 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Leveraging EfficientNet and Contrastive Learning for Accurate Global-scale Location Estimation
May 17, 2021
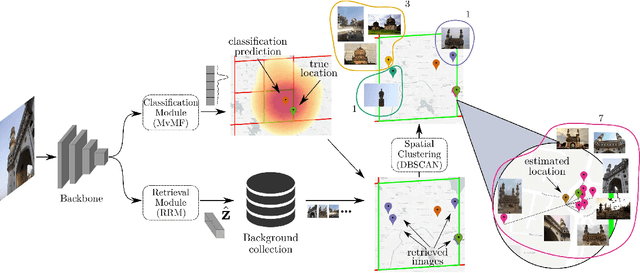
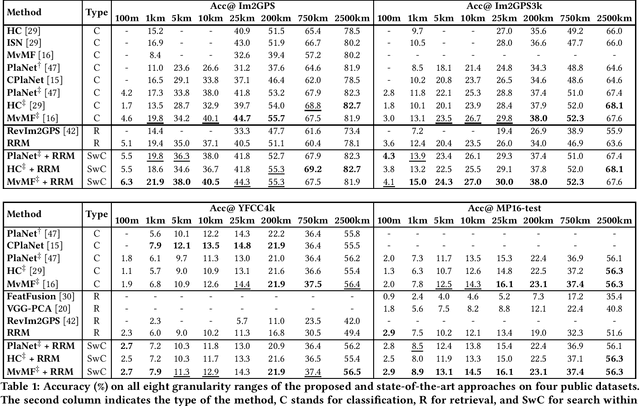
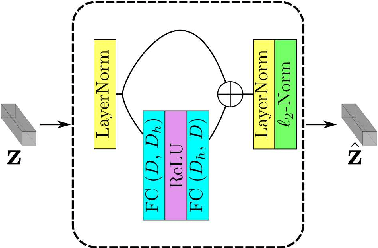
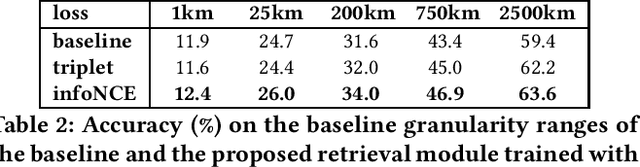
In this paper, we address the problem of global-scale image geolocation, proposing a mixed classification-retrieval scheme. Unlike other methods that strictly tackle the problem as a classification or retrieval task, we combine the two practices in a unified solution leveraging the advantages of each approach with two different modules. The first leverages the EfficientNet architecture to assign images to a specific geographic cell in a robust way. The second introduces a new residual architecture that is trained with contrastive learning to map input images to an embedding space that minimizes the pairwise geodesic distance of same-location images. For the final location estimation, the two modules are combined with a search-within-cell scheme, where the locations of most similar images from the predicted geographic cell are aggregated based on a spatial clustering scheme. Our approach demonstrates very competitive performance on four public datasets, achieving new state-of-the-art performance in fine granularity scales, i.e., 15.0% at 1km range on Im2GPS3k.
