 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Defending Against Physically Realizable Attacks on Image Classification
Sep 20, 2019

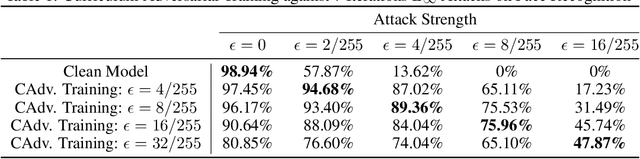
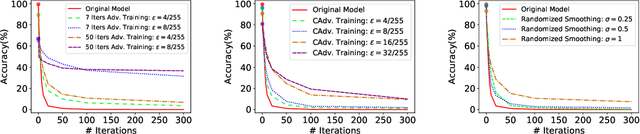
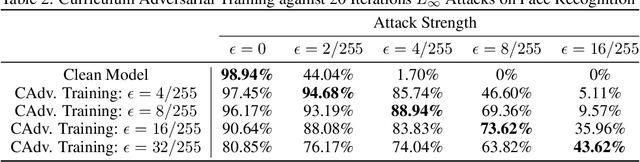
We study the problem of defending deep neural network approaches for image classification from physically realizable attacks. First, we demonstrate that the two most scalable and effective methods for learning robust models, adversarial training with PGD attacks and randomized smoothing, exhibit very limited effectiveness against three of the highest profile physical attacks. Next, we propose a new abstract adversarial model, rectangular occlusion attacks, in which an adversary places a small adversarially crafted rectangle in an image, and develop two approaches for efficiently computing the resulting adversarial examples. Finally, we demonstrate that adversarial training using our new attack yields image classification models that exhibit high robustness against the physically realizable attacks we study, offering the first effective generic defense against such attacks.
Bi-Directional Domain Translation for Zero-Shot Sketch-Based Image Retrieval
Nov 29, 2019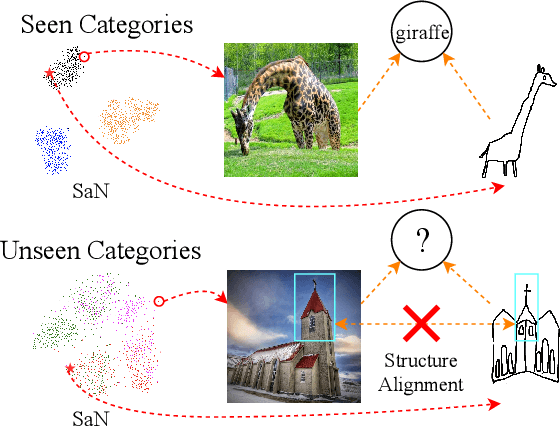
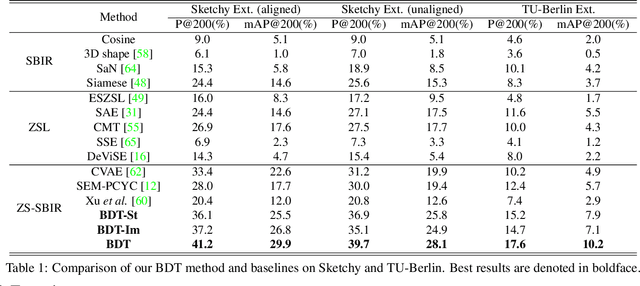
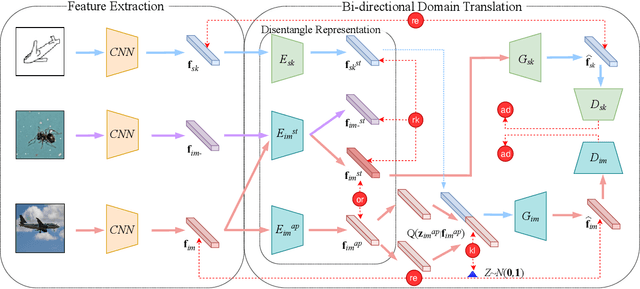
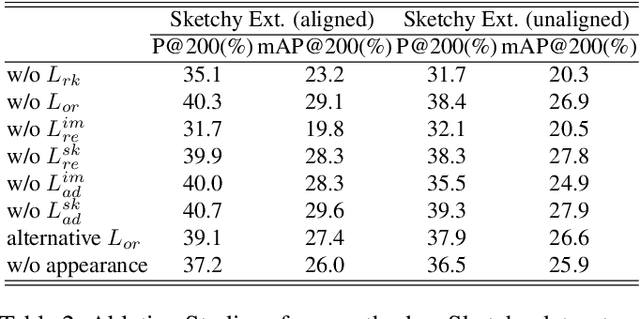
The goal of Sketch-Based Image Retrieval (SBIR) is using free-hand sketches to retrieve images of the same category from a natural image gallery. However, SBIR requires all categories to be seen during training, which cannot be guaranteed in real-world applications. So we investigate more challenging Zero-Shot SBIR (ZS-SBIR), in which test categories do not appear in the training stage. Traditional SBIR methods are prone to be category-based retrieval and cannot generalize well from seen categories to unseen