 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlockwise Advantage Estimation for Multi-Objective RL with Verifiable Rewards
Feb 10, 2026Group Relative Policy Optimization (GRPO) assigns a single scalar advantage to all tokens in a completion. For structured generations with explicit segments and objectives, this couples unrelated reward signals across segments, leading to objective interference and misattributed credit. We propose Blockwise Advantage Estimation, a family of GRPO-compatible methods that assigns each objective its own advantage and applies it only to the tokens in the corresponding text block, reducing reliance on hand-designed scalar rewards and scaling naturally to additional objectives. A key challenge is estimating advantages for later blocks whose rewards are conditioned on sampled prefixes; standard unbiased approaches require expensive nested rollouts from intermediate states. Concretely, we introduce an Outcome-Conditioned Baseline that approximates intermediate state values using only within-group statistics by stratifying samples according to a prefix-derived intermediate outcome. On math tasks with uncertainty estimation, our method mitigates reward interference, is competitive with a state-of-the-art reward-designed approach, and preserves test-time gains from confidence-weighted ensembling. More broadly, it provides a modular recipe for optimizing sequential objectives in structured generations without additional rollouts.
SWE-rebench: An Automated Pipeline for Task Collection and Decontaminated Evaluation of Software Engineering Agents
May 26, 2025LLM-based agents have shown promising capabilities in a growing range of software engineering (SWE) tasks. However, advancing this field faces two critical challenges. First, high-quality training data is scarce, especially data that reflects real-world SWE scenarios, where agents must interact with development environments, execute code and adapt behavior based on the outcomes of their actions. Existing datasets are either limited to one-shot code generation or comprise small, manually curated collections of interactive tasks, lacking both scale and diversity. Second, the lack of fresh interactive SWE tasks affects evaluation of rapidly improving models, as static benchmarks quickly become outdated due to contamination issues. To address these limitations, we introduce a novel, automated, and scalable pipeline to continuously extract real-world interactive SWE tasks from diverse GitHub repositories. Using this pipeline, we construct SWE-rebench, a public dataset comprising over 21,000 interactive Python-based SWE tasks, suitable for reinforcement learning of SWE agents at scale. Additionally, we use continuous supply of fresh tasks collected using SWE-rebench methodology to build a contamination-free benchmark for agentic software engineering. We compare results of various LLMs on this benchmark to results on SWE-bench Verified and show that performance of some language models might be inflated due to contamination issues.
Guided Search Strategies in Non-Serializable Environments with Applications to Software Engineering Agents
May 19, 2025Large language models (LLMs) have recently achieved remarkable results in complex multi-step tasks, such as mathematical reasoning and agentic software engineering. However, they often struggle to maintain consistent performance across multiple solution attempts. One effective approach to narrow the gap between average-case and best-case performance is guided test-time search, which explores multiple solution paths to identify the most promising one. Unfortunately, effective search techniques (e.g. MCTS) are often unsuitable for non-serializable RL environments, such as Docker containers, where intermediate environment states cannot be easily saved and restored. We investigate two complementary search strategies applicable to such environments: 1-step lookahead and trajectory selection, both guided by a learned action-value function estimator. On the SWE-bench Verified benchmark, a key testbed for agentic software engineering, we find these methods to double the average success rate of a fine-tuned Qwen-72B model, achieving 40.8%, the new state-of-the-art for open-weights models. Additionally, we show that these techniques are transferable to more advanced closed models, yielding similar improvements with GPT-4o.
Kraken: enabling joint trajectory prediction by utilizing Mode Transformer and Greedy Mode Processing
Dec 08, 2023Accurate and reliable motion prediction is essential for safe urban autonomy. The most prominent motion prediction approaches are based on modeling the distribution of possible future trajectories of each actor in autonomous system's vicinity. These "independent" marginal predictions might be accurate enough to properly describe casual driving situations where the prediction target is not likely to interact with other actors. They are, however, inadequate for modeling interactive situations where the actors' future trajectories are likely to intersect. To mitigate this issue we propose Kraken -- a real-time trajectory prediction model capable of approximating pairwise interactions between the actors as well as producing accurate marginal predictions. Kraken relies on a simple Greedy Mode Processing technique allowing it to convert a factorized prediction for a pair of agents into a physically-plausible joint prediction. It also utilizes the Mode Transformer module to increase the diversity of predicted trajectories and make the joint prediction more informative. We evaluate Kraken on Waymo Motion Prediction challenge where it held the first place in the Interaction leaderboard and the second place in the Motion leaderboard in October 2021.
