 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Natural and Realistic Single Image Super-Resolution with Explicit Natural Manifold Discrimination
Nov 09, 2019

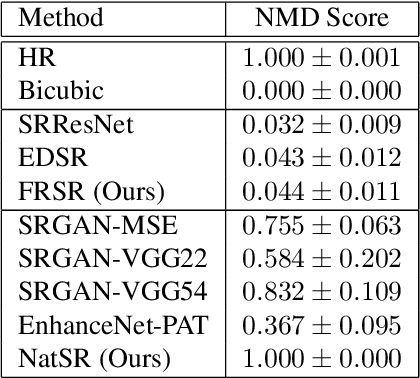
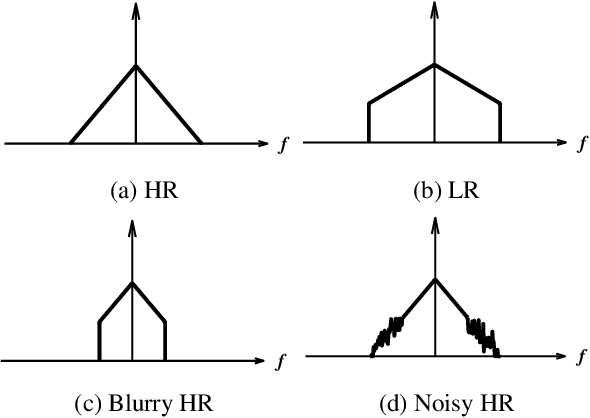
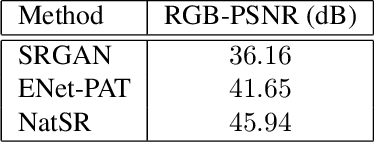
Recently, many convolutional neural networks for single image super-resolution (SISR) have been proposed, which focus on reconstructing the high-resolution images in terms of objective distortion measures. However, the networks trained with objective loss functions generally fail to reconstruct the realistic fine textures and details that are essential for better perceptual quality. Recovering the realistic details remains a challenging problem, and only a few works have been proposed which aim at increasing the perceptual quality by generating enhanced textures. However, the generated fake details often make undesirable artifacts and the overall image looks somewhat unnatural. Therefore, in this paper, we present a new approach to reconstructing realistic super-resolved images with high perceptual quality, while maintaining the naturalness of the result. In particular, we focus on the domain prior properties of SISR problem. Specifically, we define the naturalness prior in the low-level domain and constrain the output image in the natural manifold, which eventually generates more natural and realistic images. Our results show better naturalness compared to the recent super-resolution algorithms including perception-oriented ones.
Over-and-Under Complete Convolutional RNN for MRI Reconstruction
Jun 16, 2021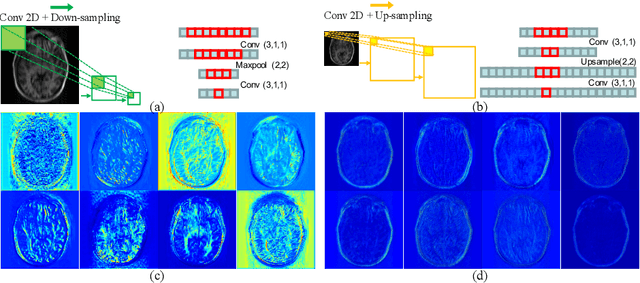
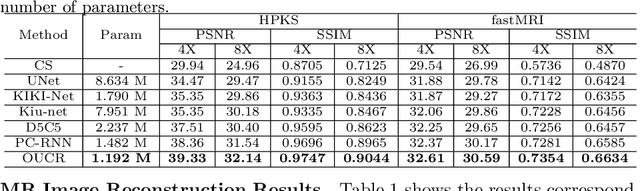
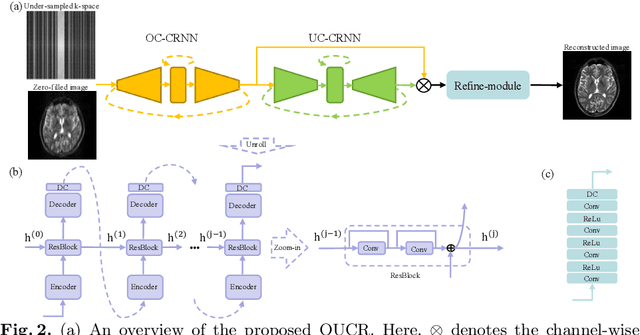
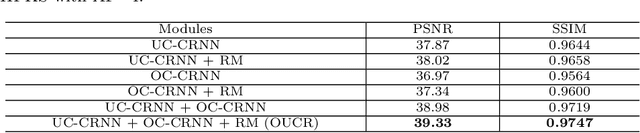
Reconstructing magnetic resonance (MR) images from undersampled data is a challenging problem due to various artifacts introduced by the under-sampling operation. Recent deep learning-based methods for MR image reconstruction usually leverage a generic auto-encoder architecture which captures low-level features at the initial layers and high?level features at the deeper layers. Such networks focus much on global features which may not be optimal to reconstruct the fully-sampled image. In this paper, we propose an Over-and-Under Complete Convolu?tional Recurrent Neural Network (OUCR), which consists of an overcomplete and an undercomplete Convolutional Recurrent Neural Network(CRNN). The overcomplete branch gives special attention in learning local structures by restraining the receptive field of the network. Combining it with the undercomplete branch leads to a network which focuses more on low-level features without losing out on the global structures. Extensive experiments on two datasets demonstrate that the proposed method achieves significant improvements over the compressed sensing and popular deep learning-based methods with less number of trainable parameters. Our code is available at https://github.com/guopengf/OUCR.
