 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Self-Training Ensemble Networks for Zero-Shot Image Recognition
May 18, 2018
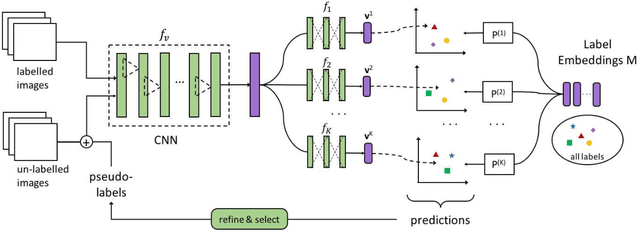
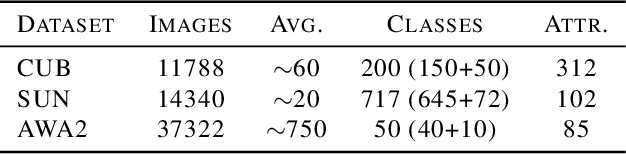
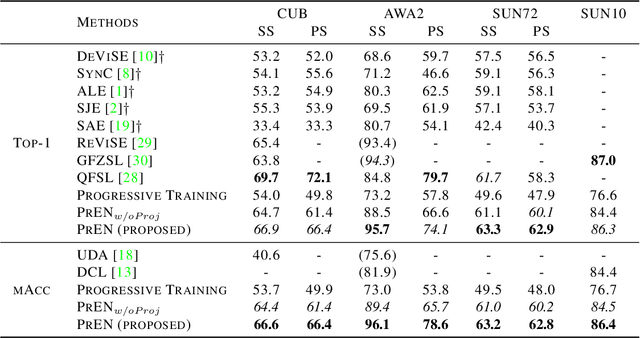
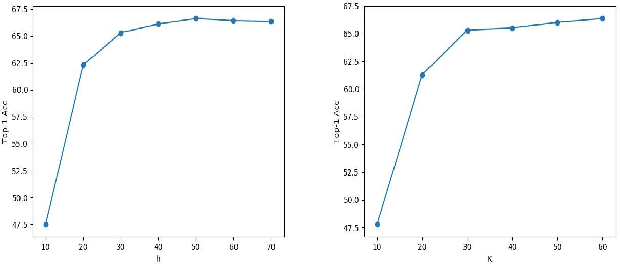
Despite the advancement of supervised image recognition algorithms, their de- pendence on the availability of labeled data and the rapid expansion of image categories raise the significant challenge of zero-shot learning. Zero-shot learn- ing (ZSL) aims to transfer knowledge from labeled classes into unlabeled classes to reduce human labeling effort. In this paper, we propose a novel self-training ensemble network model to address zero-shot image recognition. The ensemble network is built by learning multiple image classification functions with a shared feature extraction network but different label embedding representations, each of which facilitates information transfer to different subsets of unlabeled classes. A self-training framework is then deployed to iteratively label the most confident images in each unlabeled class with predicted pseudo-labels and update the ensem- ble network with the training data augmented by the pseudo-labels. The proposed model performs training on both labeled and unlabeled data. It can naturally bridge the domain shift problem in visual appearances and be extended to the generalized zero-shot learning scenario. We conduct experiments on multiple standard ZSL datasets and the empirical results demonstrate the efficacy of the proposed model.
