 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Auxiliary Learning for Graph Neural Networks via Meta-Learning
Mar 01, 2021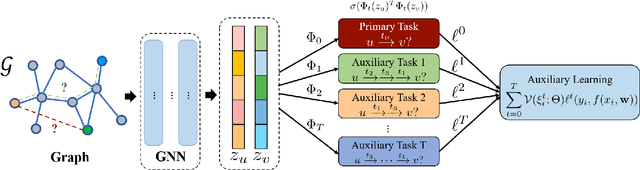
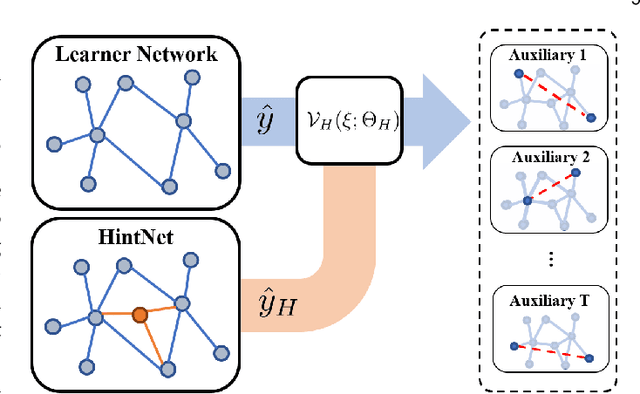
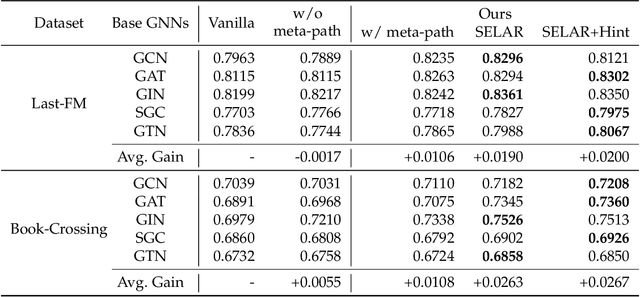
In recent years, graph neural networks (GNNs) have been widely adopted in representation learning of graph-structured data and provided state-of-the-art performance in various application such as link prediction and node classification. Simultaneously, self-supervised learning has been studied to some extent to leverage rich unlabeled data in representation learning on graphs. However, employing self-supervision tasks as auxiliary tasks to assist a primary task has been less explored in the literature on graphs. In this paper, we propose a novel self-supervised auxiliary learning framework to effectively learn graph neural networks. Moreover, we design first a meta-path prediction as a self-supervised auxiliary task for heterogeneous graphs. Our method is learning to learn a primary task with various auxiliary tasks to improve generalization performance. The proposed method identifies an effective combination of auxiliary tasks and automatically balances them to improve the primary task. Our methods can be applied to any graph neural networks in a plug-in manner without manual labeling or additional data. Also, it can be extended to any other auxiliary tasks. Our experiments demonstrate that the proposed method consistently improves the performance of link prediction and node classification on heterogeneous graphs.