Non-negative Tensor Patch Dictionary Approaches for Image Compression and Deblurring Applications
Sep 25, 2019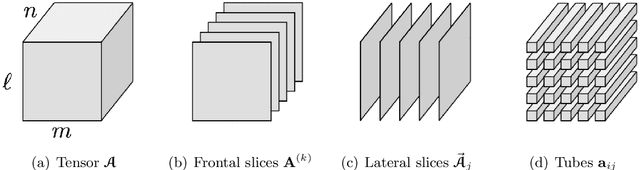


In recent work (Soltani, Kilmer, Hansen, BIT 2016), an algorithm for non-negative tensor patch dictionary learning in the context of X-ray CT imaging and based on a tensor-tensor product called the $t$-product (Kilmer and Martin, 2011) was presented. Building on that work, in this paper, we use of non-negative tensor patch-based dictionaries trained on other data, such as facial image data, for the purposes of either compression or image deblurring. We begin with an analysis in which we address issues such as suitability of the tensor-based approach relative to a matrix-based approach, dictionary size and patch size to balance computational efficiency and qualitative representations. Next, we develop an algorithm that is capable of recovering non-negative tensor coefficients given a non-negative tensor dictionary. The algorithm is based on a variant of the Modified Residual Norm Steepest Descent method. We show how to augment the algorithm to enforce sparsity in the tensor coefficients, and note that the approach has broader applicability since it can be applied to the matrix case as well. We illustrate the surprising result that dictionaries trained on image data from one class can be successfully used to represent and compress image data from different classes and across different resolutions. Finally, we address the use of non-negative tensor dictionaries in image deblurring. We show that tensor treatment of the deblurring problem coupled with non-negative tensor patch dictionaries can give superior restorations as compared to standard treatment of the non-negativity constrained deblurring problem.
DC-WCNN: A deep cascade of wavelet based convolutional neural networks for MR Image Reconstruction
Jan 08, 2020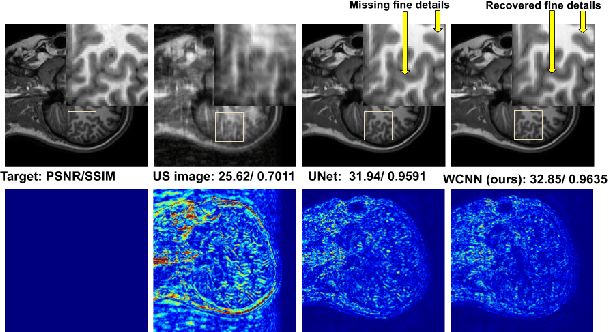
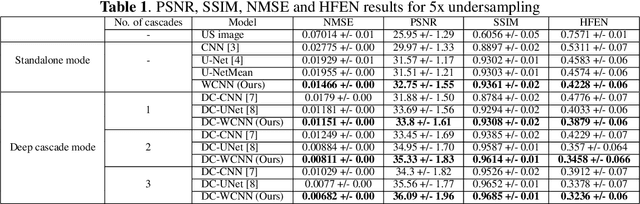
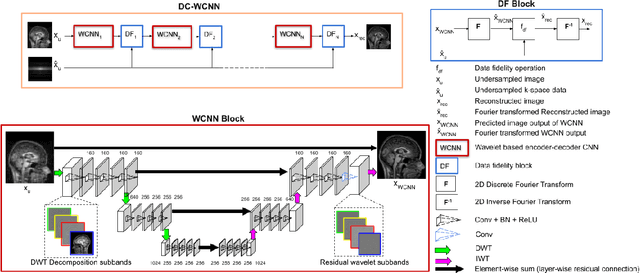
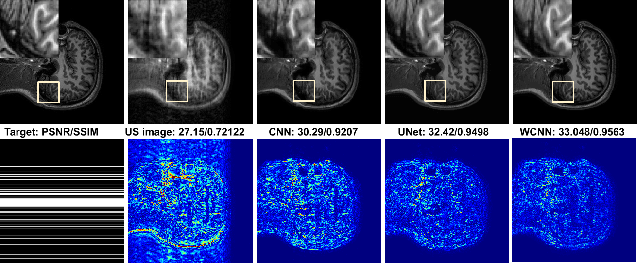