VICE: Visual Identification and Correction of Neural Circuit Errors
May 14, 2021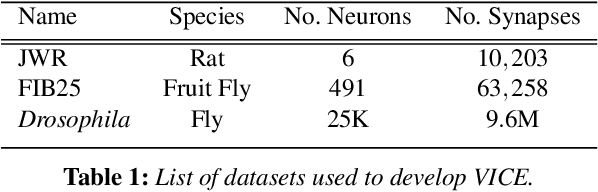
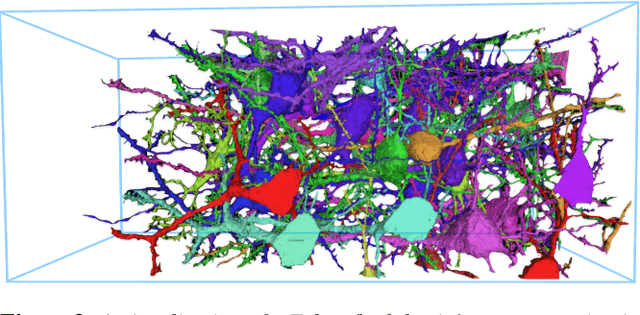
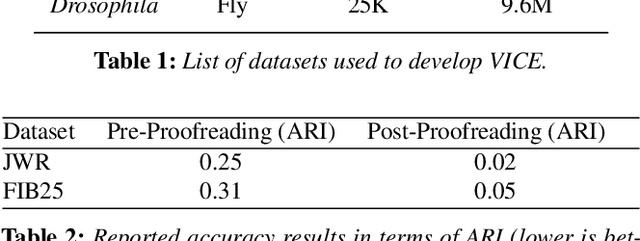
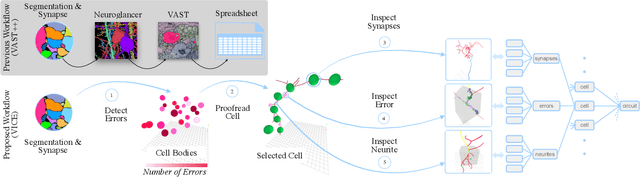
A connectivity graph of neurons at the resolution of single synapses provides scientists with a tool for understanding the nervous system in health and disease. Recent advances in automatic image segmentation and synapse prediction in electron microscopy (EM) datasets of the brain have made reconstructions of neurons possible at the nanometer scale. However, automatic segmentation sometimes struggles to segment large neurons correctly, requiring human effort to proofread its output. General proofreading involves inspecting large volumes to correct segmentation errors at the pixel level, a visually intensive and time-consuming process. This paper presents the design and implementation of an analytics framework that streamlines proofreading, focusing on connectivity-related errors. We accomplish this with automated likely-error detection and synapse clustering that drives the proofreading effort with highly interactive 3D visualizations. In particular, our strategy centers on proofreading the local circuit of a single cell to ensure a basic level of completeness. We demonstrate our framework's utility with a user study and report quantitative and subjective feedback from our users. Overall, users find the framework more efficient for proofreading, understanding evolving graphs, and sharing error correction strategies.
PLM: Partial Label Masking for Imbalanced Multi-label Classification
May 22, 2021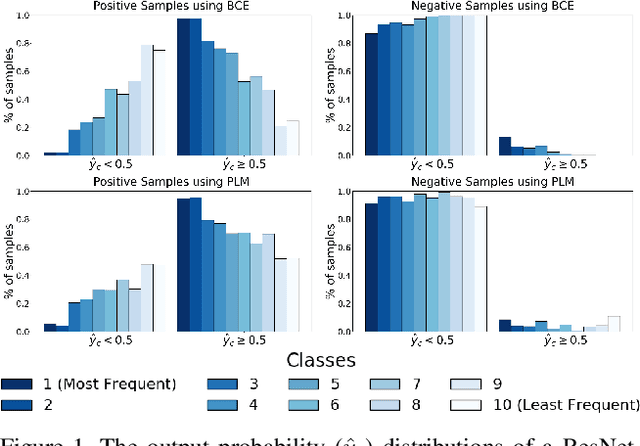
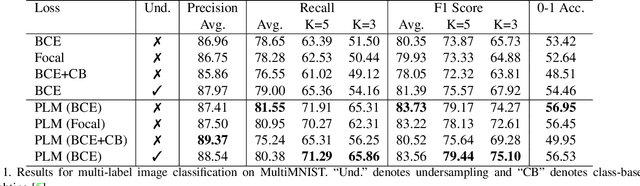
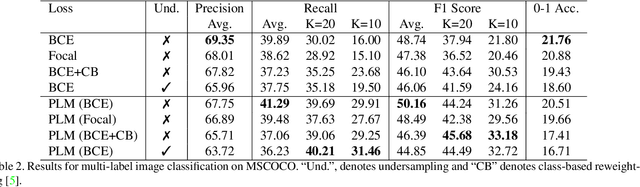
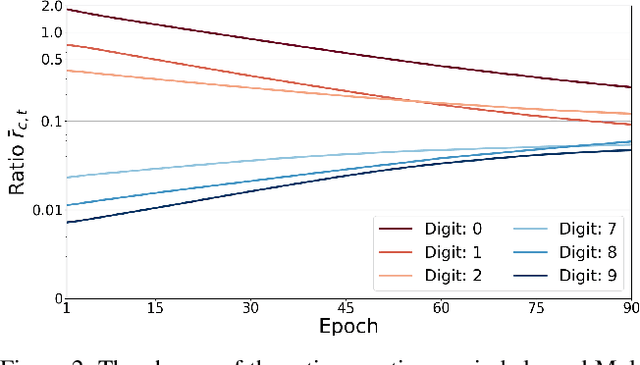
