 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Structured Denoising Diffusion Models in Discrete State-Spaces
Jul 07, 2021
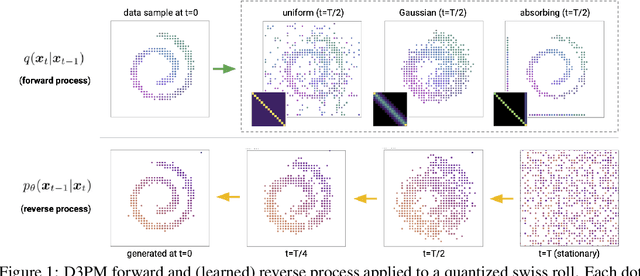
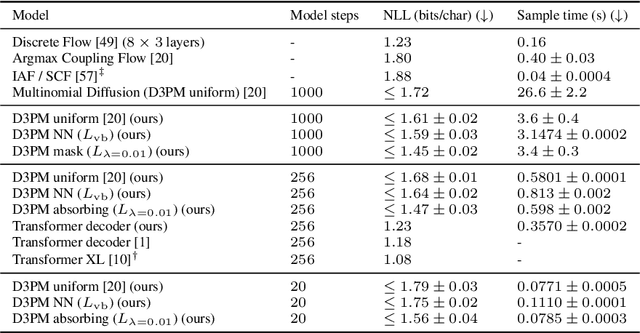

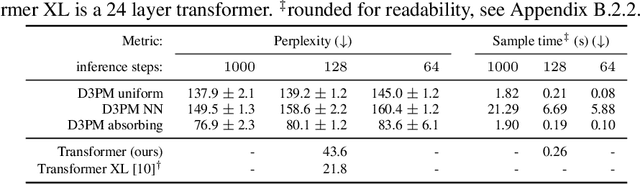
Denoising diffusion probabilistic models (DDPMs) (Ho et al. 2020) have shown impressive results on image and waveform generation in continuous state spaces. Here, we introduce Discrete Denoising Diffusion Probabilistic Models (D3PMs), diffusion-like generative models for discrete data that generalize the multinomial diffusion model of Hoogeboom et al. 2021, by going beyond corruption processes with uniform transition probabilities. This includes corruption with transition matrices that mimic Gaussian kernels in continuous space, matrices based on nearest neighbors in embedding space, and matrices that introduce absorbing states. The third allows us to draw a connection between diffusion models and autoregressive and mask-based generative models. We show that the choice of transition matrix is an important design decision that leads to improved results in image and text domains. We also introduce a new loss function that combines the variational lower bound with an auxiliary cross entropy loss. For text, this model class achieves strong results on character-level text generation while scaling to large vocabularies on LM1B. On the image dataset CIFAR-10, our models approach the sample quality and exceed the log-likelihood of the continuous-space DDPM model.
Attention-based 3D Object Reconstruction from a Single Image
Aug 11, 2020Recently, learning-based approaches for 3D reconstruction from 2D images have gained popularity due to its modern applications, e.g., 3D printers, autonomous robots, self-driving cars, virtual reality, and augmented reality. The computer vision community has applied a great effort in developing functions to reconstruct the full 3D geometry of objects and scenes. However, to extract image features, they rely on convolutional neural networks, which are ineffective in capturing long-range dependencies. In this paper, we propose to substantially improve Occupancy Networks, a state-of-the-art method for 3D object reconstruction. For such we apply the concept of self-attention within the network's encoder in order to leverage complementary input features rather than those based on local regions, helping the encoder to extract global information. With our approach, we were capable of improving the original work in 5.05% of mesh IoU, 0.83% of Normal Consistency, and more than 10X the Chamfer-L1 distance. We also perform a qualitative study that shows that our approach was able to generate much more consistent meshes, confirming its increased generalization power over the current state-of-the-art.