M2FN: Multi-step Modality Fusion for Advertisement Image Assessment
Feb 09, 2021
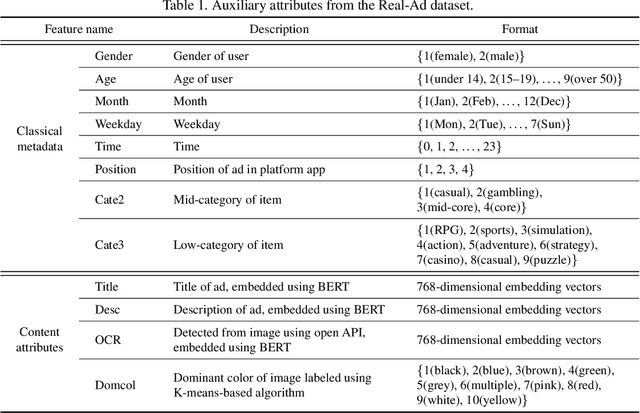
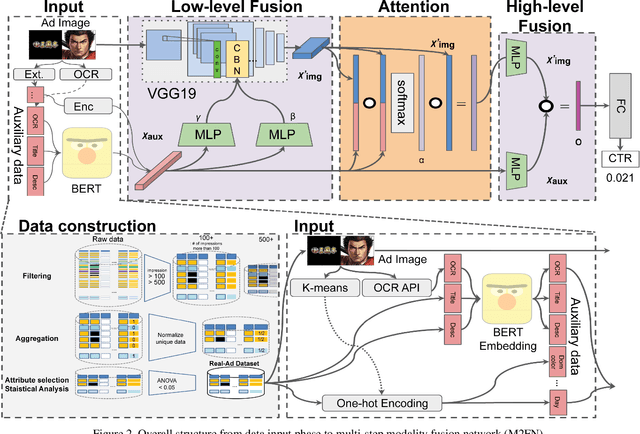
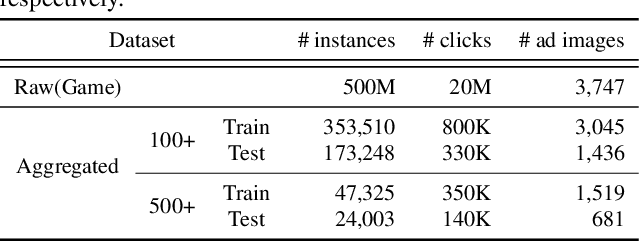
Assessing advertisements, specifically on the basis of user preferences and ad quality, is crucial to the marketing industry. Although recent studies have attempted to use deep neural networks for this purpose, these studies have not utilized image-related auxiliary attributes, which include embedded text frequently found in ad images. We, therefore, investigated the influence of these attributes on ad image preferences. First, we analyzed large-scale real-world ad log data and, based on our findings, proposed a novel multi-step modality fusion network (M2FN) that determines advertising images likely to appeal to user preferences. Our method utilizes auxiliary attributes through multiple steps in the network, which include conditional batch normalization-based low-level fusion and attention-based high-level fusion. We verified M2FN on the AVA dataset, which is widely used for aesthetic image assessment, and then demonstrated that M2FN can achieve state-of-the-art performance in preference prediction using a real-world ad dataset with rich auxiliary attributes.
Self-supervised Auxiliary Learning with Meta-paths for Heterogeneous Graphs
Aug 18, 2020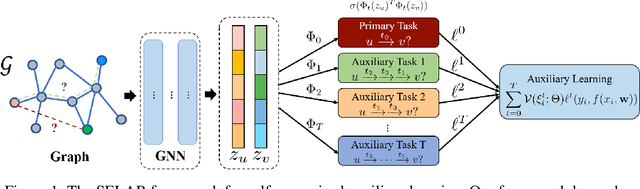
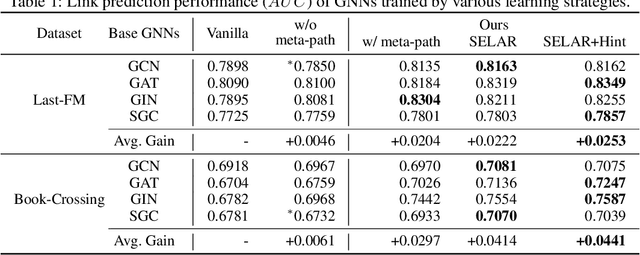
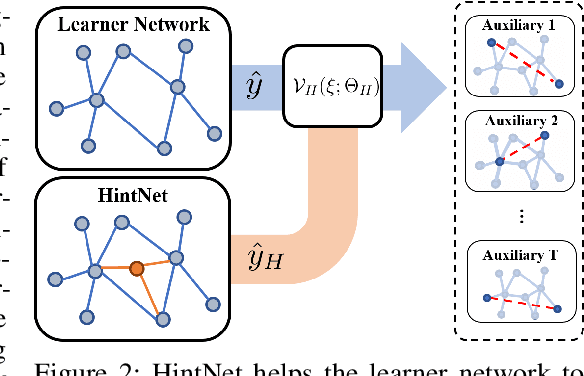
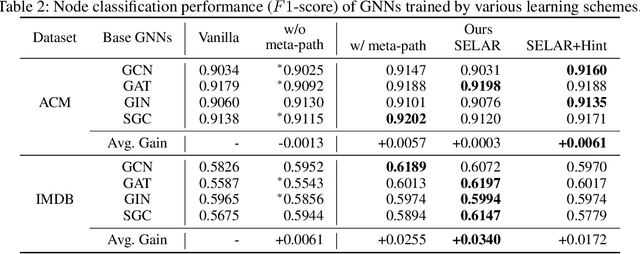
Graph neural networks have shown superior performance in a wide range of applications providing a powerful representation of graph-structured data. Recent works show that the representation can be further improved by auxiliary tasks. However, the auxiliary tasks for heterogeneous graphs, which contain rich semantic information with various types of nodes and edges, have less explored in the literature. In this paper, to learn graph neural networks on heterogeneous graphs we propose a novel