A Residual Network based Deep Learning Model for Detection of COVID-19 from Cough Sounds
Jun 04, 2021
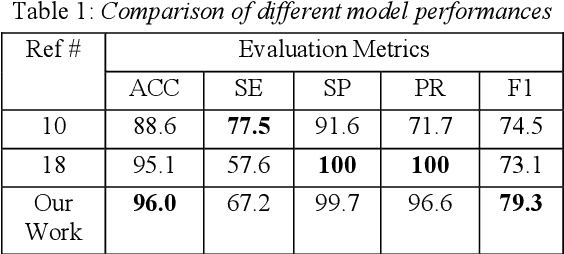
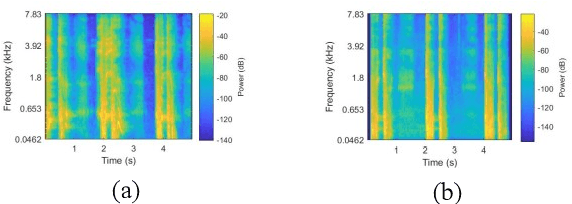
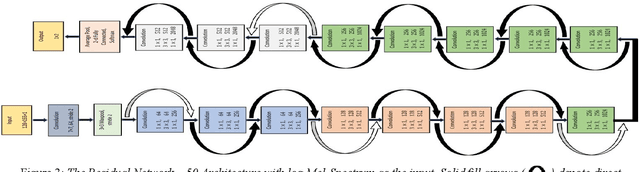
The present work proposes a deep-learning-based approach for the classification of COVID-19 coughs from non-COVID-19 coughs and that can be used as a low-resource-based tool for early detection of the onset of such respiratory diseases. The proposed system uses the ResNet-50 architecture, a popularly known Convolutional Neural Network (CNN) for image recognition tasks, fed with the log-Mel spectrums of the audio data to discriminate between the two types of coughs. For the training and validation of the proposed deep learning model, this work utilizes the Track-1 dataset provided by the DiCOVA Challenge 2021 organizers. Additionally, to increase the number of COVID-positive samples and to enhance variability in the training data, it has also utilized a large open-source database of COVID-19 coughs collected by the EPFL CoughVid team. Our developed model has achieved an average validation AUC of 98.88%. Also, applying this model on the Blind Test Set released by the DiCOVA Challenge, the system has achieved a Test AUC of 75.91%, Test Specificity of 62.50%, and Test Sensitivity of 80.49%. Consequently, this submission has secured 16th position in the DiCOVA Challenge 2021 leader-board.
TabLeX: A Benchmark Dataset for Structure and Content Information Extraction from Scientific Tables
May 12, 2021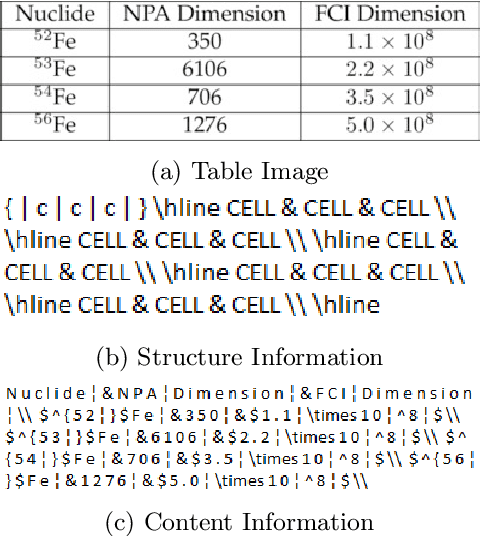
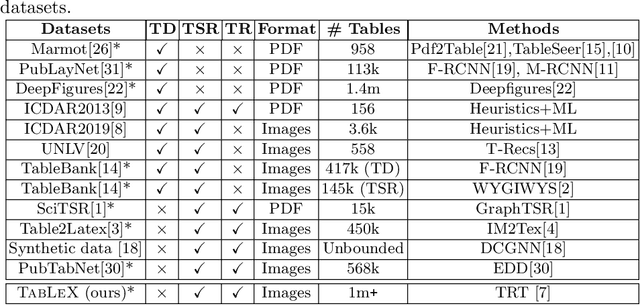
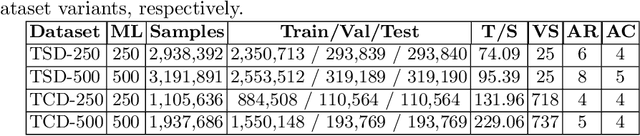
Information Extraction (IE) from the tables present in scientific articles is challenging due to complicated tabular representations and complex embedded text. This paper presents TabLeX, a large-scale benchmark dataset comprising table images generated from scientific articles. TabLeX consists of two subsets, one for table structure extraction and the other for table content extraction. Each table image is accompanied by its corresponding LATEX source code. To facilitate the development of robust table IE tools, TabLeX contains images in different aspect ratios and in a variety of fonts. Our analysis sheds light on the shortcomings of current state-of-the-art table extraction models and shows that they fail on even simple table images. Towards the end, we experiment with a transformer-based existing baseline to report performance scores. In contrast to the static benchmarks, we plan to augment this dataset with more complex and diverse tables at regular intervals.
