 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Resonant Tunnelling Diode Nano-Optoelectronic Spiking Nodes For Neuromorphic Information Processing
Jul 14, 2021
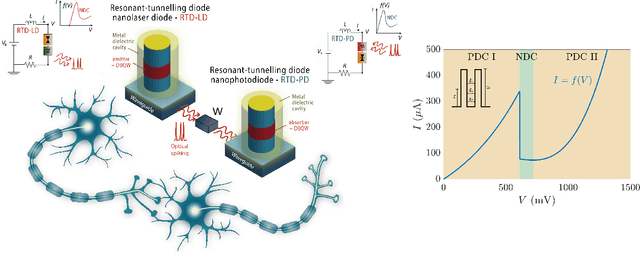
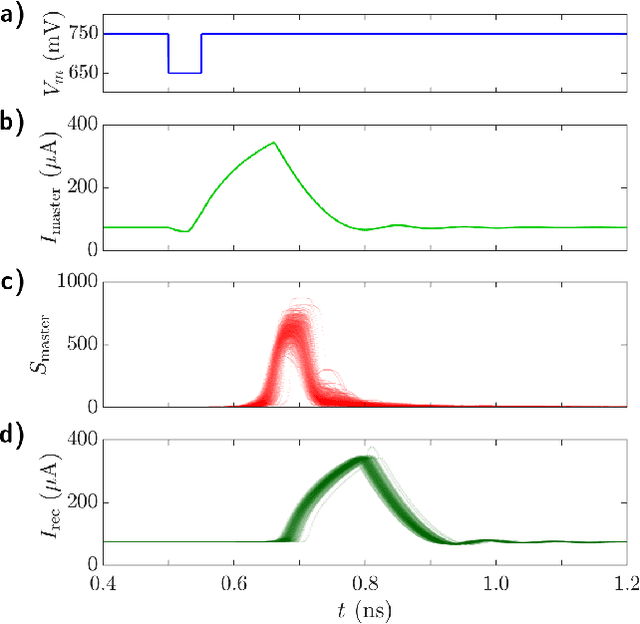
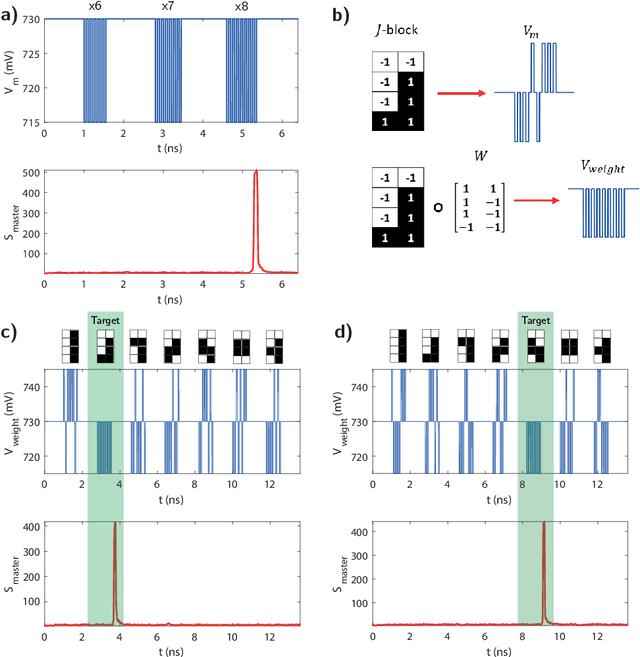
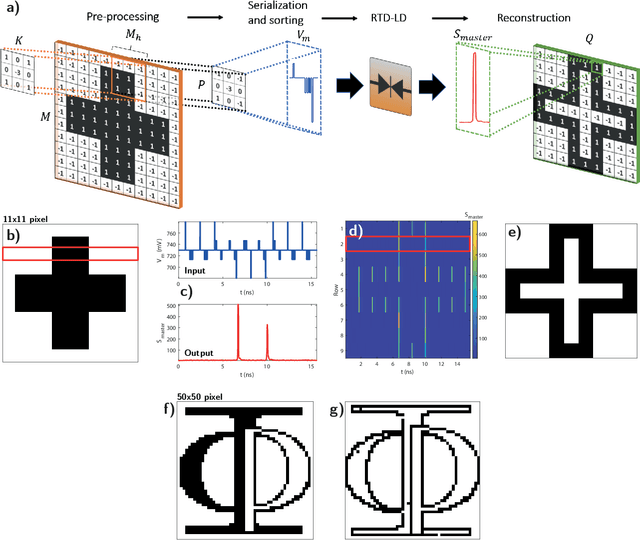
In this work, we introduce an optoelectronic spiking artificial neuron capable of operating at ultrafast rates ($\approx$ 100 ps/optical spike) and with low energy consumption ($<$ pJ/spike). The proposed system combines an excitable resonant tunnelling diode (RTD) element exhibiting negative differential conductance, coupled to a nanoscale light source (forming a master node) or a photodetector (forming a receiver node). We study numerically the spiking dynamical responses and information propagation functionality of an interconnected master-receiver RTD node system. Using the key functionality of pulse thresholding and integration, we utilize a single node to classify sequential pulse patterns and perform convolutional functionality for image feature (edge) recognition. We also demonstrate an optically-interconnected spiking neural network model for processing of spatiotemporal data at over 10 Gbps with high inference accuracy. Finally, we demonstrate an off-chip supervised learning approach utilizing spike-timing dependent plasticity for the RTD-enabled photonic spiking neural network. These results demonstrate the potential and viability of RTD spiking nodes for low footprint, low energy, high-speed optoelectronic realization of neuromorphic hardware.
