 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Self-supervised Monocular Multi-robot Relative Localization with Efficient Deep Neural Networks
May 26, 2021
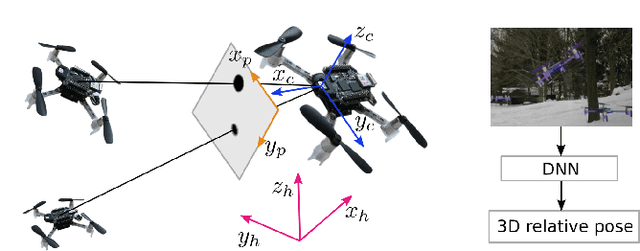
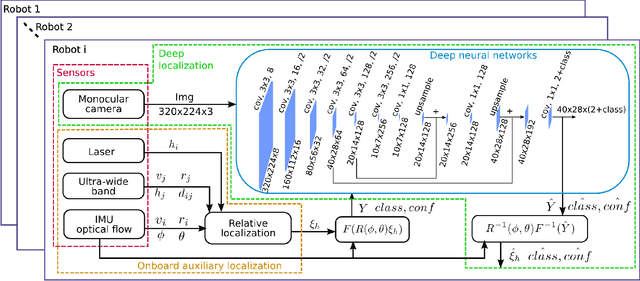
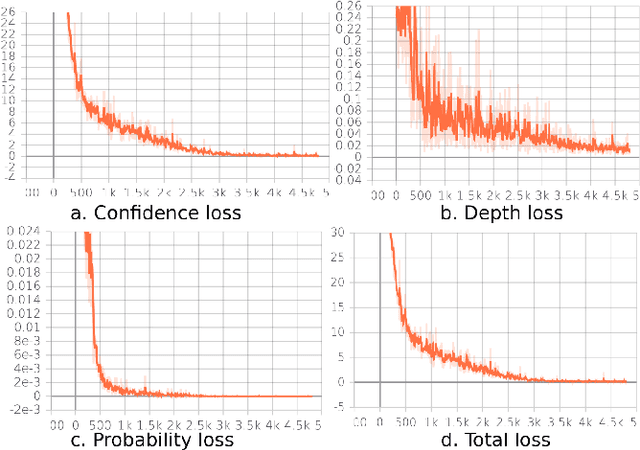

Relative localization is an important ability for multiple robots to perform cooperative tasks. This paper presents a deep neural network (DNN) for monocular relative localization between multiple tiny flying robots. This approach does not require any ground-truth data from external systems or manual labeling. Our system is able to label real-world images with 3D relative positions between robots by another onboard relative estimation technology. After the training from scratch in this self-supervised way, the DNN can predict the relative positions of peer robots by purely using the monocular image. This deep-learning based visual relative localization is scalable, distributed and autonomous. Simulation shows the pipeline for synthetic image generation for multiple robots with Blender and 3D rendering, which allows for preliminary validation of the designed network. Experiments are conducted on two Crazyflie quadrotors for dataset collection with random attitude and velocity. Training and testing of the proposed network on these real-world datasets further validate the self-supervised localization effectiveness in real environment.
An Universal Image Attractiveness Ranking Framework
Sep 19, 2018

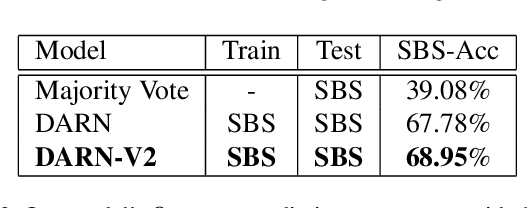
We propose a new framework to rank image attractiveness using a novel pairwise deep network trained with a large set of side-by-side multi-labeled image pairs from a web image index. The judges only provide relative ranking between two images without the need to directly assign an absolute score, or rate any predefined image attribute, thus making the rating more intuitive and straightforward. We investigate a deep attractiveness rank net (DARN), a combination of deep convolutional neural network and rank net, to directly learn an attractiveness score mean and variance for each image and the underlying criteria the judges use to label each pair. The extension of this model (DARN-V2) is able to adapt to individual judge's personal preference. We also show the attractiveness of search results are significantly improved by using this attractiveness information in a real commercial search engine. We evaluate our model against other state-of-the-art models on our side-by-side web test data and another public aesthetic data set. Our model outperforms on side-by-side labeled data, and is competitive on data labeled by absolute score.