Learning Invariant Representations across Domains and Tasks
Mar 03, 2021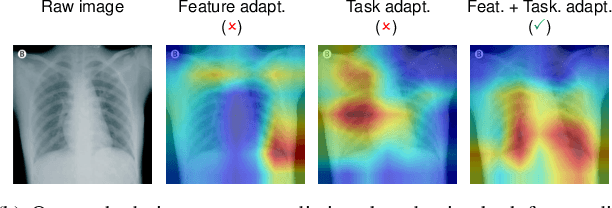
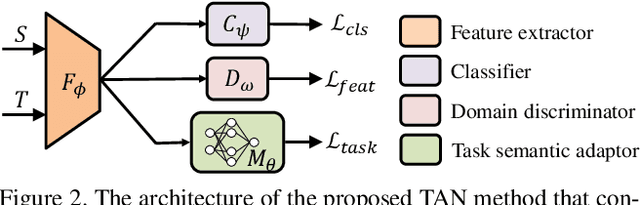
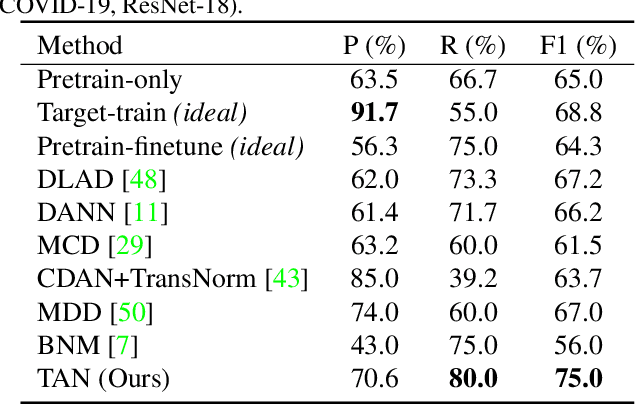
Being expensive and time-consuming to collect massive COVID-19 image samples to train deep classification models, transfer learning is a promising approach by transferring knowledge from the abundant typical pneumonia datasets for COVID-19 image classification. However, negative transfer may deteriorate the performance due to the feature distribution divergence between two datasets and task semantic difference in diagnosing pneumonia and COVID-19 that rely on different characteristics. It is even more challenging when the target dataset has no labels available, i.e., unsupervised task transfer learning. In this paper, we propose a novel Task Adaptation Network (TAN) to solve this unsupervised task transfer problem. In addition to learning transferable features via domain-adversarial training, we propose a novel task semantic adaptor that uses the learning-to-learn strategy to adapt the task semantics. Experiments on three public COVID-19 datasets demonstrate that our proposed method achieves superior performance. Especially on COVID-DA dataset, TAN significantly increases the recall and F1 score by 5.0% and 7.8% compared to recently strong baselines. Moreover, we show that TAN also achieves superior performance on several public domain adaptation benchmarks.
Brain over Brawn -- Using a Stereo Camera to Detect, Track and Intercept a Faster UAV by Reconstructing Its Trajectory
Jul 02, 2021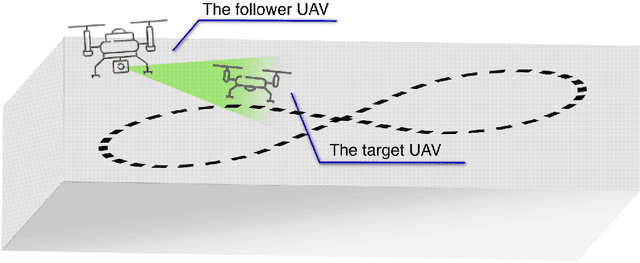
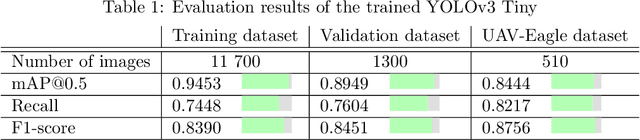

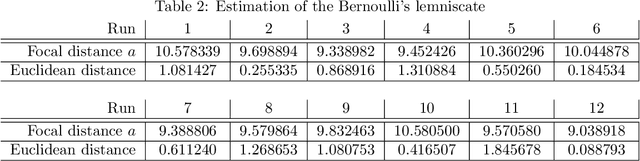
The work presented in this paper demonstrates our approach to intercepting a faster intruder UAV, inspired by the MBZIRC2020 Challenge 1. By leveraging the knowledge of the shape of the intruder's trajectory we are able to calculate the interception point. Target tracking is based on image processing by a YOLOv3 Tiny convolutional neural network, combined with depth calculation using a gimbal-mounted ZED Mini stereo camera. We use RGB and depth data from ZED Mini to extract the 3D position of the target, for which we devise a histogram-of-depth based processing to reduce noise. Obtained 3D measurements of target's position are used to calculate the position, the orientation and the size of a figure-eight shaped trajectory, which we approximate using lemniscate of Bernoulli. Once the approximation is deemed sufficiently precise, measured by Hausdorff distance between measurements and the approximation, an interception point is calculated to position the intercepting UAV right on the path of the target. The proposed method, which has been significantly improved based on the experience gathered during the MBZIRC competition, has been validated in simulation and through field experiments. The results confirmed that an efficient visual perception module which extracts information related to the motion of the target UAV as a basis for the interception, has been developed. The system is able to track and intercept the target which is 30% faster than the interceptor in majority of simulation experiments. Tests in the unstructured environment yielded 9 out of 12 successful results.