self-supervised auxiliary learning method using meta-paths, which are composite relations of multiple edge types. Our proposed method is learning to learn a primary task by predicting meta-paths as auxiliary tasks. This can be viewed as a type of meta-learning. The proposed method can identify an effective combination of auxiliary tasks and automatically balance them to improve the primary task. Our methods can be applied to any graph neural networks in a plug-in manner without manual labeling or additional data. The experiments demonstrate that the proposed method consistently improves the performance of link prediction and node classification on heterogeneous graphs.
Which Strategies Matter for Noisy Label Classification? Insight into Loss and Uncertainty
Aug 14, 2020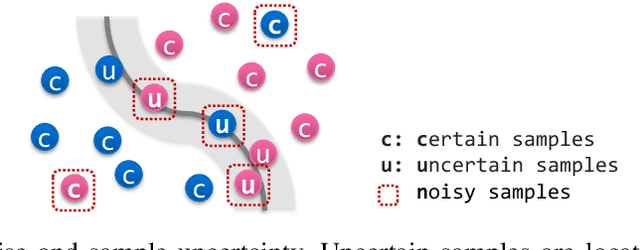
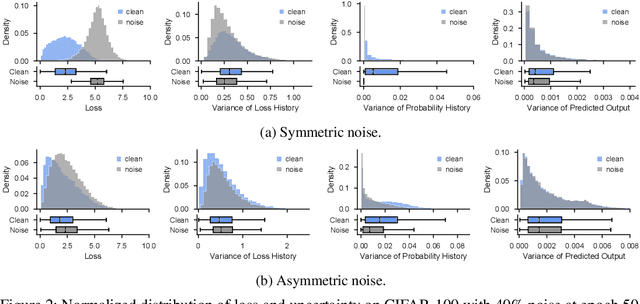
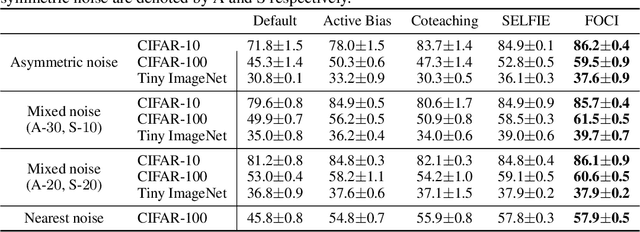
Label noise is a critical factor that degrades the generalization performance of deep neural networks, thus leading to severe issues in real-world problems. Existing studies have employed strategies based on either loss or uncertainty to address noisy labels, and ironically some strategies contradict each other: emphasizing or discarding uncertain samples or concentrating on high or low loss samples. To elucidate how opposing strategies can enhance model performance and offer insights into training with noisy labels, we present analytical results on how loss and uncertainty values of samples change throughout the training process. From the in-depth analysis, we design a new robust training method that emphasizes clean and informative samples, while minimizing the influence of noise using both loss and uncertainty. We demonstrate the effectiveness of our method with extensive experiments on synthetic and real-world datasets for various deep learning models. The results show that our method significantly outperforms other state-of-the-art methods and can be used generally regardless of neural network architectures.
