 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
nnDetection: A Self-configuring Method for Medical Object Detection
Jun 01, 2021
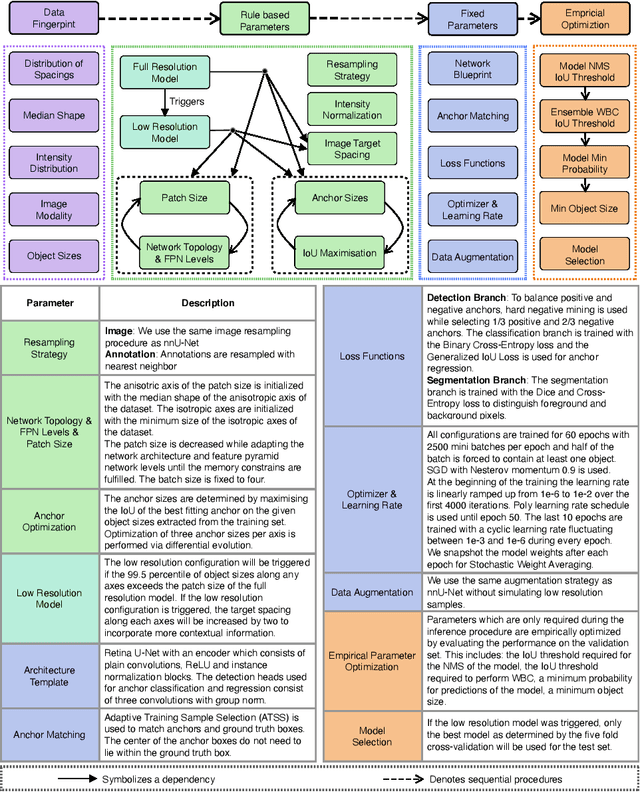
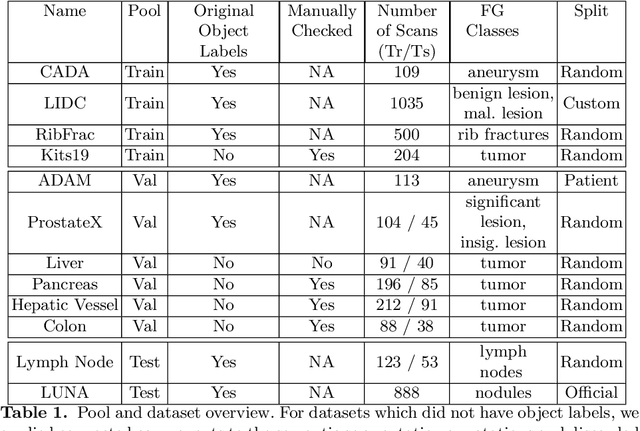
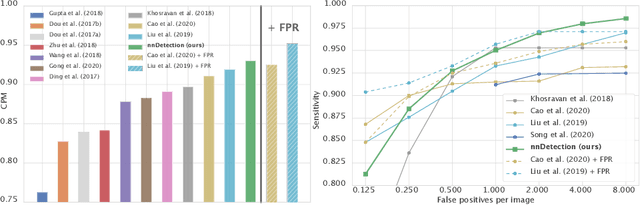
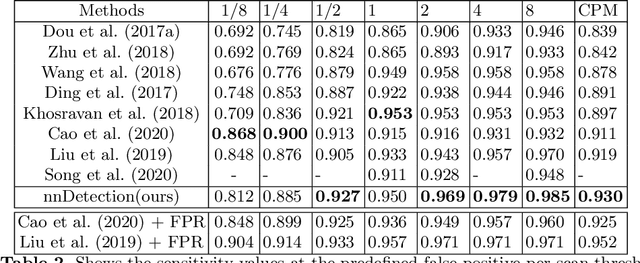
Simultaneous localisation and categorization of objects in medical images, also referred to as medical object detection, is of high clinical relevance because diagnostic decisions often depend on rating of objects rather than e.g. pixels. For this task, the cumbersome and iterative process of method configuration constitutes a major research bottleneck. Recently, nnU-Net has tackled this challenge for the task of image segmentation with great success. Following nnU-Net's agenda, in this work we systematize and automate the configuration process for medical object detection. The resulting self-configuring method, nnDetection, adapts itself without any manual intervention to arbitrary medical detection problems while achieving results en par with or superior to the state-of-the-art. We demonstrate the effectiveness of nnDetection on two public benchmarks, ADAM and LUNA16, and propose 10 further medical object detection tasks on public data sets for comprehensive method evaluation. Code is at https://github.com/MIC-DKFZ/nnDetection .