Several variants of Convolutional Neural Networks (CNN) have been developed for Magnetic Resonance (MR) image reconstruction. Among them, U-Net has shown to be the baseline architecture for MR image reconstruction. However, sub-sampling is performed by its pooling layers, causing information loss which in turn leads to blur and missing fine details in the reconstructed image. We propose a modification to the U-Net architecture to recover fine structures. The proposed network is a wavelet packet transform based encoder-decoder CNN with residual learning called CNN. The proposed WCNN has discrete wavelet transform instead of pooling and inverse wavelet transform instead of unpooling layers and residual connections. We also propose a deep cascaded framework (DC-WCNN) which consists of cascades of WCNN and k-space data fidelity units to achieve high quality MR reconstruction. Experimental results show that WCNN and DC-WCNN give promising results in terms of evaluation metrics and better recovery of fine details as compared to other methods.
Dialog-based Interactive Image Retrieval
Nov 01, 2018

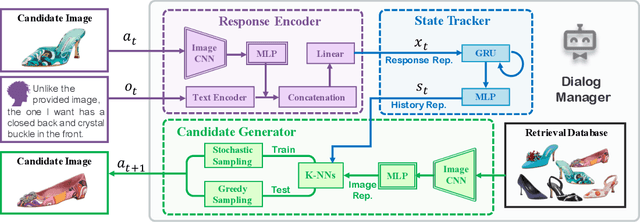
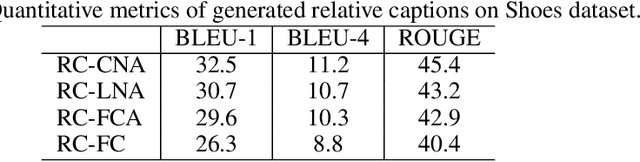
Existing methods for interactive image retrieval have demonstrated the merit of integrating user feedback, improving retrieval results. However, most current systems rely on restricted forms of user feedback, such as binary relevance responses, or feedback based on a fixed set of relative attributes, which limits their impact. In this paper, we introduce a new approach to interactive image search that enables users to provide feedback via natural language, allowing for more natural and effective interaction. We formulate the task of dialog-based interactive image retrieval as a reinforcement learning problem, and reward the dialog system for improving the rank of the target image during each dialog turn. To mitigate the cumbersome and costly process of collecting human-machine conversations as the dialog system learns, we train our system with a user simulator, which is itself trained to describe the differences between target and candidate images. The efficacy of our approach is demonstrated in a footwear retrieval application. Experiments on both simulated and real-world data show that 1) our proposed learning framework achieves better accuracy than other supervised and reinforcement learning baselines and 2) user feedback based on natural language rather than pre-specified attributes leads to more effective retrieval results, and a more natural and expressive communication interface.