* 8 pages, 4 figures, 3 tables
Inverse Problems Leveraging Pre-trained Contrastive Representations
Oct 14, 2021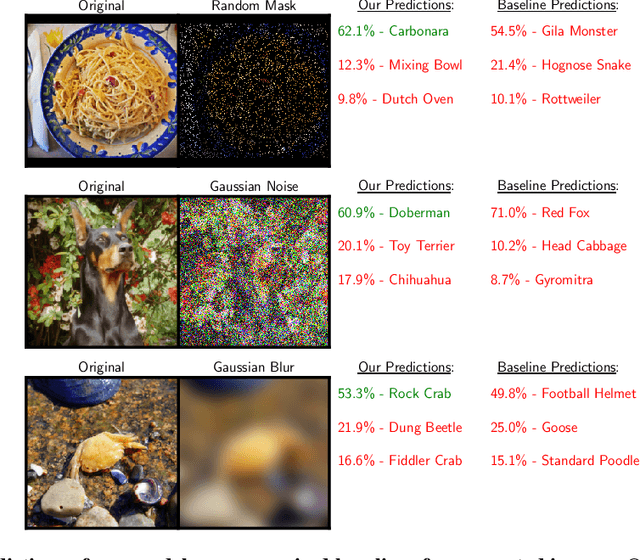
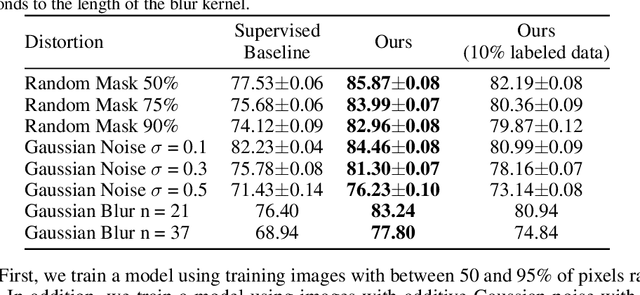
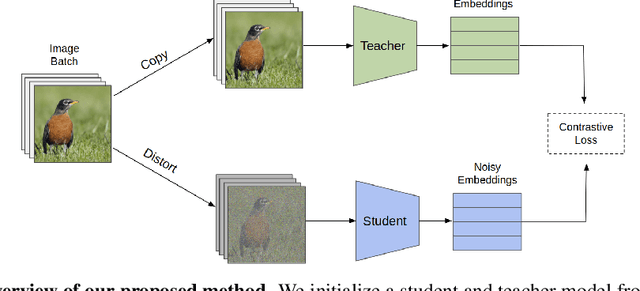
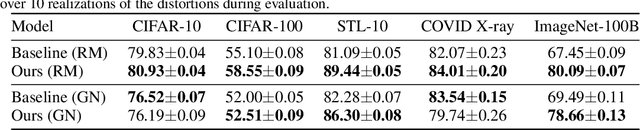
We study a new family of inverse problems for recovering representations of corrupted data. We assume access to a pre-trained representation learning network R(x) that operates on clean images, like CLIP. The problem is to recover the representation of an image R(x), if we are only given a corrupted version A(x), for some known forward operator A. We propose a supervised inversion method that uses a contrastive objective to obtain excellent representations for highly corrupted images. Using a linear probe on our robust representations, we achieve a higher accuracy than end-to-end supervised baselines when classifying images with various types of distortions, including blurring, additive noise, and random pixel masking. We evaluate on a subset of ImageNet and observe that our method is robust to varying levels of distortion. Our method outperforms end-to-end baselines even with a fraction of the labeled data in a wide range of forward operators.
Guided Evolution for Neural Architecture Search
Oct 28, 2021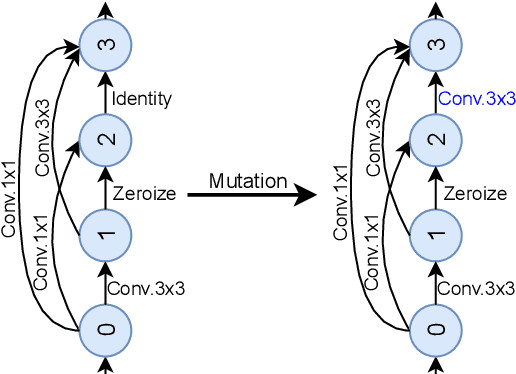
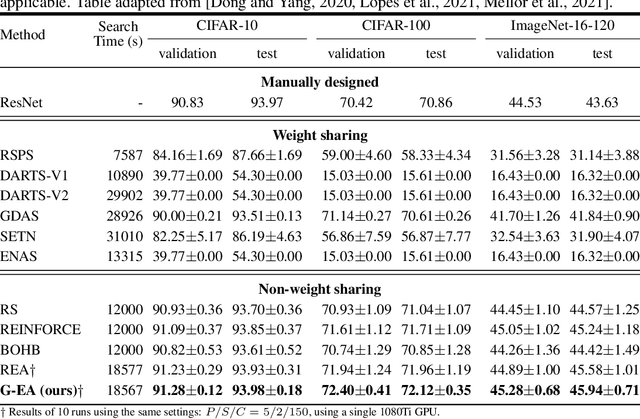
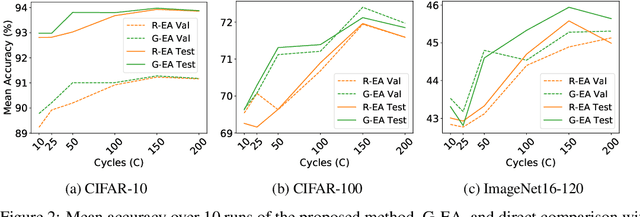
Neural Architecture Search (NAS) methods have been successfully applied to image tasks with excellent results. However, NAS methods are often complex and tend to converge to local minima as soon as generated architectures seem to yield good results. In this paper, we propose G-EA, a novel approach for guided evolutionary NAS. The rationale behind G-EA, is to explore the search space by generating and evaluating several architectures in each generation at initialization stage using a zero-proxy estimator, where only the highest-scoring network