A CNN With Multi-scale Convolution for Hyperspectral Image Classification using Target-Pixel-Orientation scheme
Feb 02, 2020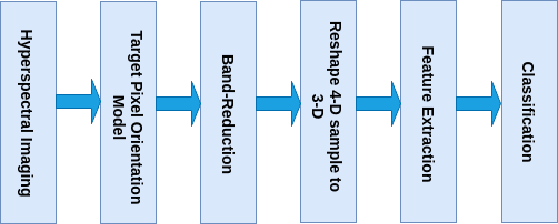

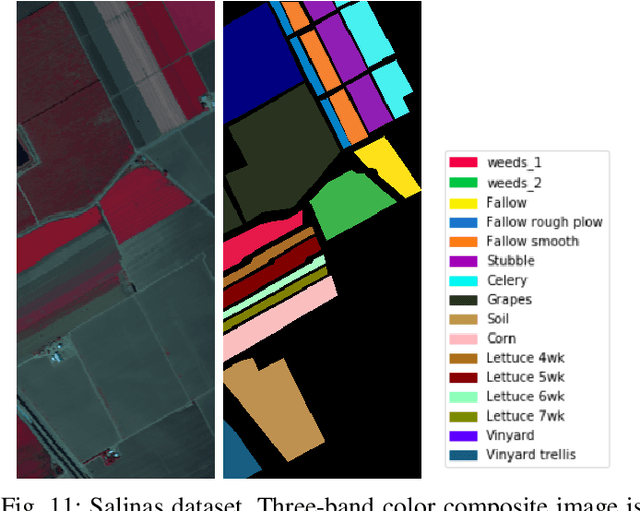
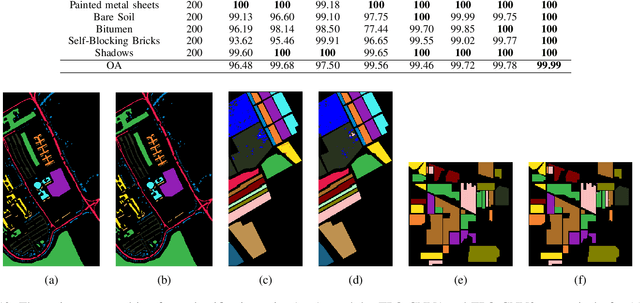
Recently, CNN is a popular choice to handle the hyperspectral image classification challenges. In spite of having such large spectral information in Hyper-Spectral Image(s) (HSI), it creates a curse of dimensionality. Also, large spatial variability of spectral signature adds more difficulty in classification problem. Additionally, training a CNN in the end to end fashion with scarced training examples is another challenging and interesting problem. In this paper, a novel target-patch-orientation method is proposed to train a CNN based network. Also, we have introduced a hybrid of 3D-CNN and 2D-CNN based network architecture to implement band reduction and feature extraction methods, respectively. Experimental results show that our method outperforms the accuracies reported in the existing state of the art methods.
