 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SAIL-VOS 3D: A Synthetic Dataset and Baselines for Object Detection and 3D Mesh Reconstruction from Video Data
May 18, 2021
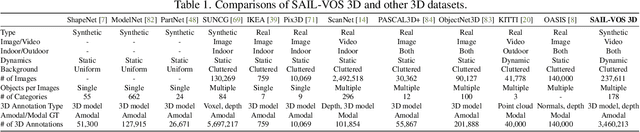
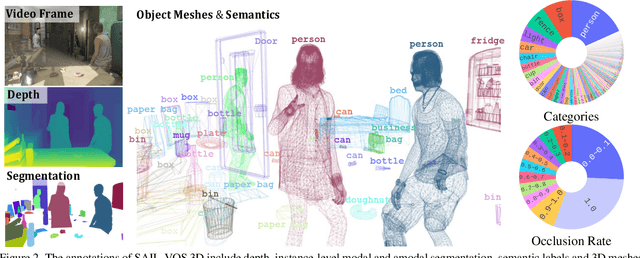

Extracting detailed 3D information of objects from video data is an important goal for holistic scene understanding. While recent methods have shown impressive results when reconstructing meshes of objects from a single image, results often remain ambiguous as part of the object is unobserved. Moreover, existing image-based datasets for mesh reconstruction don't permit to study models which integrate temporal information. To alleviate both concerns we present SAIL-VOS 3D: a synthetic video dataset with frame-by-frame mesh annotations which extends SAIL-VOS. We also develop first baselines for reconstruction of 3D meshes from video data via temporal models. We demonstrate efficacy of the proposed baseline on SAIL-VOS 3D and Pix3D, showing that temporal information improves reconstruction quality. Resources and additional information are available at http://sailvos.web.illinois.edu.
Which Ads to Show? Advertisement Image Assessment with Auxiliary Information via Multi-step Modality Fusion
Oct 06, 2019
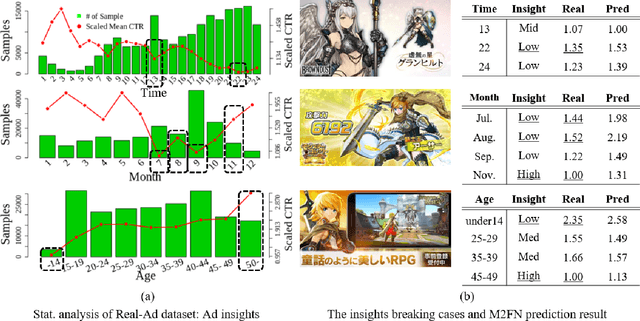
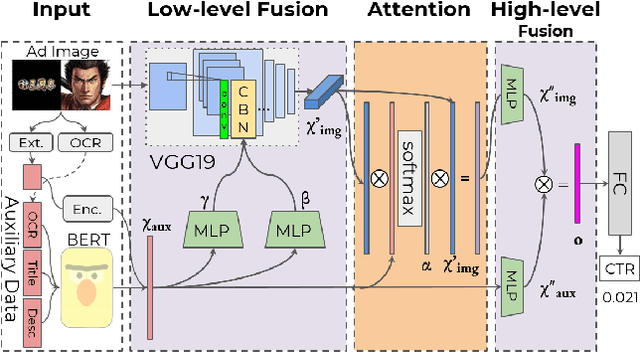
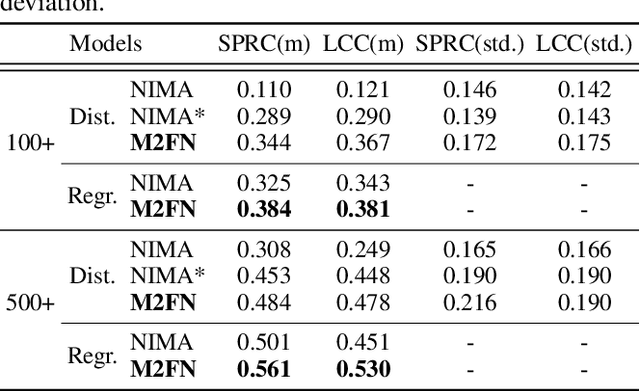
Assessing aesthetic preference is a fundamental task related to human cognition. It can also contribute to various practical applications such as image creation for online advertisements. Despite crucial influences of image quality, auxiliary information of ad images such as tags and target subjects can also determine image preference. Existing studies mainly focus on images and thus are less useful for advertisement scenarios where rich auxiliary data are available. Here we propose a modality fusion-based neural network that evaluates the aesthetic preference of images with auxiliary information. Our method fully utilizes auxiliary data by introducing multi-step modality fusion using both conditional batch normalization-based low-level and attention-based high-level fusion mechanisms, inspired by the findings from statistical analyses on real advertisement data. Our approach achieved state-of-the-art performance on the AVA dataset, a widely used dataset for aesthetic assessment. Besides, the proposed method is evaluated on large-scale real-world advertisement image data with rich auxiliary attributes, providing promising preference prediction results. Through extensive experiments, we investigate how image and auxiliary information together influence click-through rate.