is trained and kept for the next generation. This evaluation at initialization stage allows continuous extraction of knowledge from the search space without increasing computation, thus allowing the search to be efficiently guided. Moreover, G-EA forces exploitation of the most performant networks by descendant generation while at the same time forcing exploration by parent mutation and by favouring younger architectures to the detriment of older ones. Experimental results demonstrate the effectiveness of the proposed method, showing that G-EA achieves state-of-the-art results in NAS-Bench-201 search space in CIFAR-10, CIFAR-100 and ImageNet16-120, with mean accuracies of 93.98%, 72.12% and 45.94% respectively.
Heavy Ball Neural Ordinary Differential Equations
Oct 10, 2021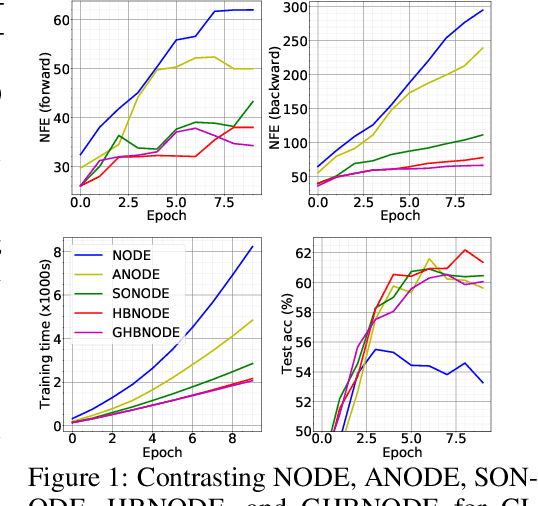

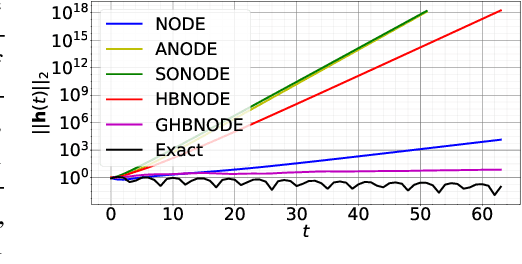
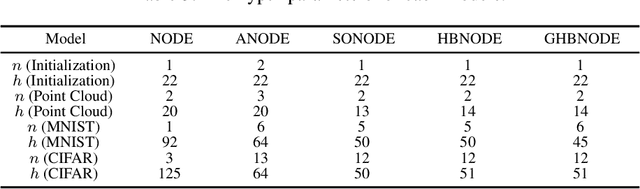
We propose heavy ball neural ordinary differential equations (HBNODEs), leveraging the continuous limit of the classical momentum accelerated gradient descent, to improve neural ODEs (NODEs) training and inference. HBNODEs have two properties that imply practical advantages over NODEs: (i) The adjoint state of an HBNODE also satisfies an HBNODE, accelerating both forward and backward ODE solvers, thus significantly reducing the number of function evaluations (NFEs) and improving the utility of the trained models. (ii) The spectrum of HBNODEs is well structured, enabling effective learning of long-term dependencies from complex sequential data. We verify the advantages of HBNODEs over NODEs on benchmark tasks, including image classification, learning complex dynamics, and sequential modeling. Our method requires remarkably fewer forward and backward NFEs, is more accurate, and learns long-term dependencies more effectively than the other ODE-based neural network models. Code is available at \url{https://github.com/hedixia/HeavyBallNODE}.
