 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbabilistic operator learning: generative modeling and uncertainty quantification for foundation models of differential equations
Sep 05, 2025In-context operator networks (ICON) are a class of operator learning methods based on the novel architectures of foundation models. Trained on a diverse set of datasets of initial and boundary conditions paired with corresponding solutions to ordinary and partial differential equations (ODEs and PDEs), ICON learns to map example condition-solution pairs of a given differential equation to an approximation of its solution operator. Here, we present a probabilistic framework that reveals ICON as implicitly performing Bayesian inference, where it computes the mean of the posterior predictive distribution over solution operators conditioned on the provided context, i.e., example condition-solution pairs. The formalism of random differential equations provides the probabilistic framework for describing the tasks ICON accomplishes while also providing a basis for understanding other multi-operator learning methods. This probabilistic perspective provides a basis for extending ICON to \emph{generative} settings, where one can sample from the posterior predictive distribution of solution operators. The generative formulation of ICON (GenICON) captures the underlying uncertainty in the solution operator, which enables principled uncertainty quantification in the solution predictions in operator learning.
A Multimodal PDE Foundation Model for Prediction and Scientific Text Descriptions
Feb 09, 2025Neural networks are one tool for approximating non-linear differential equations used in scientific computing tasks such as surrogate modeling, real-time predictions, and optimal control. PDE foundation models utilize neural networks to train approximations to multiple differential equations simultaneously and are thus a general purpose solver that can be adapted to downstream tasks. Current PDE foundation models focus on either learning general solution operators and/or the governing system of equations, and thus only handle numerical or symbolic modalities. However, real-world applications may require more flexible data modalities, e.g. text analysis or descriptive outputs. To address this gap, we propose a novel multimodal deep learning approach that leverages a transformer-based architecture to approximate solution operators for a wide variety of ODEs and PDEs. Our method integrates numerical inputs, such as equation parameters and initial conditions, with text descriptions of physical processes or system dynamics. This enables our model to handle settings where symbolic representations may be incomplete or unavailable. In addition to providing accurate numerical predictions, our approach generates interpretable scientific text descriptions, offering deeper insights into the underlying dynamics and solution properties. The numerical experiments show that our model provides accurate solutions for in-distribution data (with average relative error less than 3.3%) and out-of-distribution data (average relative error less than 7.8%) together with precise text descriptions (with correct descriptions generated 100% of times). In certain tests, the model is also shown to be capable of extrapolating solutions in time.
A Primal-Dual Framework for Transformers and Neural Networks
Jun 19, 2024Self-attention is key to the remarkable success of transformers in sequence modeling tasks including many applications in natural language processing and computer vision. Like neural network layers, these attention mechanisms are often developed by heuristics and experience. To provide a principled framework for constructing attention layers in transformers, we show that the self-attention corresponds to the support vector expansion derived from a support vector regression problem, whose primal formulation has the form of a neural network layer. Using our framework, we derive popular attention layers used in practice and propose two new attentions: 1) the Batch Normalized Attention (Attention-BN) derived from the batch normalization layer and 2) the Attention with Scaled Head (Attention-SH) derived from using less training data to fit the SVR model. We empirically demonstrate the advantages of the Attention-BN and Attention-SH in reducing head redundancy, increasing the model's accuracy, and improving the model's efficiency in a variety of practical applications including image and time-series classification.
Wasserstein proximal operators describe score-based generative models and resolve memorization
Feb 09, 2024



We focus on the fundamental mathematical structure of score-based generative models (SGMs). We first formulate SGMs in terms of the Wasserstein proximal operator (WPO) and demonstrate that, via mean-field games (MFGs), the WPO formulation reveals mathematical structure that describes the inductive bias of diffusion and score-based models. In particular, MFGs yield optimality conditions in the form of a pair of coupled partial differential equations: a forward-controlled Fokker-Planck (FP) equation, and a backward Hamilton-Jacobi-Bellman (HJB) equation. Via a Cole-Hopf transformation and taking advantage of the fact that the cross-entropy can be related to a linear functional of the density, we show that the HJB equation is an uncontrolled FP equation. Second, with the mathematical structure at hand, we present an interpretable kernel-based model for the score function which dramatically improves the performance of SGMs in terms of training samples and training time. In addition, the WPO-informed kernel model is explicitly constructed to avoid the recently studied memorization effects of score-based generative models. The mathematical form of the new kernel-based models in combination with the use of the terminal condition of the MFG reveals new explanations for the manifold learning and generalization properties of SGMs, and provides a resolution to their memorization effects. Finally, our mathematically informed, interpretable kernel-based model suggests new scalable bespoke neural network architectures for high-dimensional applications.
PDE Generalization of In-Context Operator Networks: A Study on 1D Scalar Nonlinear Conservation Laws
Jan 21, 2024Can we build a single large model for a wide range of PDE-related scientific learning tasks? Can this model generalize to new PDEs, even of new forms, without any fine-tuning? In-context operator learning and the corresponding model In-Context Operator Networks (ICON) represent an initial exploration of these questions. The capability of ICON regarding the first question has been demonstrated previously. In this paper, we present a detailed methodology for solving PDE problems with ICON, and show how a single ICON model can make forward and reverse predictions for different equations with different strides, provided with appropriately designed data prompts. We show the positive evidence to the second question, i.e., ICON can generalize well to some PDEs with new forms without any fine-tuning. This is exemplified through a study on 1D scalar nonlinear conservation laws, a family of PDEs with temporal evolution. We also show how to broaden the range of problems that an ICON model can address, by transforming functions and equations to ICON's capability scope. We believe that the progress in this paper is a significant step towards the goal of training a foundation model for PDE-related tasks under the in-context operator learning framework.
Prompting In-Context Operator Learning with Sensor Data, Equations, and Natural Language
Aug 09, 2023