Deep Image Retrieval: Learning global representations for image search
Jul 28, 2016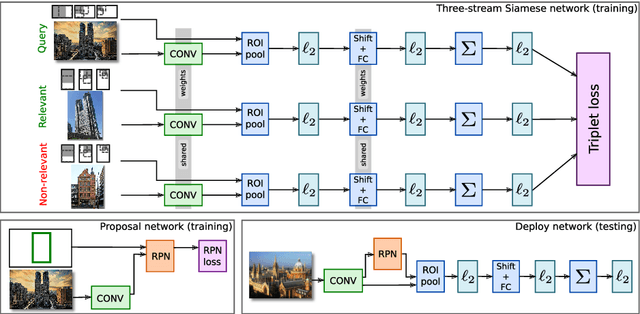
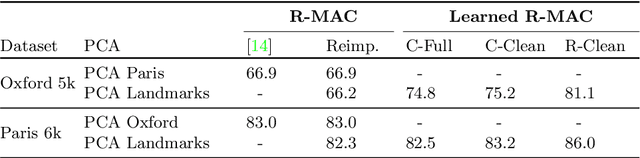
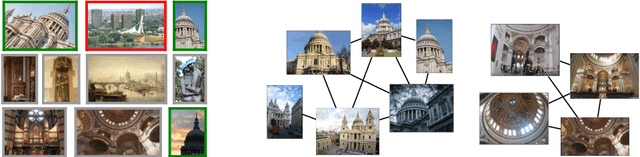
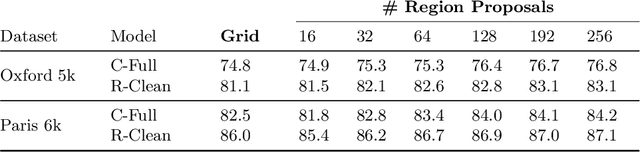
We propose a novel approach for instance-level image retrieval. It produces a global and compact fixed-length representation for each image by aggregating many region-wise descriptors. In contrast to previous works employing pre-trained deep networks as a black box to produce features, our method leverages a deep architecture trained for the specific task of image retrieval. Our contribution is twofold: (i) we leverage a ranking framework to learn convolution and projection weights that are used to build the region features; and (ii) we employ a region proposal network to learn which regions should be pooled to form the final global descriptor. We show that using clean training data is key to the success of our approach. To that aim, we use a large scale but noisy landmark dataset and develop an automatic cleaning approach. The proposed architecture produces a global image representation in a single forward pass. Our approach significantly outperforms previous approaches based on global descriptors on standard datasets. It even surpasses most prior works based on costly local descriptor indexing and spatial verification. Additional material is available at www.xrce.xerox.com/Deep-Image-Retrieval.
