 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Accurate 2D soft segmentation of medical image via SoftGAN network
Jul 29, 2020
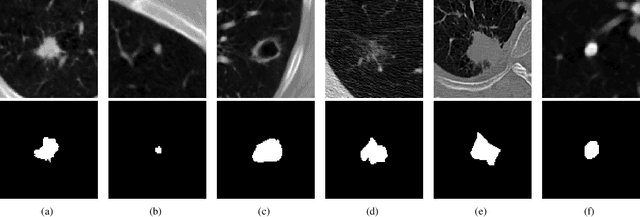


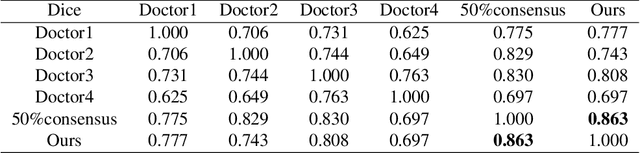
Accurate 2D lung nodules segmentation from medical Computed Tomography (CT) images is crucial in medical applications. Most current approaches cannot achieve precise segmentation results that preserving both rich edge details description and smooth transition representations between image regions due to the tininess, complexities, and irregularities of lung nodule shapes. To address this issue, we propose a novel Cascaded Generative Adversarial Network (CasGAN) to cope with CT images super-resolution and segmentation tasks, in which the semantic soft segmentation form on precise lesion representation is introduced for the first time according to our knowledge, and lesion edges can be retained accurately after our segmentation that can promote rapid acquisition of high-quality large-scale annotation data based on RECIST weak supervision information. Extensive experiments validate that our CasGAN outperforms the state-of-the-art methods greatly in segmentation quality, which is also robust on the application of medical images beyond lung nodules. Besides, we provide a challenging lung nodules soft segmentation dataset of medical CT images for further studies.
LIFE: Lighting Invariant Flow Estimation
Apr 07, 2021

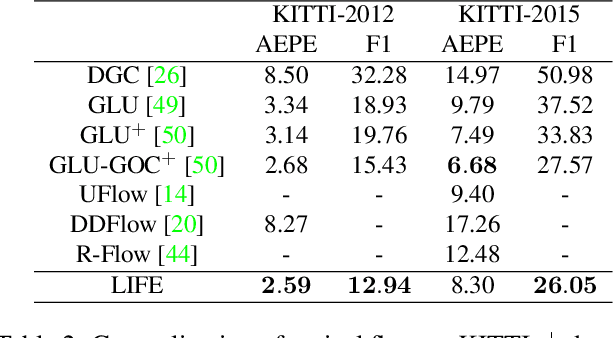
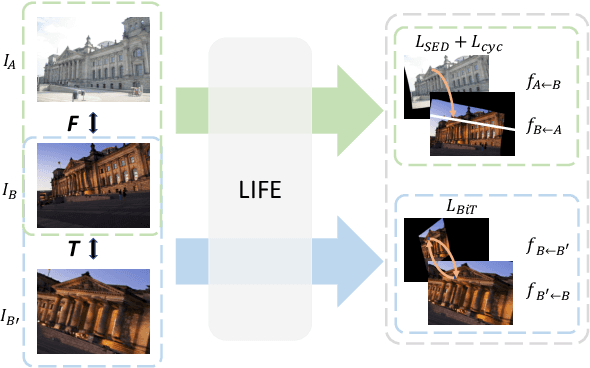
We tackle the problem of estimating flow between two images with large lighting variations. Recent learning-based flow estimation frameworks have shown remarkable performance on image pairs with small displacement and constant illuminations, but cannot work well on cases with large viewpoint change and lighting variations because of the lack of pixel-wise flow annotations for such cases. We observe that via the Structure-from-Motion (SfM) techniques, one can easily estimate relative camera poses between image pairs with large viewpoint change and lighting variations. We propose a novel weakly supervised framework LIFE to train a neural network for estimating accurate lighting-invariant flows between image pairs. Sparse correspondences are conventionally established via feature matching with descriptors encoding local image contents. However, local image contents are inevitably ambiguous and error-prone during the cross-image feature matching process, which hinders downstream tasks. We propose to guide feature matching with the flows predicted by LIFE, which addresses the ambiguous matching by utilizing abundant context information in the image pairs. We show that LIFE outperforms previous flow learning frameworks by large margins in challenging scenarios, consistently improves feature matching, and benefits downstream tasks.