Unified Batch All Triplet Loss for Visible-Infrared Person Re-identification
Mar 08, 2021

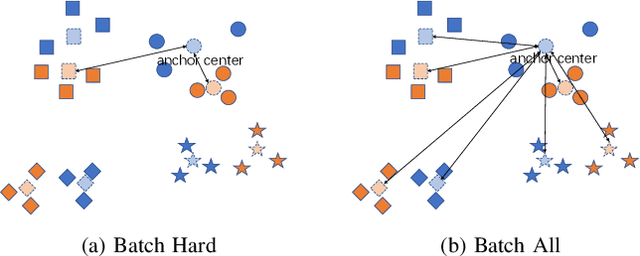
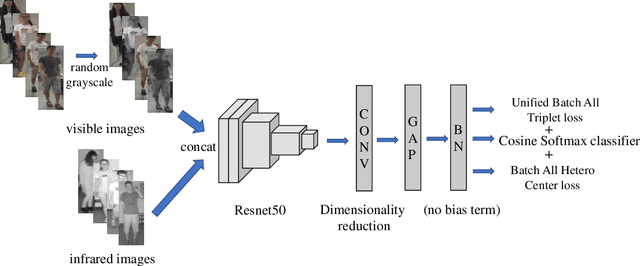
Visible-Infrared cross-modality person re-identification (VI-ReID), whose aim is to match person images between visible and infrared modality, is a challenging cross-modality image retrieval task. Batch Hard Triplet loss is widely used in person re-identification tasks, but it does not perform well in the Visible-Infrared person re-identification task. Because it only optimizes the hardest triplet for each anchor image within the mini-batch, samples in the hardest triplet may all belong to the same modality, which will lead to the imbalance problem of modality optimization. To address this problem, we adopt the batch all triplet selection strategy, which selects all the possible triplets among samples to optimize instead of the hardest triplet. Furthermore, we introduce Unified Batch All Triplet loss and Cosine Softmax loss to collaboratively optimize the cosine distance between image vectors. Similarly, we rewrite the Hetero Center Triplet loss, which is proposed for VI-ReID task, into a batch all form to improve model performance. Extensive experiments indicate the effectiveness of the proposed methods, which outperform state-of-the-art methods by a wide margin.