Shifts: A Dataset of Real Distributional Shift Across Multiple Large-Scale Tasks
Jul 23, 2021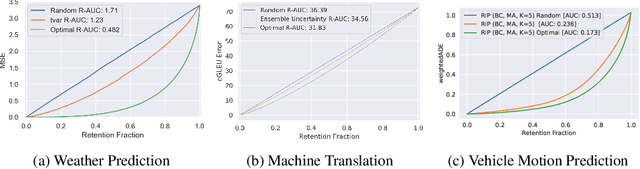
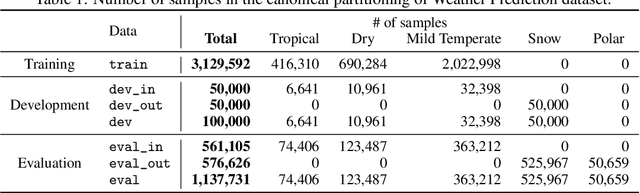
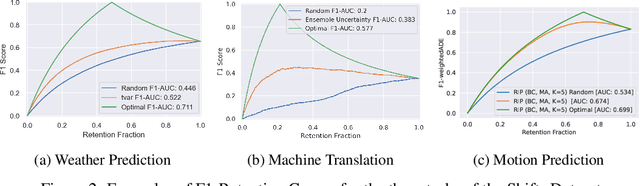
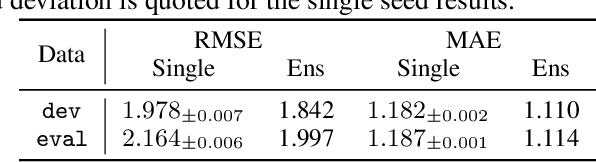
There has been significant research done on developing methods for improving robustness to distributional shift and uncertainty estimation. In contrast, only limited work has examined developing standard datasets and benchmarks for assessing these approaches. Additionally, most work on uncertainty estimation and robustness has developed new techniques based on small-scale regression or image classification tasks. However, many tasks of practical interest have different modalities, such as tabular data, audio, text, or sensor data, which offer significant challenges involving regression and discrete or continuous structured prediction. Thus, given the current state of the field, a standardized large-scale dataset of tasks across a range of modalities affected by distributional shifts is necessary. This will enable researchers to meaningfully evaluate the plethora of recently developed uncertainty quantification methods, as well as assessment criteria and state-of-the-art baselines. In this work, we propose the \emph{Shifts Dataset} for evaluation of uncertainty estimates and robustness to distributional shift. The dataset, which has been collected from industrial sources and services, is composed of three tasks, with each corresponding to a particular data modality: tabular weather prediction, machine translation, and self-driving car (SDC) vehicle motion prediction. All of these data modalities and tasks are affected by real, `in-the-wild' distributional shifts and pose interesting challenges with respect to uncertainty estimation. In this work we provide a description of the dataset and baseline results for all tasks.
