 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Reverse Engineering of Generative Models: Inferring Model Hyperparameters from Generated Images
Jun 15, 2021
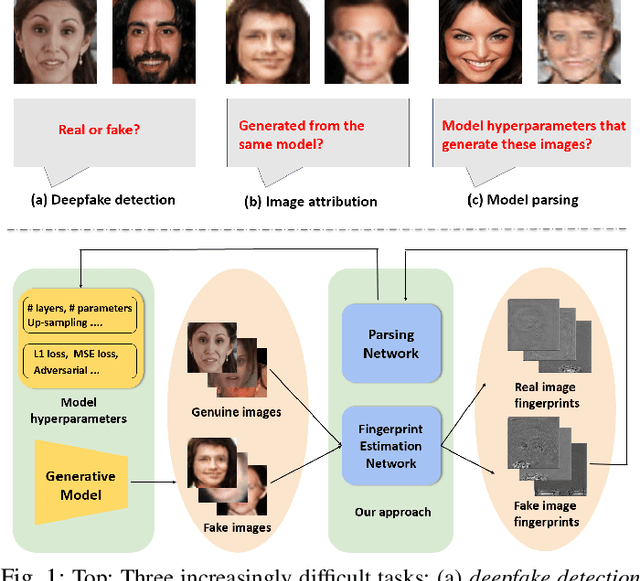


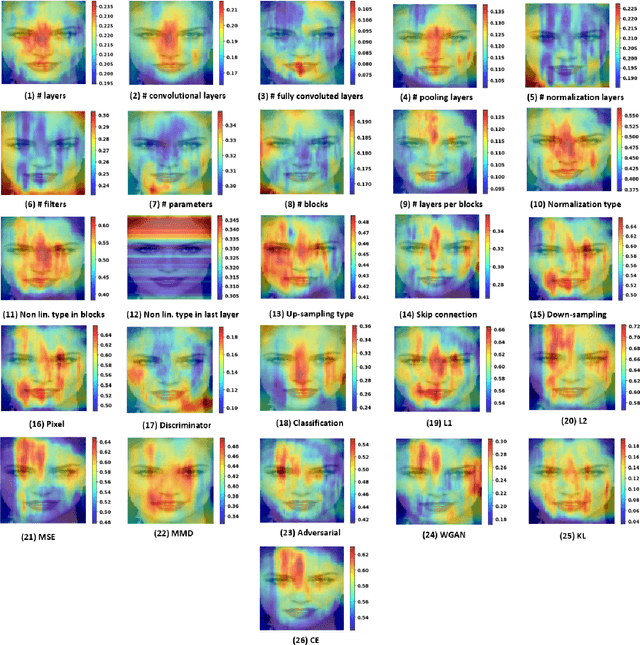
State-of-the-art (SOTA) Generative Models (GMs) can synthesize photo-realistic images that are hard for humans to distinguish from genuine photos. We propose to perform reverse engineering of GMs to infer the model hyperparameters from the images generated by these models. We define a novel problem, "model parsing", as estimating GM network architectures and training loss functions by examining their generated images -- a task seemingly impossible for human beings. To tackle this problem, we propose a framework with two components: a Fingerprint Estimation Network (FEN), which estimates a GM fingerprint from a generated image by training with four constraints to encourage the fingerprint to have desired properties, and a Parsing Network (PN), which predicts network architecture and loss functions from the estimated fingerprints. To evaluate our approach, we collect a fake image dataset with $100$K images generated by $100$ GMs. Extensive experiments show encouraging results in parsing the hyperparameters of the unseen models. Finally, our fingerprint estimation can be leveraged for deepfake detection and image attribution, as we show by reporting SOTA results on both the recent Celeb-DF and image attribution benchmarks.
