 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePLM: Partial Label Masking for Imbalanced Multi-label Classification
Paper and Code
May 22, 2021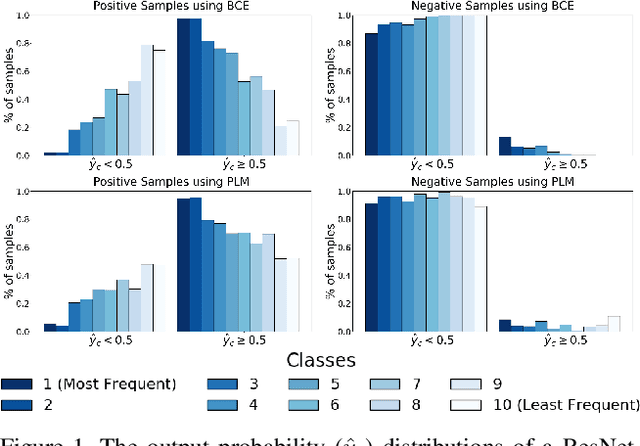
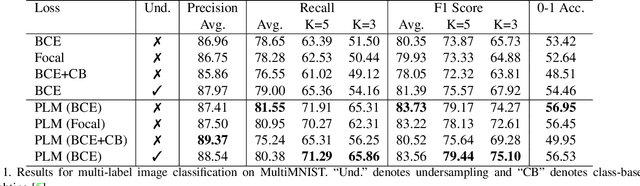
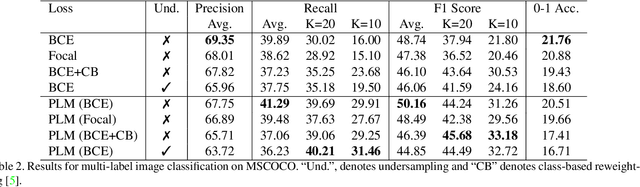
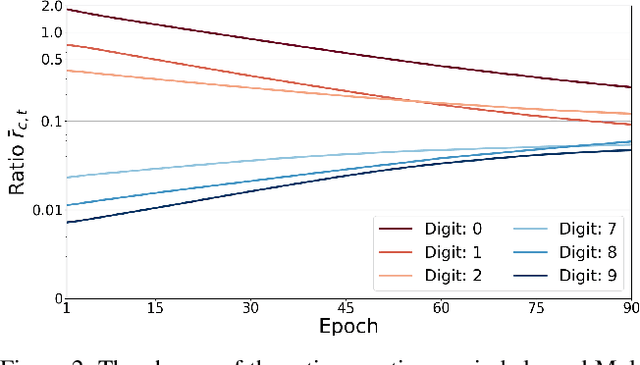
Neural networks trained on real-world datasets with long-tailed label distributions are biased towards frequent classes and perform poorly on infrequent classes. The imbalance in the ratio of positive and negative samples for each class skews network output probabilities further from ground-truth distributions. We propose a method, Partial Label Masking (PLM), which utilizes this ratio during training. By stochastically masking labels during loss computation, the method balances this ratio for each class, leading to improved recall on minority classes and improved precision on frequent classes. The ratio is estimated adaptively based on the network's performance by minimizing the KL divergence between predicted and ground-truth distributions. Whereas most existing approaches addressing data imbalance are mainly focused on single-label classification and do not generalize well to the multi-label case, this work proposes a general approach to solve the long-tail data imbalance issue for multi-label classification. PLM is versatile: it can be applied to most objective functions and it can be used alongside other strategies for class imbalance. Our method achieves strong performance when compared to existing methods on both multi-label (MultiMNIST and MSCOCO) and single-label (imbalanced CIFAR-10 and CIFAR-100) image classification datasets.