Neural ODEs for Image Segmentation with Level Sets
Dec 25, 2019
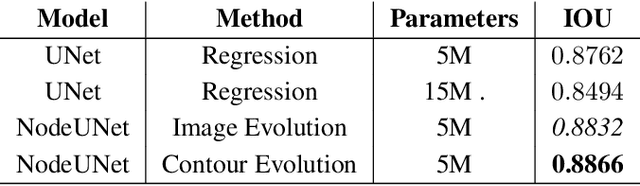
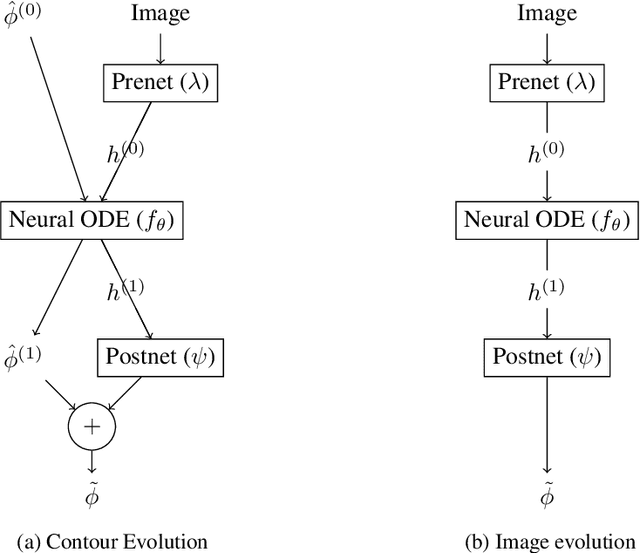
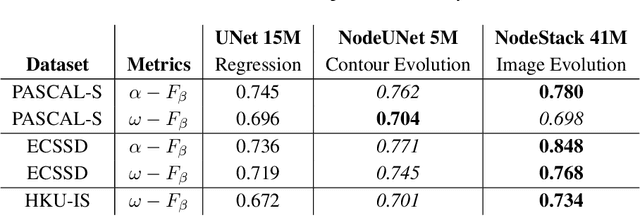
We propose a novel approach for image segmentation that combines Neural Ordinary Differential Equations (NODEs) and the Level Set method. Our approach parametrizes the evolution of an initial contour with a NODE that implicitly learns from data a speed function describing the evolution. In addition, for cases where an initial contour is not available and to alleviate the need for careful choice or design of contour embedding functions, we propose a NODE-based method that evolves an image embedding into a dense per-pixel semantic label space. We evaluate our methods on kidney segmentation (KiTS19) and on salient object detection (PASCAL-S, ECSSD and HKU-IS). In addition to improving initial contours provided by deep learning models while using a fraction of their number of parameters, our approach achieves F scores that are higher than several state-of-the-art deep learning algorithms.
An Empirical Study of Training End-to-End Vision-and-Language Transformers
Nov 03, 2021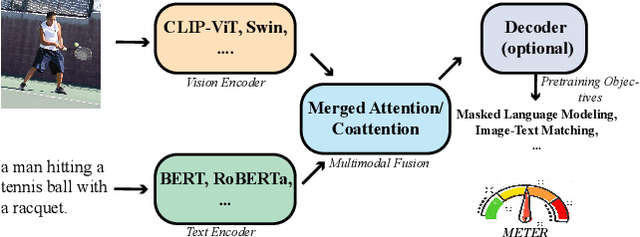

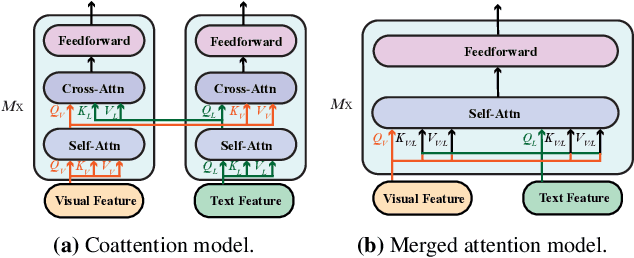

Vision-and-language (VL) pre-training has proven to be highly effective on various VL downstream tasks. While recent work has shown that fully transformer-based VL models can be more efficient than previous region-feature-based methods, their performance on downstream tasks are often degraded significantly. In this paper, we present METER~(\textbf{M}ultimodal \textbf{E}nd-to-end \textbf{T}ransform\textbf{ER}), through which we systematically investigate how to design and pre-train a fully transformer-based VL model in an end-to-end manner. Specifically, we dissect the model designs along multiple dimensions: vision encoders (e.g., CLIP-ViT, Swin transformer), text encoders (e.g., RoBERTa, DeBERTa), multimodal fusion (e.g., merged attention vs. co-attention), architecture design (e.g., encoder-only vs. encoder-decoder), and pre-training objectives (e.g., masked image modeling). We conduct comprehensive experiments on a wide range of VL tasks, and provide insights on how to train a performant VL transformer while maintaining fast inference speed. Notably, METER~achieves an accuracy of 77.64\% on the VQAv2 test-std set using only 4M images for pre-training, surpassing the state-of-the-art region-feature-based VinVL model by +1.04\%, and outperforming the previous best fully transformer-based ALBEF model by +1.6\%.
