 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoVLN: Decoupling Observation, Reasoning, and Correction for Vision-and-Language Navigation
Mar 13, 2026Vision-and-Language Navigation (VLN) requires agents to follow long-horizon instructions and navigate complex 3D environments. However, existing approaches face two major challenges: constructing an effective long-term memory bank and overcoming the compounding errors problem. To address these issues, we propose DecoVLN, an effective framework designed for robust streaming perception and closed-loop control in long-horizon navigation. First, we formulate long-term memory construction as an optimization problem and introduce adaptive refinement mechanism that selects frames from a historical candidate pool by iteratively optimizing a unified scoring function. This function jointly balances three key criteria: semantic relevance to the instruction, visual diversity from the selected memory, and temporal coverage of the historical trajectory. Second, to alleviate compounding errors, we introduce a state-action pair-level corrective finetuning strategy. By leveraging geodesic distance between states to precisely quantify deviation from the expert trajectory, the agent collects high-quality state-action pairs in the trusted region while filtering out the polluted data with low relevance. This improves both the efficiency and stability of error correction. Extensive experiments demonstrate the effectiveness of DecoVLN, and we have deployed it in real-world environments.
Deep Interleaved Network for Image Super-Resolution With Asymmetric Co-Attention
Apr 24, 2020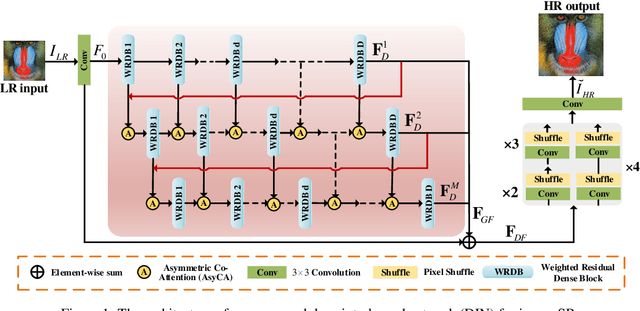
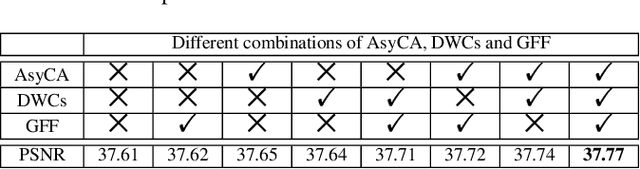
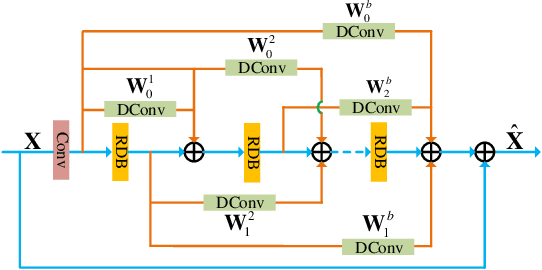
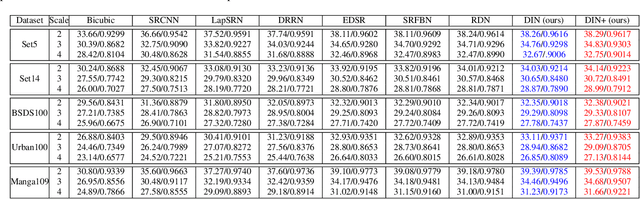
Recently, Convolutional Neural Networks (CNN) based image super-resolution (SR) have shown significant success in the literature. However, these methods are implemented as single-path stream to enrich feature maps from the input for the final prediction, which fail to fully incorporate former low-level features into later high-level features. In this paper, to tackle this problem, we propose a deep interleaved network (DIN) to learn how information at different states should be combined for image SR where shallow information guides deep representative features prediction. Our DIN follows a multi-branch pattern allowing multiple interconnected branches to interleave and fuse at different states. Besides, the asymmetric co-attention (AsyCA) is proposed and attacked to the interleaved nodes to adaptively emphasize informative features from different states and improve the discriminative ability of networks. Extensive experiments demonstrate the superiority of our proposed DIN in comparison with the state-of-the-art SR methods.