Slot Based Image Augmentation System for Object Detection
Jul 19, 2019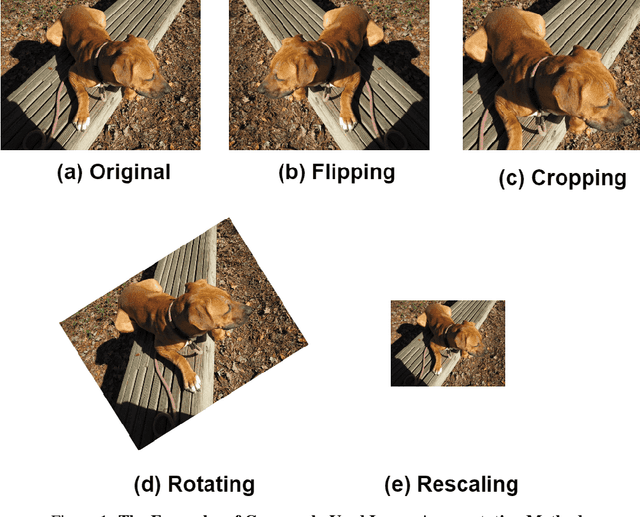
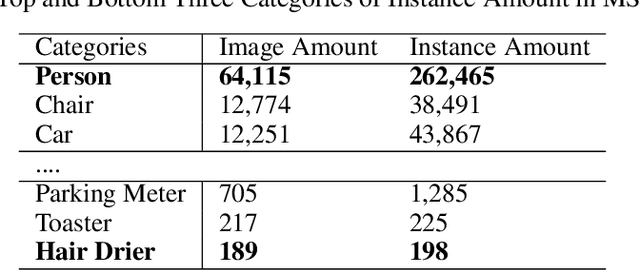
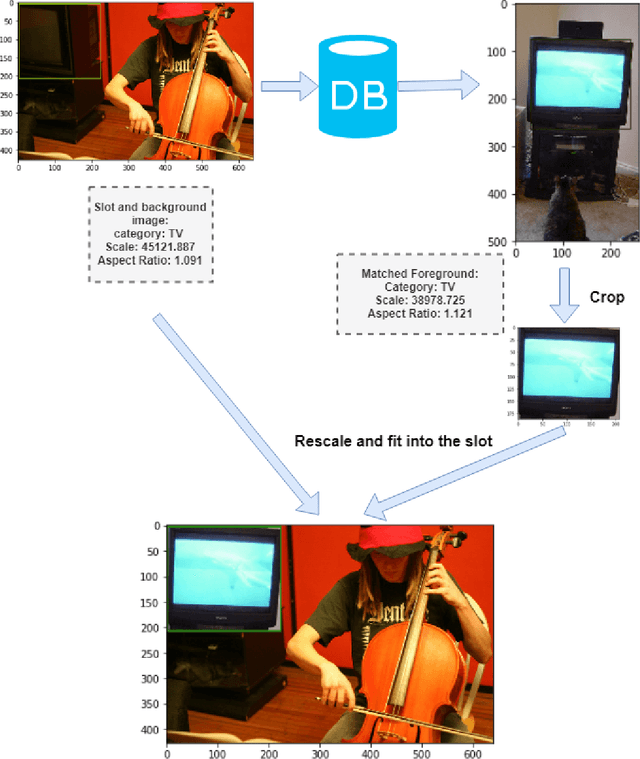

Object Detection has been a significant topic in computer vision. As the continuous development of Deep Learning, many advanced academic and industrial outcomes are established on localising and classifying the target objects, such as instance segmentation, video tracking and robotic vision. As the core concept of Deep Learning, Deep Neural Networks (DNNs) and associated training are highly integrated with task-driven modelling, having great effects on accurate detection. The main focus of improving detection performance is proposing DNNs with extra layers and novel topological connections to extract the desired features from input data. However, training these models can be computationally expensive and laborious progress as the complicated model architecture and enormous parameters. Besides, the dataset is another reason causing this issue and low detection accuracy, because of insufficient data samples or difficult instances. To address these training difficulties, this thesis presents two different approaches to improve the detection performance in the relatively light-weight way. As the intrinsic feature of data-driven in deep learning, the first approach is "slot-based image augmentation" to enrich the dataset with extra foreground and background combinations. Instead of the commonly used image flipping method, the proposed system achieved similar mAP improvement with less extra images which decrease training time. This proposed augmentation system has extra flexibility adapting to various scenarios and the performance-driven analysis provides an alternative aspect of conducting image augmentation