Triplet-Watershed for Hyperspectral Image Classification
Mar 17, 2021
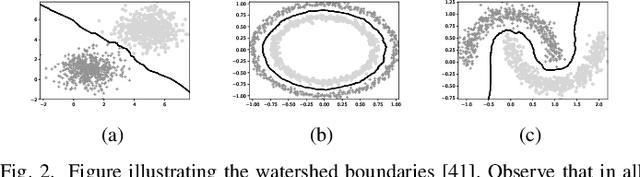
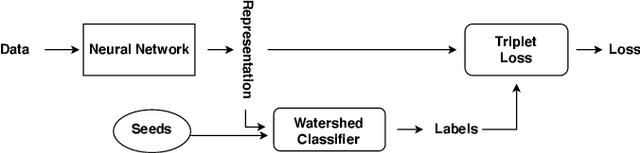
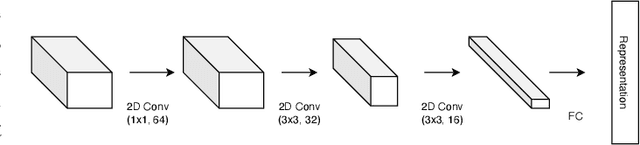
Hyperspectral images (HSI) consist of rich spatial and spectral information, which can potentially be used for several applications. However, noise, band correlations and high dimensionality restrict the applicability of such data. This is recently addressed using creative deep learning network architectures such as ResNet, SSRN, and A2S2K. However, the last layer, i.e the classification layer, remains unchanged and is taken to be the softmax classifier. In this article, we propose to use a watershed classifier. Watershed classifier extends the watershed operator from Mathematical Morphology for classification. In its vanilla form, the watershed classifier does not have any trainable parameters. In this article, we propose a novel approach to train deep learning networks to obtain representations suitable for the watershed classifier. The watershed classifier exploits the connectivity patterns, a characteristic of HSI datasets, for better inference. We show that exploiting such characteristics allows the Triplet-Watershed to achieve state-of-art results. These results are validated on Indianpines (IP), University of Pavia (UP), and Kennedy Space Center (KSC) datasets, relying on simple convnet architecture using a quarter of parameters compared to previous state-of-the-art networks.
