 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Image Moment Models for Extended Object Tracking
Apr 09, 2018
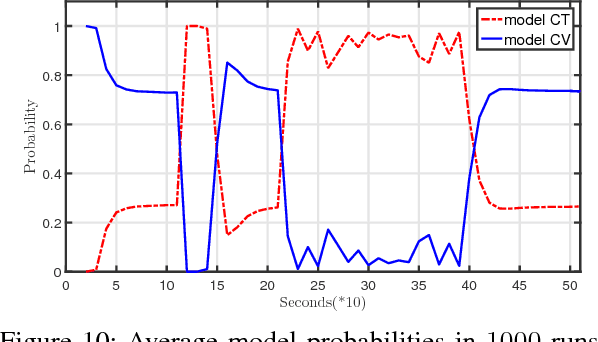

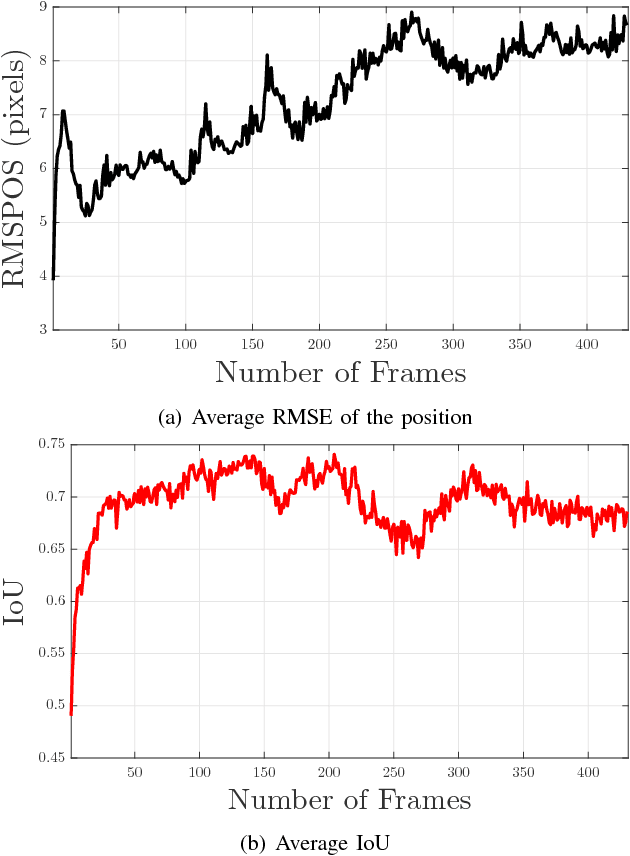
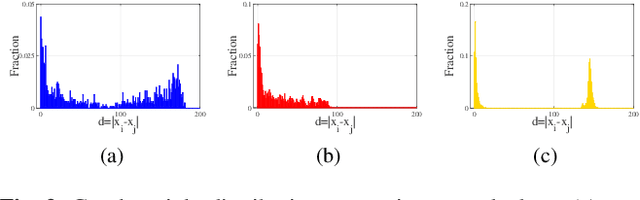
In this paper, a novel image moments based model for shape estimation and tracking of an object moving with a complex trajectory is presented. The camera is assumed to be stationary looking at a moving object. Point features inside the object are sampled as measurements. An ellipsoidal approximation of the shape is assumed as a primitive shape. The shape of an ellipse is estimated using a combination of image moments. Dynamic model of image moments when the object moves under the constant velocity or coordinated turn motion model is derived as a function for the shape estimation of the object. An Unscented Kalman Filter-Interacting Multiple Model (UKF-IMM) filter algorithm is applied to estimate the shape of the object (approximated as an ellipse) and track its position and velocity. A likelihood function based on average log-likelihood is derived for the IMM filter. Simulation results of the proposed UKF-IMM algorithm with the image moments based models are presented that show the estimations of the shape of the object moving in complex trajectories. Comparison results, using intersection over union (IOU), and position and velocity root mean square errors (RMSE) as metrics, with a benchmark algorithm from literature are presented. Results on real image data captured from the quadcopter are also presented.