MLP-Mixer: An all-MLP Architecture for Vision
May 17, 2021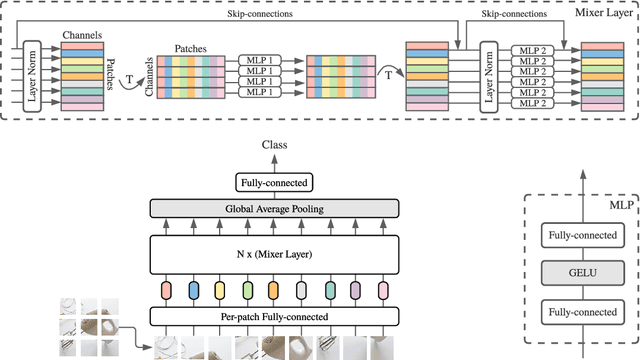
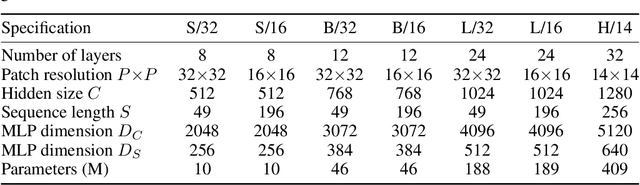
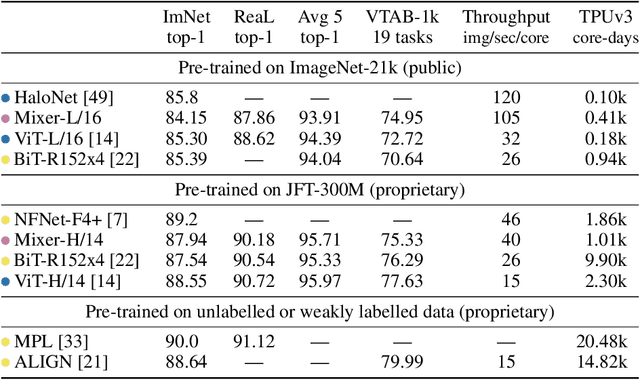
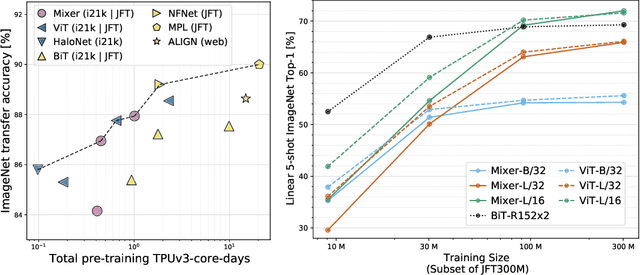
Convolutional Neural Networks (CNNs) are the go-to model for computer vision. Recently, attention-based networks, such as the Vision Transformer, have also become popular. In this paper we show that while convolutions and attention are both sufficient for good performance, neither of them are necessary. We present MLP-Mixer, an architecture based exclusively on multi-layer perceptrons (MLPs). MLP-Mixer contains two types of layers: one with MLPs applied independently to image patches (i.e. "mixing" the per-location features), and one with MLPs applied across patches (i.e. "mixing" spatial information). When trained on large datasets, or with modern regularization schemes, MLP-Mixer attains competitive scores on image classification benchmarks, with pre-training and inference cost comparable to state-of-the-art models. We hope that these results spark further research beyond the realms of well established CNNs and Transformers.