M2TR: Multi-modal Multi-scale Transformers for Deepfake Detection
Apr 21, 2021
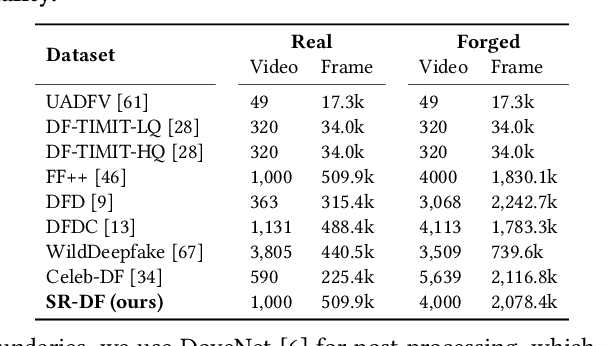
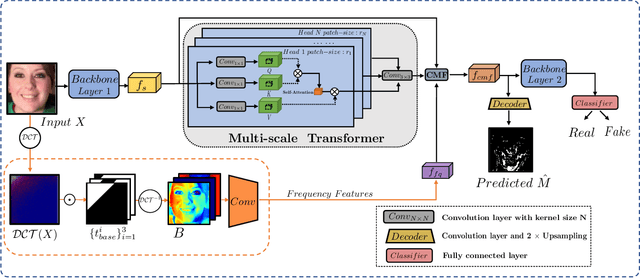
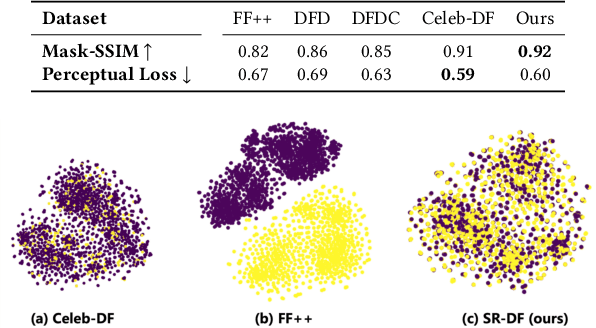
The widespread dissemination of forged images generated by Deepfake techniques has posed a serious threat to the trustworthiness of digital information. This demands effective approaches that can detect perceptually convincing Deepfakes generated by advanced manipulation techniques. Most existing approaches combat Deepfakes with deep neural networks by mapping the input image to a binary prediction without capturing the consistency among different pixels. In this paper, we aim to capture the subtle manipulation artifacts at different scales for Deepfake detection. We achieve this with transformer models, which have recently demonstrated superior performance in modeling dependencies between pixels for a variety of recognition tasks in computer vision. In particular, we introduce a Multi-modal Multi-scale TRansformer (M2TR), which uses a multi-scale transformer that operates on patches of different sizes to detect the local inconsistency at different spatial levels. To improve the detection results and enhance the robustness of our method to image compression, M2TR also takes frequency information, which is further combined with RGB features using a cross modality fusion module. Developing and evaluating Deepfake detection methods requires large-scale datasets. However, we observe that samples in existing benchmarks contain severe artifacts and lack diversity. This motivates us to introduce a high-quality Deepfake dataset, SR-DF, which consists of 4,000 DeepFake videos generated by state-of-the-art face swapping and facial reenactment methods. On three Deepfake datasets, we conduct extensive experiments to verify the effectiveness of the proposed method, which outperforms state-of-the-art Deepfake detection methods.
