 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learning Raw Image Denoising with Bayer Pattern Unification and Bayer Preserving Augmentation
Apr 29, 2019
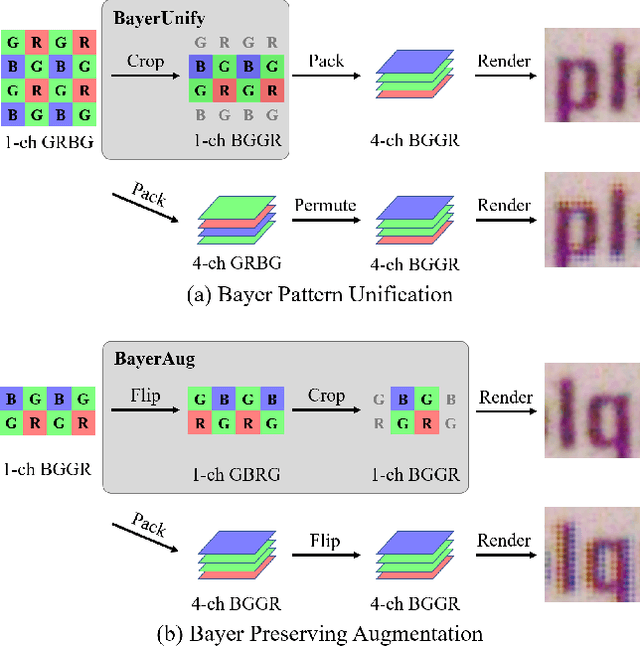



In this paper, we present new data pre-processing and augmentation techniques for DNN-based raw image denoising. Compared with traditional RGB image denoising, performing this task on direct camera sensor readings presents new challenges such as how to effectively handle various Bayer patterns from different data sources, and subsequently how to perform valid data augmentation with raw images. To address the first problem, we propose a Bayer pattern unification (BayerUnify) method to unify different Bayer patterns. This allows us to fully utilize a heterogeneous dataset to train a single denoising model instead of training one model for each pattern. Furthermore, while it is essential to augment the dataset to improve model generalization and performance, we discovered that it is error-prone to modify raw images by adapting augmentation methods designed for RGB images. Towards this end, we present a Bayer preserving augmentation (BayerAug) method as an effective approach for raw image augmentation. Combining these data processing technqiues with a modified U-Net, our method achieves a PSNR of 52.11 and a SSIM of 0.9969 in NTIRE 2019 Real Image Denoising Challenge, demonstrating the state-of-the-art performance.
Neighbor2Neighbor: Self-Supervised Denoising from Single Noisy Images
Jan 11, 2021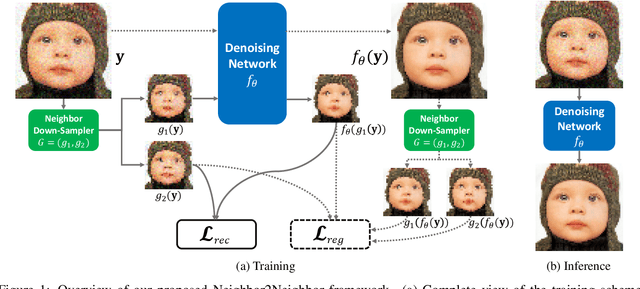
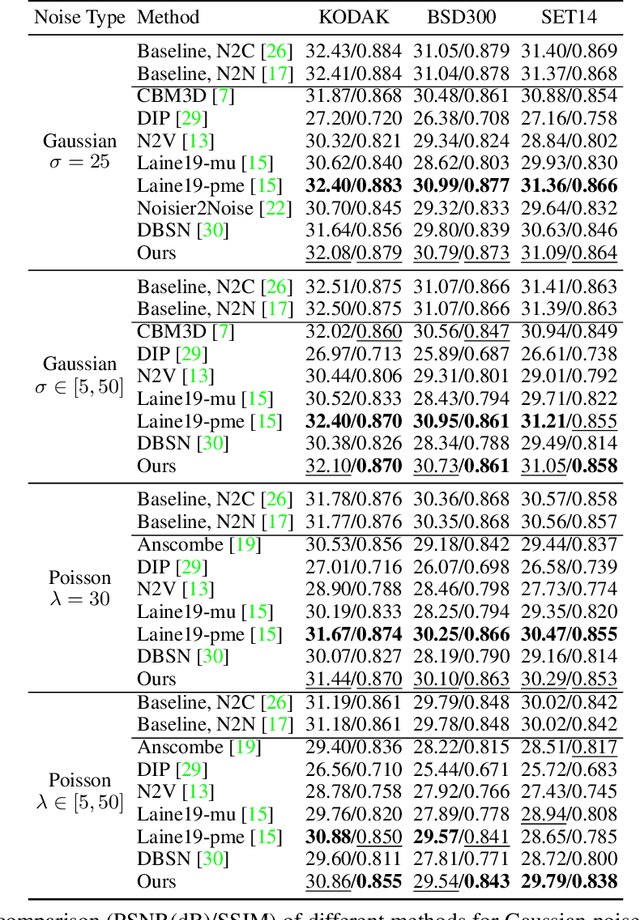
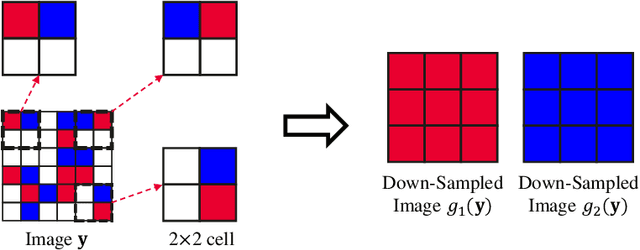