Brain Image Synthesis with Unsupervised Multivariate Canonical CSC$\ell_4$Net
Mar 22, 2021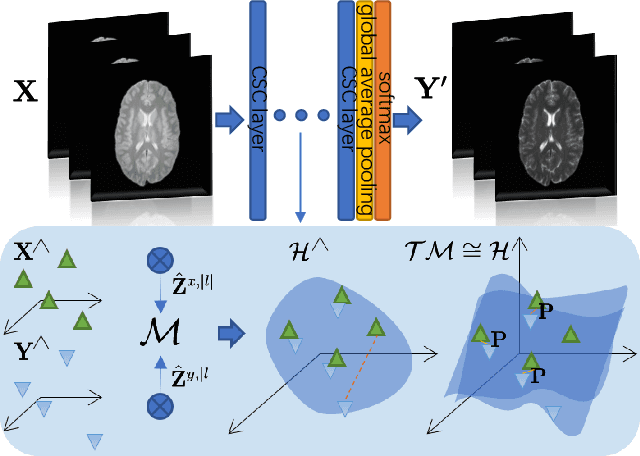
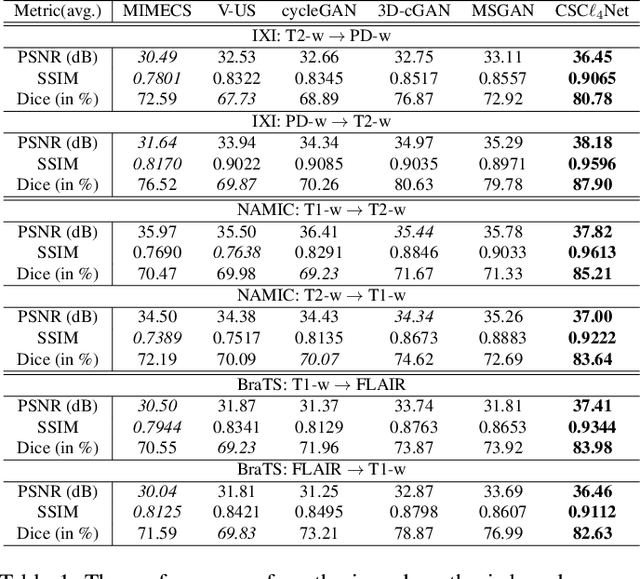
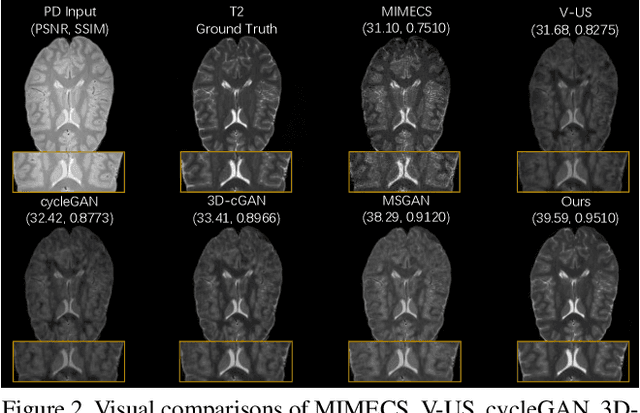
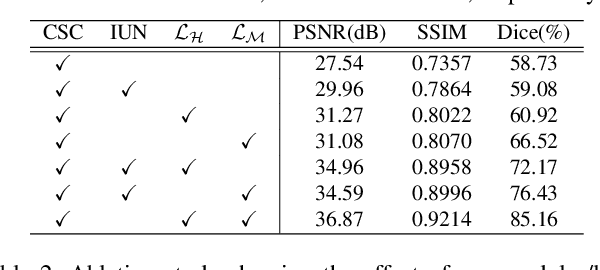
Recent advances in neuroscience have highlighted the effectiveness of multi-modal medical data for investigating certain pathologies and understanding human cognition. However, obtaining full sets of different modalities is limited by various factors, such as long acquisition times, high examination costs and artifact suppression. In addition, the complexity, high dimensionality and heterogeneity of neuroimaging data remains another key challenge in leveraging existing randomized scans effectively, as data of the same modality is often measured differently by different machines. There is a clear need to go beyond the traditional imaging-dependent process and synthesize anatomically specific target-modality data from a source input. In this paper, we propose to learn dedicated features that cross both intre- and intra-modal variations using a novel CSC$\ell_4$Net. Through an initial unification of intra-modal data in the feature maps and multivariate canonical adaptation, CSC$\ell_4$Net facilitates feature-level mutual transformation. The positive definite Riemannian manifold-penalized data fidelity term further enables CSC$\ell_4$Net to reconstruct missing measurements according to transformed features. Finally, the maximization $\ell_4$-norm boils down to a computationally efficient optimization problem. Extensive experiments validate the ability and robustness of our CSC$\ell_4$Net compared to the state-of-the-art methods on multiple datasets.