Objective crystallographic symmetry classifications of noisy and noise-free 2D periodic patterns with strong Fedorov type pseudosymmetries
Aug 03, 2021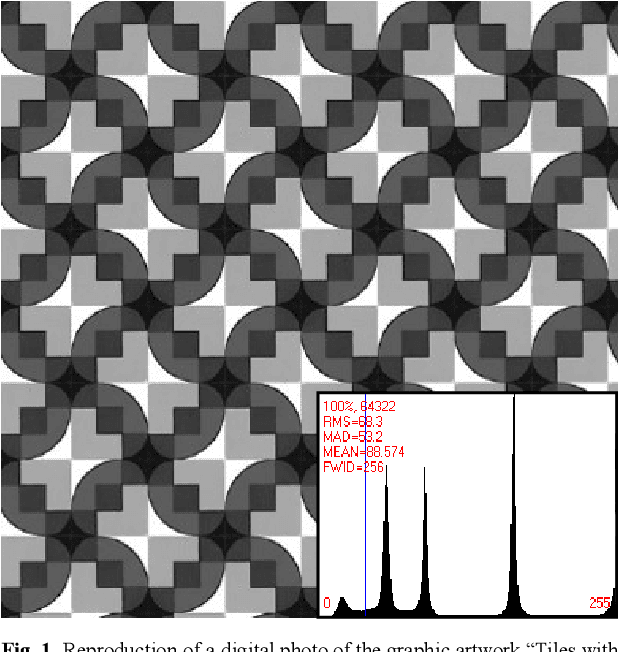

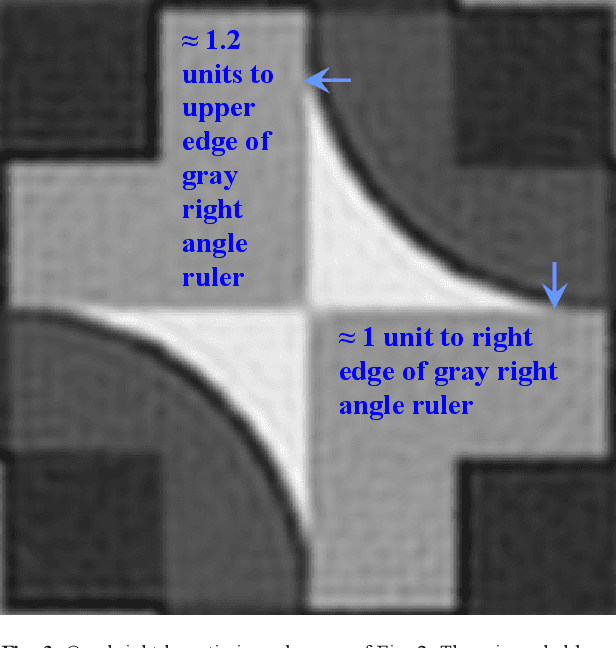
Statistically sound crystallographic symmetry classifications are obtained with information theory based methods in the presence of approximately Gaussian distributed noise. A set of three synthetic images with very strong Fedorov type pseudosymmetries and varying amounts of noise serve as examples. The correct distinctions between genuine symmetries and their Fedorov type pseudosymmetry counterparts failed only for the noisiest image of the series where an inconsistent combination of plane symmetry group and projected Laue class was obtained. Contrary to traditional crystallographic symmetry classifications with an image processing program such as CRISP, the classification process does not need to be supervised by a human being. This enables crystallographic symmetry classification of digital images that are more or less periodic in two dimensions (2D) as recorded with sufficient spatial resolution from a wide range of samples with different types of scanning probe microscopes. Alternatives to the employed objective classification methods as proposed by members of the computational symmetry community and machine learning proponents are briefly discussed in an appendix and are found to be wanting because they ignore Fedorov type pseudosymmetries completely. The information theory based methods are more accurate than visual classifications at first sight by most human experts.