Nonlocal Patches based Gaussian Mixture Model for Image Inpainting
Sep 22, 2019



We consider the inpainting problem for noisy images. It is very challenge to suppress noise when image inpainting is processed. An image patches based nonlocal variational method is proposed to simultaneously inpainting and denoising in this paper. Our approach is developed on an assumption that the small image patches should be obeyed a distribution which can be described by a high dimension Gaussian Mixture Model. By a maximum a posteriori (MAP) estimation, we formulate a new regularization term according to the log-likelihood function of the mixture model. To optimize this regularization term efficiently, we adopt the idea of the Expectation Maximum (EM) algorithm. In which, the expectation step can give an adaptive weighting function which can be regarded as a nonlocal connections among pixels. Using this fact, we built a framework for non-local image inpainting under noise. Moreover, we mathematically prove the existence of minimizer for the proposed inpainting model. By using a spitting algorithm, the proposed model are able to realize image inpainting and denoising simultaneously. Numerical results show that the proposed method can produce impressive reconstructed results when the inpainting region is rather large.
Meta-Learning for Multi-Label Few-Shot Classification
Oct 26, 2021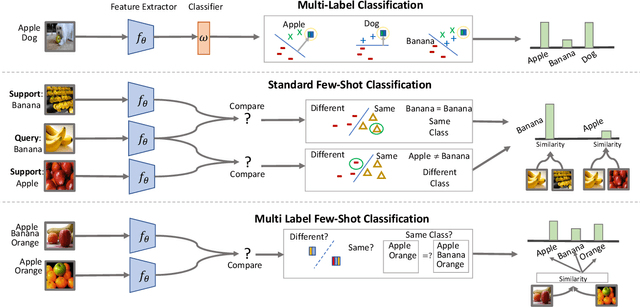
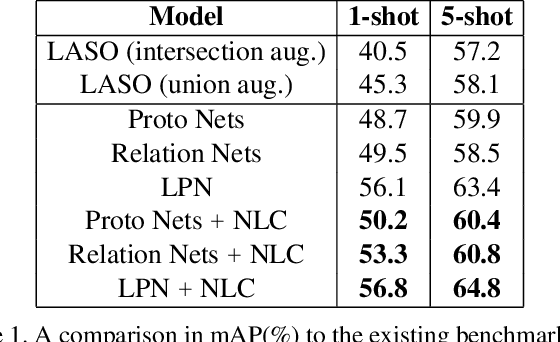
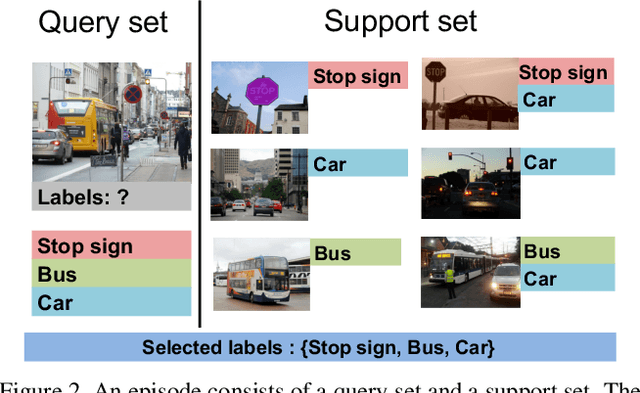
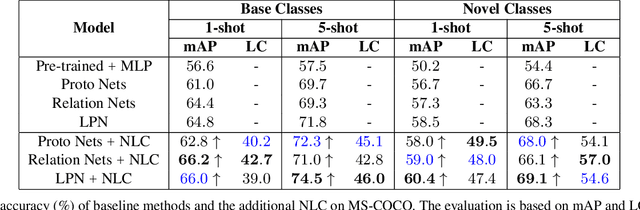
Even with the luxury of having abundant data, multi-label classification is widely known to be a challenging task to address. This work targets the problem of multi-label meta-learning, where a model learns to predict multiple labels within a query (e.g., an image) by just observing a few supporting examples. In doing so, we first propose a benchmark for Few-Shot Learning (FSL) with multiple labels per sample. Next, we discuss and extend several solutions specifically designed to address the conventional and single-label FSL, to work in the multi-label regime. Lastly, we introduce a neural module to estimate the label count of a given sample by exploiting the relational inference. We will show empirically the benefit of the label count module, the label propagation algorithm, and the extensions of conventional FSL methods on three challenging datasets, namely MS-COCO, iMaterialist, and Open MIC. Overall, our thorough experiments suggest that the proposed label-propagation algorithm in conjunction with the neural label count module (NLC) shall be considered as the method of choice.