Underwater image enhancement with Image Colorfulness Measure
Apr 18, 2020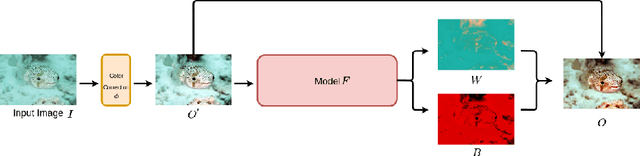
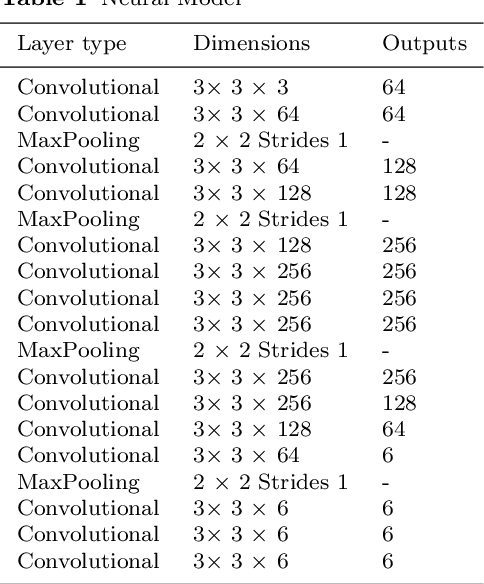


Due to the absorption and scattering effects of the water, underwater images tend to suffer from many severe problems, such as low contrast, grayed out colors and blurring content. To improve the visual quality of underwater images, we proposed a novel enhancement model, which is a trainable end-to-end neural model. Two parts constitute the overall model. The first one is a non-parameter layer for the preliminary color correction, then the second part is consisted of parametric layers for a self-adaptive refinement, namely the channel-wise linear shift. For better details, contrast and colorfulness, this enhancement network is jointly optimized by the pixel-level and characteristiclevel training criteria. Through extensive experiments on natural underwater scenes, we show that the proposed method can get high quality enhancement results.
Self-Supervised Multi-Modal Alignment for Whole Body Medical Imaging
Jul 14, 2021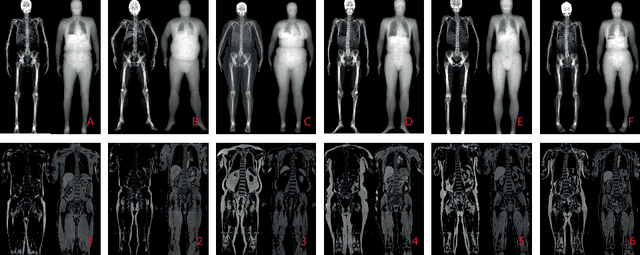
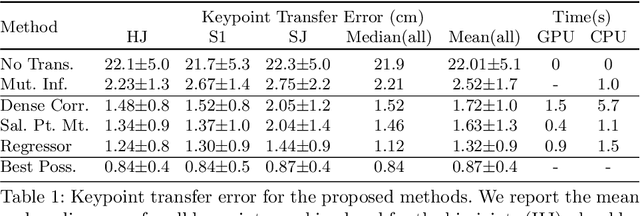
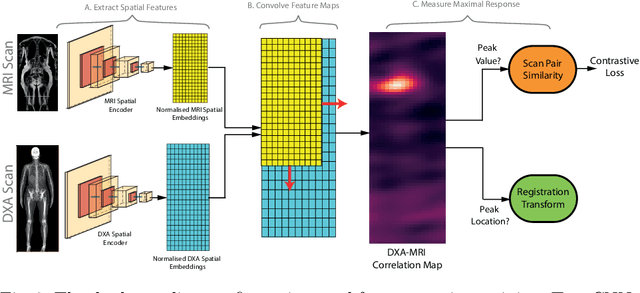
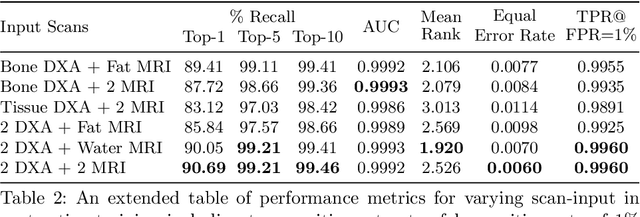
This paper explores the use of self-supervised deep learning in medical imaging in cases where two scan modalities are available for the same subject. Specifically, we use a large publicly-available dataset of over 20,000 subjects from the UK Biobank with both whole body Dixon technique magnetic resonance (MR) scans and also dual-energy x-ray absorptiometry (DXA) scans. We make three contributions: (i) We introduce a multi-modal