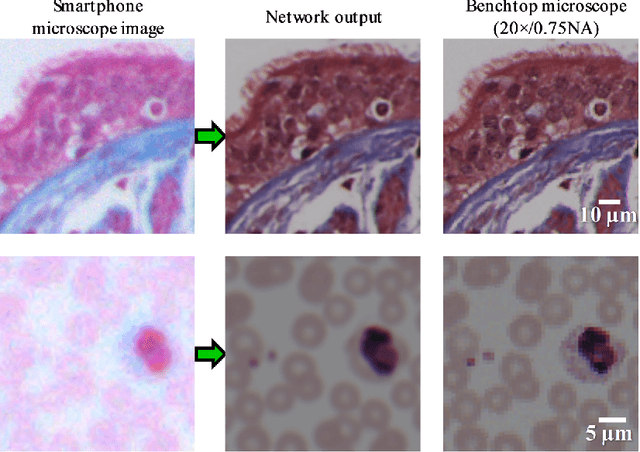

We discuss recently emerging applications of the state-of-art deep learning methods on optical microscopy and microscopic image reconstruction, which enable new transformations among different modes and modalities of microscopic imaging, driven entirely by image data. We believe that deep learning will fundamentally change both the hardware and image reconstruction methods used in optical microscopy in a holistic manner.
FastNeRF: High-Fidelity Neural Rendering at 200FPS
Apr 15, 2021
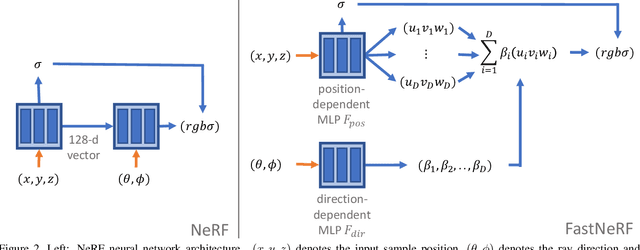
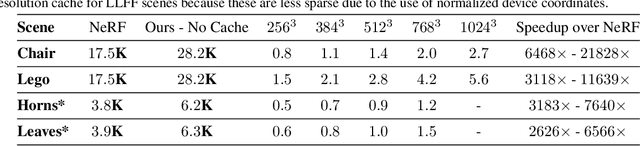
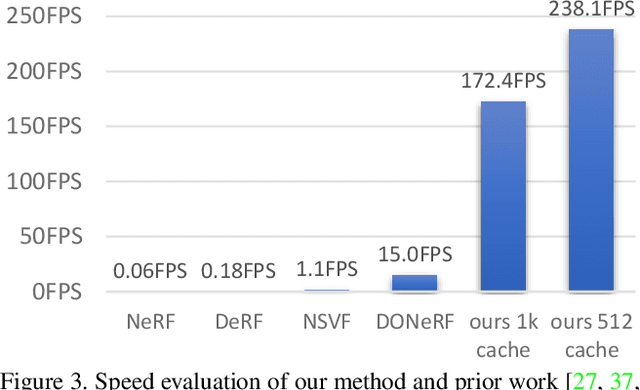
Recent work on Neural Radiance Fields (NeRF) showed how neural networks can be used to encode complex 3D environments that can be rendered photorealistically from novel viewpoints. Rendering these images is very computationally demanding and recent improvements are still a long way from enabling interactive rates, even on high-end hardware. Motivated by scenarios on mobile and mixed reality devices, we propose FastNeRF, the first NeRF-based system capable of rendering high fidelity photorealistic images at 200Hz on a high-end consumer GPU. The core of our method is a graphics-inspired factorization that allows for (i) compactly caching a deep radiance map at each position in space, (ii) efficiently querying that map using ray directions to estimate the pixel values in the rendered image. Extensive experiments show that the proposed method is 3000 times faster than the original NeRF algorithm and at least an order of magnitude faster than existing work on accelerating NeRF, while maintaining visual quality and extensibility.