Deep Learning for Weakly-Supervised Object Detection and Object Localization: A Survey
May 26, 2021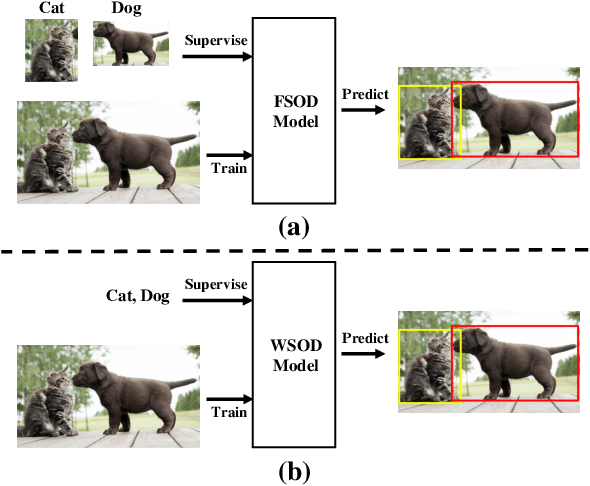
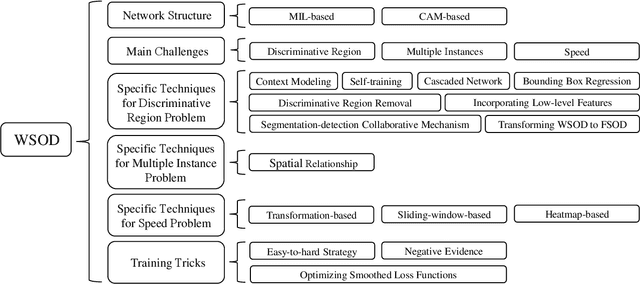

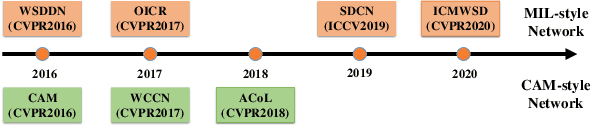
Weakly-Supervised Object Detection (WSOD) and Localization (WSOL), i.e., detecting multiple and single instances with bounding boxes in an image using image-level labels, are long-standing and challenging tasks in the CV community. With the success of deep neural networks in object detection, both WSOD and WSOL have received unprecedented attention. Hundreds of WSOD and WSOL methods and numerous techniques have been proposed in the deep learning era. To this end, in this paper, we consider WSOL is a sub-task of WSOD and provide a comprehensive survey of the recent achievements of WSOD. Specifically, we firstly describe the formulation and setting of the WSOD, including the background, challenges, basic framework. Meanwhile, we summarize and analyze all advanced techniques and training tricks for improving detection performance. Then, we introduce the widely-used datasets and evaluation metrics of WSOD. Lastly, we discuss the future directions of WSOD. We believe that these summaries can help pave a way for future research on WSOD and WSOL.
HorNet: A Hierarchical Offshoot Recurrent Network for Improving Person Re-ID via Image Captioning