image-matching contrastive framework, that is able to learn to match different-modality scans of the same subject with high accuracy. (ii) Without any adaption, we show that the correspondences learnt during this contrastive training step can be used to perform automatic cross-modal scan registration in a completely unsupervised manner. (iii) Finally, we use these registrations to transfer segmentation maps from the DXA scans to the MR scans where they are used to train a network to segment anatomical regions without requiring ground-truth MR examples. To aid further research, our code will be made publicly available.
How Modular Should Neural Module Networks Be for Systematic Generalization?
Jun 15, 2021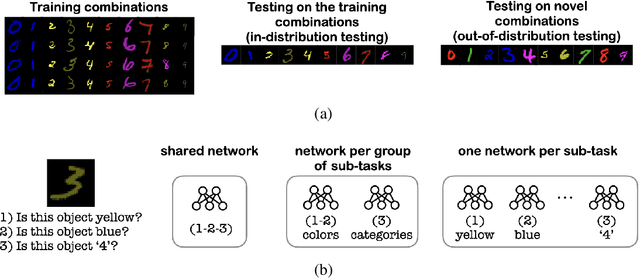

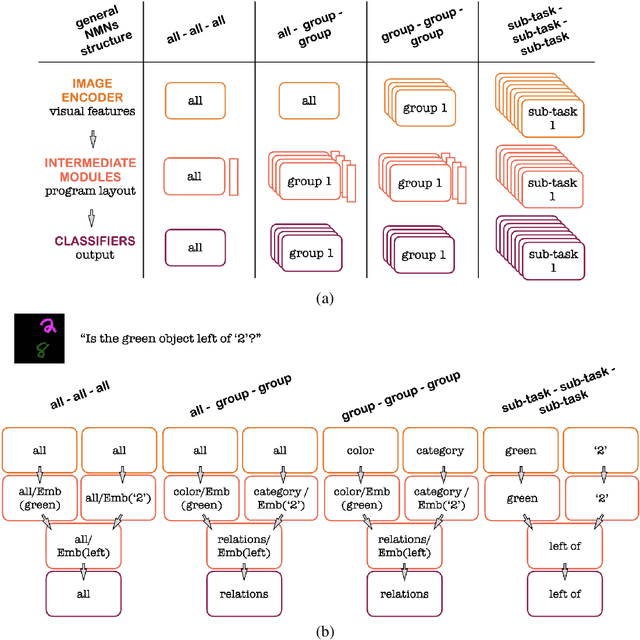

Neural Module Networks (NMNs) aim at Visual Question Answering (VQA) via composition of modules that tackle a sub-task. NMNs are a promising strategy to achieve systematic generalization, i.e. overcoming biasing factors in the training distribution. However, the aspects of NMNs that facilitate systematic generalization are not fully understood. In this paper, we demonstrate that the stage and the degree at which modularity is defined has large influence on systematic generalization. In a series of experiments on three VQA datasets (MNIST with multiple attributes, SQOOP, and CLEVR-CoGenT), our results reveal that tuning the degree of modularity in the network, especially at the image encoder stage, reaches substantially higher systematic generalization. These findings lead to new NMN architectures that outperform previous ones in terms of systematic generalization.