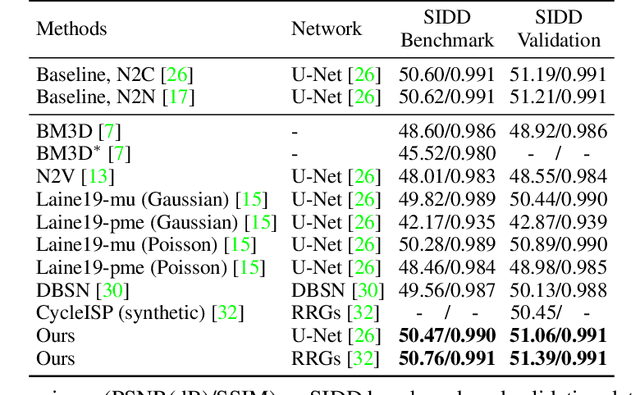
In the last few years, image denoising has benefited a lot from the fast development of neural networks. However, the requirement of large amounts of noisy-clean image pairs for supervision limits the wide use of these models. Although there have been a few attempts in training an image denoising model with only single noisy images, existing self-supervised denoising approaches suffer from inefficient network training, loss of useful information, or dependence on noise modeling. In this paper, we present a very simple yet effective method named Neighbor2Neighbor to train an effective image denoising model with only noisy images. Firstly, a random neighbor down-sampler is proposed for the generation of training image pairs. In detail, input and target used to train a network are images down-sampled from the same noisy image, satisfying the requirement that paired pixels of paired images are neighbors and have very similar appearance with each other. Secondly, a denoising network is trained on down-sampled training pairs generated in the first stage, with a proposed regularizer as additional loss for better performance. The proposed Neighbor2Neighbor framework is able to enjoy the progress of state-of-the-art supervised denoising networks in network architecture design. Moreover, it avoids heavy dependence on the assumption of the noise distribution. We explain our approach from a theoretical perspective and further validate it through extensive experiments, including synthetic experiments with different noise distributions in sRGB space and real-world experiments on a denoising benchmark dataset in raw-RGB space.