Revisiting Discriminator in GAN Compression: A Generator-discriminator Cooperative Compression Scheme
Oct 27, 2021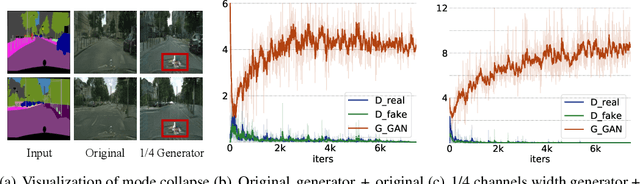
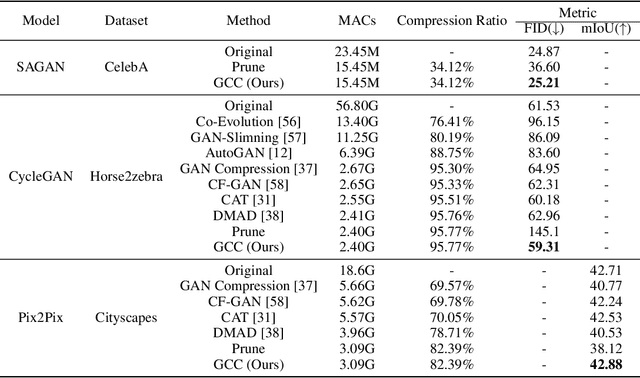
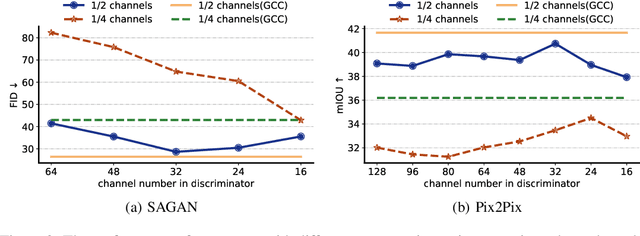

Recently, a series of algorithms have been explored for GAN compression, which aims to reduce tremendous computational overhead and memory usages when deploying GANs on resource-constrained edge devices. However, most of the existing GAN compression work only focuses on how to compress the generator, while fails to take the discriminator into account. In this work, we revisit the role of discriminator in GAN compression and design a novel generator-discriminator cooperative compression scheme for GAN compression, termed GCC. Within GCC, a selective activation discriminator automatically selects and activates convolutional channels according to a local capacity constraint and a global coordination constraint, which help maintain the Nash equilibrium with the lightweight generator during the adversarial training and avoid mode collapse. The original generator and discriminator are also optimized from scratch, to play as a teacher model to progressively refine the pruned generator and the selective activation discriminator. A novel online collaborative distillation scheme is designed to take full advantage of the intermediate feature of the teacher generator and discriminator to further boost the performance of the lightweight generator. Extensive experiments on various GAN-based generation tasks demonstrate the effectiveness and generalization of GCC. Among them, GCC contributes to reducing 80% computational costs while maintains comparable performance in image translation tasks. Our code and models are available at \url{https://github.com/SJLeo/GCC}.
Personalizing Pre-trained Models
Jun 02, 2021
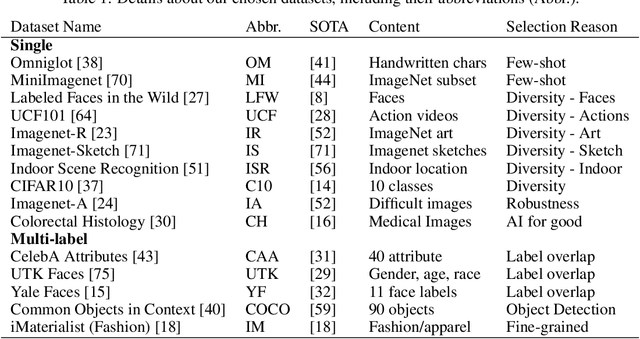
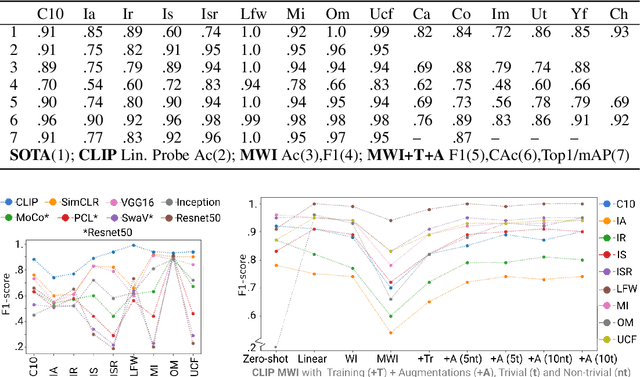
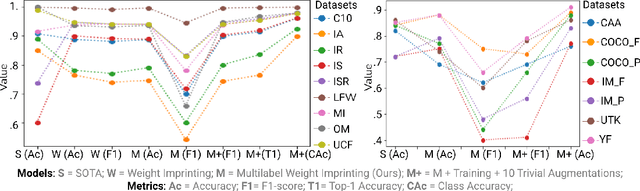
Self-supervised or weakly supervised models trained on large-scale datasets have shown sample-efficient transfer to diverse datasets in few-shot settings. We consider how upstream pretrained models can be leveraged for downstream few-shot, multilabel, and continual learning tasks. Our model CLIPPER (CLIP PERsonalized) uses image representations from CLIP, a large-scale image representation learning model trained using weak natural language supervision. We developed a technique, called