Denoising Auto-encoding Priors in Undecimated Wavelet Domain for MR Image Reconstruction
Sep 04, 2019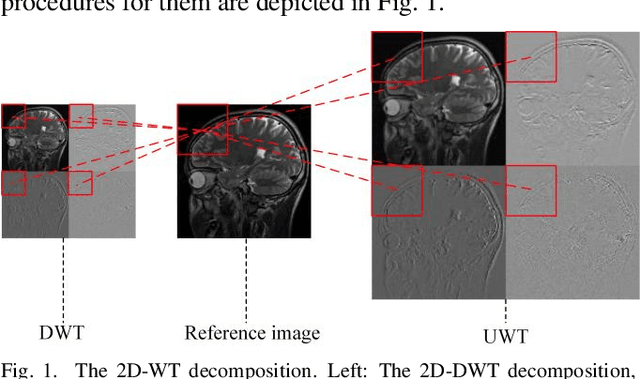

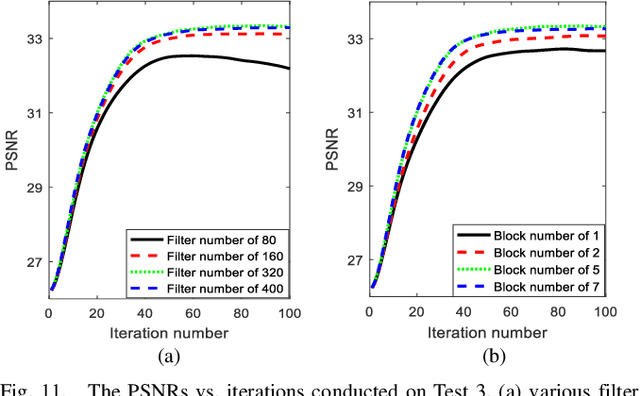
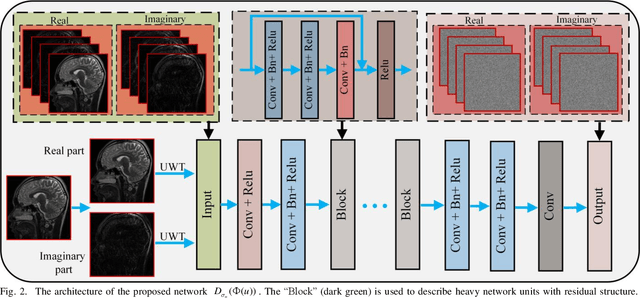
Compressive sensing is an impressive approach for fast MRI. It aims at reconstructing MR image using only a few under-sampled data in k-space, enhancing the efficiency of the data acquisition. In this study, we propose to learn priors based on undecimated wavelet transform and an iterative image reconstruction algorithm. At the stage of prior learning, transformed feature images obtained by undecimated wavelet transform are stacked as an input of denoising autoencoder network (DAE). The highly redundant and multi-scale input enables the correlation of feature images at different channels, which allows a robust network-driven prior. At the iterative reconstruction, the transformed DAE prior is incorporated into the classical iterative procedure by the means of proximal gradient algorithm. Experimental comparisons on different sampling trajectories and ratios validated the great potential of the presented algorithm.