ones. In contrast, we disentangle image features into structure features and appearance features to facilitate structure-based retrieval. To assist feature disentanglement and take full advantage of disentangled information, we propose a Bi-directional Domain Translation (BDT) framework for ZS-SBIR, in which the image domain and sketch domain can be translated to each other through disentangled structure and appearance features. Finally, we perform retrieval in both structure feature space and image feature space. Extensive experiments demonstrate that our proposed approach remarkably outperforms state-of-the-art approaches by about 8% on the Sketchy dataset and over 5% on the TU-Berlin dataset.
ContinuityLearner: Geometric Continuity Feature Learning for Lane Segmentation
Aug 07, 2021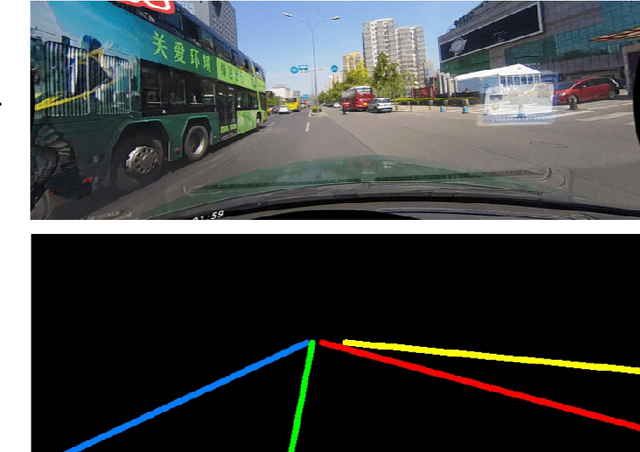
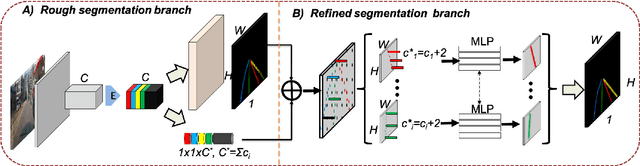
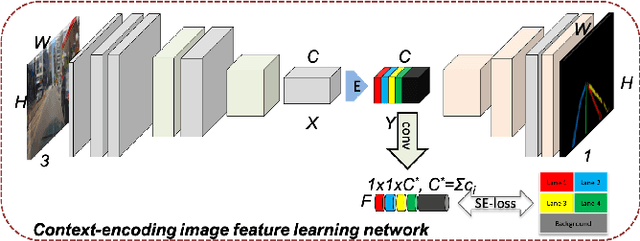
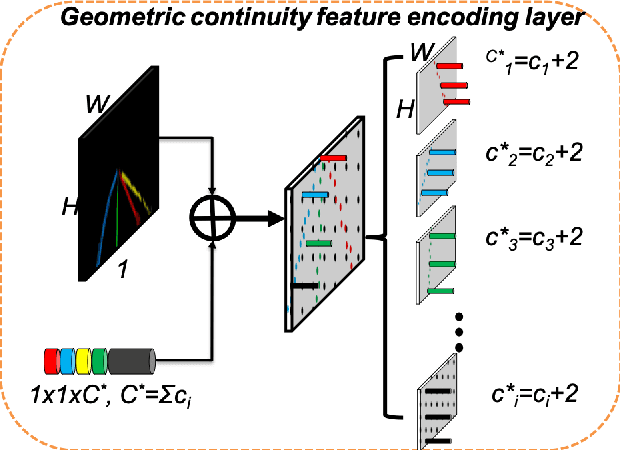
Lane segmentation is a challenging issue in autonomous driving system designing because lane marks show weak textural consistency due to occlusion or extreme illumination but strong geometric continuity in traffic images, from which general convolution neural networks (CNNs) are not capable of learning semantic objects. To empower conventional CNNs in learning geometric clues of lanes, we propose a deep network named ContinuityLearner to better learn geometric prior within lane. Specifically, our proposed CNN-based paradigm involves a novel Context-encoding image feature learning network to generate class-dependent image feature maps and a new encoding layer to exploit the geometric continuity feature representation by fusing both spatial and visual information of lane together. The ContinuityLearner, performing on the geometric continuity feature of lanes, is trained to directly predict the lane in traffic scenarios with integrated and continuous instance semantic. The experimental results on the CULane dataset and the Tusimple benchmark demonstrate that our ContinuityLearner has superior performance over other state-of-the-art techniques in lane segmentation.