Multi-Manifold Learning for Large-scale Targeted Advertising System
Jul 08, 2020
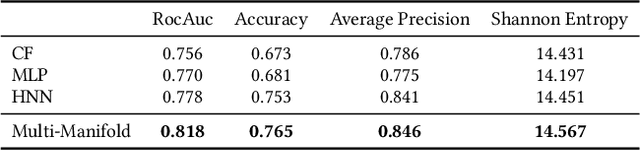
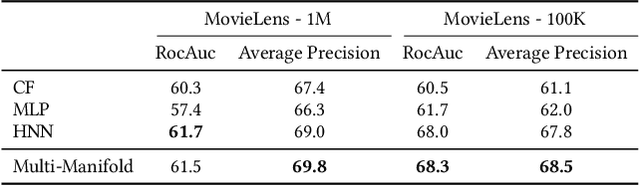
Messenger advertisements (ads) give direct and personal user experience yielding high conversion rates and sales. However, people are skeptical about ads and sometimes perceive them as spam, which eventually leads to a decrease in user satisfaction. Targeted advertising, which serves ads to individuals who may exhibit interest in a particular advertising message, is strongly required. The key to the success of precise user targeting lies in learning the accurate user and ad representation in the embedding space. Most of the previous studies have limited the representation learning in the Euclidean space, but recent studies have suggested hyperbolic manifold learning for the distinct projection of complex network properties emerging from real-world datasets such as social networks, recommender systems, and advertising. We propose a framework that can effectively learn the hierarchical structure in users and ads on the hyperbolic space, and extend to the Multi-Manifold Learning. Our method constructs multiple hyperbolic manifolds with learnable curvatures and maps the representation of user and ad to each manifold. The origin of each manifold is set as the centroid of each user cluster. The user preference for each ad is estimated using the distance between two entities in the hyperbolic space, and the final prediction is determined by aggregating the values calculated from the learned multiple manifolds. We evaluate our method on public benchmark datasets and a large-scale commercial messenger system LINE, and demonstrate its effectiveness through improved performance.
* Accepted at AdKDD 2020
Graphs, Entities, and Step Mixture
May 18, 2020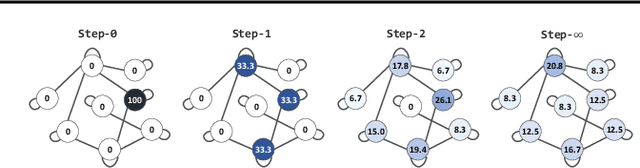
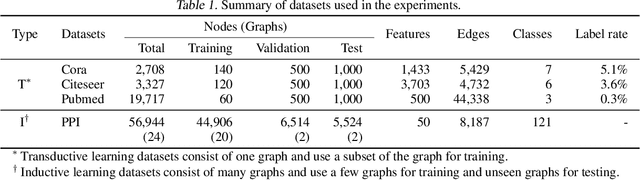
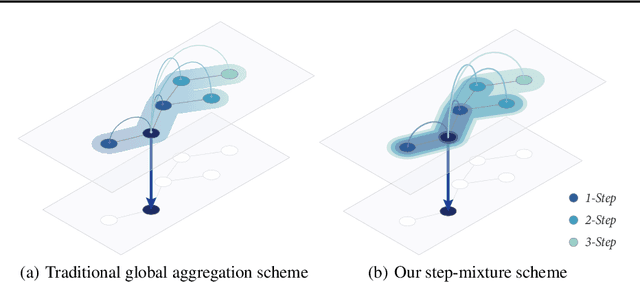
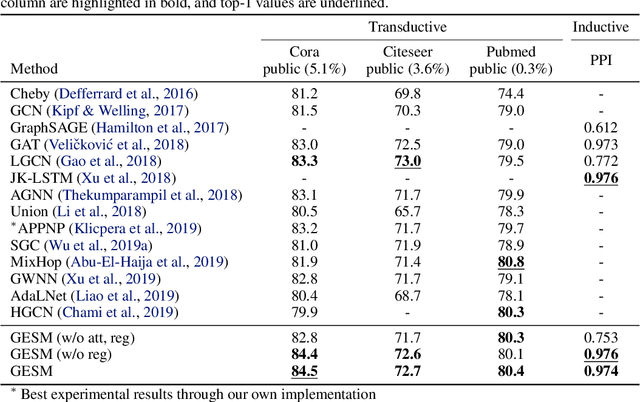
Existing approaches for graph neural networks commonly suffer from the oversmoothing issue, regardless of how neighborhoods are aggregated. Most methods also focus on transductive scenarios for fixed graphs, leading to poor generalization for unseen graphs. To address these issues, we propose a new graph neural network that considers both edge-based neighborhood relationships and node-based entity features, i.e. Graph Entities with Step Mixture via random walk (GESM). GESM employs a mixture of various steps through random walk to alleviate the oversmoothing problem, attention to dynamically reflect interrelations depending on node information, and structure-based regularization to enhance embedding representation. With intensive experiments, we show that the proposed GESM achieves state-of-the-art or comparable performances on eight benchmark graph datasets comprising transductive and inductive learning tasks. Furthermore, we empirically demonstrate the significance of considering global information.