Self-Trained One-class Classification for Unsupervised Anomaly Detection
Jun 11, 2021
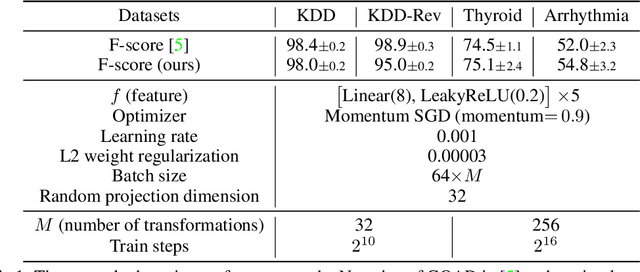
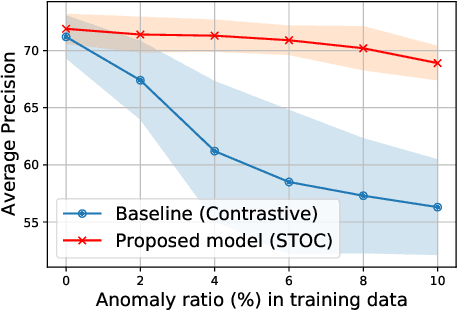
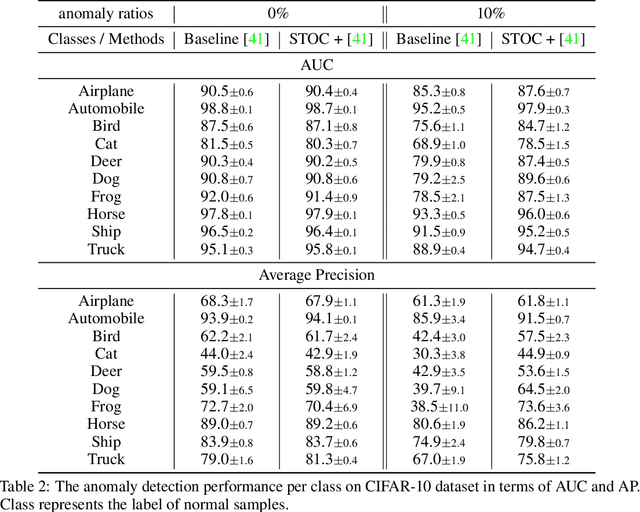
Anomaly detection (AD), separating anomalies from normal data, has various applications across domains, from manufacturing to healthcare. While most previous works have shown to be effective for cases with fully or partially labeled data, they are less practical for AD applications due to tedious data labeling processes. In this work, we focus on unsupervised AD problems whose entire training data are unlabeled and may contain both normal and anomalous samples. To tackle this problem, we build a robust one-class classification framework via data refinement. To refine the data accurately, we propose an ensemble of one-class classifiers, each of which is trained on a disjoint subset of training data. Moreover, we propose a self-training of deep representation one-class classifiers (STOC) that iteratively refines the data and deep representations. In experiments, we show the efficacy of our method for unsupervised anomaly detection on benchmarks from image and tabular data domains. For example, with a 10% anomaly ratio on CIFAR-10 data, the proposed method outperforms state-of-the-art one-class classification method by 6.3 AUC and 12.5 average precision.
Semi-supervised Semantic Segmentation with Directional Context-aware Consistency
Jun 27, 2021
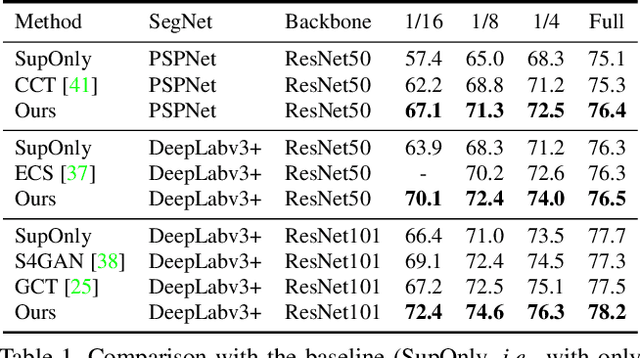
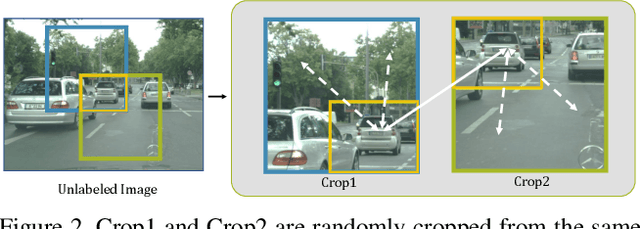
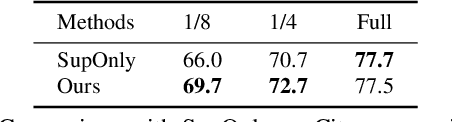
Semantic segmentation has made tremendous progress in recent years. However, satisfying performance highly depends on a large number of pixel-level annotations. Therefore, in this paper, we focus on the semi-supervised segmentation problem where only a small set of labeled data is provided with a much larger collection of totally unlabeled images. Nevertheless, due to the limited annotations, models may overly rely on the contexts available in the training data, which causes poor generalization to the scenes unseen before. A preferred high-level representation should capture the contextual information while not losing self-awareness. Therefore, we propose to maintain the context-aware consistency between features of the same identity but with different contexts, making the representations robust to the varying environments. Moreover, we present the Directional Contrastive Loss (DC Loss) to accomplish the consistency in a pixel-to-pixel manner, only requiring the feature with lower quality to be aligned towards its counterpart. In addition, to avoid the false-negative samples and filter the uncertain positive samples, we put forward two sampling strategies. Extensive experiments show that our simple yet effective method surpasses current state-of-the-art methods by a large margin and also generalizes well with extra image-level annotations.