Tagging like Humans: Diverse and Distinct Image Annotation
Mar 31, 2018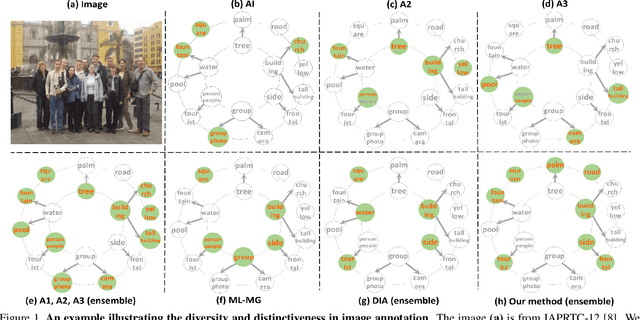
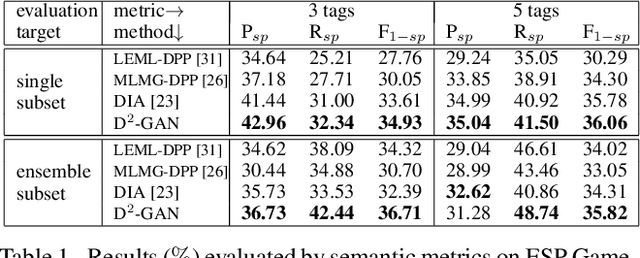
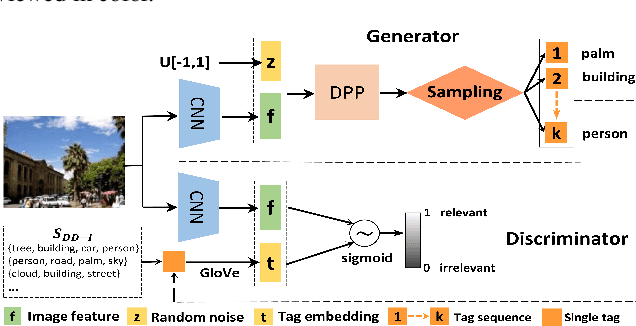
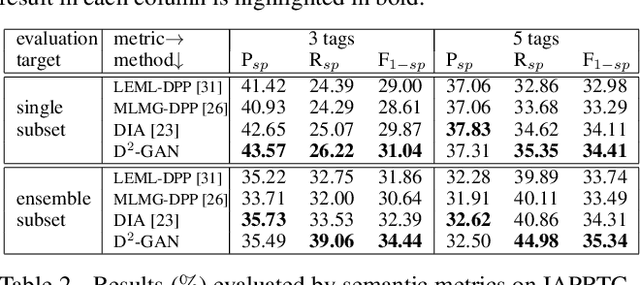
In this work we propose a new automatic image annotation model, dubbed {\bf diverse and distinct image annotation} (D2IA). The generative model D2IA is inspired by the ensemble of human annotations, which create semantically relevant, yet distinct and diverse tags. In D2IA, we generate a relevant and distinct tag subset, in which the tags are relevant to the image contents and semantically distinct to each other, using sequential sampling from a determinantal point process (DPP) model. Multiple such tag subsets that cover diverse semantic aspects or diverse semantic levels of the image contents are generated by randomly perturbing the DPP sampling process. We leverage a generative adversarial network (GAN) model to train D2IA. Extensive experiments including quantitative and qualitative comparisons, as well as human subject studies, on two benchmark datasets demonstrate that the proposed model can produce more diverse and distinct tags than the state-of-the-arts.
Re-labeling ImageNet: from Single to Multi-Labels, from Global to Localized Labels
Jan 13, 2021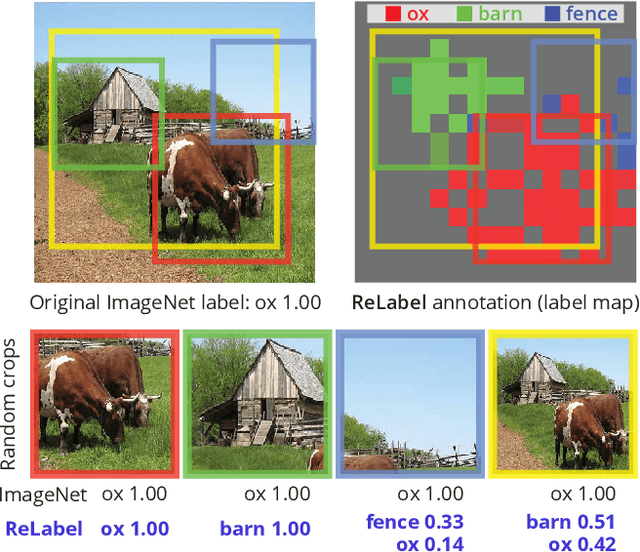

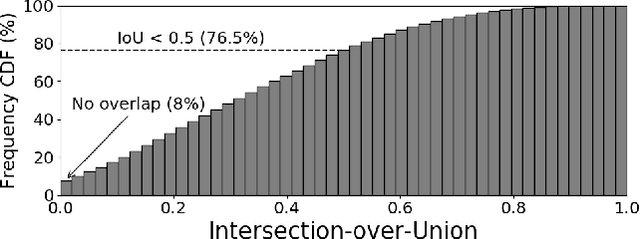

ImageNet has been arguably the most popular image classification benchmark, but it is also the one with a significant level of label noise. Recent studies have shown that many samples contain multiple classes, despite being assumed to be a single-label benchmark. They have thus proposed to turn ImageNet evaluation into a multi-label task, with exhaustive multi-label annotations per image. However, they have not fixed the training set, presumably because of a formidable annotation cost. We argue that the mismatch between single-label annotations and effectively multi-label images is equally, if not