 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGAIA-2: A Controllable Multi-View Generative World Model for Autonomous Driving
Mar 26, 2025
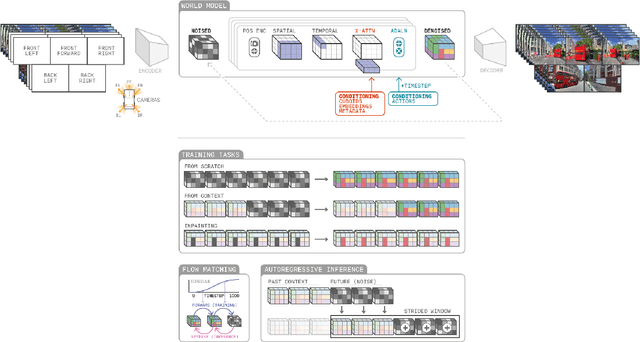


Generative models offer a scalable and flexible paradigm for simulating complex environments, yet current approaches fall short in addressing the domain-specific requirements of autonomous driving - such as multi-agent interactions, fine-grained control, and multi-camera consistency. We introduce GAIA-2, Generative AI for Autonomy, a latent diffusion world model that unifies these capabilities within a single generative framework. GAIA-2 supports controllable video generation conditioned on a rich set of structured inputs: ego-vehicle dynamics, agent configurations, environmental factors, and road semantics. It generates high-resolution, spatiotemporally consistent multi-camera videos across geographically diverse driving environments (UK, US, Germany). The model integrates both structured conditioning and external latent embeddings (e.g., from a proprietary driving model) to facilitate flexible and semantically grounded scene synthesis. Through this integration, GAIA-2 enables scalable simulation of both common and rare driving scenarios, advancing the use of generative world models as a core tool in the development of autonomous systems. Videos are available at https://wayve.ai/thinking/gaia-2.
WayveScenes101: A Dataset and Benchmark for Novel View Synthesis in Autonomous Driving
Jul 11, 2024



We present WayveScenes101, a dataset designed to help the community advance the state of the art in novel view synthesis that focuses on challenging driving scenes containing many dynamic and deformable elements with changing geometry and texture. The dataset comprises 101 driving scenes across a wide range of environmental conditions and driving scenarios. The dataset is designed for benchmarking reconstructions on in-the-wild driving scenes, with many inherent challenges for scene reconstruction methods including image glare, rapid exposure changes, and highly dynamic scenes with significant occlusion. Along with the raw images, we include COLMAP-derived camera poses in standard data formats. We propose an evaluation protocol for evaluating models on held-out camera views that are off-axis from the training views, specifically testing the generalisation capabilities of methods. Finally, we provide detailed metadata for all scenes, including weather, time of day, and traffic conditions, to allow for a detailed model performance breakdown across scene characteristics. Dataset and code are available at https://github.com/wayveai/wayve_scenes.
CarLLaVA: Vision language models for camera-only closed-loop driving
Jun 14, 2024



In this technical report, we present CarLLaVA, a Vision Language Model (VLM) for autonomous driving, developed for the CARLA Autonomous Driving Challenge 2.0. CarLLaVA uses the vision encoder of the LLaVA VLM and the LLaMA architecture as backbone, achieving state-of-the-art closed-loop driving performance with only camera input and without the need for complex or expensive labels. Additionally, we show preliminary results on predicting language commentary alongside the driving output. CarLLaVA uses a semi-disentangled output representation of both path predictions and waypoints, getting the advantages of the path for better lateral control and the waypoints for better longitudinal control. We propose an efficient training recipe to train on large driving datasets without wasting compute on easy, trivial data. CarLLaVA ranks 1st place in the sensor track of the CARLA Autonomous Driving Challenge 2.0 outperforming the previous state of the art by 458% and the best concurrent submission by 32.6%.
LangProp: A code optimization framework using Language Models applied to driving
Jan 18, 2024