Neural networks trained on real-world datasets with long-tailed label distributions are biased towards frequent classes and perform poorly on infrequent classes. The imbalance in the ratio of positive and negative samples for each class skews network output probabilities further from ground-truth distributions. We propose a method, Partial Label Masking (PLM), which utilizes this ratio during training. By stochastically masking labels during loss computation, the method balances this ratio for each class, leading to improved recall on minority classes and improved precision on frequent classes. The ratio is estimated adaptively based on the network's performance by minimizing the KL divergence between predicted and ground-truth distributions. Whereas most existing approaches addressing data imbalance are mainly focused on single-label classification and do not generalize well to the multi-label case, this work proposes a general approach to solve the long-tail data imbalance issue for multi-label classification. PLM is versatile: it can be applied to most objective functions and it can be used alongside other strategies for class imbalance. Our method achieves strong performance when compared to existing methods on both multi-label (MultiMNIST and MSCOCO) and single-label (imbalanced CIFAR-10 and CIFAR-100) image classification datasets.
Unsupervised Metric Relocalization Using Transform Consistency Loss
Nov 01, 2020
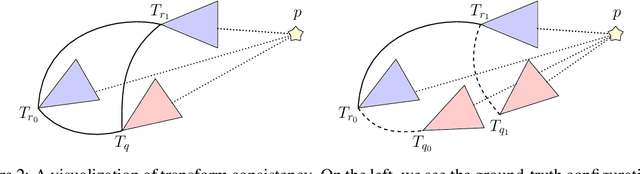
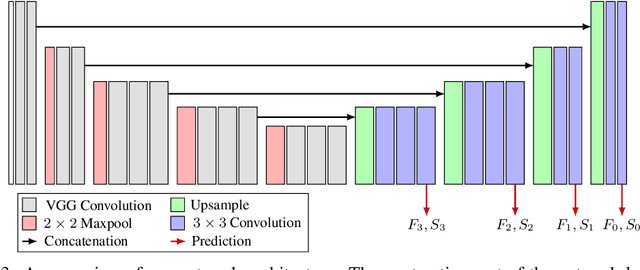
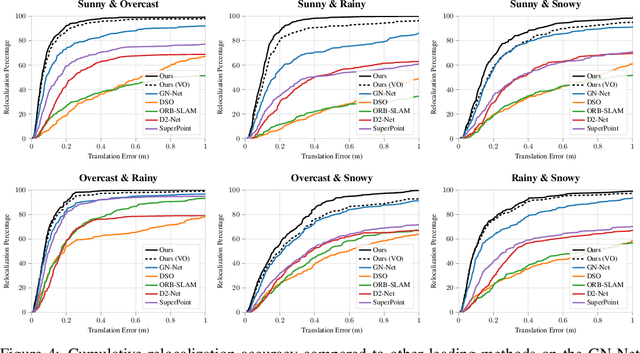
Training networks to perform metric relocalization traditionally requires accurate image correspondences. In practice, these are obtained by restricting domain coverage, employing additional sensors, or capturing large multi-view datasets. We instead propose a self-supervised solution, which exploits a key insight: localizing a query image within a map should yield the same absolute pose, regardless of the reference image used for registration. Guided by this intuition, we derive a novel transform consistency loss. Using this loss function, we train a deep neural network to infer dense feature and saliency maps to perform robust metric relocalization in dynamic environments. We evaluate our framework on synthetic and real-world data, showing our approach outperforms other supervised methods when a limited amount of ground-truth information is available.