IQ Photonic Receiver for Coherent Imaging with a Scalable Aperture
Aug 17, 2021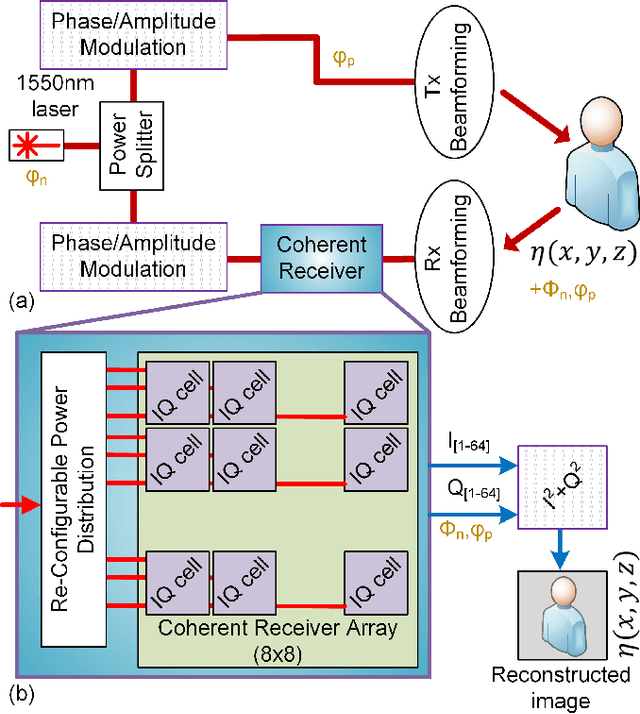
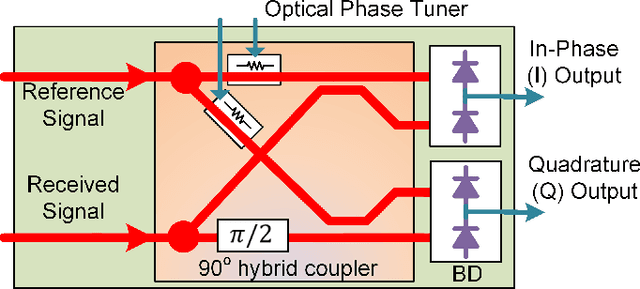
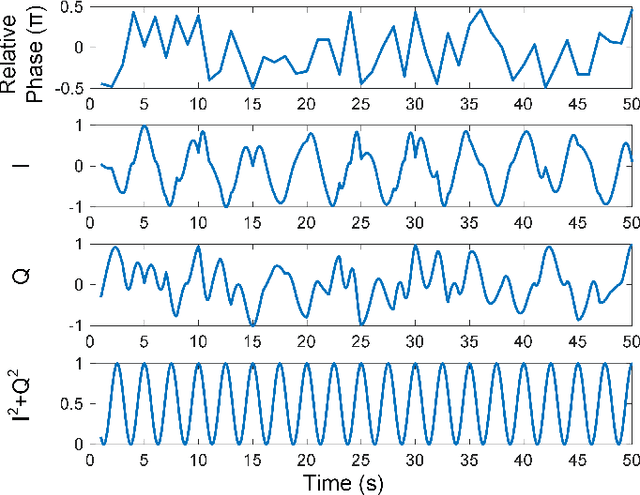
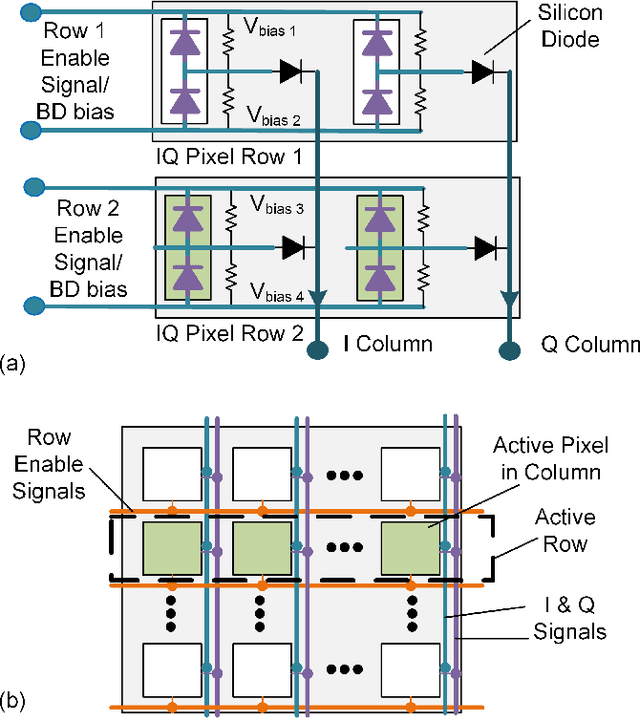
Silicon photonics (SiP) integrated coherent image sensors offer higher sensitivity and improved range-resolution-product compared to direct detection image sensors such as CCD and CMOS devices. Previous generation of SiP coherent imagers suffer from relative optical phase fluctuations between the signal and reference paths, which results in random phase and amplitude fluctuations in the output signal. This limitation negatively impacts the SNR and signal acquisition times. Here we present a coherent imager system that suppresses the optical carrier signal and removes non-idealities from the relative optical path using a photonic in-phase (I) and quadrature (Q) receiver via a $90^\circ$ hybrid detector. Furthermore, we incorporate row-column read-out and row-column addressing schemes to address the electro-optical interconnect density challenge. Our novel row-column read-out architecture for the sensor array requires only $2N$ interconnects for $N^2$ sensors. An $8\times8$ IQ sensor array is presented as a proof-of-concept demonstration with $1.2\times 10^{-5}$ resolution over range accuracy. Free-space FMCW ranging with 250um resolution at 1m distance has been demonstrated using this sensor array.