Learning Data Teaching Strategies Via Knowledge Tracing
Nov 13, 2021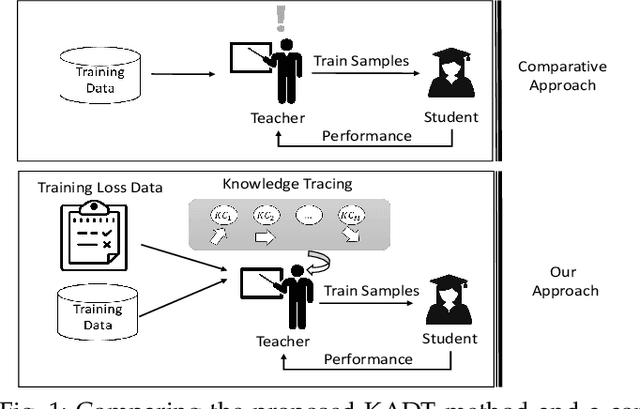

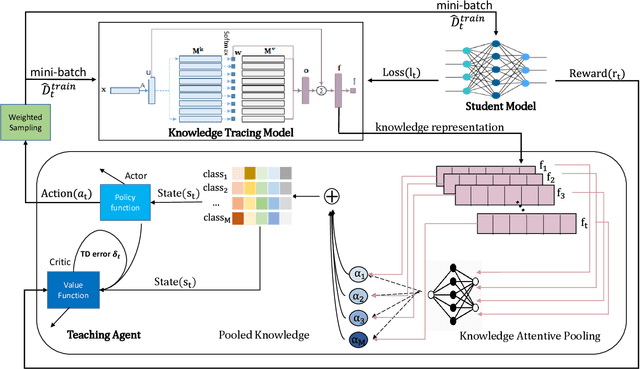

Teaching plays a fundamental role in human learning. Typically, a human teaching strategy would involve assessing a student's knowledge progress for tailoring the teaching materials in a way that enhances the learning progress. A human teacher would achieve this by tracing a student's knowledge over important learning concepts in a task. Albeit, such teaching strategy is not well exploited yet in machine learning as current machine teaching methods tend to directly assess the progress on individual training samples without paying attention to the underlying learning concepts in a learning task. In this paper, we propose a novel method, called Knowledge Augmented Data Teaching (KADT), which can optimize a data teaching strategy for a student model by tracing its knowledge progress over multiple learning concepts in a learning task. Specifically, the KADT method incorporates a knowledge tracing model to dynamically capture the knowledge progress of a student model in terms of latent learning concepts. Then we develop an attention pooling mechanism to distill knowledge representations of a student model with respect to class labels, which enables to develop a data teaching strategy on critical training samples. We have evaluated the performance of the KADT method on four different machine learning tasks including knowledge tracing, sentiment analysis, movie recommendation, and image classification. The results comparing to the state-of-the-art methods empirically validate that KADT consistently outperforms others on all tasks.