Single Image Super-resolution via Dense Blended Attention Generative Adversarial Network for Clinical Diagnosis
Jun 15, 2019In clinical diagnosis, doctors are able to see biological tissues and early lesions more clearly with the assistance of high-resolution(HR) medical images, which is of vital significance for improving diagnosis accuracy. In order to address the issue that medical images would suffer from severe blurring caused by lack of high-frequency details, this paper develops a novel image super-resolution(SR) algorithm called SR-DBAN via dense neural network and blended attention mechanism. Specifically, a novel blended attention block is proposed and introduced to dense neural network(DenseNet), so that the neural network can concentrate more attention to the regions and channels with sufficient high-frequency details adaptively. In the framework of SR-DBAN, batch normalization layers in the original DenseNet are removed to avoid loss of high-frequency texture details, final HR images are obtained by deconvolution at the very end of the network. Furthermore, inspired by the impressive performance of generative adversarial network, this paper develops a novel image SR algorithm called SR-DBAGAN via dense blended attention generative adversarial network. SR-DBAGAN consists a generator and a discriminator, the generator uses our proposed SR-DBAN to generate HR images and try to fool the discriminator while the discriminator is designed based on Wasserstein GAN(WGAN) to discriminate. We deployed our algorithms on blurry prostate MRI images, and experimental results showed that our proposed algorithms have generated considerable sharpness and texture details and have a significant improvement on the peak signal-to-noise ratio(PSNR) and structural similarity index(SSIM), respectively, compared with mainstream interpolation-based and deep learning-based image SR algorithms, which fully proves the effectiveness and superiority of our proposed algorithms.
AMD Severity Prediction And Explainability Using Image Registration And Deep Embedded Clustering
Jul 06, 2019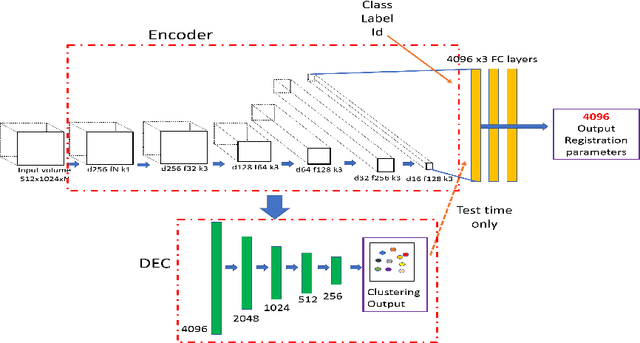
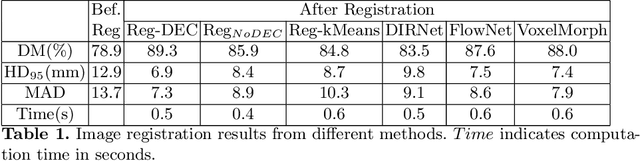
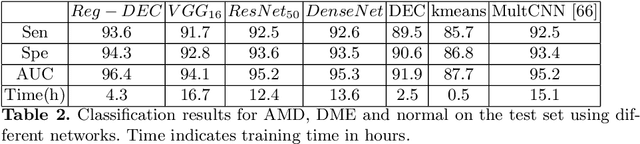