Which Ads to Show? Advertisement Image Assessment with Auxiliary Information via Multi-step Modality Fusion
Oct 06, 2019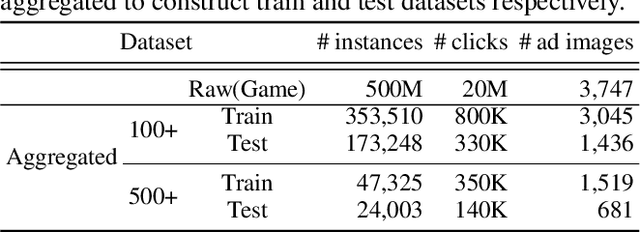
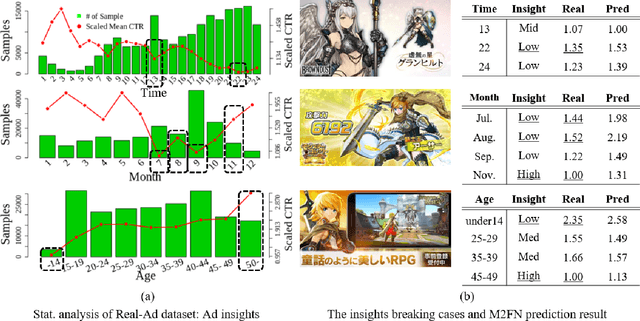
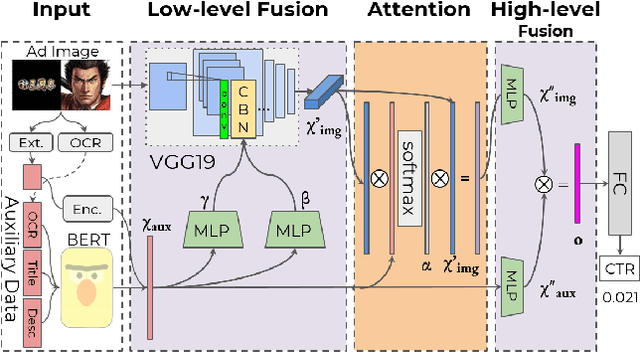
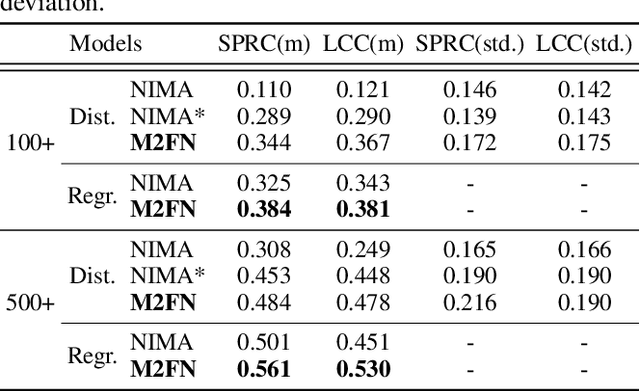
Assessing aesthetic preference is a fundamental task related to human cognition. It can also contribute to various practical applications such as image creation for online advertisements. Despite crucial influences of image quality, auxiliary information of ad images such as tags and target subjects can also determine image preference. Existing studies mainly focus on images and thus are less useful for advertisement scenarios where rich auxiliary data are available. Here we propose a modality fusion-based neural network that evaluates the aesthetic preference of images with auxiliary information. Our method fully utilizes auxiliary data by introducing multi-step modality fusion using both conditional batch normalization-based low-level and attention-based high-level fusion mechanisms, inspired by the findings from statistical analyses on real advertisement data. Our approach achieved state-of-the-art performance on the AVA dataset, a widely used dataset for aesthetic assessment. Besides, the proposed method is evaluated on large-scale real-world advertisement image data with rich auxiliary attributes, providing promising preference prediction results. Through extensive experiments, we investigate how image and auxiliary information together influence click-through rate.