In the growing domain of scientific machine learning, in-context operator learning has demonstrated notable potential in learning operators from prompted data during inference stage without weight updates. However, the current model's overdependence on sensor data, may inadvertently overlook the invaluable human insight into the operator. To address this, we present a transformation of in-context operator learning into a multi-modal paradigm. We propose the use of "captions" to integrate human knowledge about the operator, expressed through natural language descriptions and equations. We illustrate how this method not only broadens the flexibility and generality of physics-informed learning, but also significantly boosts learning performance and reduces data needs. Furthermore, we introduce a more efficient neural network architecture for multi-modal in-context operator learning, referred to as "ICON-LM", based on a language-model-like architecture. We demonstrate the viability of "ICON-LM" for scientific machine learning tasks, which creates a new path for the application of language models.
In-Context Operator Learning for Differential Equation Problems
Apr 17, 2023



This paper introduces a new neural-network-based approach, namely IN-context Differential Equation Encoder-Decoder (INDEED), to simultaneously learn operators from data and apply it to new questions during the inference stage, without any weight update. Existing methods are limited to using a neural network to approximate a specific equation solution or a specific operator, requiring retraining when switching to a new problem with different equations. By training a single neural network as an operator learner, we can not only get rid of retraining (even fine-tuning) the neural network for new problems, but also leverage the commonalities shared across operators so that only a few demos are needed when learning a new operator. Our numerical results show the neural network's capability as a few-shot operator learner for a diversified type of differential equation problems, including forward and inverse problems of ODEs and PDEs, and also show that it can generalize its learning capability to operators beyond the training distribution, even to an unseen type of operator.
Momentum Transformer: Closing the Performance Gap Between Self-attention and Its Linearization
Aug 01, 2022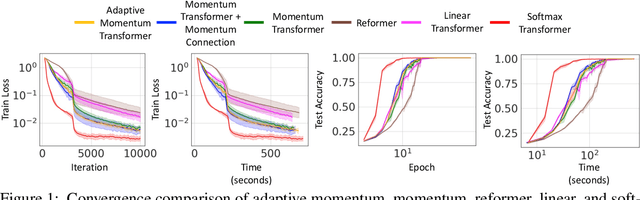
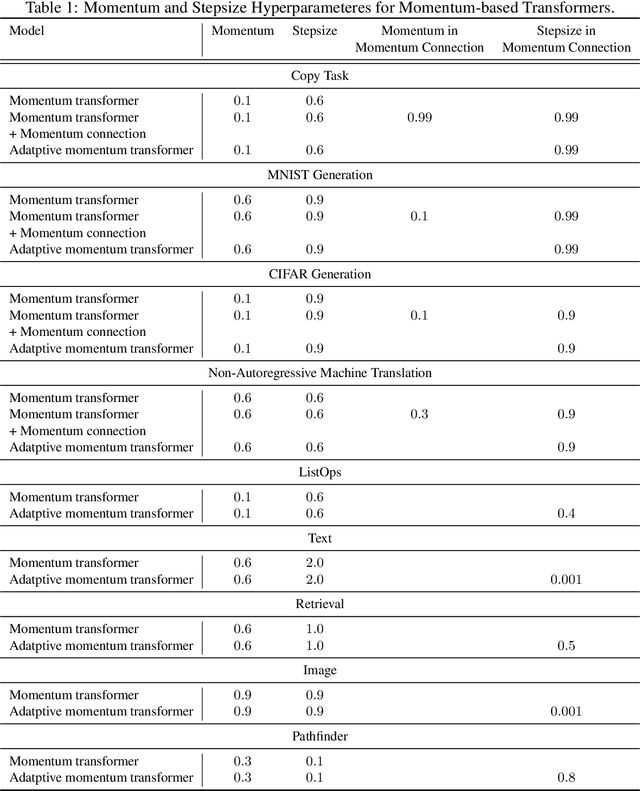