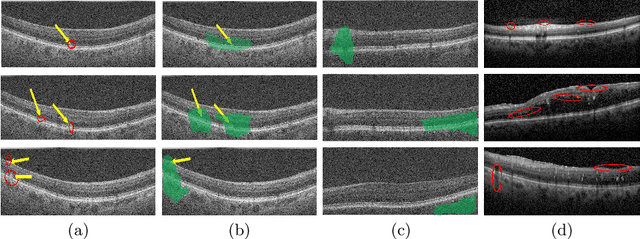
We propose a method to predict severity of age related macular degeneration (AMD) from input optical coherence tomography (OCT) images. Although there is no standard clinical severity scale for AMD, we leverage deep learning (DL) based image registration and clustering methods to identify diseased cases and predict their severity. Experiments demonstrate our approach's disease classification performance matches state of the art methods. The predicted disease severity performs well on previously unseen data. Registration output provides better explainability than class activation maps regarding label and severity decisions
Augmenting Images for ASR and TTS through Single-loop and Dual-loop Multimodal Chain Framework
Nov 04, 2020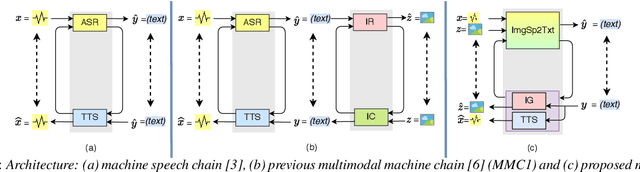
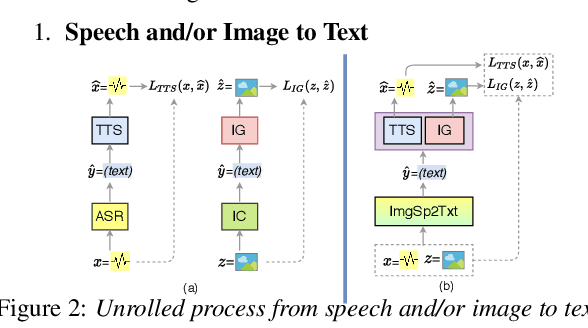
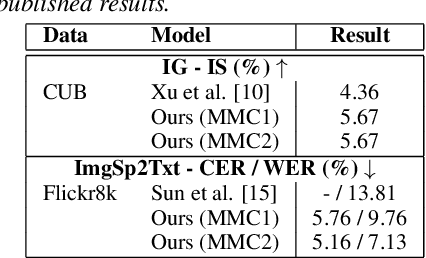
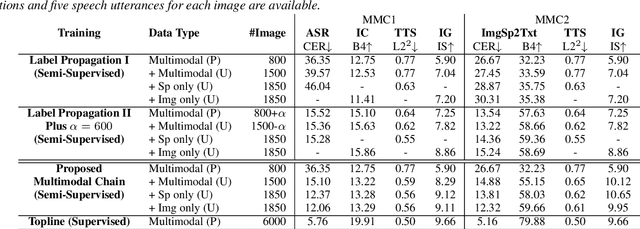
Previous research has proposed a machine speech chain to enable automatic speech recognition (ASR) and text-to-speech synthesis (TTS) to assist each other in semi-supervised learning and to avoid the need for a large amount of paired speech and text data. However, that framework still requires a large amount of unpaired (speech or text) data. A prototype multimodal machine chain was then explored to further reduce the need for a large amount of unpaired data, which could improve ASR or TTS even when no more speech or text data were available. Unfortunately, this framework relied on the image retrieval (IR) model, and thus it was limited to handling only those images that were already known during training. Furthermore, the performance of this framework was only investigated with single-speaker artificial speech data. In this study, we revamp the multimodal machine chain framework with image generation (IG) and investigate the possibility of augmenting image data for ASR and TTS using single-loop and dual-loop architectures on multispeaker natural speech data. Experimental results revealed that both single-loop and dual-loop multimodal chain frameworks enabled ASR and TTS to improve their performance using an image-only dataset.