GuideMe: A Mobile Application based on Global Positioning System and Object Recognition Towards a Smart Tourist Guide
May 27, 2021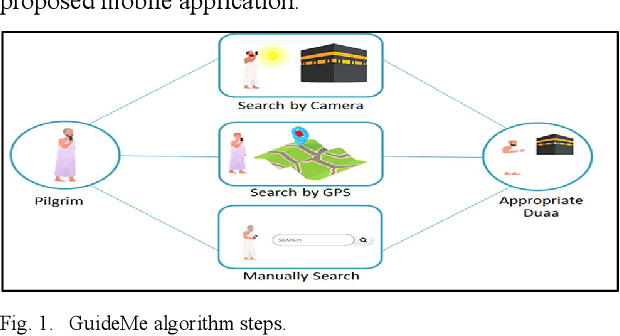



Finding information about tourist places to visit is a challenging problem that people face while visiting different countries. This problem is accentuated when people are coming from different countries, speak different languages, and are from all segments of society. In this context, visitors and pilgrims face important problems to find the appropriate doaas when visiting holy places. In this paper, we propose a mobile application that helps the user find the appropriate doaas for a given holy place in an easy and intuitive manner. Three different options are developed to achieve this goal: 1) manual search, 2) GPS location to identify the holy places and therefore their corresponding doaas, and 3) deep learning (DL) based method to determine the holy place by analyzing an image taken by the visitor. Experiments show good performance of the proposed mobile application in providing the appropriate doaas for visited holy places.
Museum Painting Retrieval
May 11, 2021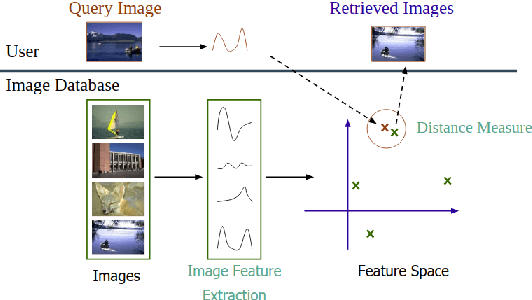

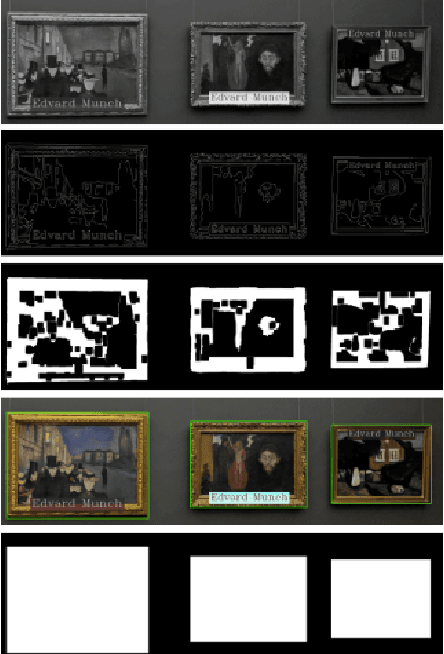

To retrieve images based on their content is one of the most studied topics in the field of computer vision. Nowadays, this problem can be addressed using modern techniques such as feature extraction using machine learning, but over the years different classical methods have been developed. In this paper, we implement a query by example retrieval system for finding paintings in a museum image collection using classic computer vision techniques. Specifically, we study the performance of the color, texture, text and feature descriptors in datasets with different perturbations in the images: noise, overlapping text boxes, color corruption and rotation. We evaluate each of the cases using the Mean Average Precision (MAP) metric, and we obtain results that vary between 0.5 and 1.0 depending on the problem conditions.