DNA Steganalysis Using Deep Recurrent Neural Networks
Oct 05, 2018

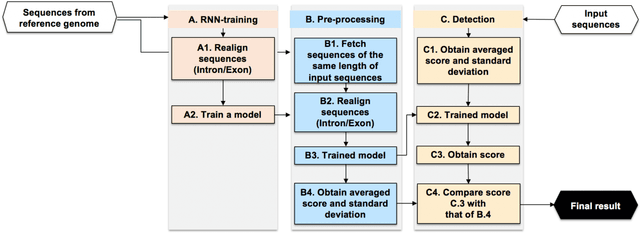
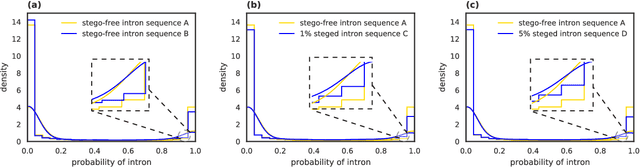
Recent advances in next-generation sequencing technologies have facilitated the use of deoxyribonucleic acid (DNA) as a novel covert channels in steganography. There are various methods that exist in other domains to detect hidden messages in conventional covert channels. However, they have not been applied to DNA steganography. The current most common detection approaches, namely frequency analysis-based methods, often overlook important signals when directly applied to DNA steganography because those methods depend on the distribution of the number of sequence characters. To address this limitation, we propose a general sequence learning-based DNA steganalysis framework. The proposed approach learns the intrinsic distribution of coding and non-coding sequences and detects hidden messages by exploiting distribution variations after hiding these messages. Using deep recurrent neural networks (RNNs), our framework identifies the distribution variations by using the classification score to predict whether a sequence is to be a coding or non-coding sequence. We compare our proposed method to various existing methods and biological sequence analysis methods implemented on top of our framework. According to our experimental results, our approach delivers a robust detection performance compared to other tools.
