 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeV-LASIK: Consistent Glasses-Removal from Videos Using Synthetic Data
Jun 20, 2024Diffusion-based generative models have recently shown remarkable image and video editing capabilities. However, local video editing, particularly removal of small attributes like glasses, remains a challenge. Existing methods either alter the videos excessively, generate unrealistic artifacts, or fail to perform the requested edit consistently throughout the video. In this work, we focus on consistent and identity-preserving removal of glasses in videos, using it as a case study for consistent local attribute removal in videos. Due to the lack of paired data, we adopt a weakly supervised approach and generate synthetic imperfect data, using an adjusted pretrained diffusion model. We show that despite data imperfection, by learning from our generated data and leveraging the prior of pretrained diffusion models, our model is able to perform the desired edit consistently while preserving the original video content. Furthermore, we exemplify the generalization ability of our method to other local video editing tasks by applying it successfully to facial sticker-removal. Our approach demonstrates significant improvement over existing methods, showcasing the potential of leveraging synthetic data and strong video priors for local video editing tasks.
Diffusing Colors: Image Colorization with Text Guided Diffusion
Dec 07, 2023



The colorization of grayscale images is a complex and subjective task with significant challenges. Despite recent progress in employing large-scale datasets with deep neural networks, difficulties with controllability and visual quality persist. To tackle these issues, we present a novel image colorization framework that utilizes image diffusion techniques with granular text prompts. This integration not only produces colorization outputs that are semantically appropriate but also greatly improves the level of control users have over the colorization process. Our method provides a balance between automation and control, outperforming existing techniques in terms of visual quality and semantic coherence. We leverage a pretrained generative Diffusion Model, and show that we can finetune it for the colorization task without losing its generative power or attention to text prompts. Moreover, we present a novel CLIP-based ranking model that evaluates color vividness, enabling automatic selection of the most suitable level of vividness based on the specific scene semantics. Our approach holds potential particularly for color enhancement and historical image colorization.
Temporally stable video segmentation without video annotations
Oct 17, 2021
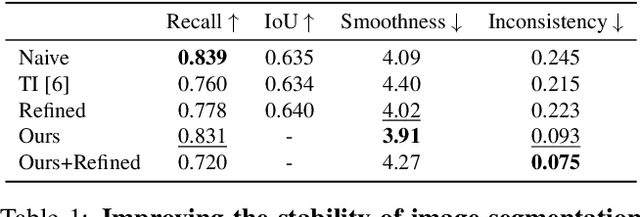
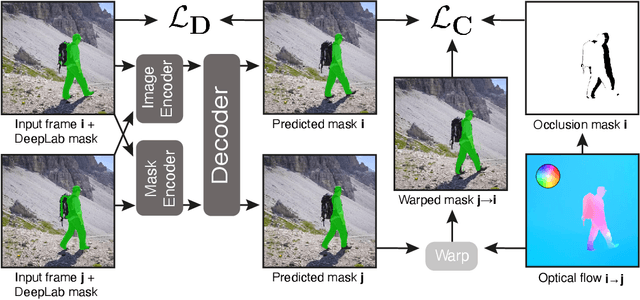
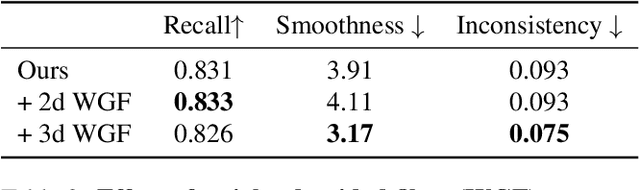
Temporally consistent dense video annotations are scarce and hard to collect. In contrast, image segmentation datasets (and pre-trained models) are ubiquitous, and easier to label for any novel task. In this paper, we introduce a method to adapt still image segmentation models to video in an unsupervised manner, by using an optical flow-based consistency measure. To ensure that the inferred segmented videos appear more stable in practice, we verify that the consistency measure is well correlated with human judgement via a user study. Training a new multi-input multi-output decoder using this measure as a loss, together with a technique for refining current image segmentation datasets and a temporal weighted-guided filter, we observe stability improvements in the generated segmented videos with minimal loss of accuracy.