Blind Image Deblurring via Reweighted Graph Total Variation
Dec 24, 2017
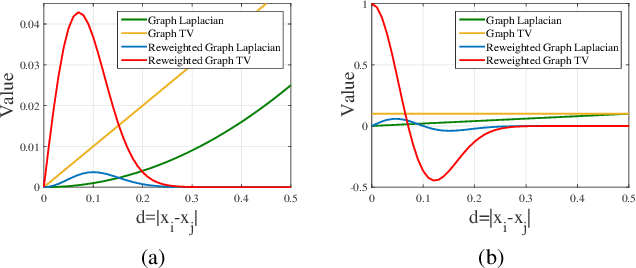

Blind image deblurring, i.e., deblurring without knowledge of the blur kernel, is a highly ill-posed problem. The problem can be solved in two parts: i) estimate a blur kernel from the blurry image, and ii) given estimated blur kernel, de-convolve blurry input to restore the target image. In this paper, by interpreting an image patch as a signal on a weighted graph, we first argue that a skeleton image---a proxy that retains the strong gradients of the target but smooths out the details---can be used to accurately estimate the blur kernel and has a unique bi-modal edge weight distribution. We then design a reweighted graph total variation (RGTV) prior that can efficiently promote bi-modal edge weight distribution given a blurry patch. However, minimizing a blind image deblurring objective with RGTV results in a non-convex non-differentiable optimization problem. We propose a fast algorithm that solves for the skeleton image and the blur kernel alternately. Finally with the computed blur kernel, recent non-blind image deblurring algorithms can be applied to restore the target image. Experimental results show that our algorithm can robustly estimate the blur kernel with large kernel size, and the reconstructed sharp image is competitive against the state-of-the-art methods.
Class agnostic moving target detection by color and location prediction of moving area
Jun 24, 2021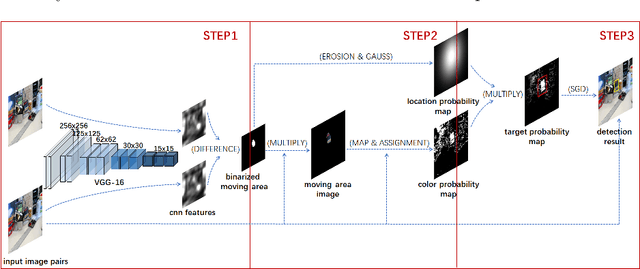
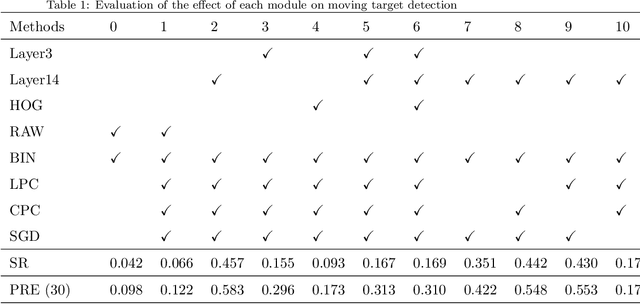


Moving target detection plays an important role in computer vision. However, traditional algorithms such as frame difference and optical flow usually suffer from low accuracy or heavy computation. Recent algorithms such as deep learning-based convolutional neural networks have achieved high accuracy and real-time performance, but they usually need to know the classes of targets in advance, which limits the practical applications. Therefore, we proposed a model free moving target detection algorithm. This algorithm extracts the moving area through the difference of image features. Then, the color and location probability map of the moving area will be calculated through maximum a posteriori probability. And the target probability map can be obtained through the dot multiply between the two maps. Finally, the optimal moving target area can be solved by stochastic gradient descent on the target probability map. Results show that the proposed algorithm achieves the highest accuracy compared with state-of-the-art algorithms, without needing to know the classes of targets. Furthermore, as the existing datasets are not suitable for moving target detection, we proposed a method for producing evaluation dataset. Besides, we also proved the proposed algorithm can be used to assist target tracking.