Emerging Disentanglement in Auto-Encoder Based Unsupervised Image Content Transfer
Jan 14, 2020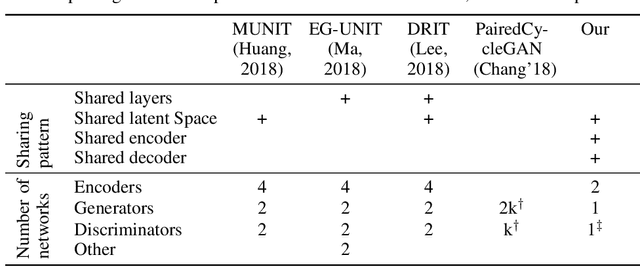
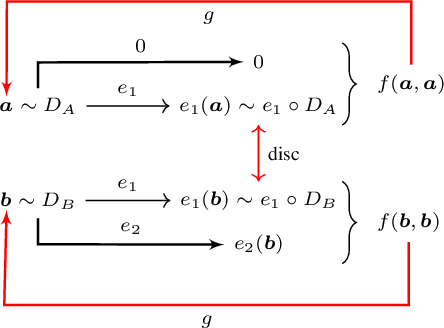


We study the problem of learning to map, in an unsupervised way, between domains A and B, such that the samples b in B contain all the information that exists in samples a in A and some additional information. For example, ignoring occlusions, B can be people with glasses, A people without, and the glasses, would be the added information. When mapping a sample a from the first domain to the other domain, the missing information is replicated from an independent reference sample b in B. Thus, in the above example, we can create, for every person without glasses a version with the glasses observed in any face image. Our solution employs a single two-pathway encoder and a single decoder for both domains. The common part of the two domains and the separate part are encoded as two vectors, and the separate part is fixed at zero for domain A. The loss terms are minimal and involve reconstruction losses for the two domains and a domain confusion term. Our analysis shows that under mild assumptions, this architecture, which is much simpler than the literature guided-translation methods, is enough to ensure disentanglement between the two domains. We present convincing results in a few visual domains, such as no-glasses to glasses, adding facial hair based on a reference image, etc.