LangProp is a framework for iteratively optimizing code generated by large language models (LLMs) in a supervised/reinforcement learning setting. While LLMs can generate sensible solutions zero-shot, the solutions are often sub-optimal. Especially for code generation tasks, it is likely that the initial code will fail on certain edge cases. LangProp automatically evaluates the code performance on a dataset of input-output pairs, as well as catches any exceptions, and feeds the results back to the LLM in the training loop, so that the LLM can iteratively improve the code it generates. By adopting a metric- and data-driven training paradigm for this code optimization procedure, one could easily adapt findings from traditional machine learning techniques such as imitation learning, DAgger, and reinforcement learning. We demonstrate the first proof of concept of automated code optimization for autonomous driving in CARLA, showing that LangProp can generate interpretable and transparent driving policies that can be verified and improved in a metric- and data-driven way. Our code will be open-sourced and is available at https://github.com/shuishida/LangProp.
LingoQA: Video Question Answering for Autonomous Driving
Dec 21, 2023Autonomous driving has long faced a challenge with public acceptance due to the lack of explainability in the decision-making process. Video question-answering (QA) in natural language provides the opportunity for bridging this gap. Nonetheless, evaluating the performance of Video QA models has proved particularly tough due to the absence of comprehensive benchmarks. To fill this gap, we introduce LingoQA, a benchmark specifically for autonomous driving Video QA. The LingoQA trainable metric demonstrates a 0.95 Spearman correlation coefficient with human evaluations. We introduce a Video QA dataset of central London consisting of 419k samples that we release with the paper. We establish a baseline vision-language model and run extensive ablation studies to understand its performance.
Driving with LLMs: Fusing Object-Level Vector Modality for Explainable Autonomous Driving
Oct 13, 2023