Unpaired Cross-lingual Image Caption Generation with Self-Supervised Rewards
Aug 15, 2019
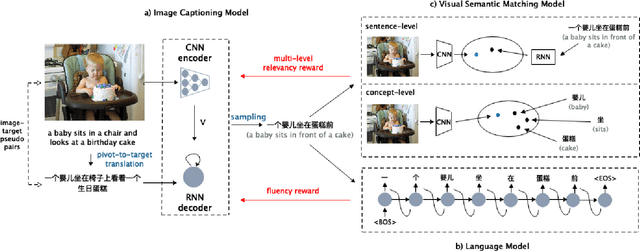
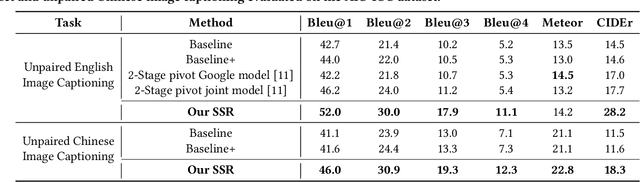
Generating image descriptions in different languages is essential to satisfy users worldwide. However, it is prohibitively expensive to collect large-scale paired image-caption dataset for every target language which is critical for training descent image captioning models. Previous works tackle the unpaired cross-lingual image captioning problem through a pivot language, which is with the help of paired image-caption data in the pivot language and pivot-to-target machine translation models. However, such language-pivoted approach suffers from inaccuracy brought by the pivot-to-target translation, including disfluency and visual irrelevancy errors. In this paper, we propose to generate cross-lingual image captions with self-supervised rewards in the reinforcement learning framework to alleviate these two types of errors. We employ self-supervision from mono-lingual corpus in the target language to provide fluency reward, and propose a multi-level visual semantic matching model to provide both sentence-level and concept-level visual relevancy rewards. We conduct extensive experiments for unpaired cross-lingual image captioning in both English and Chinese respectively on two widely used image caption corpora. The proposed approach achieves significant performance improvement over state-of-the-art methods.