DerainCycleGAN: An Attention-guided Unsupervised Benchmark for Single Image Deraining and Rainmaking
Jan 15, 2020
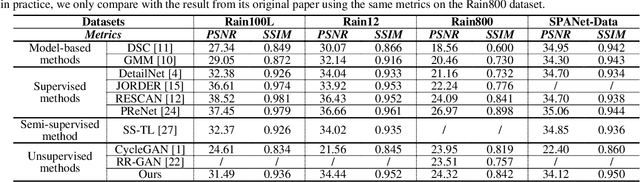


Single image deraining (SID) is an important and challenging topic in emerging vision applications, and most of emerged deraining methods are supervised relying on the ground truth (i.e., paired images) in recent years. However, in practice it is rather common to have no un-paired images in real deraining task, in such cases how to remove the rain streaks in an unsupervised way will be a very challenging task due to lack of constraints between images and hence suffering from low-quality recovery results. In this paper, we explore the unsupervised SID task using unpaired data and propose a novel net called Attention-guided Deraining by Constrained CycleGAN (or shortly, DerainCycleGAN), which can fully utilize the constrained transfer learning abilitiy and circulatory structure of CycleGAN. Specifically, we design an unsu-pervised attention guided rain streak extractor (U-ARSE) that utilizes a memory to extract the rain streak masks with two constrained cycle-consistency branches jointly by paying attention to both the rainy and rain-free image domains. As a by-product, we also contribute a new paired rain image dataset called Rain200A, which is constructed by our network automatically. Compared with existing synthesis datasets, the rainy streaks in Rain200A contains more obvious and diverse shapes and directions. As a result, existing supervised methods trained on Rain200A can perform much better for processing real rainy images. Extensive experiments on synthesis and real datasets show that our net is superior to existing unsupervised deraining networks, and is also very competitive to other related supervised networks.
Photos Are All You Need for Reciprocal Recommendation in Online Dating
Aug 26, 2021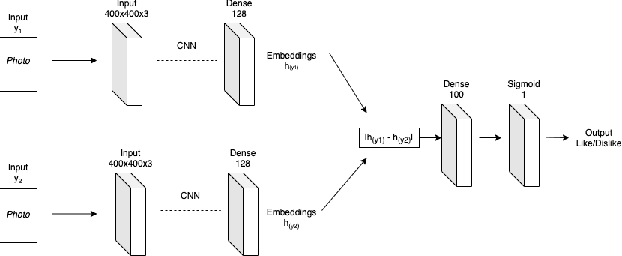
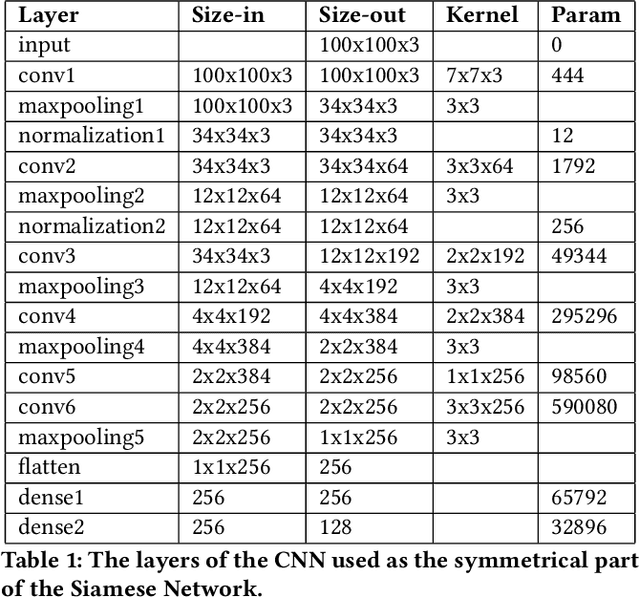
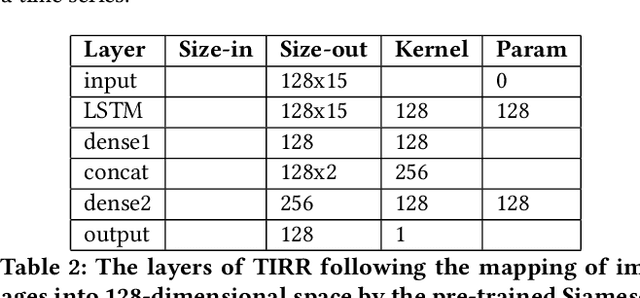
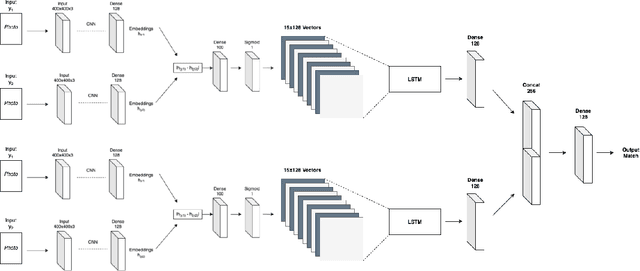
Recommender Systems are algorithms that predict a user's preference for an item. Reciprocal Recommenders are a subset of recommender systems, where the items in question are people, and the objective is therefore to predict a bidirectional preference relation. They are used in settings such as online dating services and social networks. In particular, images provided by users are a crucial part of user preference, and one that is not exploited much in the literature. We present a novel method of interpreting user image preference history and using this to make recommendations. We train a recurrent neural network to learn a user's preferences and make predictions of reciprocal preference relations that can be used to make recommendations that satisfy both users. We show that our proposed system achieves an F1 score of 0.87 when using only photographs to produce reciprocal recommendations on a large real world online dating dataset. Our system significantly outperforms on the state of the art in both content-based and collaborative filtering systems.