A Novel Bio-Inspired Texture Descriptor based on Biodiversity and Taxonomic Measures
Mar 07, 2021
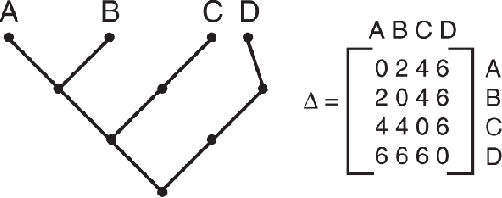
Texture can be defined as the change of image intensity that forms repetitive patterns, resulting from physical properties of the object's roughness or differences in a reflection on the surface. Considering that texture forms a complex system of patterns in a non-deterministic way, biodiversity concepts can help texture characterization in images. This paper proposes a novel approach capable of quantifying such a complex system of diverse patterns through species diversity and richness and taxonomic distinctiveness. The proposed approach considers each image channel as a species ecosystem and computes species diversity and richness measures as well as taxonomic measures to describe the texture. The proposed approach takes advantage of ecological patterns' invariance characteristics to build a permutation, rotation, and translation invariant descriptor. Experimental results on three datasets of natural texture images and two datasets of histopathological images have shown that the proposed texture descriptor has advantages over several texture descriptors and deep methods.
Shifts: A Dataset of Real Distributional Shift Across Multiple Large-Scale Tasks
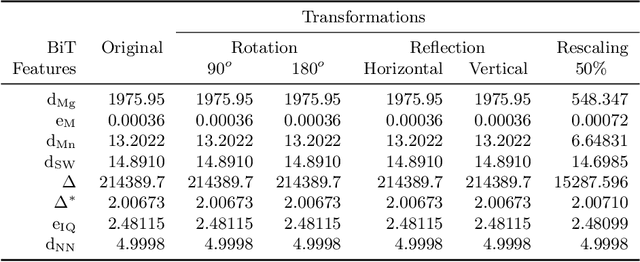
Jul 15, 2021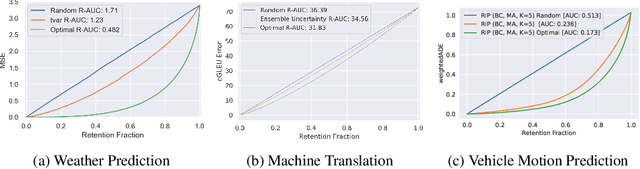
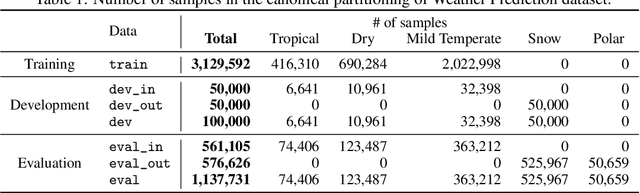
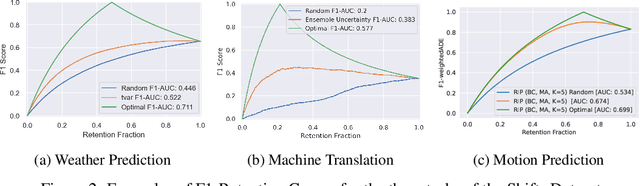
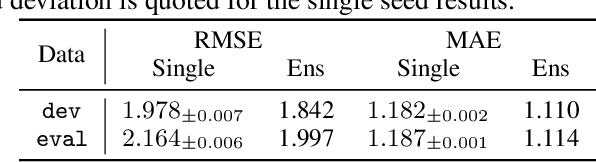
There has been significant research done on developing methods for improving robustness to distributional shift and uncertainty estimation. In contrast, only limited work has examined developing standard datasets and benchmarks for assessing these approaches. Additionally, most work on uncertainty estimation and robustness has developed new techniques based on small-scale regression or image classification tasks. However, many tasks of practical interest have different modalities, such as tabular data, audio, text, or sensor data, which offer significant challenges involving regression and discrete or continuous structured prediction. Thus, given the current state of the field, a standardized large-scale dataset of tasks across a range of modalities affected by distributional shifts is necessary. This will enable researchers to meaningfully evaluate the plethora of recently developed uncertainty quantification methods, as well as assessment criteria and state-of-the-art baselines. In this work, we propose the \emph{Shifts Dataset} for evaluation of uncertainty estimates and robustness to distributional shift. The dataset, which has been collected from industrial sources and services, is composed of three tasks, with each corresponding to a particular data modality: tabular weather prediction, machine translation, and self-driving car (SDC) vehicle motion prediction. All of these data modalities and tasks are affected by real, `in-the-wild' distributional shifts and pose interesting challenges with respect to uncertainty estimation. In this work we provide a description of the dataset and baseline results for all tasks.