Arch-Net: Model Distillation for Architecture Agnostic Model Deployment
Nov 01, 2021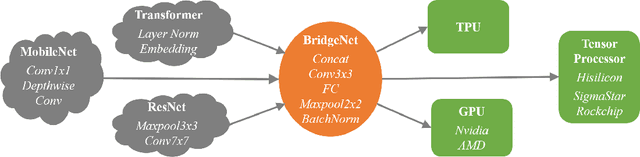
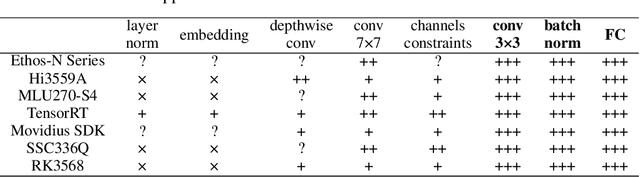
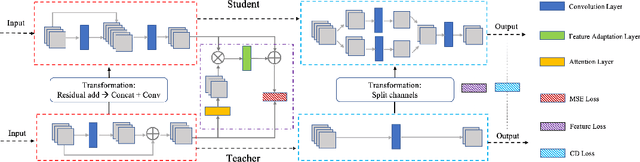

Vast requirement of computation power of Deep Neural Networks is a major hurdle to their real world applications. Many recent Application Specific Integrated Circuit (ASIC) chips feature dedicated hardware support for Neural Network Acceleration. However, as ASICs take multiple years to develop, they are inevitably out-paced by the latest development in Neural Architecture Research. For example, Transformer Networks do not have native support on many popular chips, and hence are difficult to deploy. In this paper, we propose Arch-Net, a family of Neural Networks made up of only operators efficiently supported across most architectures of ASICs. When a Arch-Net is produced, less common network constructs, like Layer Normalization and Embedding Layers, are eliminated in a progressive manner through label-free Blockwise Model Distillation, while performing sub-eight bit quantization at the same time to maximize performance. Empirical results on machine translation and image classification tasks confirm that we can transform latest developed Neural Architectures into fast running and as-accurate Arch-Net, ready for deployment on multiple mass-produced ASIC chips. The code will be available at https://github.com/megvii-research/Arch-Net.
A Proposed Set of Communicative Gestures for Human Robot Interaction and an RGB Image-based Gesture Recognizer Implemented in ROS
Sep 21, 2021

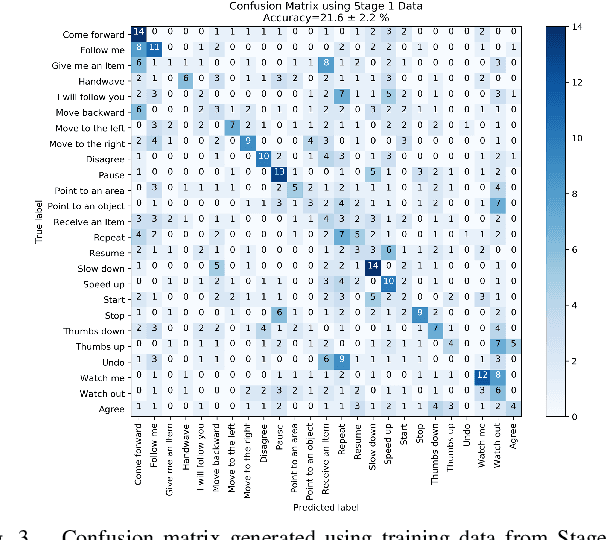
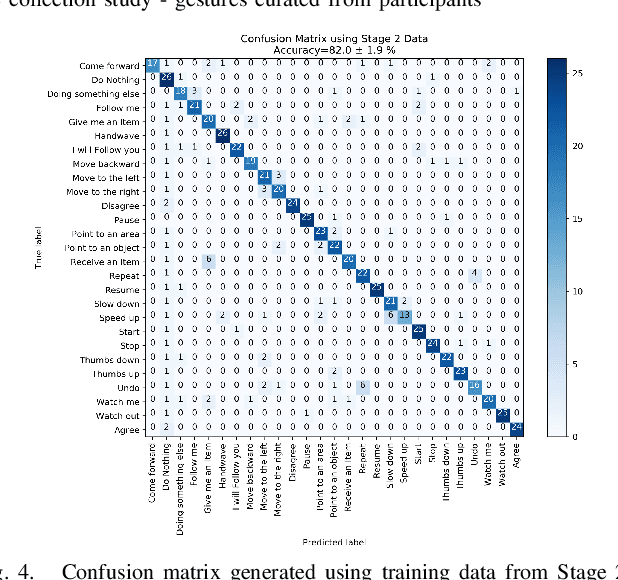
We propose a set of communicative gestures and develop a gesture recognition system with the aim of facilitating more intuitive Human-Robot Interaction (HRI) through gestures. First, we propose a set of commands commonly used for human-robot interaction. Next, an online user study with 190 participants was performed to investigate if there was an agreed set of gestures that people intuitively use to communicate the given commands to robots when no guidance or training were given. As we found large variations among the gestures exist between participants, we then proposed a set of gestures for the proposed commands to be used as a common foundation for robot interaction. We collected ~7500 video demonstrations of the proposed gestures and trained a gesture recognition model, adapting 3D Convolutional Neural Networks (CNN) as the classifier, with a final accuracy of 84.1% (sigma=2.4). The resulting model was capable of training successfully with a relatively small amount of training data. We integrated the gesture recognition model into the ROS framework and report details for a demonstrated use case, where a person commands a robot to perform a pick and place task using the proposed set. This integrated ROS gesture recognition system is made available for use, and built with the intention to allow for new adaptations depending on robot model and use case scenarios, for novel user applications.