Effective Tensor Completion via Element-wise Weighted Low-rank Tensor Train with Overlapping Ket Augmentation
Sep 17, 2021


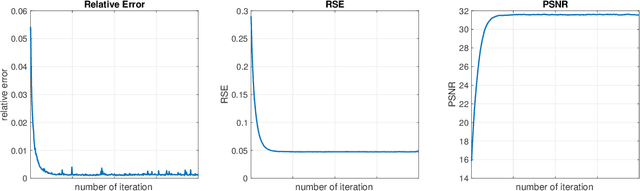
In recent years, there have been an increasing number of applications of tensor completion based on the tensor train (TT) format because of its efficiency and effectiveness in dealing with higher-order tensor data. However, existing tensor completion methods using TT decomposition have two obvious drawbacks. One is that they only consider mode weights according to the degree of mode balance, even though some elements are recovered better in an unbalanced mode. The other is that serious blocking artifacts appear when the missing element rate is relatively large. To remedy such two issues, in this work, we propose a novel tensor completion approach via the element-wise weighted technique. Accordingly, a novel formulation for tensor completion and an effective optimization algorithm, called as tensor completion by parallel weighted matrix factorization via tensor train (TWMac-TT), is proposed. In addition, we specifically consider the recovery quality of edge elements from adjacent blocks. Different from traditional reshaping and ket augmentation, we utilize a new tensor augmentation technique called overlapping ket augmentation, which can further avoid blocking artifacts. We then conduct extensive performance evaluations on synthetic data and several real image data sets. Our experimental results demonstrate that the proposed algorithm TWMac-TT outperforms several other competing tensor completion methods.
Relevance Vector Machines for harmonization of MRI brain volumes using image descriptors
Nov 08, 2019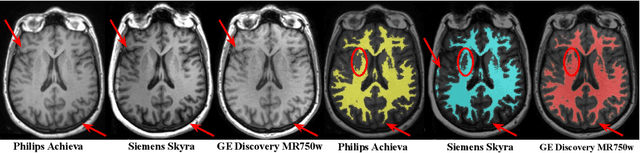
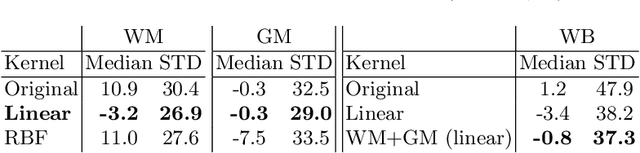
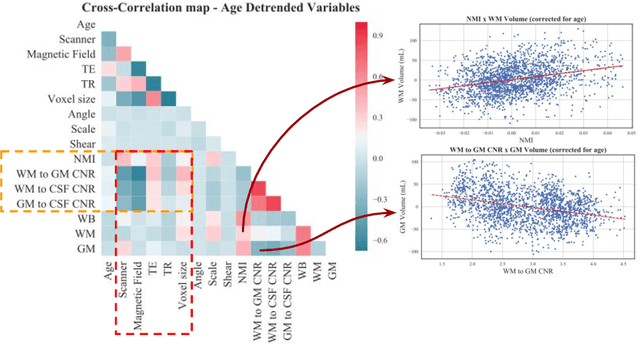
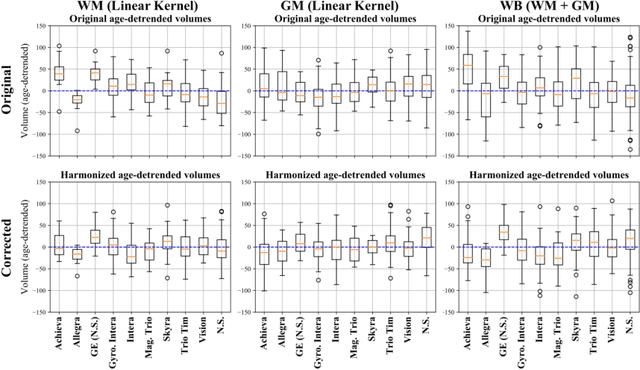
With the increased need for multi-center magnetic resonance imaging studies, problems arise related to differences in hardware and software between centers. Namely, current algorithms for brain volume quantification are unreliable for the longitudinal assessment of volume changes in this type of setting. Currently most methods attempt to decrease this issue by regressing the scanner- and/or center-effects from the original data. In this work, we explore a novel approach to harmonize brain volume measurements by using only image descriptors. First, we explore the relationships between volumes and image descriptors. Then, we train a Relevance Vector Machine (RVM) model over a large multi-site dataset of healthy subjects to perform volume harmonization. Finally, we validate the method over two different datasets: i) a subset of unseen healthy controls; and ii) a test-retest dataset of multiple sclerosis (MS) patients. The method decreases scanner and center variability while preserving measurements that did not require correction in MS patient data. We show that image descriptors can be used as input to a machine learning algorithm to improve the reliability of longitudinal volumetric studies.