TransBTS: Multimodal Brain Tumor Segmentation Using Transformer
Mar 07, 2021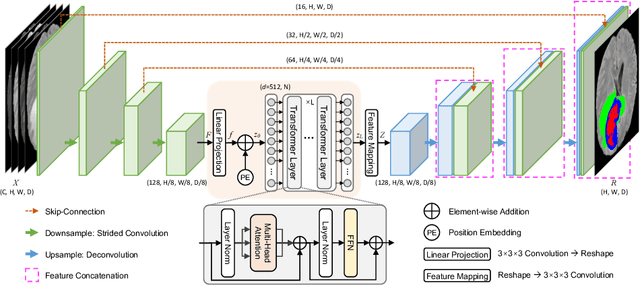
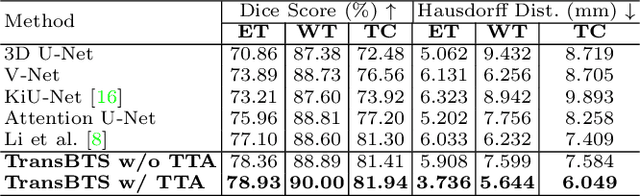
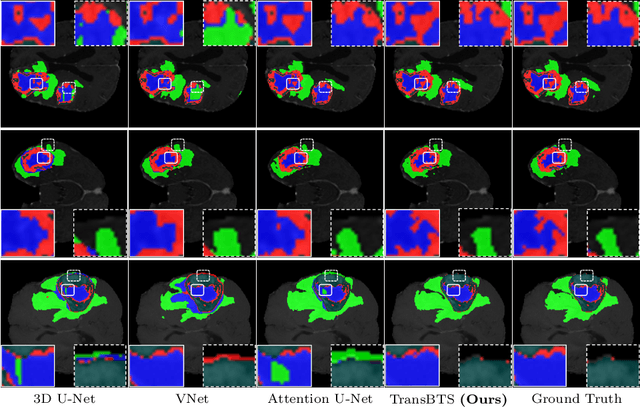
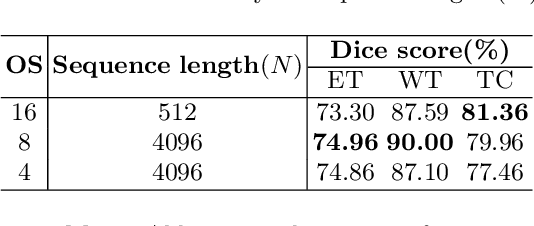
Transformer, which can benefit from global (long-range) information modeling using self-attention mechanisms, has been successful in natural language processing and 2D image classification recently. However, both local and global features are crucial for dense prediction tasks, especially for 3D medical image segmentation. In this paper, we for the first time exploit Transformer in 3D CNN for MRI Brain Tumor Segmentation and propose a novel network named TransBTS based on the encoder-decoder structure. To capture the local 3D context information, the encoder first utilizes 3D CNN to extract the volumetric spatial feature maps. Meanwhile, the feature maps are reformed elaborately for tokens that are fed into Transformer for global feature modeling. The decoder leverages the features embedded by Transformer and performs progressive upsampling to predict the detailed segmentation map. Experimental results on the BraTS 2019 dataset show that TransBTS outperforms state-of-the-art methods for brain tumor segmentation on 3D MRI scans. Code is available at https://github.com/Wenxuan-1119/TransBTS
Aggregated Deep Local Features for Remote Sensing Image Retrieval
Mar 22, 2019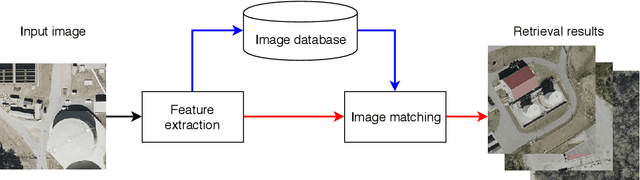


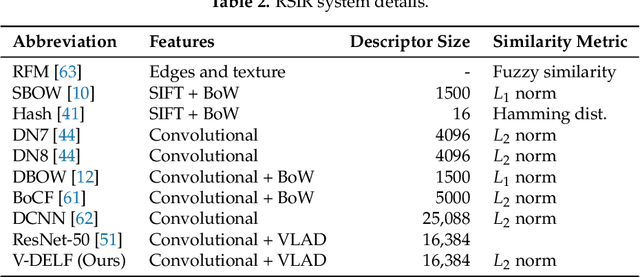
Remote Sensing Image Retrieval remains a challenging topic due to the special nature of Remote Sensing Imagery. Such images contain various different semantic objects, which clearly complicates the retrieval task. In this paper, we present an image retrieval pipeline that uses attentive, local convolutional features and aggregates them using the Vector of Locally Aggregated Descriptors (VLAD) to