Calibrating Class Activation Maps for Long-Tailed Visual Recognition
Aug 29, 2021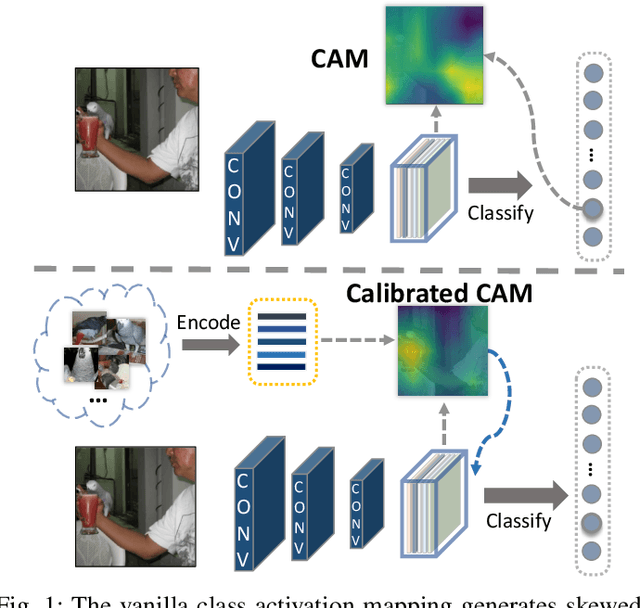
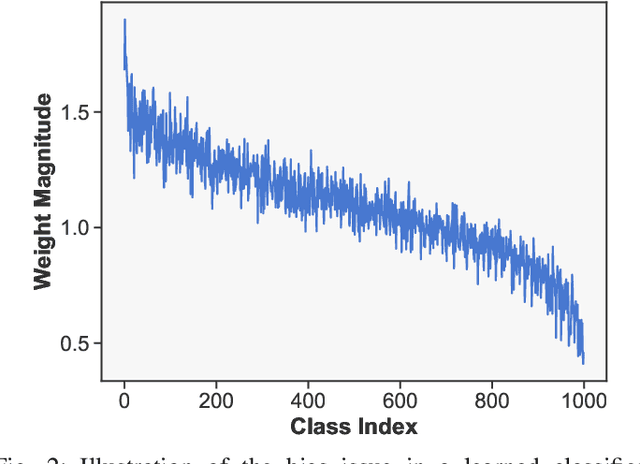
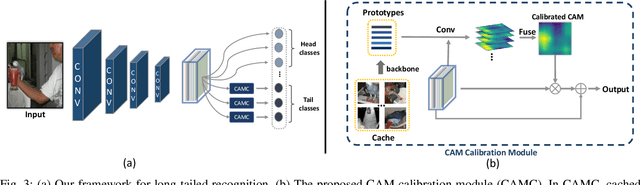
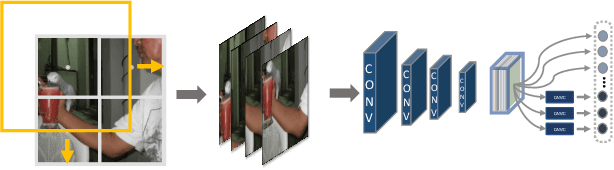
Real-world visual recognition problems often exhibit long-tailed distributions, where the amount of data for learning in different categories shows significant imbalance. Standard classification models learned on such data distribution often make biased predictions towards the head classes while generalizing poorly to the tail classes. In this paper, we present two effective modifications of CNNs to improve network learning from long-tailed distribution. First, we present a Class Activation Map Calibration (CAMC) module to improve the learning and prediction of network classifiers, by enforcing network prediction based on important image regions. The proposed CAMC module highlights the correlated image regions across data and reinforces the representations in these areas to obtain a better global representation for classification. Furthermore, we investigate the use of normalized classifiers for representation learning in long-tailed problems. Our empirical study demonstrates that by simply scaling the outputs of the classifier with an appropriate scalar, we can effectively improve the classification accuracy on tail classes without losing the accuracy of head classes. We conduct extensive experiments to validate the effectiveness of our design and we set new state-of-the-art performance on five benchmarks, including ImageNet-LT, Places-LT, iNaturalist 2018, CIFAR10-LT, and CIFAR100-LT.