* 9 pages, 4 figures. Presented at the International Workshop on Machine Learning in Clinical Neuroimaging (MLCN) 2019
Lighting the Darkness in the Deep Learning Era
Apr 21, 2021
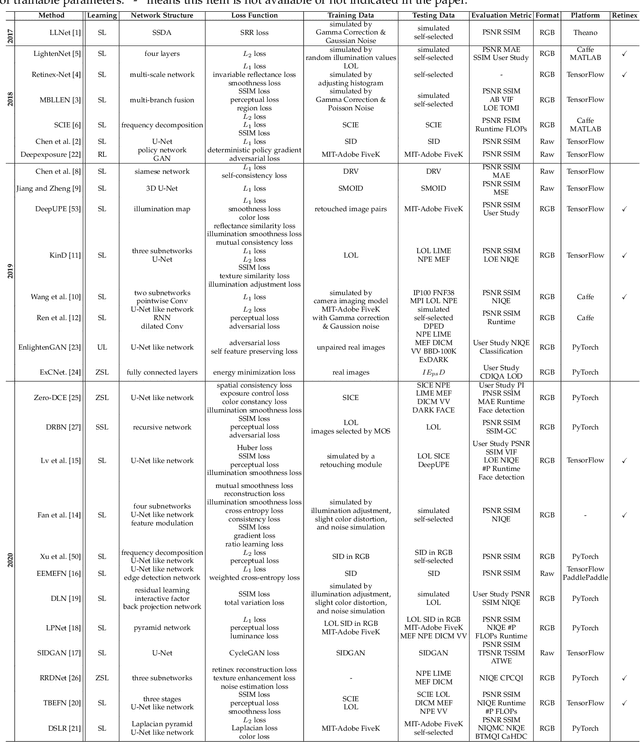

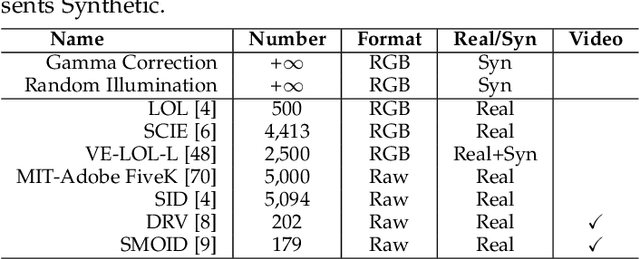
Low-light image enhancement (LLIE) aims at improving the perception or interpretability of an image captured in an environment with poor illumination. Recent advances in this area are dominated by deep learning-based solutions, where many learning strategies, network structures, loss functions, training data, etc. have been employed. In this paper, we provide a comprehensive survey to cover various aspects ranging from algorithm taxonomy to unsolved open issues. To examine the generalization of existing methods, we propose a large-scale low-light image and video dataset, in which the images and videos are taken by different mobile phones' cameras under diverse illumination conditions. Besides, for the first time, we provide a unified online platform that covers many popular LLIE methods, of which the results can be produced through a user-friendly web interface. In addition to qualitative and quantitative evaluation of existing methods on publicly available and our proposed datasets, we also validate their performance in face detection in the dark. This survey together with the proposed dataset and online platform could serve as a reference source for future study and promote the development of this research field. The proposed platform and the collected methods, datasets, and evaluation metrics are publicly available and will be regularly updated at https://github.com/Li-Chongyi/Lighting-the-Darkness-in-the-Deep-Learning-Era-Open. We will release our low-light image and video dataset.