ADeLA: Automatic Dense Labeling with Attention for Viewpoint Adaptation in Semantic Segmentation
Jul 29, 2021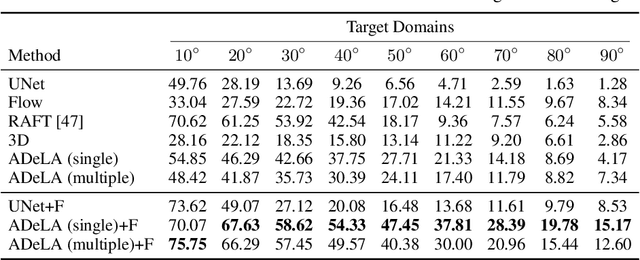

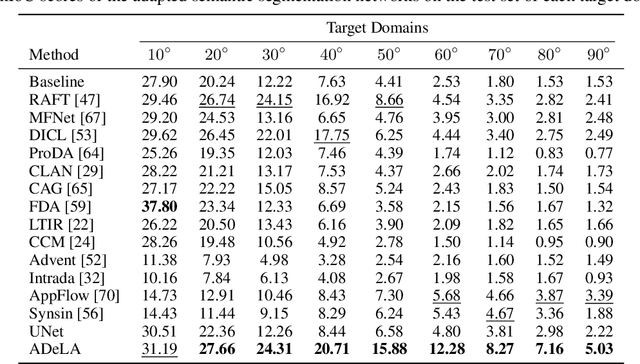

We describe an unsupervised domain adaptation method for image content shift caused by viewpoint changes for a semantic segmentation task. Most existing methods perform domain alignment in a shared space and assume that the mapping from the aligned space to the output is transferable. However, the novel content induced by viewpoint changes may nullify such a space for effective alignments, thus resulting in negative adaptation. Our method works without aligning any statistics of the images between the two domains. Instead, it utilizes a view transformation network trained only on color images to hallucinate the semantic images for the target. Despite the lack of supervision, the view transformation network can still generalize to semantic images thanks to the inductive bias introduced by the attention mechanism. Furthermore, to resolve ambiguities in converting the semantic images to semantic labels, we treat the view transformation network as a functional representation of an unknown mapping implied by the color images and propose functional label hallucination to generate pseudo-labels in the target domain. Our method surpasses baselines built on state-of-the-art correspondence estimation and view synthesis methods. Moreover, it outperforms the state-of-the-art unsupervised domain adaptation methods that utilize self-training and adversarial domain alignment. Our code and dataset will be made publicly available.
DeepIR: A Deep Semantics Driven Framework for Image Retargeting
Nov 19, 2018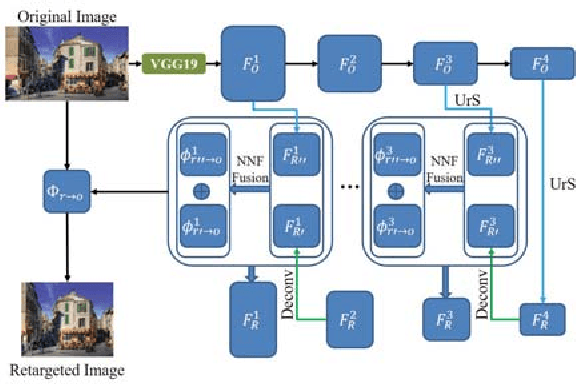
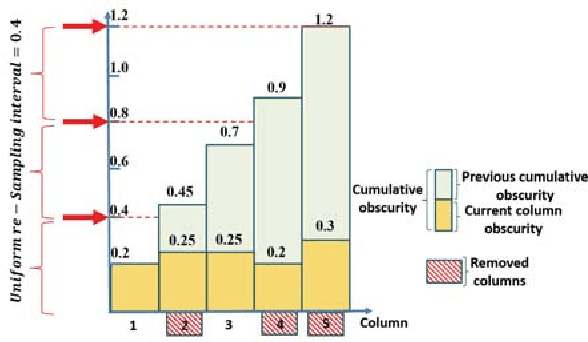
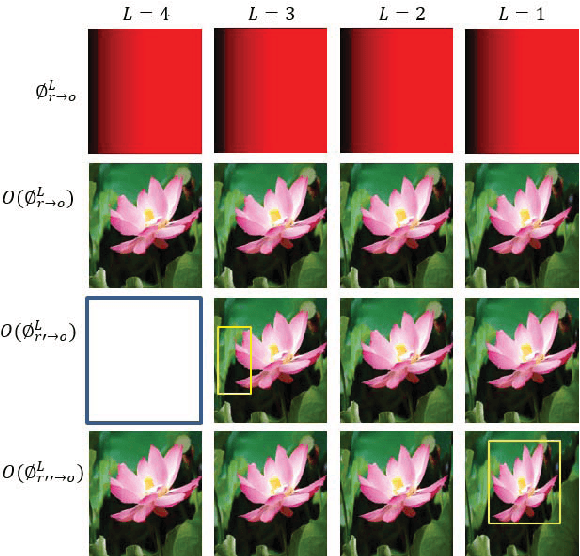