NewsCLIPpings: Automatic Generation of Out-of-Context Multimodal Media
Apr 13, 2021
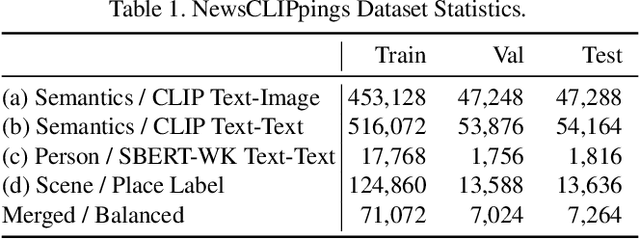

The threat of online misinformation is hard to overestimate, with adversaries relying on a range of tools, from cheap fakes to sophisticated deep fakes. We are motivated by a threat scenario where an image is being used out of context to support a certain narrative expressed in a caption. While some prior datasets for detecting image-text inconsistency can be solved with blind models due to linguistic cues introduced by text manipulation, we propose a dataset where both image and text are unmanipulated but mismatched. We introduce several strategies for automatic retrieval of suitable images for the given captions, capturing cases with related semantics but inconsistent entities as well as matching entities but inconsistent semantic context. Our large-scale automatically generated NewsCLIPpings Dataset requires models to jointly analyze both modalities and to reason about entity mismatch as well as semantic mismatch between text and images in news media.
A Workflow for Offline Model-Free Robotic Reinforcement Learning
Sep 23, 2021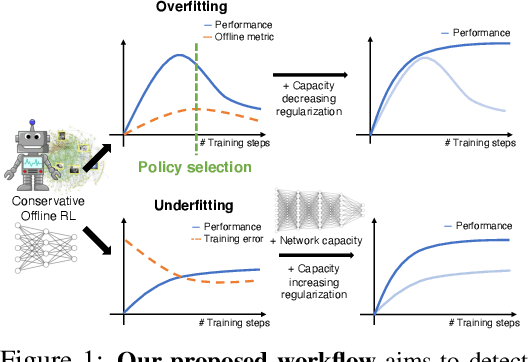

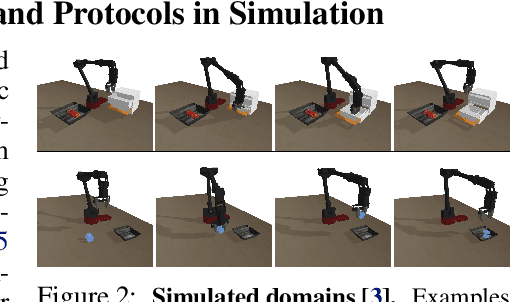
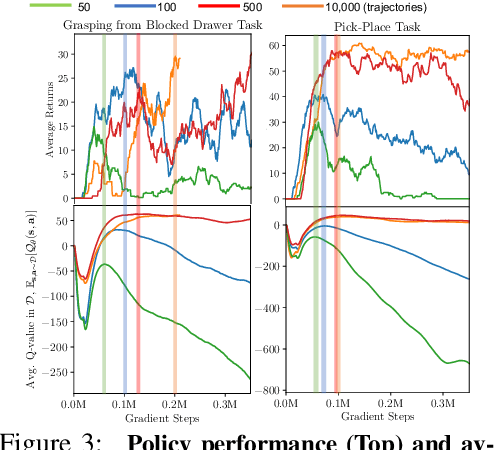
Offline reinforcement learning (RL) enables learning control policies by utilizing only prior experience, without any online interaction. This can allow robots to acquire generalizable skills from large and diverse datasets, without any costly or unsafe online data collection. Despite recent algorithmic advances in offline RL, applying these methods to real-world problems has proven challenging. Although offline RL methods can learn from prior data, there is no clear and well-understood process for making various design choices, from model architecture to algorithm hyperparameters, without actually evaluating the learned policies online. In this paper, our aim is to develop a practical workflow for using offline RL analogous to the relatively well-understood workflows for supervised learning problems. To this end, we devise a set of metrics and conditions that can be tracked over the course of offline training, and can inform the practitioner about