Large Language Models (LLMs) have shown promise in the autonomous driving sector, particularly in generalization and interpretability. We introduce a unique object-level multimodal LLM architecture that merges vectorized numeric modalities with a pre-trained LLM to improve context understanding in driving situations. We also present a new dataset of 160k QA pairs derived from 10k driving scenarios, paired with high quality control commands collected with RL agent and question answer pairs generated by teacher LLM (GPT-3.5). A distinct pretraining strategy is devised to align numeric vector modalities with static LLM representations using vector captioning language data. We also introduce an evaluation metric for Driving QA and demonstrate our LLM-driver's proficiency in interpreting driving scenarios, answering questions, and decision-making. Our findings highlight the potential of LLM-based driving action generation in comparison to traditional behavioral cloning. We make our benchmark, datasets, and model available for further exploration.
GAIA-1: A Generative World Model for Autonomous Driving
Sep 29, 2023Autonomous driving promises transformative improvements to transportation, but building systems capable of safely navigating the unstructured complexity of real-world scenarios remains challenging. A critical problem lies in effectively predicting the various potential outcomes that may emerge in response to the vehicle's actions as the world evolves. To address this challenge, we introduce GAIA-1 ('Generative AI for Autonomy'), a generative world model that leverages video, text, and action inputs to generate realistic driving scenarios while offering fine-grained control over ego-vehicle behavior and scene features. Our approach casts world modeling as an unsupervised sequence modeling problem by mapping the inputs to discrete tokens, and predicting the next token in the sequence. Emerging properties from our model include learning high-level structures and scene dynamics, contextual awareness, generalization, and understanding of geometry. The power of GAIA-1's learned representation that captures expectations of future events, combined with its ability to generate realistic samples, provides new possibilities for innovation in the field of autonomy, enabling enhanced and accelerated training of autonomous driving technology.
Linking vision and motion for self-supervised object-centric perception
Jul 14, 2023Object-centric representations enable autonomous driving algorithms to reason about interactions between many independent agents and scene features. Traditionally these representations have been obtained via supervised learning, but this decouples perception from the downstream driving task and could harm generalization. In this work we adapt a self-supervised object-centric vision model to perform object decomposition using only RGB video and the pose of the vehicle as inputs. We demonstrate that our method obtains promising results on the Waymo Open perception dataset. While object mask quality lags behind supervised methods or alternatives that use more privileged information, we find that our model is capable of learning a representation that fuses multiple camera viewpoints over time and successfully tracks many vehicles and pedestrians in the dataset. Code for our model is available at https://github.com/wayveai/SOCS.
Model-Based Imitation Learning for Urban Driving
Oct 14, 2022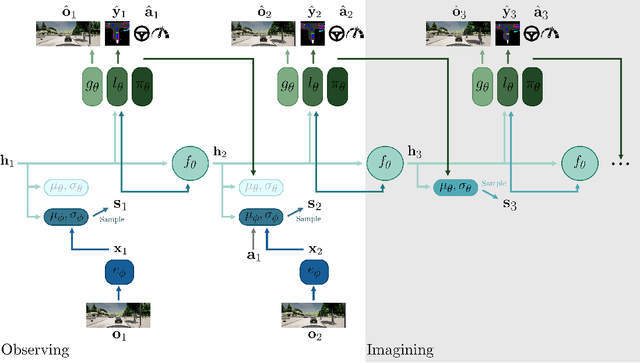
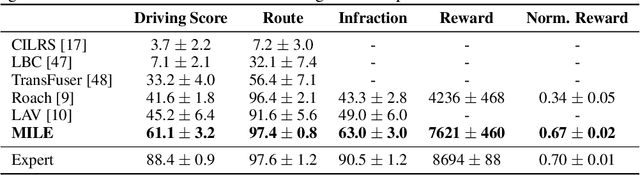
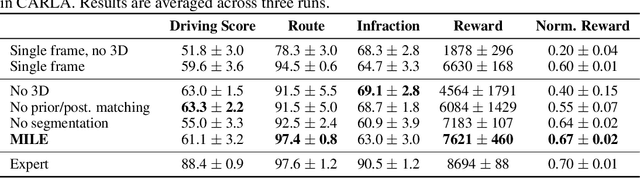
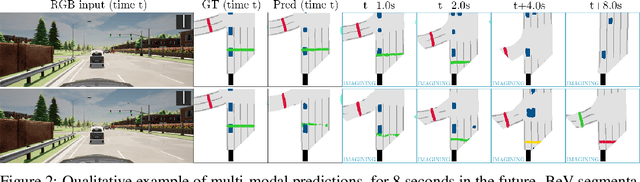
An accurate model of the environment and the dynamic agents acting in it offers great potential for improving motion planning. We present MILE: a Model-based Imitation LEarning approach to jointly learn a model of the world and a policy for autonomous driving. Our method leverages 3D geometry as an inductive bias and learns a highly compact latent space directly from high-resolution videos of expert demonstrations. Our model is trained on an offline corpus of urban driving data, without any online interaction with the environment. MILE improves upon prior state-of-the-art by 35% in driving score on the CARLA simulator when deployed in a completely new town and new weather conditions. Our model can predict diverse and plausible states and actions, that can be interpretably decoded to bird's-eye view semantic segmentation. Further, we demonstrate that it can execute complex driving manoeuvres from plans entirely predicted in imagination. Our approach is the first camera-only method that models static scene, dynamic scene, and ego-behaviour in an urban driving environment. The code and model weights are available at https://github.com/wayveai/mile.
Fake It Till You Make It: Face analysis in the wild using synthetic data alone
Oct 05, 2021
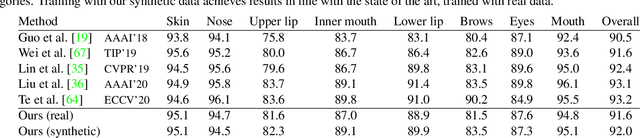


We demonstrate that it is possible to perform face-related computer vision in the wild using synthetic data alone. The community has long enjoyed the benefits of synthesizing training data with graphics, but the domain gap between real and synthetic data has remained a problem, especially for human faces. Researchers have tried to bridge this gap with data mixing, domain adaptation, and domain-adversarial training, but we show that it is possible to synthesize data with minimal domain gap, so that models trained on synthetic data generalize to real in-the-wild datasets. We describe how to combine a procedurally-generated parametric 3D face model with a comprehensive library of hand-crafted assets to render training images with unprecedented realism and diversity. We train machine learning systems for face-related tasks such as landmark localization and face parsing, showing that synthetic data can both match real data in accuracy as well as open up new approaches where manual labelling would be impossible.