DAN-Net: Dual-Domain Adaptive-Scaling Non-local Network for CT Metal Artifact Reduction
Feb 16, 2021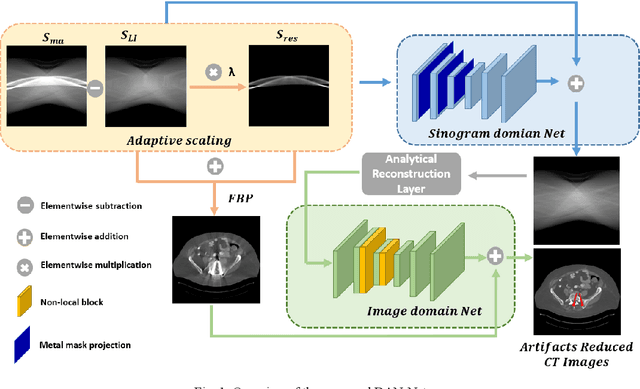
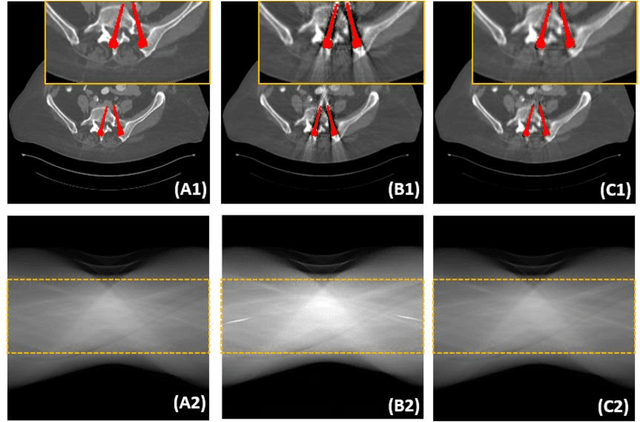
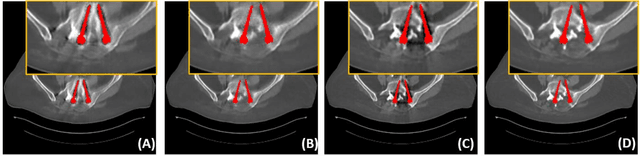
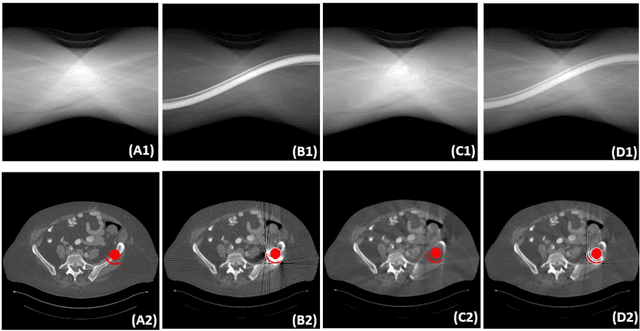
Metal implants can heavily attenuate X-rays in computed tomography (CT) scans, leading to severe artifacts in reconstructed images, which significantly jeopardize image quality and negatively impact subsequent diagnoses and treatment planning. With the rapid development of deep learning in the field of medical imaging, several network models have been proposed for metal artifact reduction (MAR) in CT. Despite the encouraging results achieved by these methods, there is still much room to further improve performance. In this paper, a novel Dual-domain Adaptive-scaling Non-local network (DAN-Net) for MAR. We correct the corrupted sinogram using adaptive scaling first to preserve more tissue and bone details as a more informative input. Then, an end-to-end dual-domain network is adopted to successively process the sinogram and its corresponding reconstructed image generated by the analytical reconstruction layer. In addition, to better suppress the existing artifacts and restrain the potential secondary artifacts caused by inaccurate results of the sinogram-domain network, a novel residual sinogram learning strategy and nonlocal module are leveraged in the proposed network model. In the experiments, the proposed DAN-Net demonstrates performance competitive with several state-of-the-art MAR methods in both qualitative and quantitative aspects.
Single Reference Image based Scene Relighting via Material Guided Filtering
Aug 23, 2017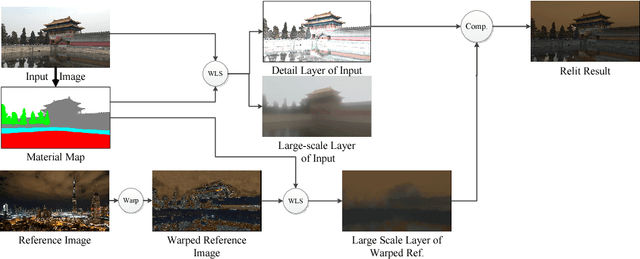


Image relighting is to change the illumination of an image to a target illumination effect without known the original scene geometry, material information and illumination condition. We propose a novel outdoor scene relighting method, which needs only a single reference image and is based on material constrained layer decomposition. Firstly, the material map is extracted from the input image. Then, the reference image is warped to the input image through patch match based image warping. Lastly, the input image is relit using material constrained layer decomposition. The experimental results reveal that our method can produce similar illumination effect as that of the reference image on the input image using only a single reference image.