more, problematic in the training setup, where random crops are applied. With the single-label annotations, a random crop of an image may contain an entirely different object from the ground truth, introducing noisy or even incorrect supervision during training. We thus re-label the ImageNet training set with multi-labels. We address the annotation cost barrier by letting a strong image classifier, trained on an extra source of data, generate the multi-labels. We utilize the pixel-wise multi-label predictions before the final pooling layer, in order to exploit the additional location-specific supervision signals. Training on the re-labeled samples results in improved model performances across the board. ResNet-50 attains the top-1 classification accuracy of 78.9% on ImageNet with our localized multi-labels, which can be further boosted to 80.2% with the CutMix regularization. We show that the models trained with localized multi-labels also outperforms the baselines on transfer learning to object detection and instance segmentation tasks, and various robustness benchmarks. The re-labeled ImageNet training set, pre-trained weights, and the source code are available at {https://github.com/naver-ai/relabel_imagenet}.
Classifying Video based on Automatic Content Detection Overview
Mar 29, 2021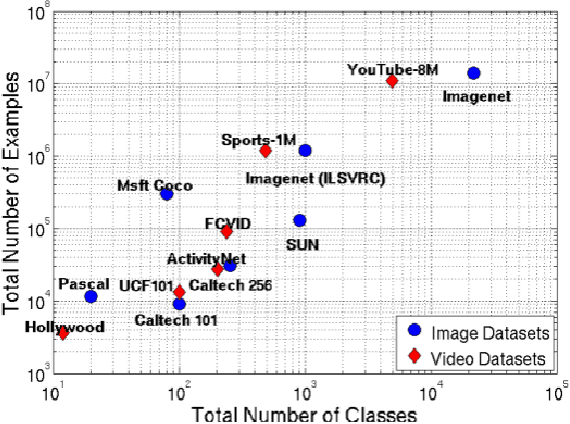
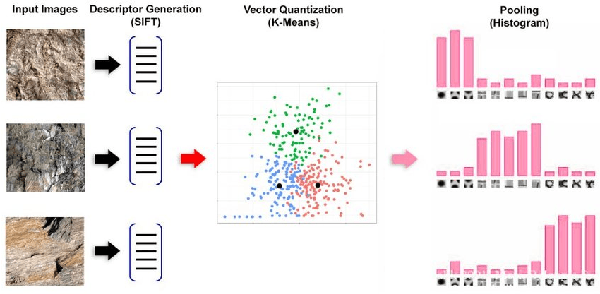
Video classification and analysis is always a popular and challenging field in computer vision. It is more than just simple image classification due to the correlation with respect to the semantic contents of subsequent frames brings difficulties for video analysis. In this literature review, we summarized some state-of-the-art methods for multi-label video classification. Our goal is first to experimentally research the current widely used architectures, and then to develop a method to deal with the sequential data of frames and perform multi-label classification based on automatic content detection of video.