produce a global descriptor. We study various system parameters such as the multiplicative and additive attention mechanisms and descriptor dimensionality. We propose a query expansion method that requires no external inputs. Experiments demonstrate that even without training, the local convolutional features and global representation outperform other systems. After system tuning, we can achieve state-of-the-art or competitive results. Furthermore, we observe that our query expansion method increases overall system performance by about 3%, using only the top-three retrieved images. Finally, we show how dimensionality reduction produces compact descriptors with increased retrieval performance and fast retrieval computation times, e.g. 50% faster than the current systems.
* Published in Remote Sensing. The first two authors have equal contribution
VITON: An Image-based Virtual Try-on Network
Jun 12, 2018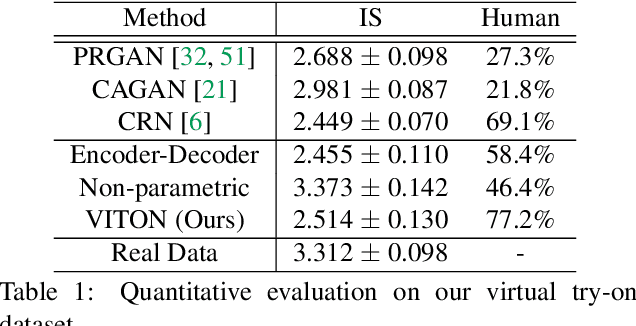
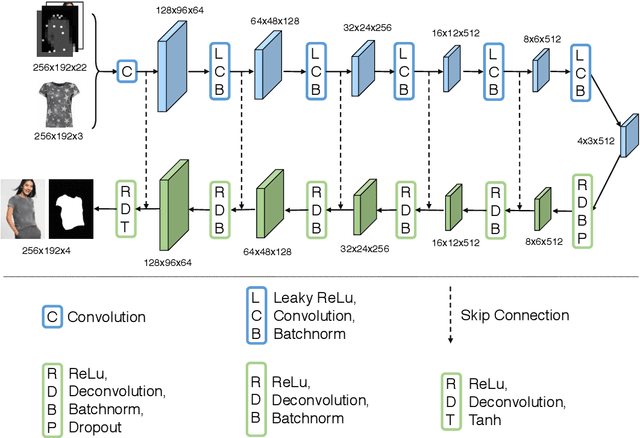


We present an image-based VIirtual Try-On Network (VITON) without using 3D information in any form, which seamlessly transfers a desired clothing item onto the corresponding region of a person using a coarse-to-fine strategy. Conditioned upon a new clothing-agnostic yet descriptive person representation, our framework first generates a coarse synthesized image with the target clothing item overlaid on that same person in the same pose. We further enhance the initial blurry clothing area with a refinement network. The network is trained to learn how much detail to utilize from the target clothing item, and where to apply to the person in order to synthesize a photo-realistic image in which the target item deforms naturally with clear visual patterns. Experiments on our newly collected Zalando dataset demonstrate its promise in the image-based virtual try-on task over state-of-the-art generative models.