Multi-label Weight Imprinting (MWI), for multi-label, continual, and few-shot learning, and CLIPPER uses MWI with image representations from CLIP. We evaluated CLIPPER on 10 single-label and 5 multi-label datasets. Our model shows robust and competitive performance, and we set new benchmarks for few-shot, multi-label, and continual learning. Our lightweight technique is also compute-efficient and enables privacy-preserving applications as the data is not sent to the upstream model for fine-tuning.
Transferability of Adversarial Examples to Attack Cloud-based Image Classifier Service
Jan 20, 2020

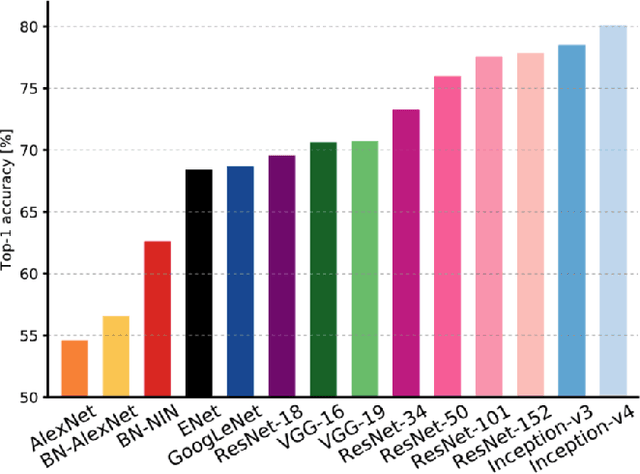
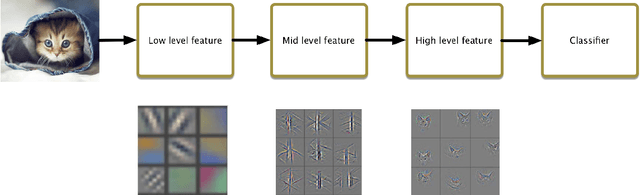
In recent years, Deep Learning(DL) techniques have been extensively deployed for computer vision tasks, particularly visual classification problems, where new algorithms reported to achieve or even surpass the human performance. While many recent works demonstrated that DL models are vulnerable to adversarial examples. Fortunately, generating adversarial examples usually requires white-box access to the victim model, and real-world cloud-based image classification services are more complex than white-box classifier,the architecture and parameters of DL models on cloud platforms cannot be obtained by the attacker. The attacker can only access the APIs opened by cloud platforms. Thus, keeping models in the cloud can usually give a (false) sense of security. In this paper, we mainly focus on studying the security of real-world cloud-based image classification services. Specifically, (1) We propose a novel attack method, Fast Featuremap Loss PGD (FFL-PGD) attack based on Substitution model, which achieves a high bypass rate with a very limited number of queries. Instead of millions of queries in previous studies, our method finds the adversarial examples using only two queries per image; and (2) we make the first attempt to conduct an extensive empirical study of black-box attacks against real-world cloud-based classification services. Through evaluations on four popular cloud platforms including Amazon, Google, Microsoft, Clarifai, we demonstrate that FFL-PGD attack has a success rate over 90\% among different classification services. (3) We discuss the possible defenses to address these security challenges in cloud-based classification services. Our defense technology is mainly divided into model training stage and image preprocessing stage.