Aug 14, 2019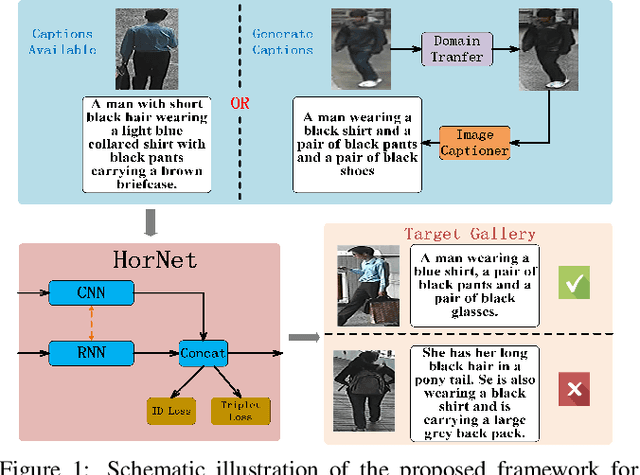
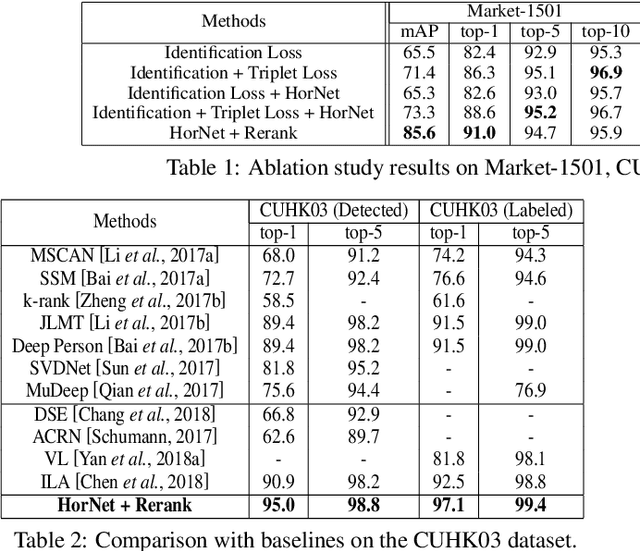
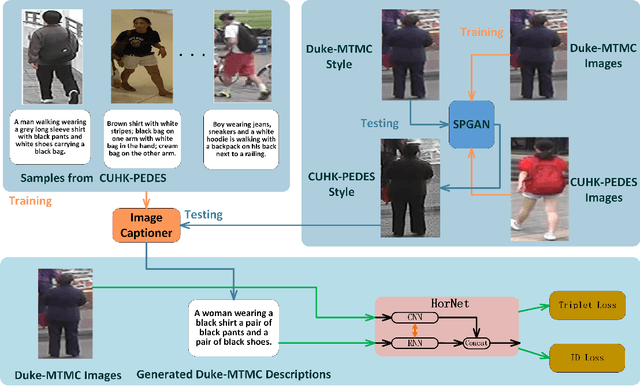
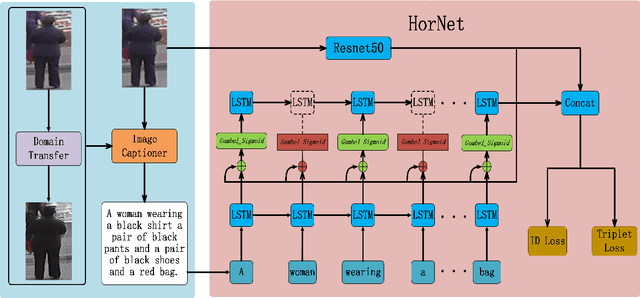
Person re-identification (re-ID) aims to recognize a person-of-interest across different cameras with notable appearance variance. Existing research works focused on the capability and robustness of visual representation. In this paper, instead, we propose a novel hierarchical offshoot recurrent network (HorNet) for improving person re-ID via image captioning. Image captions are semantically richer and more consistent than visual attributes, which could significantly alleviate the variance. We use the similarity preserving generative adversarial network (SPGAN) and an image captioner to fulfill domain transfer and language descriptions generation. Then the proposed HorNet can learn the visual and language representation from both the images and captions jointly, and thus enhance the performance of person re-ID. Extensive experiments are conducted on several benchmark datasets with or without image captions, i.e., CUHK03, Market-1501, and Duke-MTMC, demonstrating the superiority of the proposed method. Our method can generate and extract meaningful image captions while achieving state-of-the-art performance.