Design of an Efficient, Ease-of-use and Affordable Artificial Intelligence based Nucleic Acid Amplification Diagnosis Technology for Tuberculosis and Multi-drug Resistant Tuberculosis
Apr 14, 2021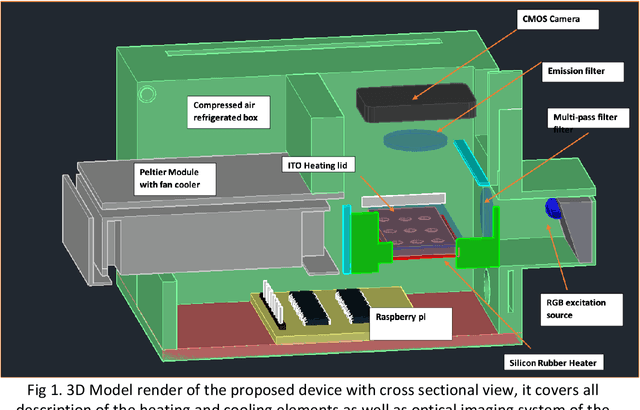
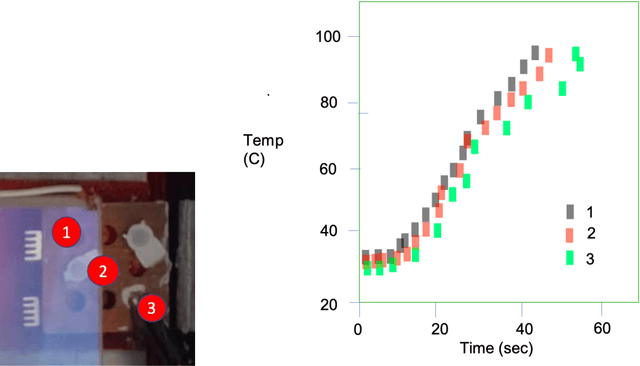
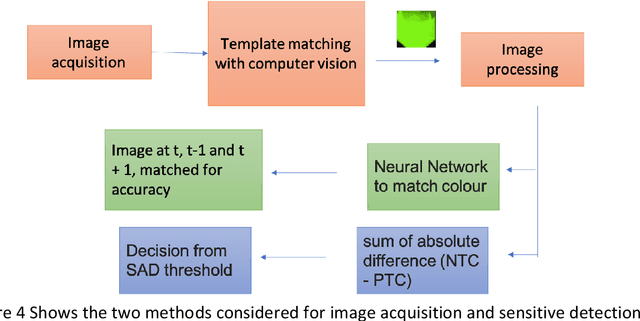
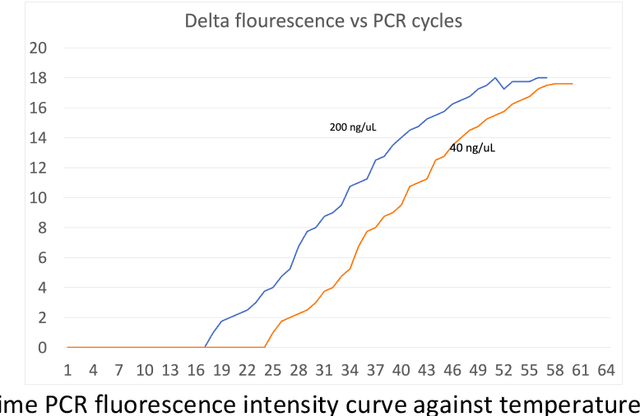
Current technologies that facilitate diagnosis for simultaneous detection of Mycobacterium tuberculosis and its resistance to first-line anti-tuberculosis drugs (Isoniazid and Rifampicim) are designed for lab-based settings and are unaffordable for large scale testing implementations. The suitability of a TB diagnosis instrument, generally required in low-resource settings, to be implementable in point-of-care last mile public health centres depends on manufacturing cost, ease-of-use, automation and portability. This paper discusses a portable, low-cost, machine learning automated Nucleic acid amplification testing (NAAT) device that employs the use of a smartphone-based fluorescence detection using novel image processing and chromaticity detection algorithms. To test the instrument, real time polymerase chain reaction (qPCR) experiment on cDNA dilution spanning over two concentrations (40 ng/uL and 200 ng/uL) was performed and sensitive detection of multiplexed positive control assay was verified.