Why do deep convolutional networks generalize so poorly to small image transformations?
May 30, 2018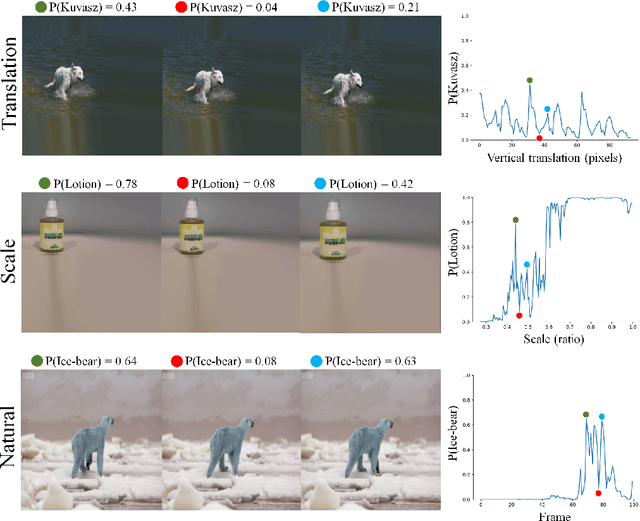

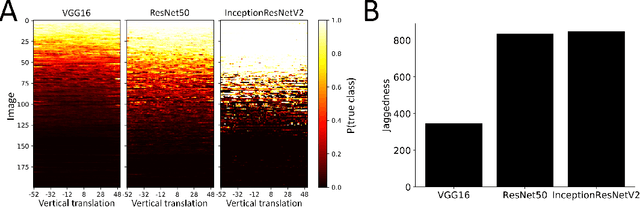
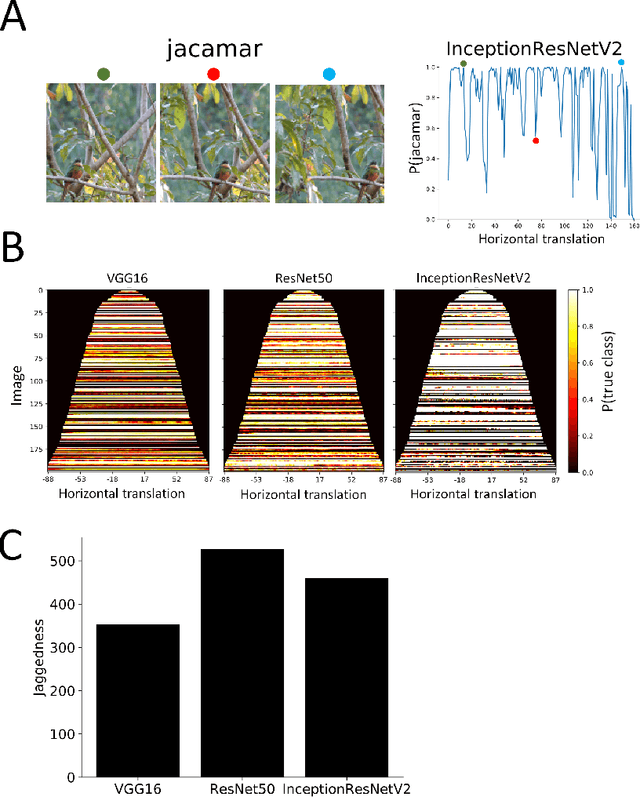
Deep convolutional network architectures are often assumed to guarantee generalization for small image translations and deformations. In this paper we show that modern CNNs (VGG16, ResNet50, and InceptionResNetV2) can drastically change their output when an image is translated in the image plane by a few pixels, and that this failure of generalization also happens with other realistic small image transformations. Furthermore, the deeper the network the more we see these failures to generalize. We show that these failures are related to the fact that the architecture of modern CNNs ignores the classical sampling theorem so that generalization is not guaranteed. We also show that biases in the statistics of commonly used image datasets makes it unlikely that CNNs will learn to be invariant to these transformations. Taken together our results suggest that the performance of CNNs in object recognition falls far short of the generalization capabilities of humans.