Using Scene Graph Context to Improve Image Generation
Jan 15, 2019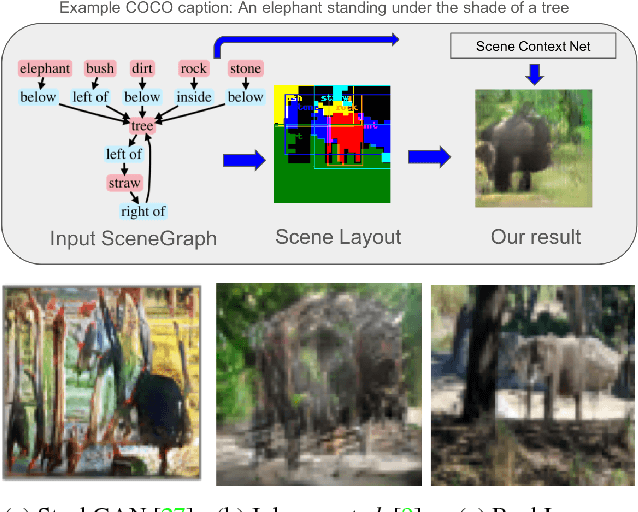

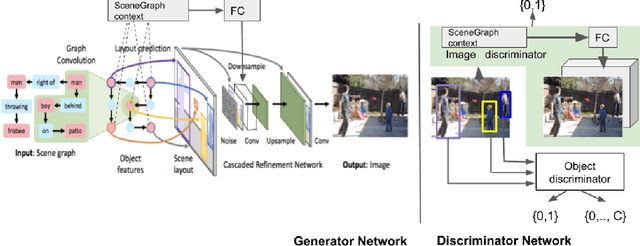

Generating realistic images from scene graphs asks neural networks to be able to reason about object relationships and compositionality. As a relatively new task, how to properly ensure the generated images comply with scene graphs or how to measure task performance remains an open question. In this paper, we propose to harness scene graph context to improve image generation from scene graphs. We introduce a scene graph context network that pools features generated by a graph convolutional neural network that are then provided to both the image generation network and the adversarial loss. With the context network, our model is trained to not only generate realistic looking images, but also to better preserve non-spatial object relationships. We also define two novel evaluation metrics, the relation score and the mean opinion relation score, for this task that directly evaluate scene graph compliance. We use both quantitative and qualitative studies to demonstrate that our pro-posed model outperforms the state-of-the-art on this challenging task.
A Discrete Scheme for Computing Image's Weighted Gaussian Curvature
Jan 20, 2021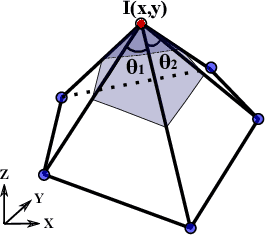
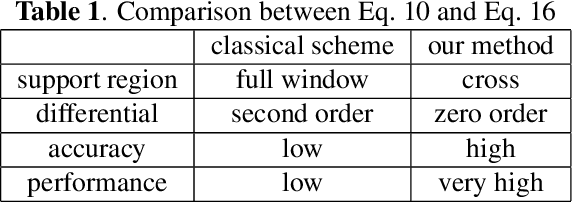
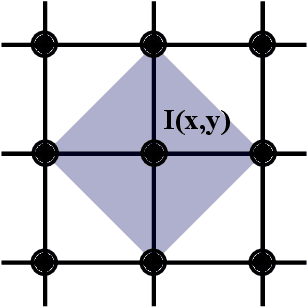
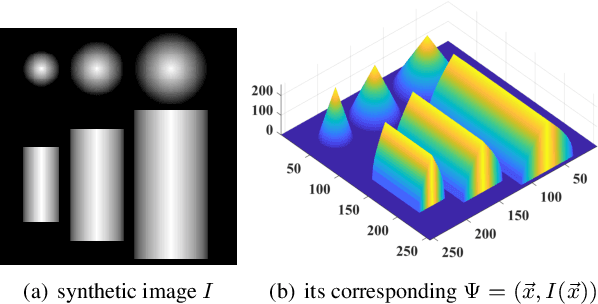
Weighted Gaussian Curvature is an important measurement for images. However, its conventional computation scheme has low performance, low accuracy and requires that the input image must be second order differentiable. To tackle these three issues, we propose a novel discrete computation scheme for the weighted Gaussian curvature. Our scheme does not require the second order differentiability. Moreover, our scheme is more accurate, has smaller support region and computationally more efficient than the conventional schemes. Therefore, our scheme holds promise for a large range of applications where the weighted Gaussian curvature is needed, for example, image smoothing, cartoon texture decomposition, optical flow estimation, etc.
