 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEradicating Negative Transfer in Multi-Physics Foundation Models via Sparse Mixture-of-Experts Routing
May 14, 2026Scaling Scientific Machine Learning (SciML) toward universal foundation models is bottlenecked by negative transfer: the simultaneous co-training of disparate partial differential equation (PDE) regimes can induce gradient conflict, unstable optimization, and plasticity loss in dense neural operators. In particular, broadband open-channel fluid dynamics and boundary-dominated porous media flows impose incompatible spectral and geometric demands on a single dense parameter path. We introduce Shodh-MoE, a sparse-activated latent transformer architecture for multi-physics transport. Shodh-MoE operates on compressed 16^3 physical latents produced by a physics-informed autoencoder with an intra-tokenizer Helmholtz-style velocity parameterization, restricting decoded states to divergence-free velocity manifolds. The model guarantees exact mass conservation, achieving a physically verifiable velocity divergence of ~2.8 x 10^-10 (evaluated post-hoc in FP64) on 128^3 grids. A Top-1 soft-semantic router dynamically assigns localized latent patches to expert subnetworks, enabling specialized parameter paths for distinct physical mechanisms while preserving shared experts for universal symmetries. In a 20,000-step distributed pretraining run over mixed three-dimensional physical tensors, routing telemetry shows autonomous domain bifurcation: held-out validation tokens from the open-channel domain route exclusively to Expert 0, while porous-media tokens route exclusively to Expert 1. The model converges simultaneously across both regimes, achieving latent validation MSEs of 2.46 x 10^-5 and 9.76 x 10^-6, and decoded physical MSEs of 2.48 x 10^-6 and 1.76 x 10^-6. These results support sparse expert routing as a practical architectural mechanism for mitigating multi-physics interference in universal neural operators.
Can LLMs Compute with Reasons?
Feb 19, 2024



Large language models (LLMs) often struggle with complex mathematical tasks, prone to "hallucinating" incorrect answers due to their reliance on statistical patterns. This limitation is further amplified in average Small LangSLMs with limited context and training data. To address this challenge, we propose an "Inductive Learning" approach utilizing a distributed network of SLMs. This network leverages error-based learning and hint incorporation to refine the reasoning capabilities of SLMs. Our goal is to provide a framework that empowers SLMs to approach the level of logic-based applications achieved by high-parameter models, potentially benefiting any language model. Ultimately, this novel concept paves the way for bridging the logical gap between humans and LLMs across various fields.
Design of an Efficient, Ease-of-use and Affordable Artificial Intelligence based Nucleic Acid Amplification Diagnosis Technology for Tuberculosis and Multi-drug Resistant Tuberculosis
Apr 14, 2021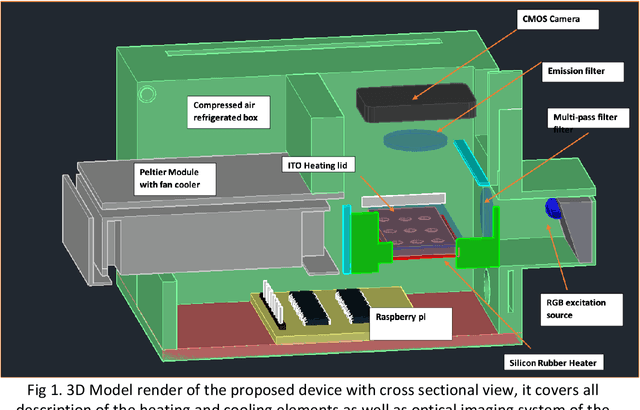
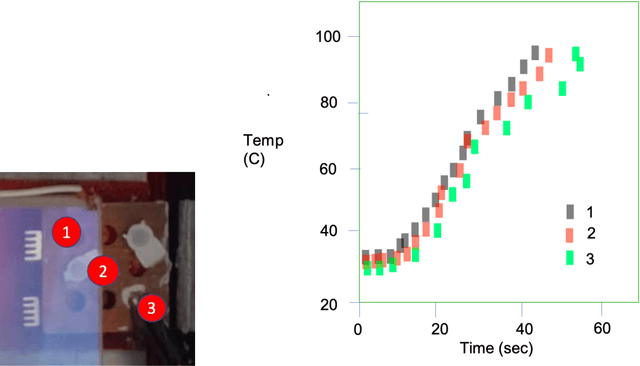
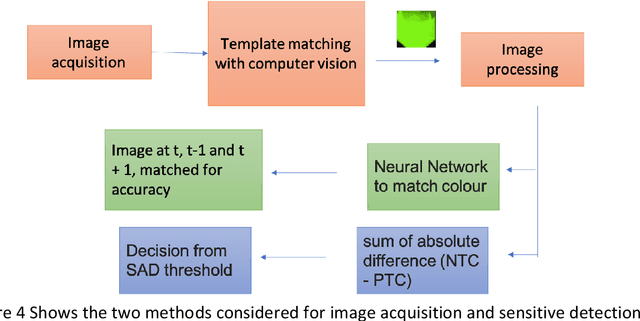
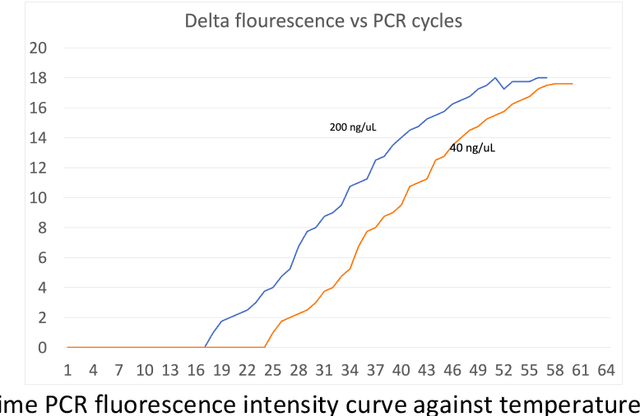
Current technologies that facilitate diagnosis for simultaneous detection of Mycobacterium tuberculosis and its resistance to first-line anti-tuberculosis drugs (Isoniazid and Rifampicim) are designed for lab-based settings and are unaffordable for large scale testing implementations. The suitability of a TB diagnosis instrument, generally required in low-resource settings, to be implementable in point-of-care last mile public health centres depends on manufacturing cost, ease-of-use, automation and portability. This paper discusses a portable, low-cost, machine learning automated Nucleic acid amplification testing (NAAT) device that employs the use of a smartphone-based fluorescence detection using novel image processing and chromaticity detection algorithms. To test the instrument, real time polymerase chain reaction (qPCR) experiment on cDNA dilution spanning over two concentrations (40 ng/uL and 200 ng/uL) was performed and sensitive detection of multiplexed positive control assay was verified.