 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-organ Segmentation Network with Adversarial Performance Validator
Apr 16, 2022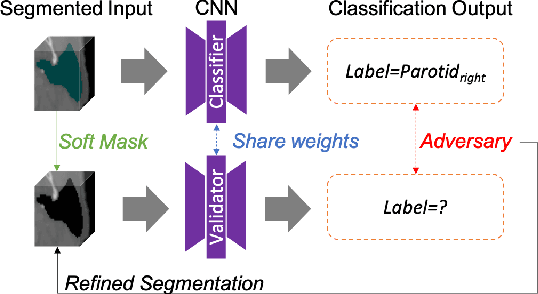
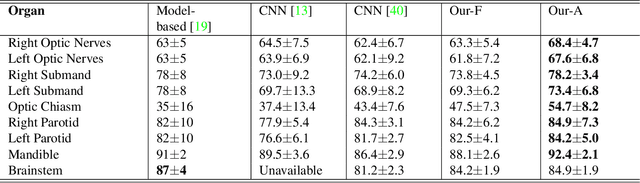
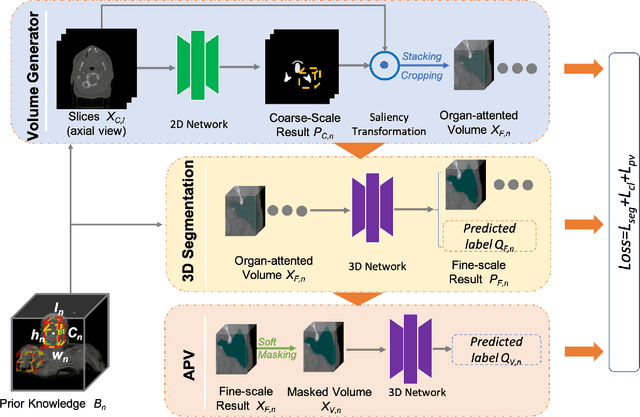
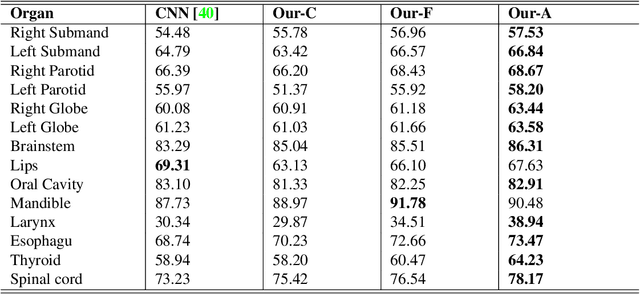
CT organ segmentation on computed tomography (CT) images becomes a significant brick for modern medical image analysis, supporting clinic workflows in multiple domains. Previous segmentation methods include 2D convolution neural networks (CNN) based approaches, fed by CT image slices that lack the structural knowledge in axial view, and 3D CNN-based methods with the expensive computation cost in multi-organ segmentation applications. This paper introduces an adversarial performance validation network into a 2D-to-3D segmentation framework. The classifier and performance validator competition contribute to accurate segmentation results via back-propagation. The proposed network organically converts the 2D-coarse result to 3D high-quality segmentation masks in a coarse-to-fine manner, allowing joint optimization to improve segmentation accuracy. Besides, the structural information of one specific organ is depicted by a statistics-meaningful prior bounding box, which is transformed into a global feature leveraging the learning process in 3D fine segmentation. The experiments on the NIH pancreas segmentation dataset demonstrate the proposed network achieves state-of-the-art accuracy on small organ segmentation and outperforms the previous best. High accuracy is also reported on multi-organ segmentation in a dataset collected by ourselves.
Deep Open Set Identification for RF Devices
Dec 05, 2021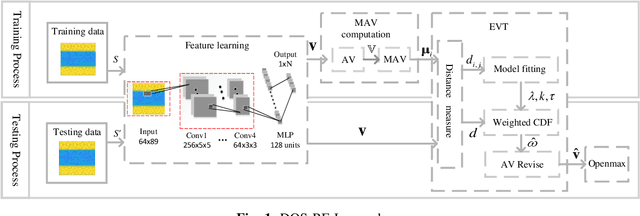
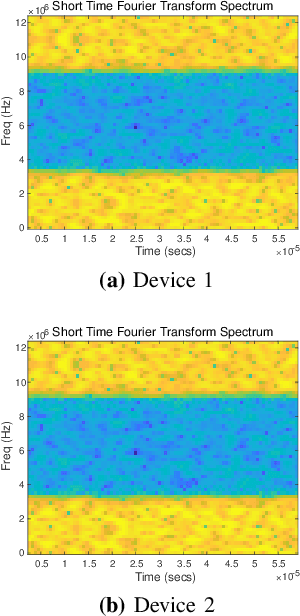
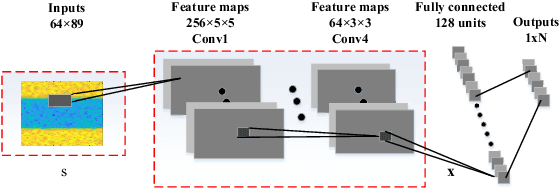
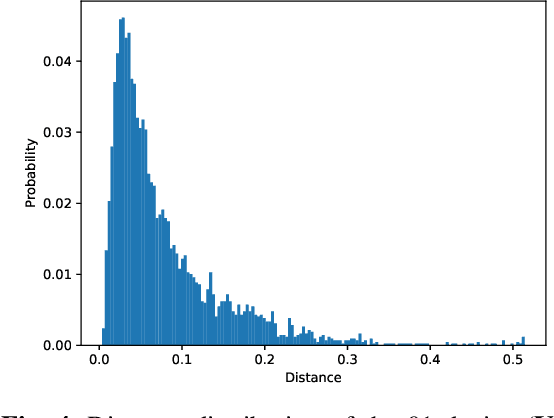
Artificial intelligence (AI) based device identification improves the security of the internet of things (IoT), and accelerates the authentication process. However, existing approaches rely on the assumption that we can learn all the classes from the training set, namely, closed-set classification. To overcome the closed-set limitation, we propose a novel open set RF device identification method to classify unseen classes in the testing set. First, we design a specific convolution neural network (CNN) with a short-time Fourier transforming (STFT) pre-processing module, which efficiently recognizes the differences of feature maps learned from various RF device signals. Then to generate a representation of known class bounds, we estimate the probability map of the open-set via the OpenMax function. We conduct experiments on sampled data and voice signal sets, considering various pre-processing schemes, network structures, distance metrics, tail sizes, and openness degrees. The simulation results show the superiority of the proposed method in terms of robustness and accuracy.