Reconstruct, Rasterize and Backprop: Dense shape and pose estimation from a single image
Apr 25, 2020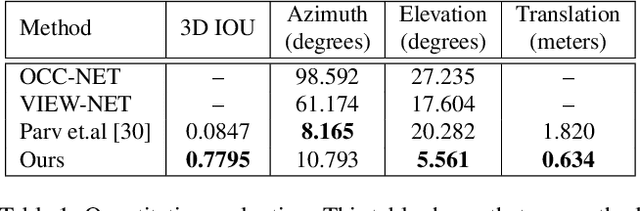

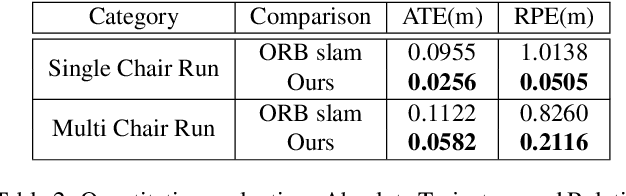

This paper presents a new system to obtain dense object reconstructions along with 6-DoF poses from a single image. Geared towards high fidelity reconstruction, several recent approaches leverage implicit surface representations and deep neural networks to estimate a 3D mesh of an object, given a single image. However, all such approaches recover only the shape of an object; the reconstruction is often in a canonical frame, unsuitable for downstream robotics tasks. To this end, we leverage recent advances in differentiable rendering (in particular, rasterization) to close the loop with 3D reconstruction in camera frame. We demonstrate that our approach---dubbed reconstruct, rasterize and backprop (RRB) achieves significantly lower pose estimation errors compared to prior art, and is able to recover dense object shapes and poses from imagery. We further extend our results to an (offline) setup, where we demonstrate a dense monocular object-centric egomotion estimation system.
Pix2seq: A Language Modeling Framework for Object Detection
Sep 22, 2021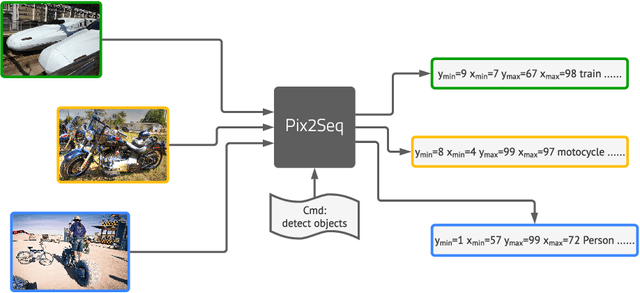
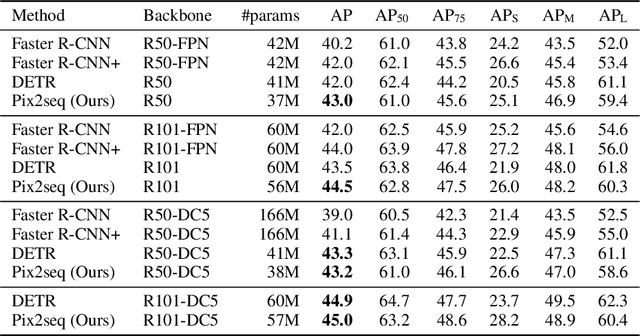
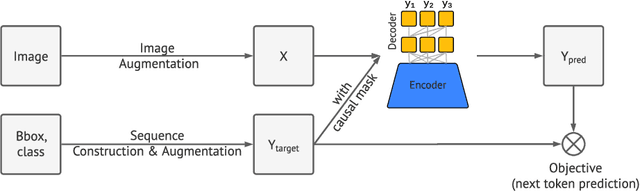
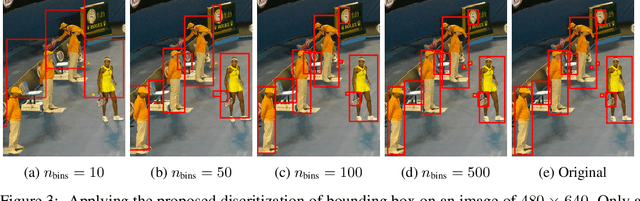
This paper presents Pix2Seq, a simple and generic framework for object detection. Unlike existing approaches that explicitly integrate prior knowledge about the task, we simply cast object detection as a language modeling task conditioned on the observed pixel inputs. Object descriptions (e.g., bounding boxes and class labels) are expressed as sequences of discrete tokens, and we train a neural net to perceive the image and generate the desired sequence. Our approach is based mainly on the intuition that if a neural net knows about where and what the objects are, we just need to teach it how to read them out. Beyond the use of task-specific data augmentations, our approach makes minimal assumptions about the task, yet it achieves competitive results on the challenging COCO dataset, compared to highly specialized and well optimized detection algorithms.