Invertible Attention
Jun 27, 2021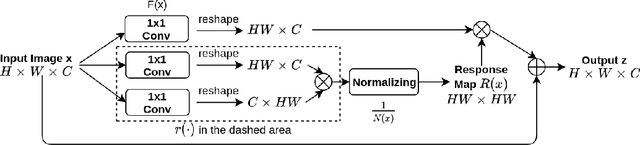


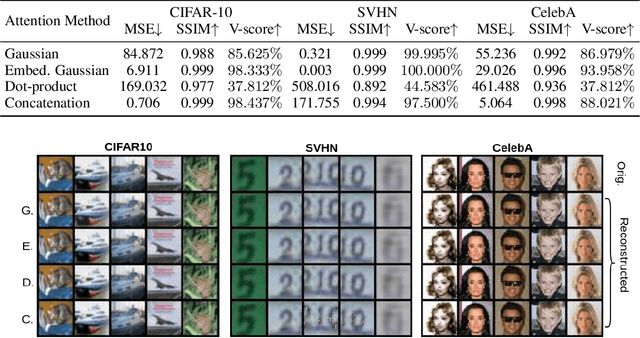
Attention has been proved to be an efficient mechanism to capture long-range dependencies. However, so far it has not been deployed in invertible networks. This is due to the fact that in order to make a network invertible, every component within the network needs to be a bijective transformation, but a normal attention block is not. In this paper, we propose invertible attention that can be plugged into existing invertible models. We mathematically and experimentally prove that the invertibility of an attention model can be achieved by carefully constraining its Lipschitz constant. We validate the invertibility of our invertible attention on image reconstruction task with 3 popular datasets: CIFAR-10, SVHN, and CelebA. We also show that our invertible attention achieves similar performance in comparison with normal non-invertible attention on dense prediction tasks. The code is available at https://github.com/Schwartz-Zha/InvertibleAttention
Keep Drawing It: Iterative language-based image generation and editing
Nov 24, 2018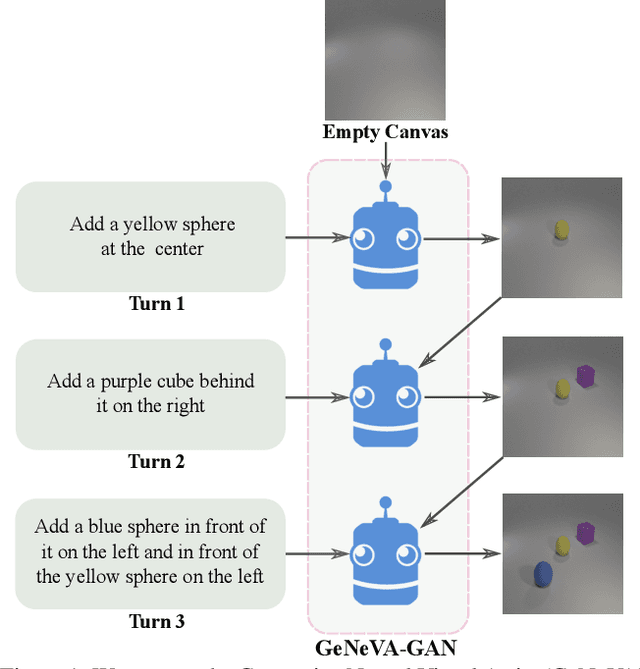
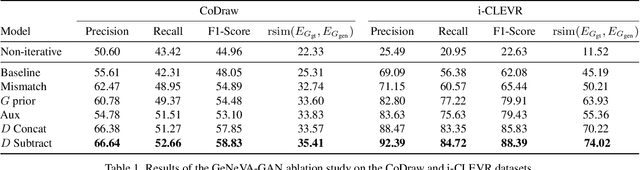

Conditional text-to-image generation approaches commonly focus on generating a single image in a single step. One practical extension beyond one-step generation is an interactive system that generates an image iteratively, conditioned on ongoing linguistic input / feedback. This is significantly more challenging as such a system must understand and keep track of the ongoing context and history. In this work, we present a recurrent image generation model which takes into account both the generated output up to the current step as well as all past instructions for generation. We show that our model is able to generate the background, add new objects, apply simple transformations to existing objects, and correct previous mistakes. We believe our approach is an important step toward interactive generation.