We present \emph{Deep Image Retargeting} (\emph{DeepIR}), a coarse-to-fine framework for content-aware image retargeting. Our framework first constructs the semantic structure of input image with a deep convolutional neural network. Then a uniform re-sampling that suits for semantic structure preserving is devised to resize feature maps to target aspect ratio at each feature layer. The final retargeting result is generated by coarse-to-fine nearest neighbor field search and step-by-step nearest neighbor field fusion. We empirically demonstrate the effectiveness of our model with both qualitative and quantitative results on widely used RetargetMe dataset.
ACE-Net: Biomedical Image Segmentation with Augmented Contracting and Expansive Paths
Aug 23, 2019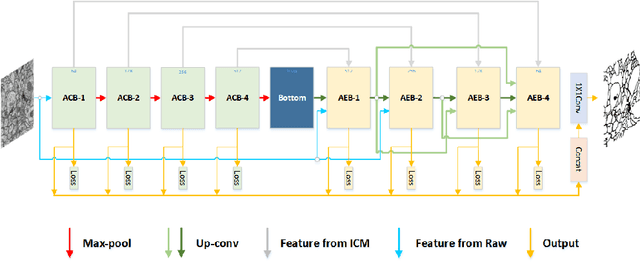
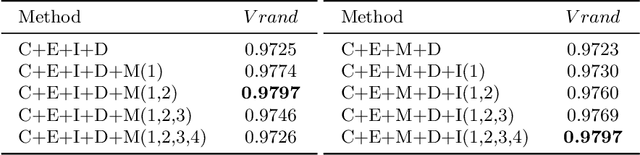
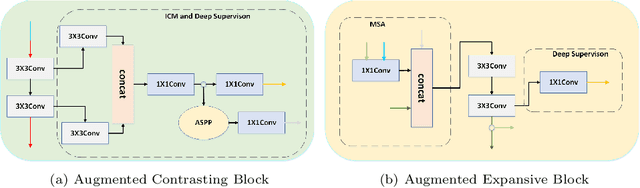
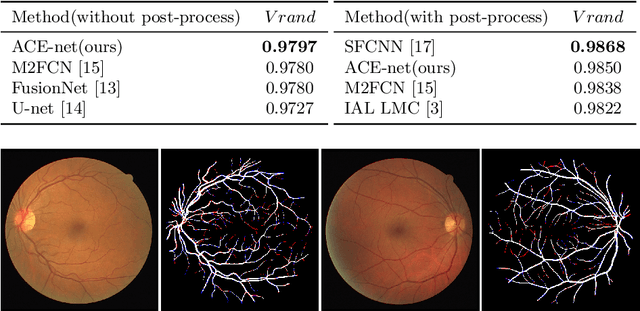
Nowadays U-net-like FCNs predominate various biomedical image segmentation applications and attain promising performance, largely due to their elegant architectures, e.g., symmetric contracting and expansive paths as well as lateral skip-connections. It remains a research direction to devise novel architectures to further benefit the segmentation. In this paper, we develop an ACE-net that aims to enhance the feature representation and utilization by augmenting the contracting and expansive paths. In particular, we augment the paths by the recently proposed advanced techniques including ASPP, dense connection and deep supervision mechanisms, and novel connections such as directly connecting the raw image to the expansive side. With these augmentations, ACE-net can utilize features from multiple sources, scales and reception fields to segment while still maintains a relative simple architecture. Experiments on two typical biomedical segmentation tasks validate its effectiveness, where highly competitive results are obtained in both tasks while ACE-net still runs fast at inference.