CITE: A Corpus of Image-Text Discourse Relations
Apr 16, 2019
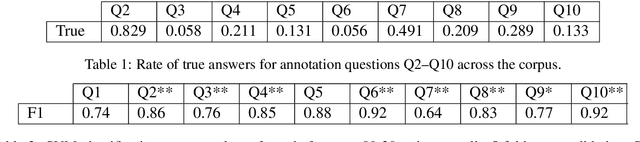

This paper presents a novel crowd-sourced resource for multimodal discourse: our resource characterizes inferences in image-text contexts in the domain of cooking recipes in the form of coherence relations. Like previous corpora annotating discourse structure between text arguments, such as the Penn Discourse Treebank, our new corpus aids in establishing a better understanding of natural communication and common-sense reasoning, while our findings have implications for a wide range of applications, such as understanding and generation of multimodal documents.
* 7 pages
Center Smoothing for Certifiably Robust Vector-Valued Functions
Feb 19, 2021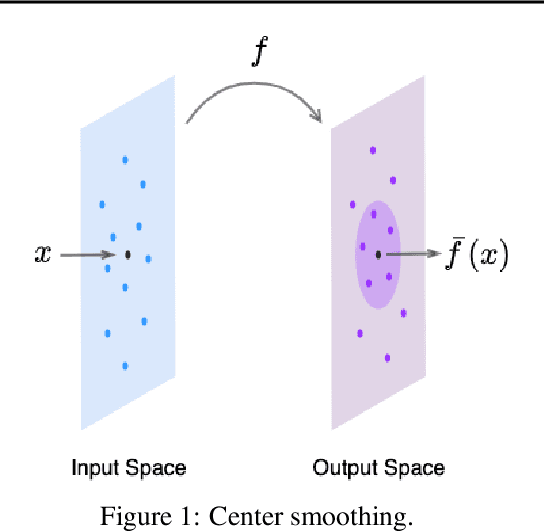
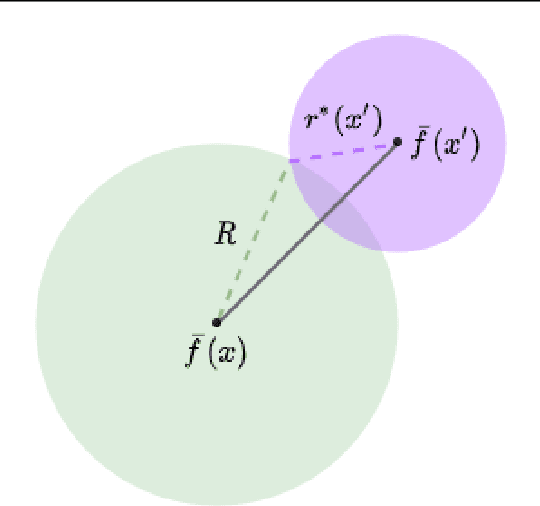
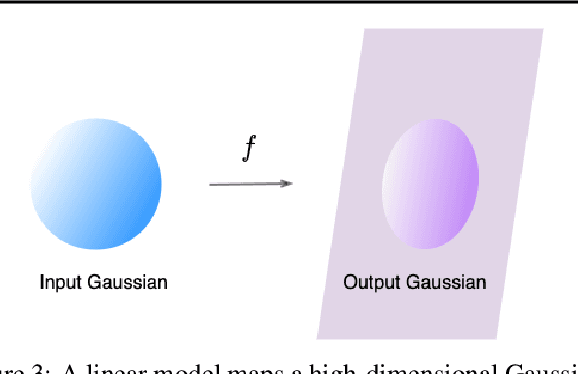

Randomized smoothing has been successfully applied in high-dimensional image classification tasks to obtain models that are provably robust against input perturbations of bounded size. We extend this technique to produce certifiable robustness for vector-valued functions, i.e., bound the change in output caused by a small change in input. These functions are used in many areas of machine learning, such as image reconstruction, dimensionality reduction, super-resolution, etc., but due to the enormous dimensionality of the output space in these problems, generating meaningful robustness guarantees is difficult. We design a smoothing procedure that can leverage the local, potentially low-dimensional, behaviour of the function around an input to obtain probabilistic robustness certificates. We demonstrate the effectiveness of our method on multiple learning tasks involving vector-valued functions with a wide range of input and output dimensionalities.