Adaptation of Tacotron2-based Text-To-Speech for Articulatory-to-Acoustic Mapping using Ultrasound Tongue Imaging
Jul 26, 2021
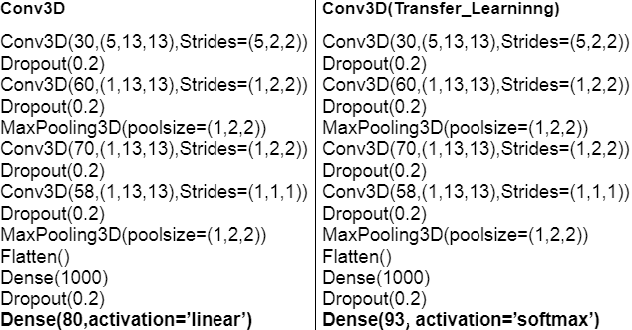
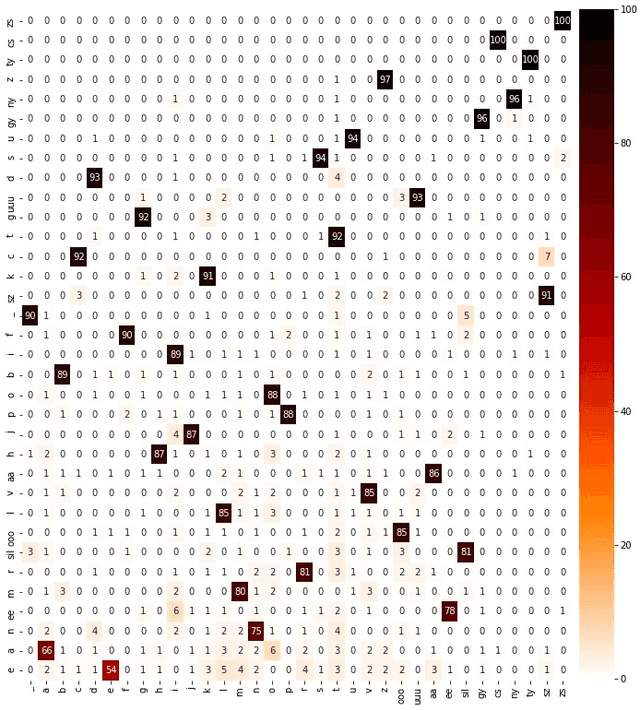
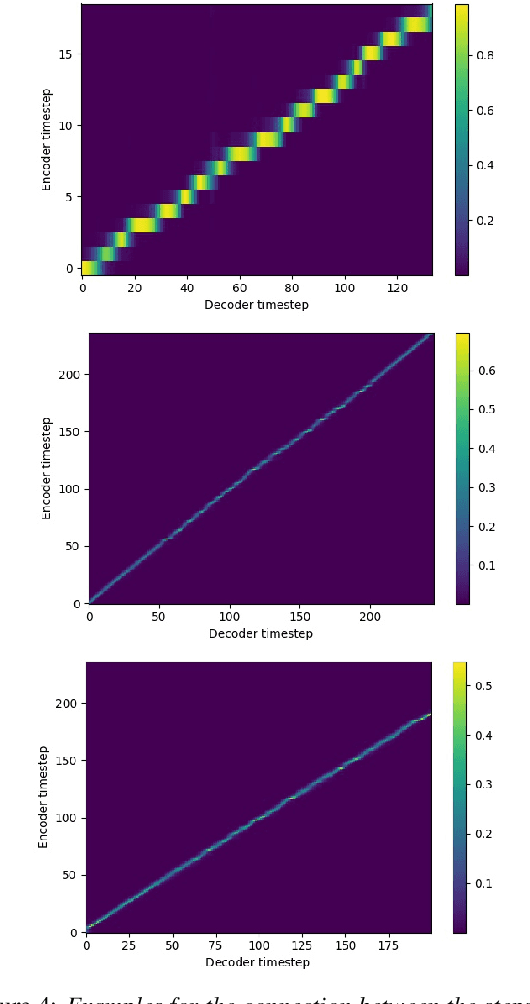
For articulatory-to-acoustic mapping, typically only limited parallel training data is available, making it impossible to apply fully end-to-end solutions like Tacotron2. In this paper, we experimented with transfer learning and adaptation of a Tacotron2 text-to-speech model to improve the final synthesis quality of ultrasound-based articulatory-to-acoustic mapping with a limited database. We use a multi-speaker pre-trained Tacotron2 TTS model and a pre-trained WaveGlow neural vocoder. The articulatory-to-acoustic conversion contains three steps: 1) from a sequence of ultrasound tongue image recordings, a 3D convolutional neural network predicts the inputs of the pre-trained Tacotron2 model, 2) the Tacotron2 model converts this intermediate representation to an 80-dimensional mel-spectrogram, and 3) the WaveGlow model is applied for final inference. This generated speech contains the timing of the original articulatory data from the ultrasound recording, but the F0 contour and the spectral information is predicted by the Tacotron2 model. The F0 values are independent of the original ultrasound images, but represent the target speaker, as they are inferred from the pre-trained Tacotron2 model. In our experiments, we demonstrated that the synthesized speech quality is more natural with the proposed solutions than with our earlier model.