PRANK: motion Prediction based on RANKing
Oct 22, 2020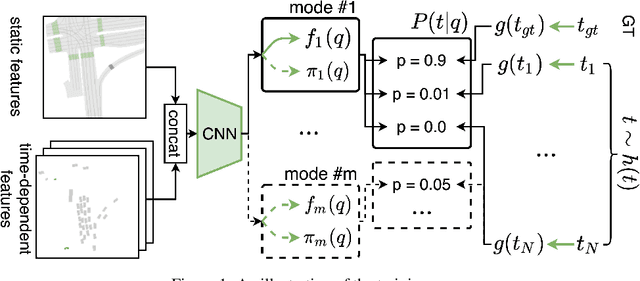
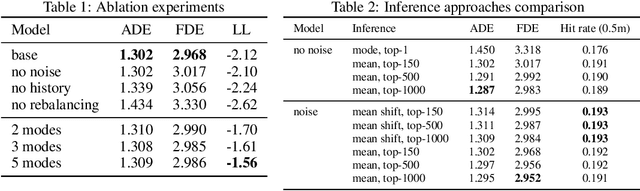
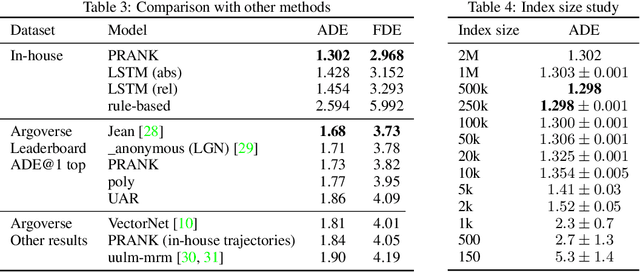
Predicting the motion of agents such as pedestrians or human-driven vehicles is one of the most critical problems in the autonomous driving domain. The overall safety of driving and the comfort of a passenger directly depend on its successful solution. The motion prediction problem also remains one of the most challenging problems in autonomous driving engineering, mainly due to high variance of the possible agent's future behavior given a situation. The two phenomena responsible for the said variance are the multimodality caused by the uncertainty of the agent's intent (e.g., turn right or move forward) and uncertainty in the realization of a given intent (e.g., which lane to turn into). To be useful within a real-time autonomous driving pipeline, a motion prediction system must provide efficient ways to describe and quantify this uncertainty, such as computing posterior modes and their probabilities or estimating density at the point corresponding to a given trajectory. It also should not put substantial density on physically impossible trajectories, as they can confuse the system processing the predictions. In this paper, we introduce the PRANK method, which satisfies these requirements. PRANK takes rasterized bird-eye images of agent's surroundings as an input and extracts features of the scene with a convolutional neural network. It then produces the conditional distribution of agent's trajectories plausible in the given scene. The key contribution of PRANK is a way to represent that distribution using nearest-neighbor methods in latent trajectory space, which allows for efficient inference in real time. We evaluate PRANK on the in-house and Argoverse datasets, where it shows competitive results.
Fast Weak Learner Based on Genetic Algorithm
Jun 04, 2009
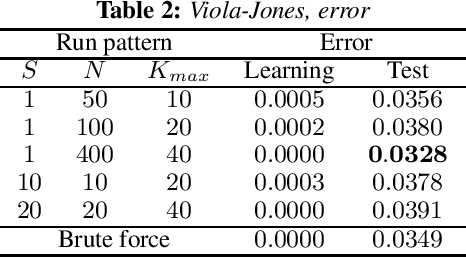
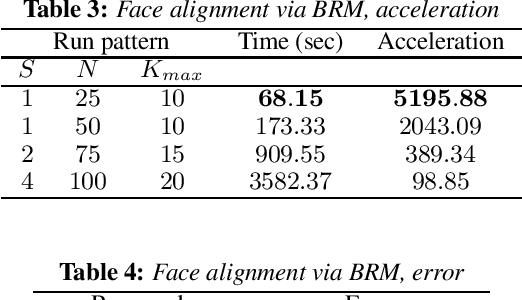
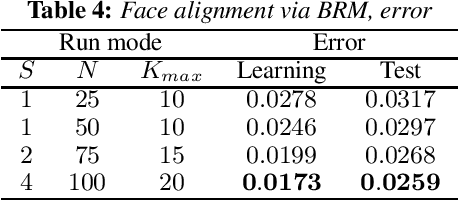
An approach to the acceleration of parametric weak classifier boosting is proposed. Weak classifier is called parametric if it has fixed number of parameters and, so, can be represented as a point into multidimensional space. Genetic algorithm is used instead of exhaustive search to learn parameters of such classifier. Proposed approach also takes cases when effective algorithm for learning some of the classifier parameters exists into account. Experiments confirm that such an approach can dramatically decrease classifier training time while keeping both training and test errors small.