Improved Residual Networks for Image and Video Recognition
Apr 10, 2020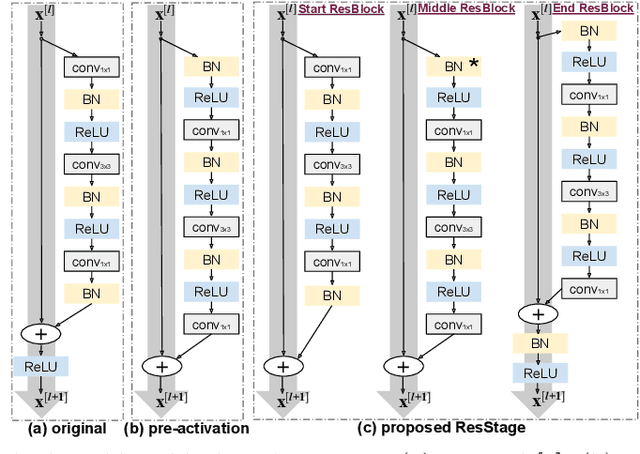
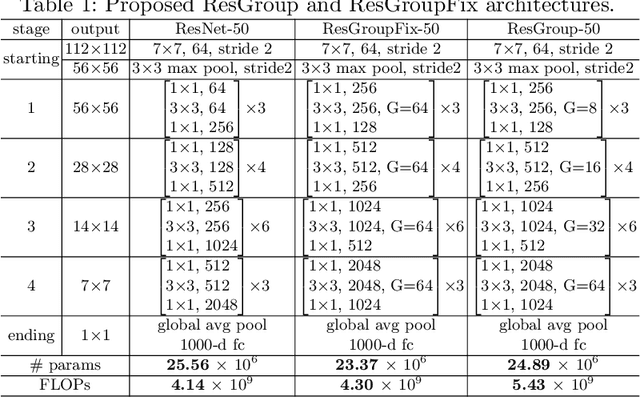
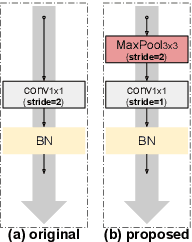
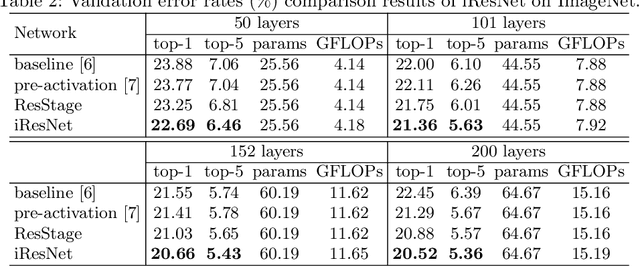
Residual networks (ResNets) represent a powerful type of convolutional neural network (CNN) architecture, widely adopted and used in various tasks. In this work we propose an improved version of ResNets. Our proposed improvements address all three main components of a ResNet: the flow of information through the network layers, the residual building block, and the projection shortcut. We are able to show consistent improvements in accuracy and learning convergence over the baseline. For instance, on ImageNet dataset, using the ResNet with 50 layers, for top-1 accuracy we can report a 1.19% improvement over the baseline in one setting and around 2% boost in another. Importantly, these improvements are obtained without increasing the model complexity. Our proposed approach allows us to train extremely deep networks, while the baseline shows severe optimization issues. We report results on three tasks over six datasets: image classification (ImageNet, CIFAR-10 and CIFAR-100), object detection (COCO) and video action recognition (Kinetics-400 and Something-Something-v2). In the deep learning era, we establish a new milestone for the depth of a CNN. We successfully train a 404-layer deep CNN on the ImageNet dataset and a 3002-layer network on CIFAR-10 and CIFAR-100, while the baseline is not able to converge at such extreme depths. Code is available at: https://github.com/iduta/iresnet
Abstract Reasoning via Logic-guided Generation
Aug 11, 2021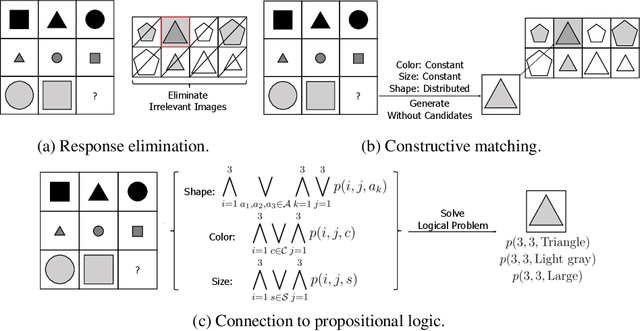
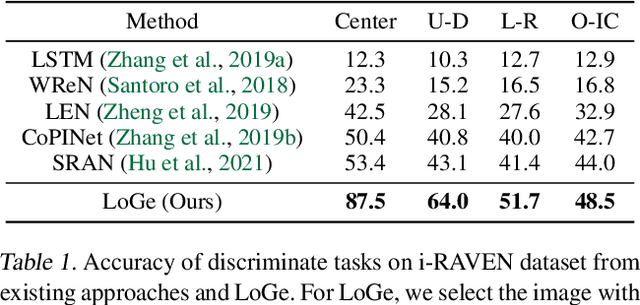
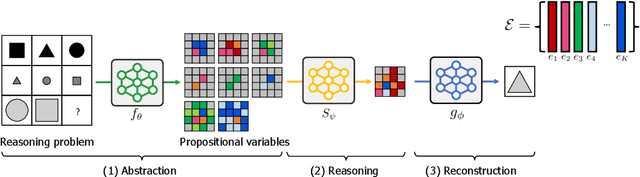
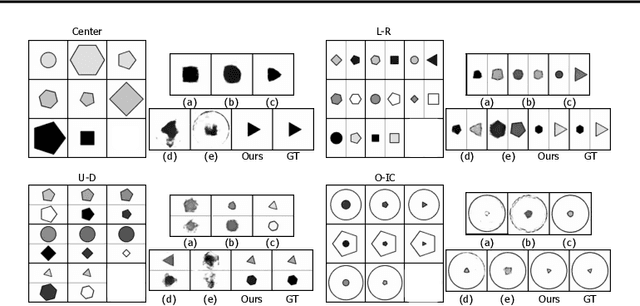