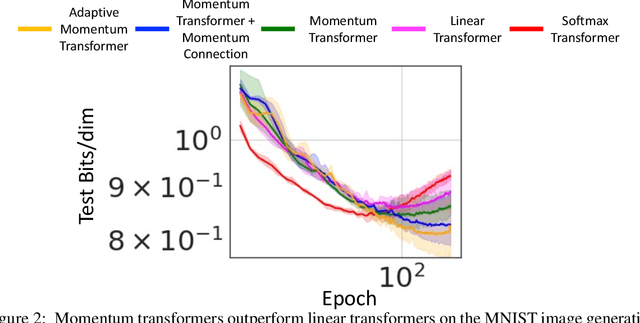
Transformers have achieved remarkable success in sequence modeling and beyond but suffer from quadratic computational and memory complexities with respect to the length of the input sequence. Leveraging techniques include sparse and linear attention and hashing tricks; efficient transformers have been proposed to reduce the quadratic complexity of transformers but significantly degrade the accuracy. In response, we first interpret the linear attention and residual connections in computing the attention map as gradient descent steps. We then introduce momentum into these components and propose the \emph{momentum transformer}, which utilizes momentum to improve the accuracy of linear transformers while maintaining linear memory and computational complexities. Furthermore, we develop an adaptive strategy to compute the momentum value for our model based on the optimal momentum for quadratic optimization. This adaptive momentum eliminates the need to search for the optimal momentum value and further enhances the performance of the momentum transformer. A range of experiments on both autoregressive and non-autoregressive tasks, including image generation and machine translation, demonstrate that the momentum transformer outperforms popular linear transformers in training efficiency and accuracy.
Multi-Agent Shape Control with Optimal Transport
Jun 30, 2022

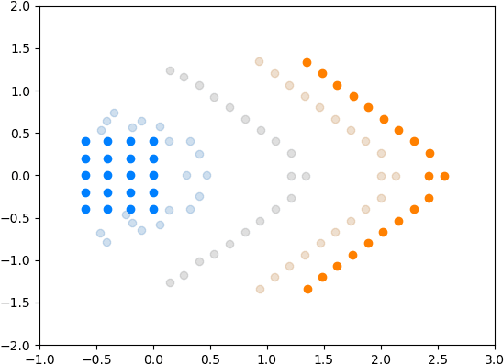
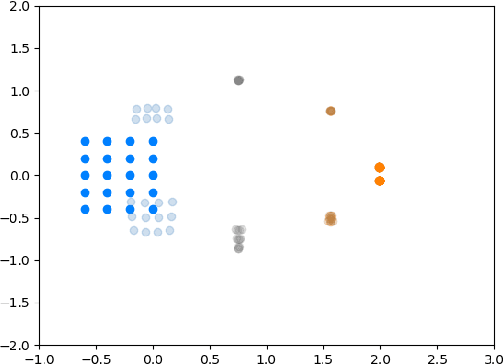
We introduce a method called MASCOT (Multi-Agent Shape Control with Optimal Transport) to compute optimal control solutions of agents with shape/formation/density constraints. For example, we might want to apply shape constraints on the agents -- perhaps we desire the agents to hold a particular shape along the path, or we want agents to spread out in order to minimize collisions. We might also want a proportion of agents to move to one destination, while the other agents move to another, and to do this in the optimal way, i.e. the source-destination assignments should be optimal. In order to achieve this, we utilize the Earth Mover's Distance from Optimal Transport to distribute the agents into their proper positions so that certain shapes can be satisfied. This cost is both introduced in the terminal cost and in the running cost of the optimal control problem.
Transformer with Fourier Integral Attentions
Jun 01, 2022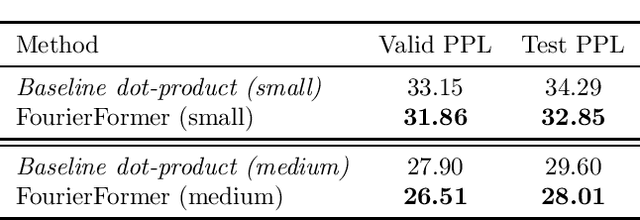



Multi-head attention empowers the recent success of transformers, the state-of-the-art models that have achieved remarkable success in sequence modeling and beyond. These attention mechanisms compute the pairwise dot products between the queries and keys, which results from the use of unnormalized Gaussian kernels with the assumption that the queries follow a mixture of Gaussian distribution. There is no guarantee that this assumption is valid in practice. In response, we first interpret attention in transformers as a nonparametric kernel regression. We then propose the FourierFormer, a new class of transformers in which the dot-product kernels are replaced by the novel generalized Fourier integral kernels. Different from the dot-product kernels, where we need to choose a good covariance matrix to capture the dependency of the features of data, the generalized Fourier integral kernels can automatically capture such dependency and remove the need to tune the covariance matrix. We theoretically prove that our proposed Fourier integral kernels can efficiently approximate any key and query distributions. Compared to the conventional transformers with dot-product attention, FourierFormers attain better accuracy and reduce the redundancy between attention heads. We empirically corroborate the advantages of FourierFormers over the baseline transformers in a variety of practical applications including language modeling and image classification.