Prototype-supervised Adversarial Network for Targeted Attack of Deep Hashing
May 17, 2021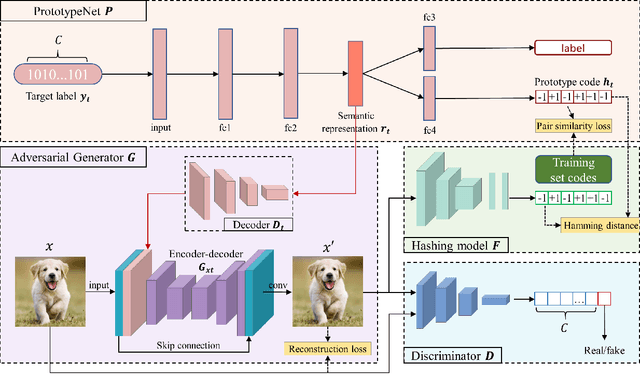
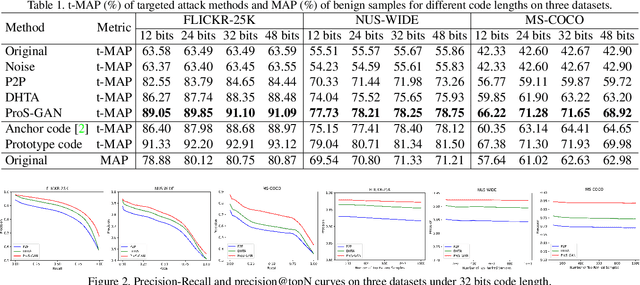
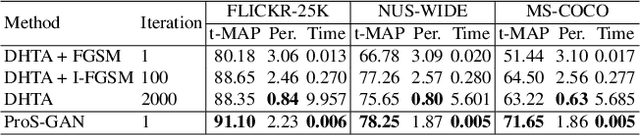

Due to its powerful capability of representation learning and high-efficiency computation, deep hashing has made significant progress in large-scale image retrieval. However, deep hashing networks are vulnerable to adversarial examples, which is a practical secure problem but seldom studied in hashing-based retrieval field. In this paper, we propose a novel prototype-supervised adversarial network (ProS-GAN), which formulates a flexible generative architecture for efficient and effective targeted hashing attack. To the best of our knowledge, this is the first generation-based method to attack deep hashing networks. Generally, our proposed framework consists of three parts, i.e., a PrototypeNet, a generator, and a discriminator. Specifically, the designed PrototypeNet embeds the target label into the semantic representation and learns the prototype code as the category-level representative of the target label. Moreover, the semantic representation and the original image are jointly fed into the generator for a flexible targeted attack. Particularly, the prototype code is adopted to supervise the generator to construct the targeted adversarial example by minimizing the Hamming distance between the hash code of the adversarial example and the prototype code. Furthermore, the generator is against the discriminator to simultaneously encourage the adversarial examples visually realistic and the semantic representation informative. Extensive experiments verify that the proposed framework can efficiently produce adversarial examples with better targeted attack performance and transferability over state-of-the-art targeted attack methods of deep hashing. The related codes could be available at https://github.com/xunguangwang/ProS-GAN .
ECINN: Efficient Counterfactuals from Invertible Neural Networks
Apr 05, 2021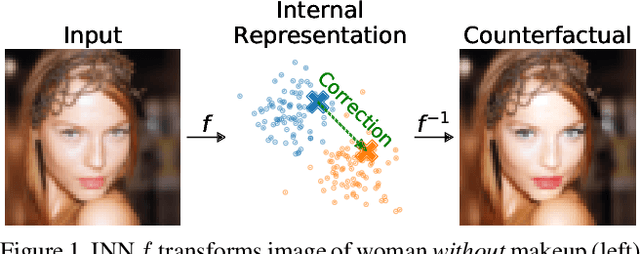
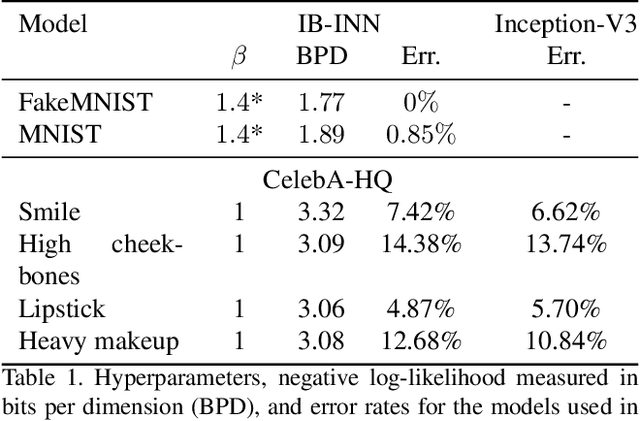
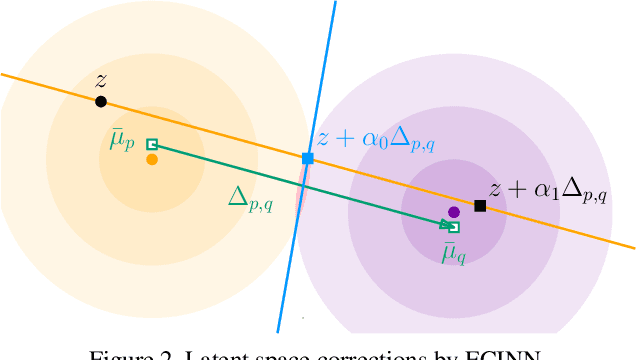