Recognizing Image Objects by Relational Analysis Using Heterogeneous Superpixels and Deep Convolutional Features
Aug 02, 2019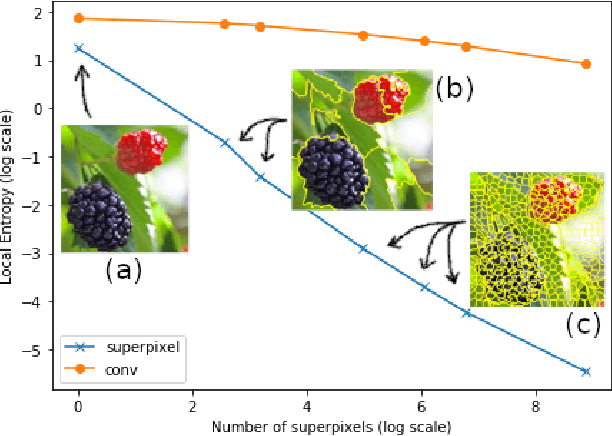
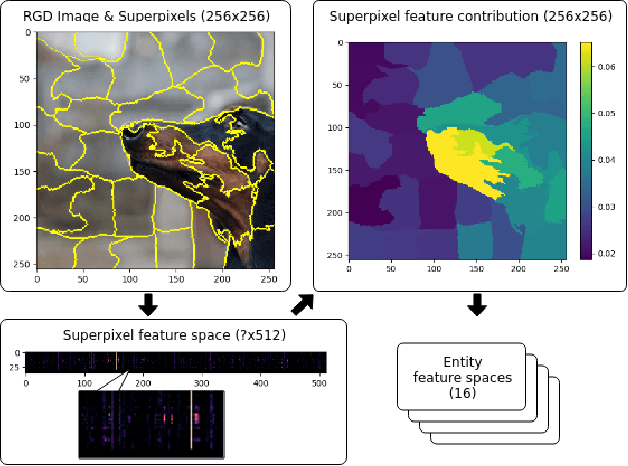
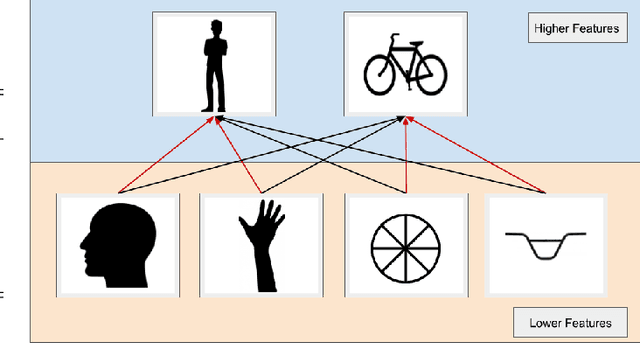

Superpixel-based methodologies have become increasingly popular in computer vision, especially when the computation is too expensive in time or memory to perform with a large number of pixels or features. However, rarely is superpixel segmentation examined within the context of deep convolutional neural network architectures. This paper presents a novel neural architecture that exploits the superpixel feature space. The visual feature space is organized using superpixels to provide the neural network with a substructure of the images. As the superpixels associate the visual feature space with parts of the objects in an image, the visual feature space is transformed into a structured vector representation per superpixel. It is shown that it is feasible to learn superpixel features using capsules and it is potentially beneficial to perform image analysis in such a structured manner. This novel deep learning architecture is examined in the context of an image classification task, highlighting explicit interpretability (explainability) of the network's decision making. The results are compared against a baseline deep neural model, as well as among superpixel capsule networks with a variety of hyperparameter settings.