how the algorithm and model architecture should be adjusted to improve final performance. Our workflow is derived from a conceptual understanding of the behavior of conservative offline RL algorithms and cross-validation in supervised learning. We demonstrate the efficacy of this workflow in producing effective policies without any online tuning, both in several simulated robotic learning scenarios and for three tasks on two distinct real robots, focusing on learning manipulation skills with raw image observations with sparse binary rewards. Explanatory video and additional results can be found at sites.google.com/view/offline-rl-workflow
Residual Dense Network for Image Restoration
Dec 25, 2018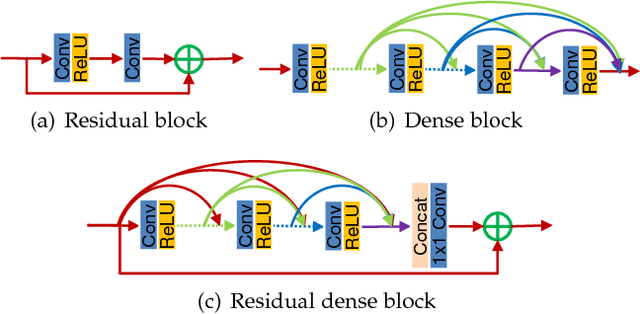
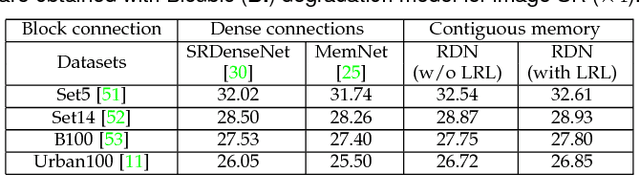
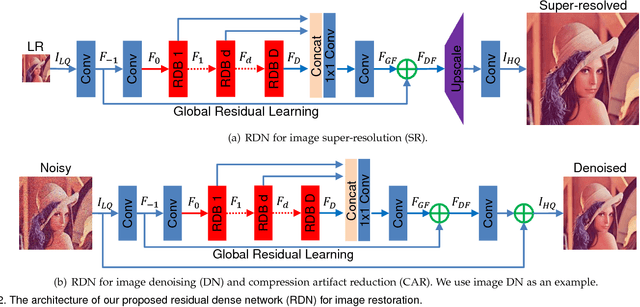
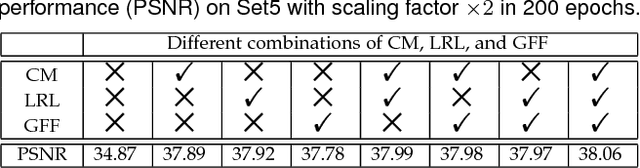
Convolutional neural network has recently achieved great success for image restoration (IR) and also offered hierarchical features. However, most deep CNN based IR models do not make full use of the hierarchical features from the original low-quality images, thereby achieving relatively-low performance. In this paper, we propose a novel residual dense network (RDN) to address this problem in IR. We fully exploit the hierarchical features from all the convolutional layers. Specifically, we propose residual dense block (RDB) to extract abundant local features via densely connected convolutional layers. RDB further allows direct connections from the state of preceding RDB to all the layers of current RDB, leading to a contiguous memory mechanism. To adaptively learn more effective features from preceding and current local features and stabilize the training of wider network, we proposed local feature fusion in RDB. After fully obtaining dense local features, we use global feature fusion to jointly and adaptively learn global hierarchical features in a holistic way. We demonstrate the effectiveness of RDN with three representative IR applications, single image super-resolution, Gaussian image denoising, and image compression artifact reduction. Experiments on benchmark datasets show that our RDN achieves favorable performance against state-of-the-art methods for each IR task.