ContinuityLearner: Geometric Continuity Feature Learning for Lane Segmentation
Aug 07, 2021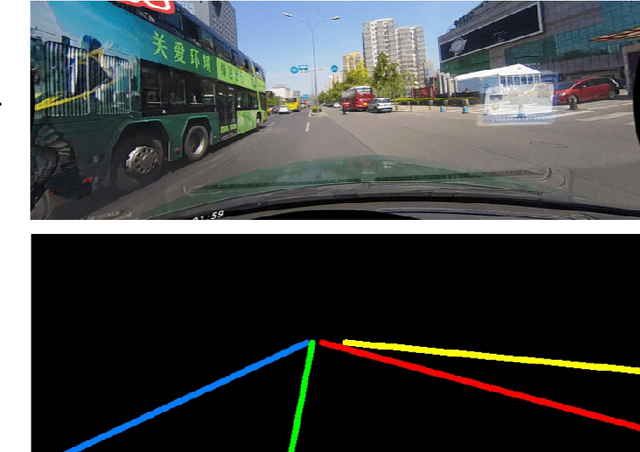
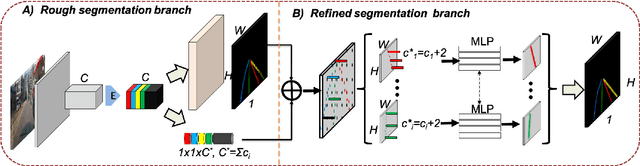
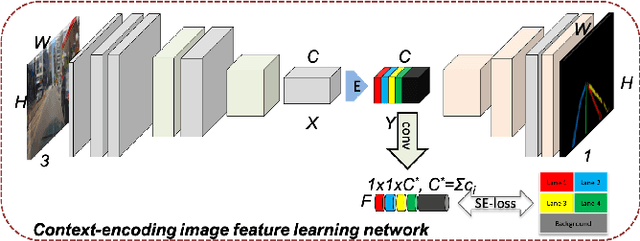
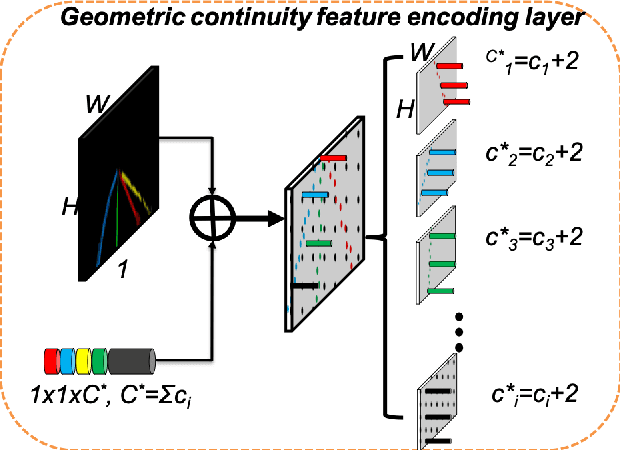
Lane segmentation is a challenging issue in autonomous driving system designing because lane marks show weak textural consistency due to occlusion or extreme illumination but strong geometric continuity in traffic images, from which general convolution neural networks (CNNs) are not capable of learning semantic objects. To empower conventional CNNs in learning geometric clues of lanes, we propose a deep network named ContinuityLearner to better learn geometric prior within lane. Specifically, our proposed CNN-based paradigm involves a novel Context-encoding image feature learning network to generate class-dependent image feature maps and a new encoding layer to exploit the geometric continuity feature representation by fusing both spatial and visual information of lane together. The ContinuityLearner, performing on the geometric continuity feature of lanes, is trained to directly predict the lane in traffic scenarios with integrated and continuous instance semantic. The experimental results on the CULane dataset and the Tusimple benchmark demonstrate that our ContinuityLearner has superior performance over other state-of-the-art techniques in lane segmentation.