Feature-Based Image Clustering and Segmentation Using Wavelets
Jul 05, 2019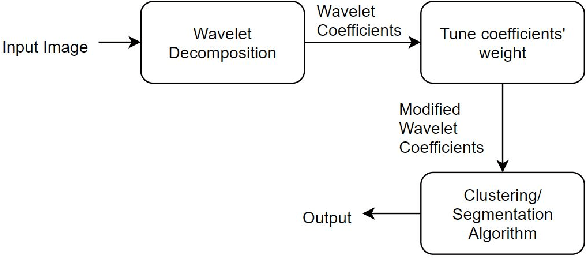
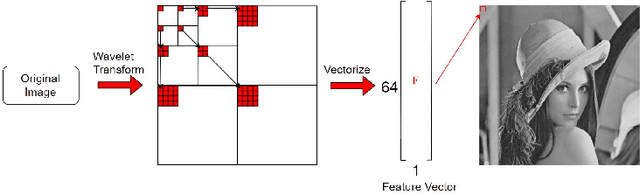
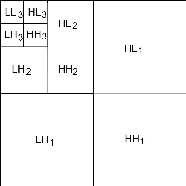
Pixel intensity is a widely used feature for clustering and segmentation algorithms, the resulting segmentation using only intensity values might suffer from noises and lack of spatial context information. Wavelet transform is often used for image denoising and classification. We proposed a novel method to incorporate Wavelet features in segmentation and clustering algorithms. The conventional K-means, Fuzzy c-means (FCM), and Active contour without edges (ACWE) algorithms were modified to adapt Wavelet features, leading to robust clustering/segmentation algorithms. A weighting parameter to control the weight of low-frequency sub-band information was also introduced. The new algorithms showed the capability to converge to different segmentation results based on the frequency information derived from the Wavelet sub-bands.
A Neural Compositional Paradigm for Image Captioning
Oct 23, 2018
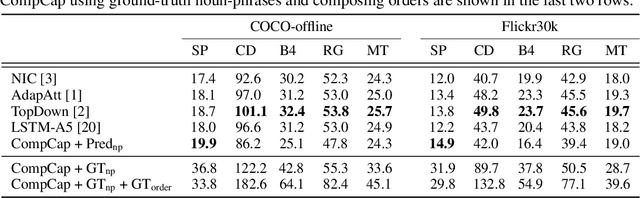
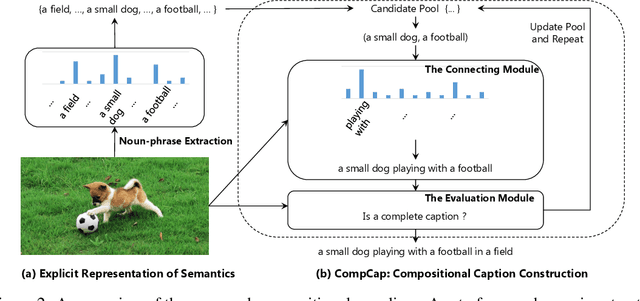
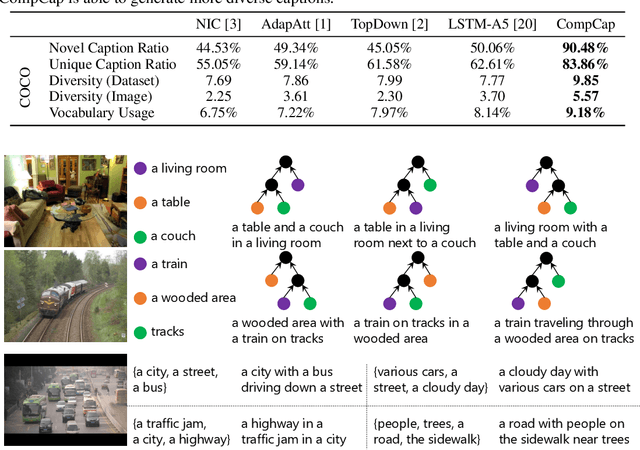
Mainstream captioning models often follow a sequential structure to generate captions, leading to issues such as introduction of irrelevant semantics, lack of diversity in the generated captions, and inadequate generalization performance. In this paper, we present an alternative paradigm for image captioning, which factorizes the captioning procedure into two stages: (1) extracting an explicit semantic representation from the given image; and (2) constructing the caption based on a recursive compositional procedure in a bottom-up manner. Compared to conventional ones, our paradigm better preserves the semantic content through an explicit factorization of semantics and syntax. By using the compositional generation procedure, caption construction follows a recursive structure, which naturally fits the properties of human language. Moreover, the proposed compositional procedure requires less data to train, generalizes better, and yields more diverse captions.