 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Residual Networks for Image and Video Recognition
Paper and Code
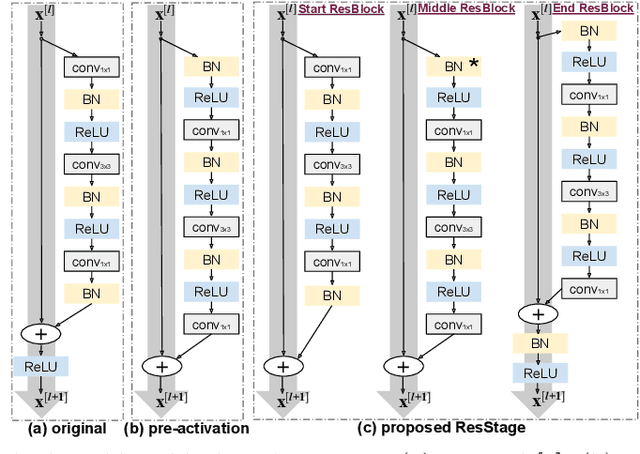
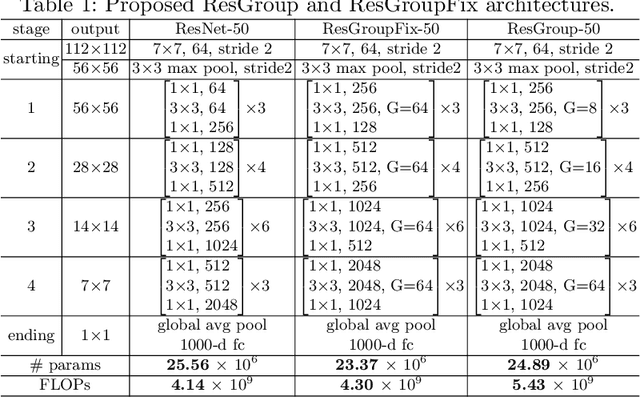
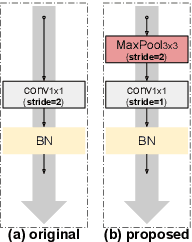
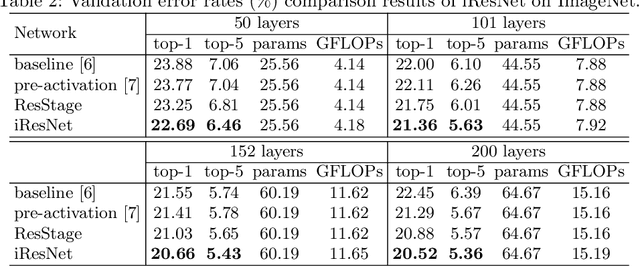
Residual networks (ResNets) represent a powerful type of convolutional neural network (CNN) architecture, widely adopted and used in various tasks. In this work we propose an improved version of ResNets. Our proposed improvements address all three main components of a ResNet: the flow of information through the network layers, the residual building block, and the projection shortcut. We are able to show consistent improvements in accuracy and learning convergence over the baseline. For instance, on ImageNet dataset, using the ResNet with 50 layers, for top-1 accuracy we can report a 1.19% improvement over the baseline in one setting and around 2% boost in another. Importantly, these improvements are obtained without increasing the model complexity. Our proposed approach allows us to train extremely deep networks, while the baseline shows severe optimization issues. We report results on three tasks over six datasets: image classification (ImageNet, CIFAR-10 and CIFAR-100), object detection (COCO) and video action recognition (Kinetics-400 and Something-Something-v2). In the deep learning era, we establish a new milestone for the depth of a CNN. We successfully train a 404-layer deep CNN on the ImageNet dataset and a 3002-layer network on CIFAR-10 and CIFAR-100, while the baseline is not able to converge at such extreme depths. Code is available at: https://github.com/iduta/iresnet