Counterfactual examples identify how inputs can be altered to change the predicted class of a classifier, thus opening up the black-box nature of, e.g., deep neural networks. We propose a method, ECINN, that utilizes the generative capacities of invertible neural networks for image classification to generate counterfactual examples efficiently. In contrast to competing methods that sometimes need a thousand evaluations or more of the classifier, ECINN has a closed-form expression and generates a counterfactual in the time of only two evaluations. Arguably, the main challenge of generating counterfactual examples is to alter only input features that affect the predicted outcome, i.e., class-dependent features. Our experiments demonstrate how ECINN alters class-dependent image regions to change the perceptual and predicted class of the counterfactuals. Additionally, we extend ECINN to also produce heatmaps (ECINNh) for easy inspection of, e.g., pairwise class-dependent changes in the generated counterfactual examples. Experimentally, we find that ECINNh outperforms established methods that generate heatmap-based explanations.
Adversarial Generation of Continuous Images
Nov 24, 2020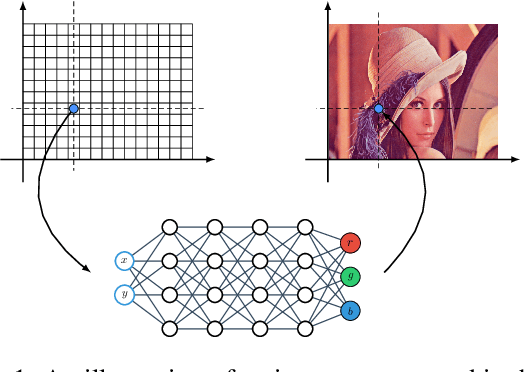


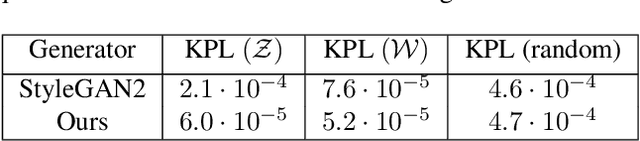
In most existing learning systems, images are typically viewed as 2D pixel arrays. However, in another paradigm gaining popularity, a 2D image is represented as an implicit neural representation (INR) -- an MLP that predicts an RGB pixel value given its (x,y) coordinate. In this paper, we propose two novel architectural techniques for building INR-based image decoders: factorized multiplicative modulation and multi-scale INRs, and use them to build a state-of-the-art continuous image GAN. Previous attempts to adapt INRs for image generation were limited to MNIST-like datasets and do not scale to complex real-world data. Our proposed architectural design improves the performance of continuous image generators by x6-40 times and reaches FID scores of 6.27 on LSUN bedroom 256x256 and 16.32 on FFHQ 1024x1024, greatly reducing the gap between continuous image GANs and pixel-based ones. To the best of our knowledge, these are the highest reported scores for an image generator, that consists entirely of fully-connected layers. Apart from that, we explore several exciting properties of INR-based decoders, like out-of-the-box superresolution, meaningful image-space interpolation, accelerated inference of low-resolution images, an ability to extrapolate outside of image boundaries and strong geometric prior. The source code is available at https://github.com/universome/inr-gan
Anomaly Detection using Deep Learning based Image Completion
Nov 16, 2018
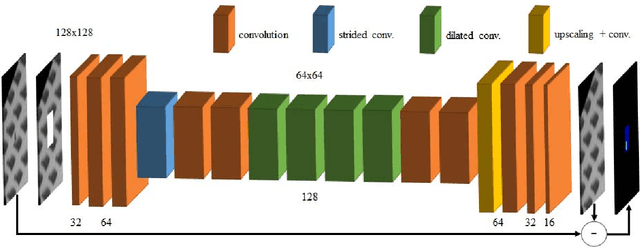
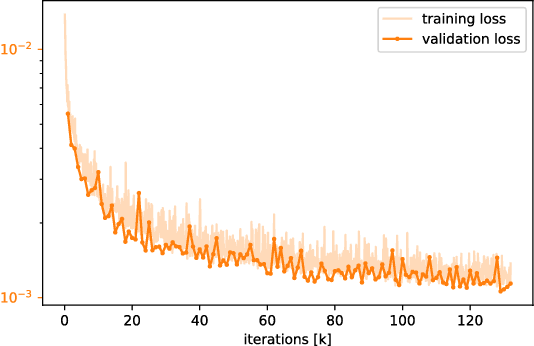