RATCHET: Medical Transformer for Chest X-ray Diagnosis and Reporting
Jul 05, 2021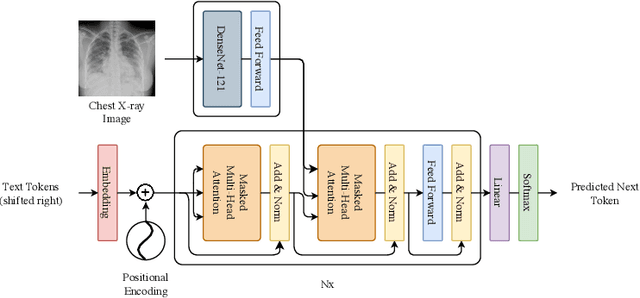
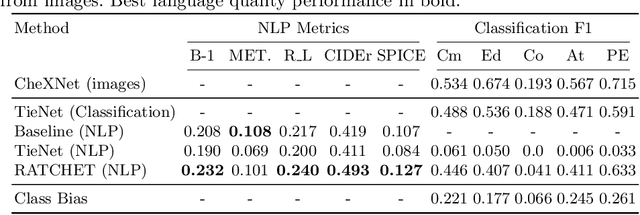
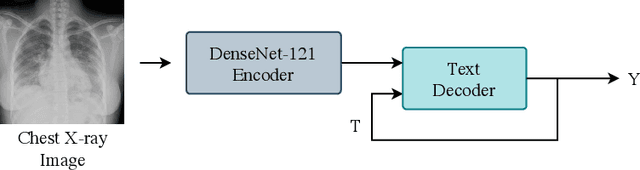
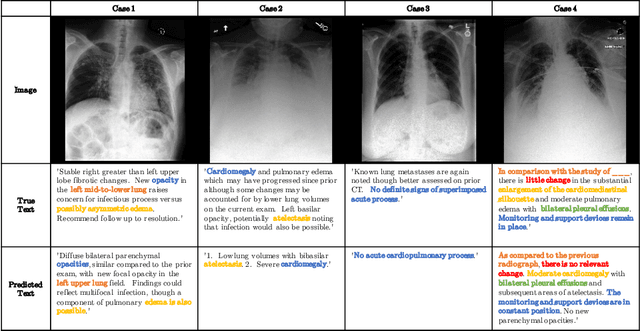
Chest radiographs are one of the most common diagnostic modalities in clinical routine. It can be done cheaply, requires minimal equipment, and the image can be diagnosed by every radiologists. However, the number of chest radiographs obtained on a daily basis can easily overwhelm the available clinical capacities. We propose RATCHET: RAdiological Text Captioning for Human Examined Thoraces. RATCHET is a CNN-RNN-based medical transformer that is trained end-to-end. It is capable of extracting image features from chest radiographs, and generates medically accurate text reports that fit seamlessly into clinical work flows. The model is evaluated for its natural language generation ability using common metrics from NLP literature, as well as its medically accuracy through a surrogate report classification task. The model is available for download at: http://www.github.com/farrell236/RATCHET.
ShadingNet: Image Intrinsics by Fine-Grained Shading Decomposition
Dec 09, 2019



In general, intrinsic image decomposition algorithms interpret shading as one unified component including all photometric effects. As shading transitions are generally smoother than albedo changes, these methods may fail in distinguishing strong (cast) shadows from albedo variations. That in return may leak into albedo map predictions. Therefore, in this paper, we propose to decompose the shading component into direct (illumination) and indirect shading (ambient light and shadows). The aim is to distinguish strong cast shadows from reflectance variations. Two end-to-end supervised CNN models (ShadingNets) are proposed exploiting the fine-grained shading model. Furthermore, surface normal features are jointly learned by the proposed CNN networks. Surface normals are expected to assist the decomposition task. A large-scale dataset of scene-level synthetic images of outdoor natural environments is provided with intrinsic image ground-truths. Large scale experiments show that our CNN approach using fine-grained shading decomposition outperforms state-of-the-art methods using unified shading.