Abstract reasoning, i.e., inferring complicated patterns from given observations, is a central building block of artificial general intelligence. While humans find the answer by either eliminating wrong candidates or first constructing the answer, prior deep neural network (DNN)-based methods focus on the former discriminative approach. This paper aims to design a framework for the latter approach and bridge the gap between artificial and human intelligence. To this end, we propose logic-guided generation (LoGe), a novel generative DNN framework that reduces abstract reasoning as an optimization problem in propositional logic. LoGe is composed of three steps: extract propositional variables from images, reason the answer variables with a logic layer, and reconstruct the answer image from the variables. We demonstrate that LoGe outperforms the black box DNN frameworks for generative abstract reasoning under the RAVEN benchmark, i.e., reconstructing answers based on capturing correct rules of various attributes from observations.
Prediction of MRI Hardware Failures based on Image Features using Time Series Classification
Jan 05, 2020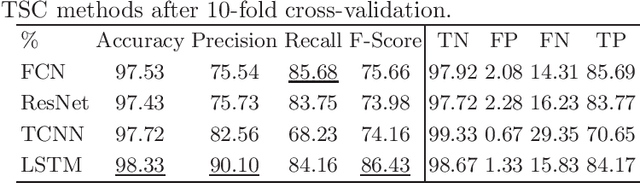
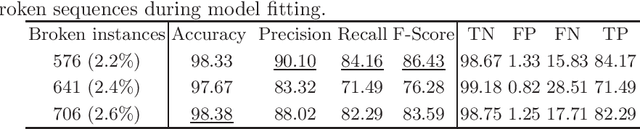
Already before systems malfunction one has to know if hardware components will fail in near future in order to counteract in time. Thus, unplanned downtime is ought to be avoided. In medical imaging, maximizing the system's uptime is crucial for patients' health and healthcare provider's daily business. We aim to predict failures of Head/Neck coils used in Magnetic Resonance Imaging (MRI) by training a statistical model on sequential data collected over time. As image features depend on the coil's condition, their deviations from the normal range already hint to future failure. Thus, we used image features and their variation over time to predict coil damage. After comparison of different time series classification methods we found Long Short Term Memorys (LSTMs) to achieve the highest F-score of 86.43% and to tell with 98.33% accuracy if hardware should be replaced.