Visualisation of Medical Image Fusion and Translation for Accurate Diagnosis of High Grade Gliomas
Jan 30, 2020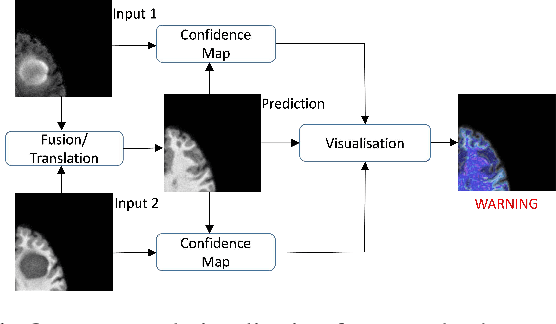
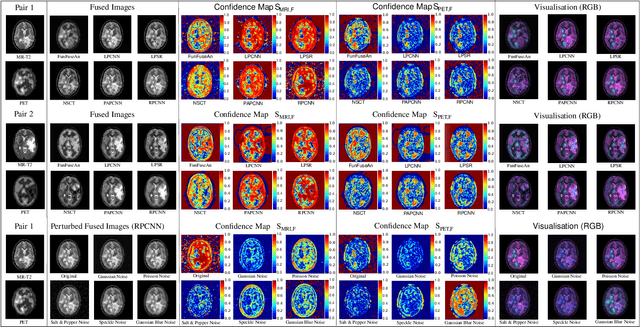
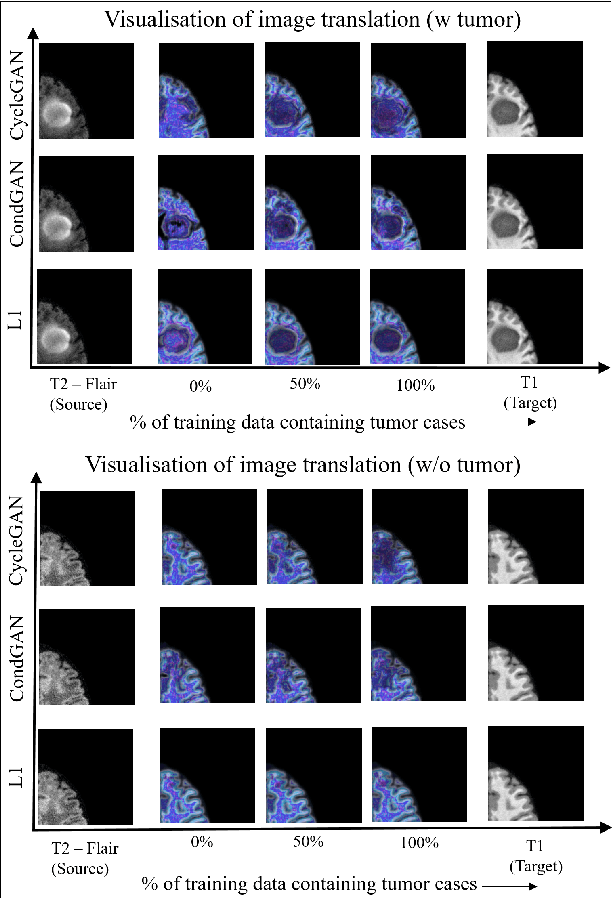
The medical image fusion combines two or more modalities into a single view while medical image translation synthesizes new images and assists in data augmentation. Together, these methods help in faster diagnosis of high grade malignant gliomas. However, they might be untrustworthy due to which neurosurgeons demand a robust visualisation tool to verify the reliability of the fusion and translation results before they make pre-operative surgical decisions. In this paper, we propose a novel approach to compute a confidence heat map between the source-target image pair by estimating the information transfer from the source to the target image using the joint probability distribution of the two images. We evaluate several fusion and translation methods using our visualisation procedure and showcase its robustness in enabling neurosurgeons to make finer clinical decisions.