Deep Interleaved Network for Image Super-Resolution With Asymmetric Co-Attention
Apr 24, 2020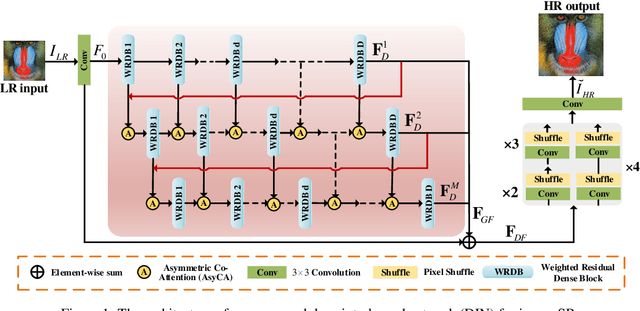
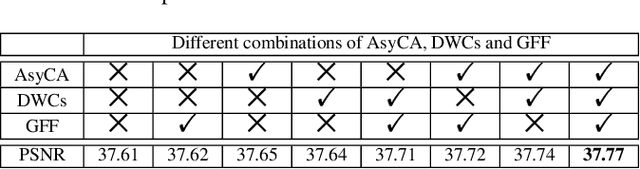
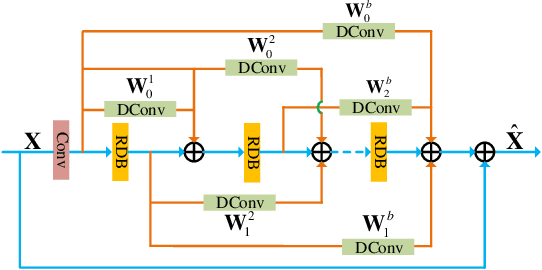
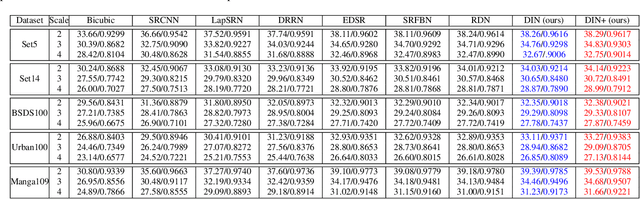
Recently, Convolutional Neural Networks (CNN) based image super-resolution (SR) have shown significant success in the literature. However, these methods are implemented as single-path stream to enrich feature maps from the input for the final prediction, which fail to fully incorporate former low-level features into later high-level features. In this paper, to tackle this problem, we propose a deep interleaved network (DIN) to learn how information at different states should be combined for image SR where shallow information guides deep representative features prediction. Our DIN follows a multi-branch pattern allowing multiple interconnected branches to interleave and fuse at different states. Besides, the asymmetric co-attention (AsyCA) is proposed and attacked to the interleaved nodes to adaptively emphasize informative features from different states and improve the discriminative ability of networks. Extensive experiments demonstrate the superiority of our proposed DIN in comparison with the state-of-the-art SR methods.