Computer-Aided Design as Language
May 06, 2021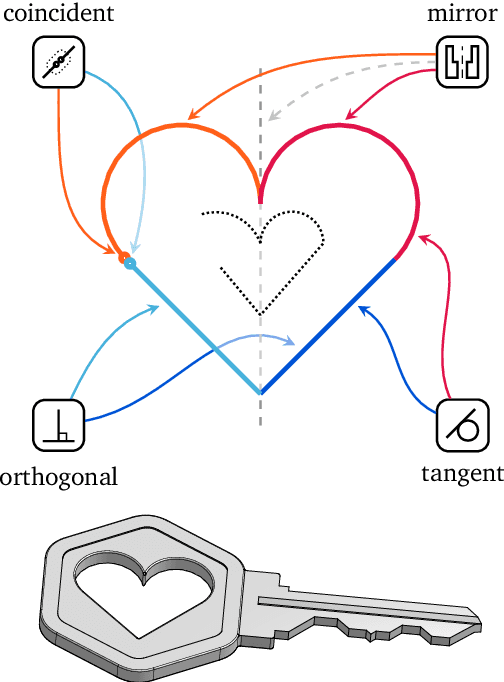
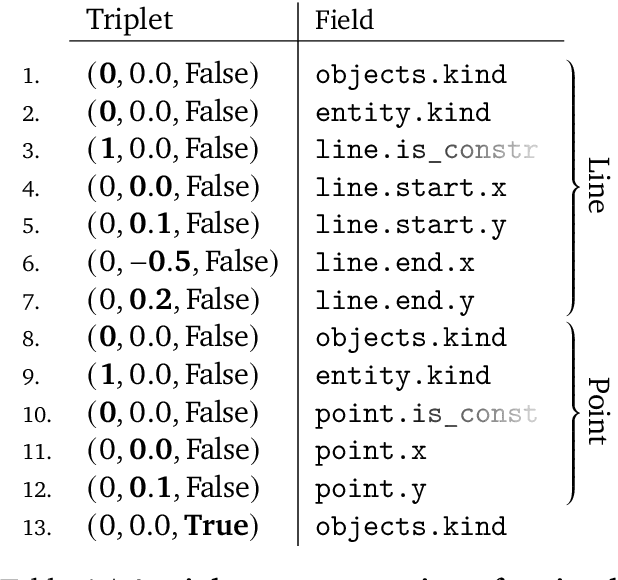
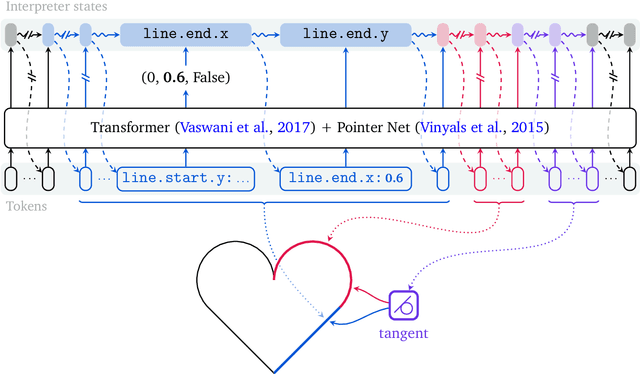
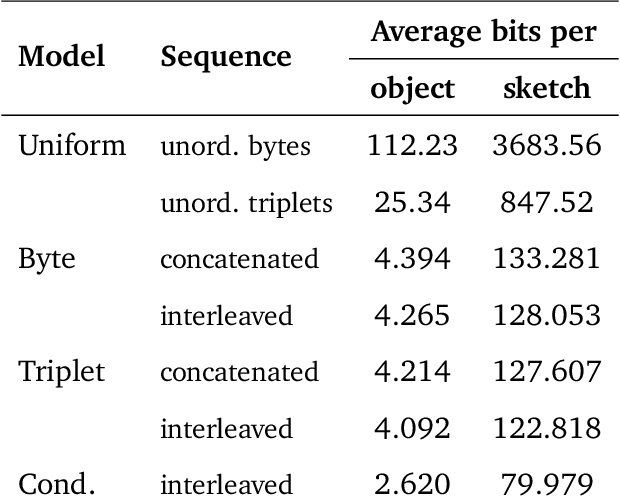
Computer-Aided Design (CAD) applications are used in manufacturing to model everything from coffee mugs to sports cars. These programs are complex and require years of training and experience to master. A component of all CAD models particularly difficult to make are the highly structured 2D sketches that lie at the heart of every 3D construction. In this work, we propose a machine learning model capable of automatically generating such sketches. Through this, we pave the way for developing intelligent tools that would help engineers create better designs with less effort. Our method is a combination of a general-purpose language modeling technique alongside an off-the-shelf data serialization protocol. We show that our approach has enough flexibility to accommodate the complexity of the domain and performs well for both unconditional synthesis and image-to-sketch translation.