DeepCCI: End-to-end Deep Learning for Chemical-Chemical Interaction Prediction
Dec 14, 2017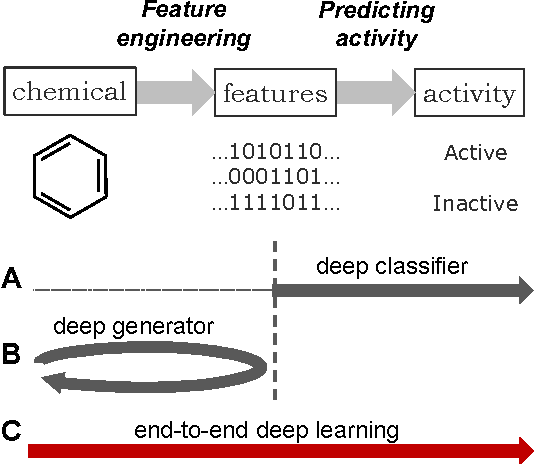

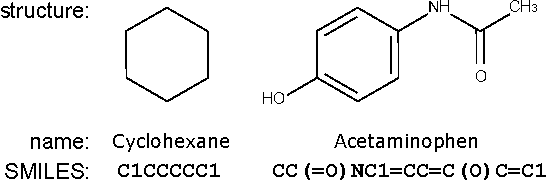
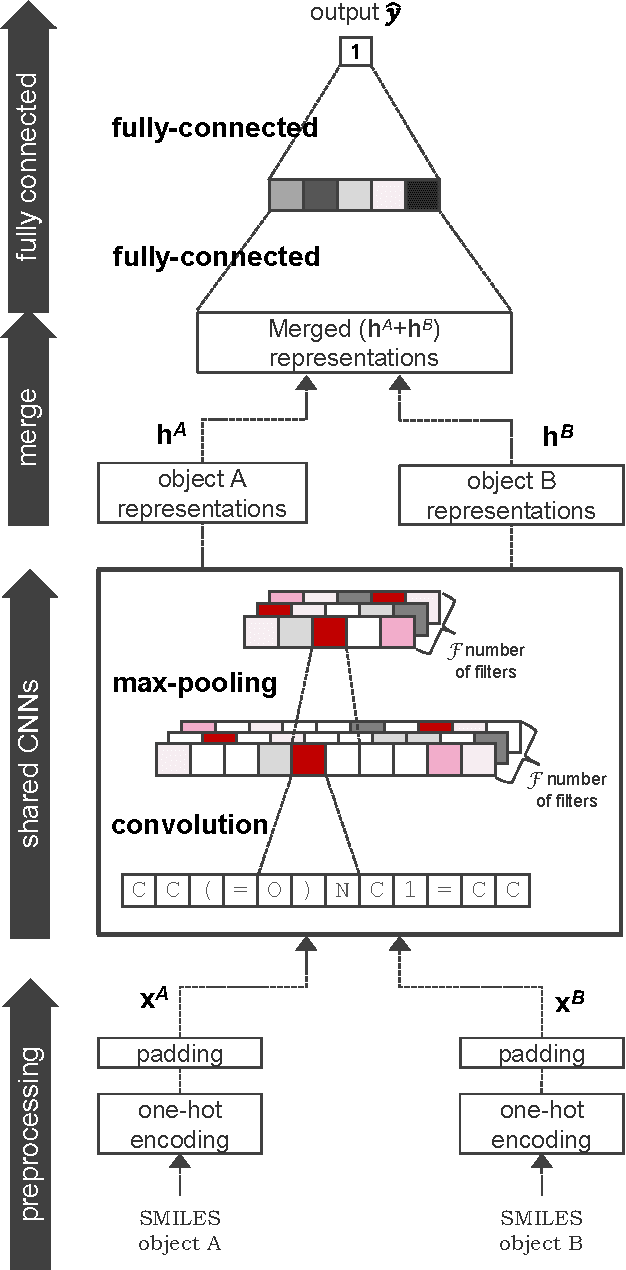
Chemical-chemical interaction (CCI) plays a key role in predicting candidate drugs, toxicity, therapeutic effects, and biological functions. In various types of chemical analyses, computational approaches are often required due to the amount of data that needs to be handled. The recent remarkable growth and outstanding performance of deep learning have attracted considerable research attention. However,even in state-of-the-art drug analysis methods, deep learning continues to be used only as a classifier, although deep learning is capable of not only simple classification but also automated feature extraction. In this paper, we propose the first end-to-end learning method for CCI, named DeepCCI. Hidden features are derived from a simplified molecular input line entry system (SMILES), which is a string notation representing the chemical structure, instead of learning from crafted features. To discover hidden representations for the SMILES strings, we use convolutional neural networks (CNNs). To guarantee the commutative property for homogeneous interaction, we apply model sharing and hidden representation merging techniques. The performance of DeepCCI was compared with a plain deep classifier and conventional machine learning methods. The proposed DeepCCI showed the best performance in all seven evaluation metrics used. In addition, the commutative property was experimentally validated. The automatically extracted features through end-to-end SMILES learning alleviates the significant efforts required for manual feature engineering. It is expected to improve prediction performance, in drug analyses.