On the Robustness of Pretraining and Self-Supervision for a Deep Learning-based Analysis of Diabetic Retinopathy
Jun 25, 2021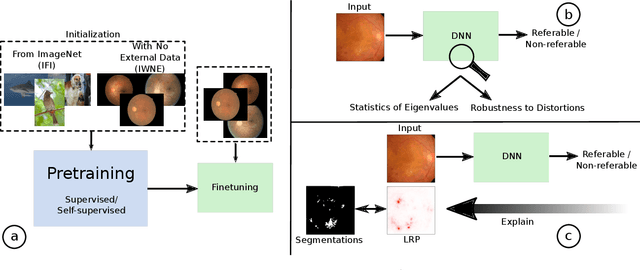

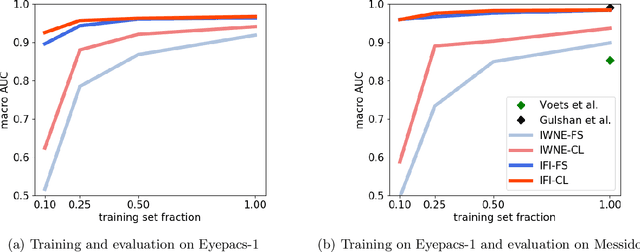
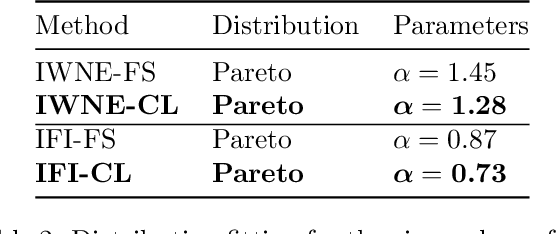
There is an increasing number of medical use-cases where classification algorithms based on deep neural networks reach performance levels that are competitive with human medical experts. To alleviate the challenges of small dataset sizes, these systems often rely on pretraining. In this work, we aim to assess the broader implications of these approaches. For diabetic retinopathy grading as exemplary use case, we compare the impact of different training procedures including recently established self-supervised pretraining methods based on contrastive learning. To this end, we investigate different aspects such as quantitative performance, statistics of the learned feature representations, interpretability and robustness to image distortions. Our results indicate that models initialized from ImageNet pretraining report a significant increase in performance, generalization and robustness to image distortions. In particular, self-supervised models show further benefits to supervised models. Self-supervised models with initialization from ImageNet pretraining not only report higher performance, they also reduce overfitting to large lesions along with improvements in taking into account minute lesions indicative of the progression of the disease. Understanding the effects of pretraining in a broader sense that goes beyond simple performance comparisons is of crucial importance for the broader medical imaging community beyond the use-case considered in this work.
Towards Understanding the Generative Capability of Adversarially Robust Classifiers
Aug 20, 2021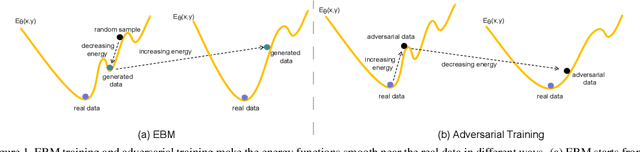
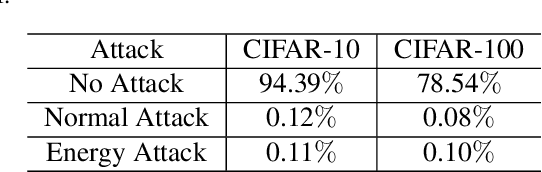
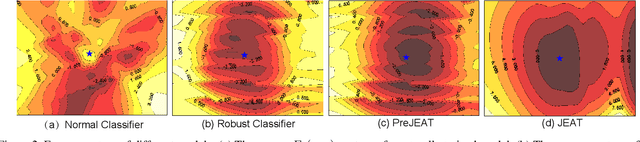
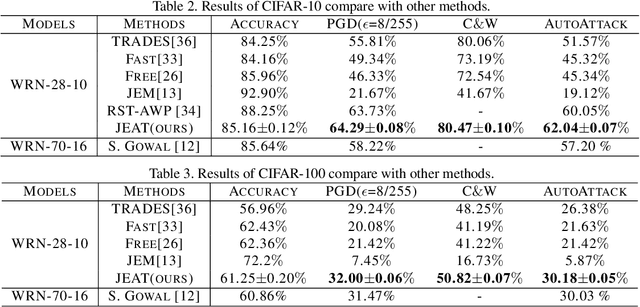
Recently, some works found an interesting phenomenon that adversarially robust classifiers can generate good images comparable to generative models. We investigate this phenomenon from an energy perspective and provide a novel explanation. We reformulate adversarial example generation, adversarial training, and image generation in terms of an energy function. We find that adversarial training contributes to obtaining an energy function that is flat and has low energy around the real data, which is the key for generative capability. Based on our new understanding, we further propose a better adversarial training method, Joint Energy Adversarial Training (JEAT), which can generate high-quality images and achieve new state-of-the-art robustness under a wide range of attacks. The Inception Score of the images (CIFAR-10) generated by JEAT is 8.80, much better than original robust classifiers (7.50). In particular, we achieve new state-of-the-art robustness on CIFAR-10 (from 57.20% to 62.04%) and CIFAR-100 (from 30.03% to 30.18%) without extra training data.