Benchmarks for Corruption Invariant Person Re-identification
Nov 01, 2021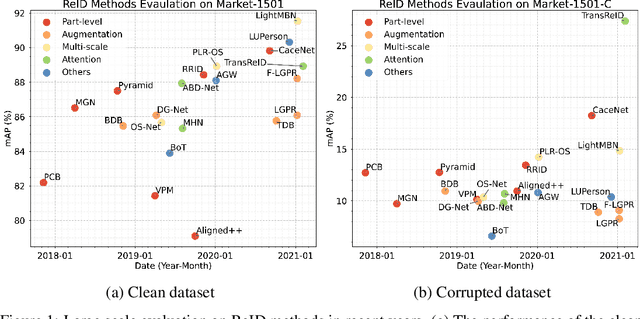
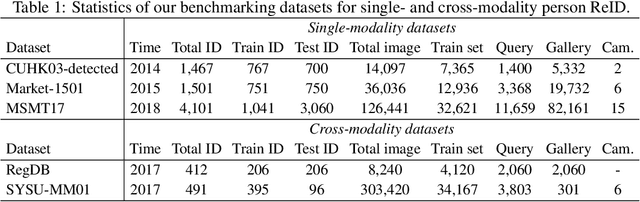
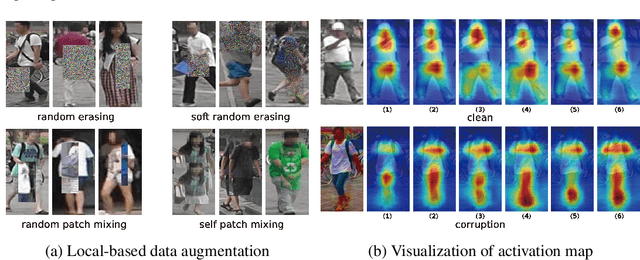
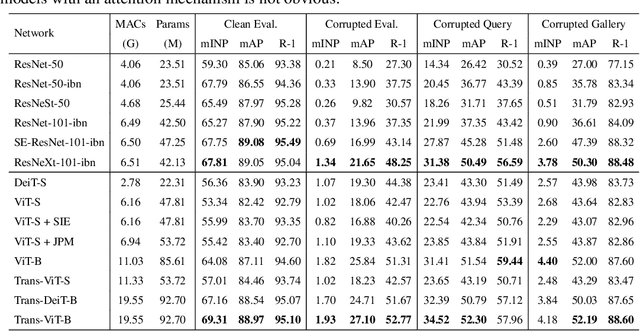
When deploying person re-identification (ReID) model in safety-critical applications, it is pivotal to understanding the robustness of the model against a diverse array of image corruptions. However, current evaluations of person ReID only consider the performance on clean datasets and ignore images in various corrupted scenarios. In this work, we comprehensively establish six ReID benchmarks for learning corruption invariant representation. In the field of ReID, we are the first to conduct an exhaustive study on corruption invariant learning in single- and cross-modality datasets, including Market-1501, CUHK03, MSMT17, RegDB, SYSU-MM01. After reproducing and examining the robustness performance of 21 recent ReID methods, we have some observations: 1) transformer-based models are more robust towards corrupted images, compared with CNN-based models, 2) increasing the probability of random erasing (a commonly used augmentation method) hurts model corruption robustness, 3) cross-dataset generalization improves with corruption robustness increases. By analyzing the above observations, we propose a strong baseline on both single- and cross-modality ReID datasets which achieves improved robustness against diverse corruptions. Our codes are available on https://github.com/MinghuiChen43/CIL-ReID.