 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoDMD: Copula-aware Distribution Matching Distillation for Fast Video Generation
Jun 20, 2026Few-step distillation for video diffusion models has attracted significant attention, driven by the urgent demand for efficient deployment in real-world scenarios. However, Distribution Matching Distillation (DMD), a leading paradigm, tends to degrade under limited NFE budgets, manifesting in video generation as layout instability, oversaturation, and broken motion dynamics. We trace this failure to a structural limitation: standard DMD is an intra-sample distribution-matching objective with coordinate-wise gradients, and thus imposes no explicit constraint on the relational geometry across batch elements or temporal frames, leaving the underlying copula largely unregulated. Combined with the mode-seeking tendency of its reverse-KL objective, this absence of relational guidance makes DMD prone to collapsing into local optima in the few-step regime. Motivated by this insight, we propose Copula-aware DMD (CoDMD), a lightweight relational regularizer that reuses score estimates already produced by the frozen teacher and the online fake model to construct pairwise relation matrices across samples and frames. These are matched through a supplementary distributional objective that requires no additional networks, datasets, or sampling trajectories. On the Wan-2.1-T2V model series at 1.3B & 14B scales, CoDMD distills 50-step teachers into 4-step students, achieving an approximate 25$\times$ speed-up while attaining VBench scores of 84.46 & 84.87, outperforming prior trajectory-based (rCM 82.81 & 84.05) and distribution-based (DMD 83.38 & 83.81) methods.
Continuous Semi-Implicit Models
Jun 07, 2025Semi-implicit distributions have shown great promise in variational inference and generative modeling. Hierarchical semi-implicit models, which stack multiple semi-implicit layers, enhance the expressiveness of semi-implicit distributions and can be used to accelerate diffusion models given pretrained score networks. However, their sequential training often suffers from slow convergence. In this paper, we introduce CoSIM, a continuous semi-implicit model that extends hierarchical semi-implicit models into a continuous framework. By incorporating a continuous transition kernel, CoSIM enables efficient, simulation-free training. Furthermore, we show that CoSIM achieves consistency with a carefully designed transition kernel, offering a novel approach for multistep distillation of generative models at the distributional level. Extensive experiments on image generation demonstrate that CoSIM performs on par or better than existing diffusion model acceleration methods, achieving superior performance on FD-DINOv2.
Invertible Attention
Jun 27, 2021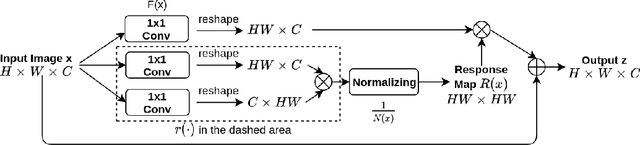


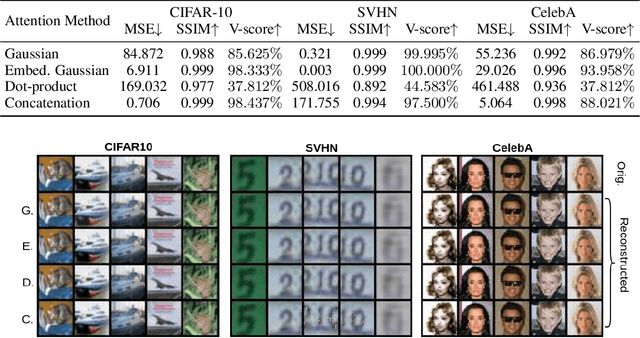
Attention has been proved to be an efficient mechanism to capture long-range dependencies. However, so far it has not been deployed in invertible networks. This is due to the fact that in order to make a network invertible, every component within the network needs to be a bijective transformation, but a normal attention block is not. In this paper, we propose invertible attention that can be plugged into existing invertible models. We mathematically and experimentally prove that the invertibility of an attention model can be achieved by carefully constraining its Lipschitz constant. We validate the invertibility of our invertible attention on image reconstruction task with 3 popular datasets: CIFAR-10, SVHN, and CelebA. We also show that our invertible attention achieves similar performance in comparison with normal non-invertible attention on dense prediction tasks. The code is available at https://github.com/Schwartz-Zha/InvertibleAttention