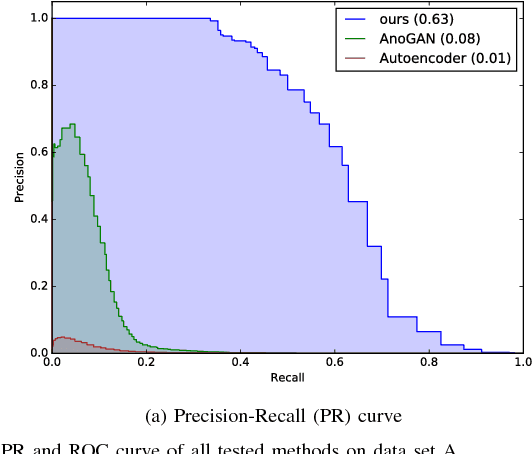
Automated surface inspection is an important task in many manufacturing industries and often requires machine learning driven solutions. Supervised approaches, however, can be challenging, since it is often difficult to obtain large amounts of labeled training data. In this work, we instead perform one-class unsupervised learning on fault-free samples by training a deep convolutional neural network to complete images whose center regions are cut out. Since the network is trained exclusively on fault-free data, it completes the image patches with a fault-free version of the missing image region. The pixel-wise reconstruction error within the cut out region is an anomaly image which can be used for anomaly detection. Results on surface images of decorated plastic parts demonstrate that this approach is suitable for detection of visible anomalies and moreover surpasses all other tested methods.
Real-World Super-Resolution of Face-Images from Surveillance Cameras
Feb 05, 2021
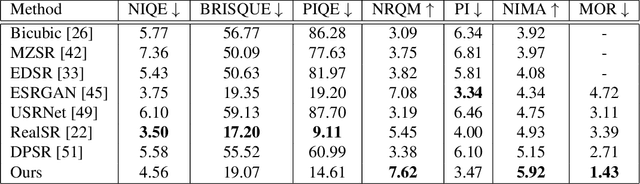

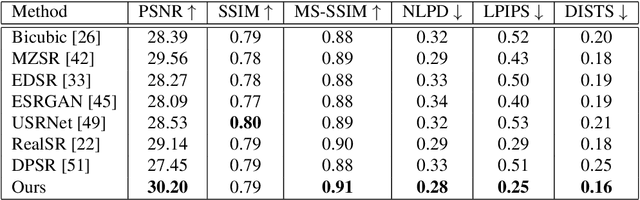
Most existing face image Super-Resolution (SR) methods assume that the Low-Resolution (LR) images were artificially downsampled from High-Resolution (HR) images with bicubic interpolation. This operation changes the natural image characteristics and reduces noise. Hence, SR methods trained on such data most often fail to produce good results when applied to real LR images. To solve this problem, we propose a novel framework for generation of realistic LR/HR training pairs. Our framework estimates realistic blur kernels, noise distributions, and JPEG compression artifacts to generate LR images with similar image characteristics as the ones in the source domain. This allows us to train a SR model using high quality face images as Ground-Truth (GT). For better perceptual quality we use a Generative Adversarial Network (GAN) based SR model where we have exchanged the commonly used VGG-loss [24] with LPIPS-loss [52]. Experimental results on both real and artificially corrupted face images show that our method results in more detailed reconstructions with less noise compared to existing State-of-the-Art (SoTA) methods. In addition, we show that the traditional non-reference Image Quality Assessment (IQA) methods fail to capture this improvement and demonstrate that the more recent NIMA metric [16] correlates better with human perception via Mean Opinion Rank (MOR).