Representation Memorization for Fast Learning New Knowledge without Forgetting
Aug 28, 2021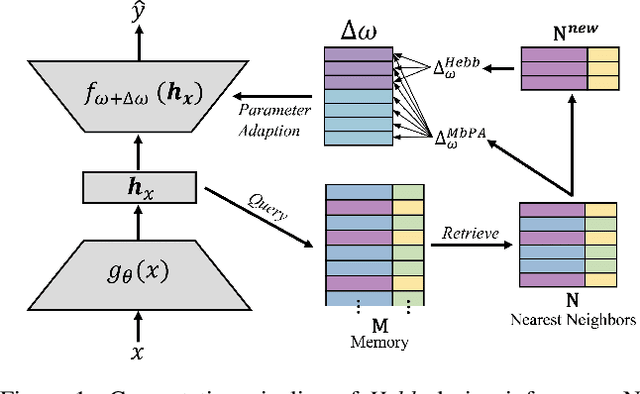
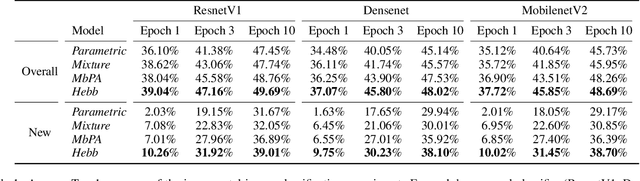
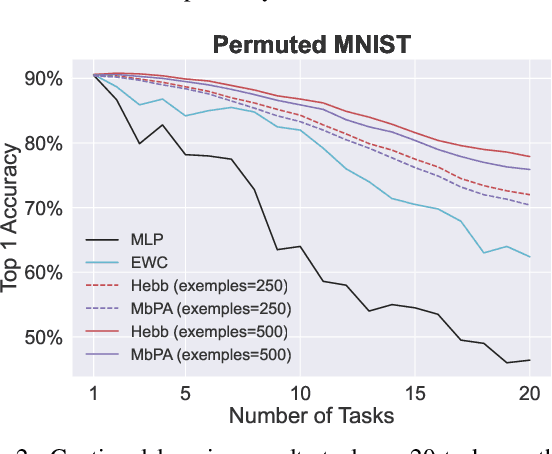
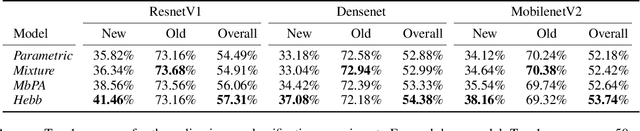
The ability to quickly learn new knowledge (e.g. new classes or data distributions) is a big step towards human-level intelligence. In this paper, we consider scenarios that require learning new classes or data distributions quickly and incrementally over time, as it often occurs in real-world dynamic environments. We propose "Memory-based Hebbian Parameter Adaptation" (Hebb) to tackle the two major challenges (i.e., catastrophic forgetting and sample efficiency) towards this goal in a unified framework. To mitigate catastrophic forgetting, Hebb augments a regular neural classifier with a continuously updated memory module to store representations of previous data. To improve sample efficiency, we propose a parameter adaptation method based on the well-known Hebbian theory, which directly "wires" the output network's parameters with similar representations retrieved from the memory. We empirically verify the superior performance of Hebb through extensive experiments on a wide range of learning tasks (image classification, language model) and learning scenarios (continual, incremental, online). We demonstrate that Hebb effectively mitigates catastrophic forgetting, and it indeed learns new knowledge better and faster than the current state-of-the-art.