Recursive Cascaded Networks for Unsupervised Medical Image Registration
Jul 29, 2019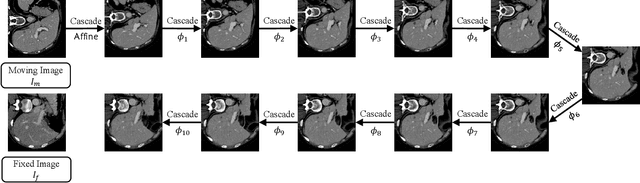

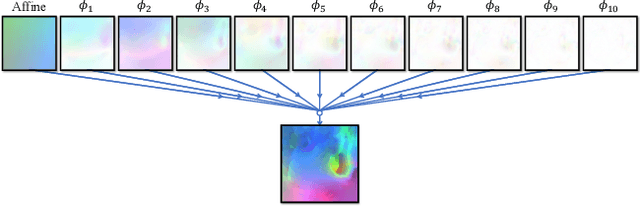
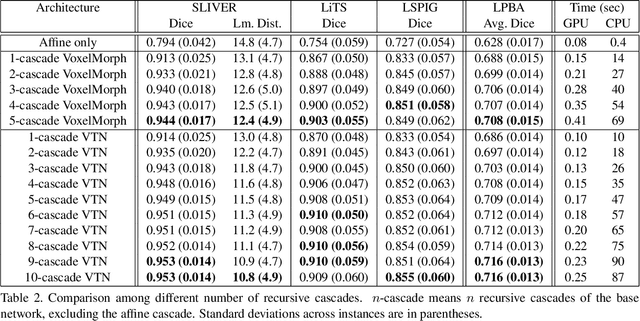
We present recursive cascaded networks, a general architecture that enables learning deep cascades, for deformable image registration. The proposed architecture is simple in design and can be built on any base network. The moving image is warped successively by each cascade and finally aligned to the fixed image; this procedure is recursive in a way that every cascade learns to perform a progressive deformation for the current warped image. The entire system is end-to-end and jointly trained in an unsupervised manner. In addition, enabled by the recursive architecture, one cascade can be iteratively applied for multiple times during testing, which approaches a better fit between each of the image pairs. We evaluate our method on 3D medical images, where deformable registration is most commonly applied. We demonstrate that recursive cascaded networks achieve consistent, significant gains and outperform state-of-the-art methods. The performance reveals an increasing trend as long as more cascades are trained, while the limit is not observed. Our code will be made publicly available.
Defending Against Physically Realizable Attacks on Image Classification
Sep 20, 2019
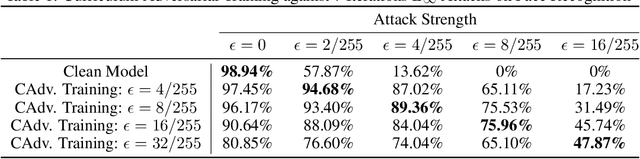
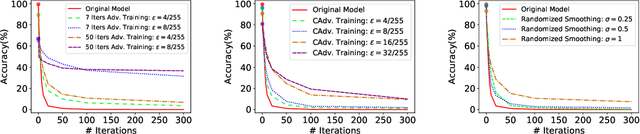
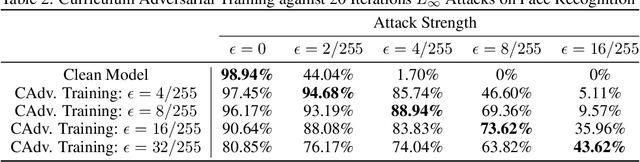
We study the problem of defending deep neural network approaches for image classification from physically realizable attacks. First, we demonstrate that the two most scalable and effective methods for learning robust models, adversarial training with PGD attacks and randomized smoothing, exhibit very limited effectiveness against three of the highest profile physical attacks. Next, we propose a new abstract adversarial model, rectangular occlusion attacks, in which an adversary places a small adversarially crafted rectangle in an image, and develop two approaches for efficiently computing the resulting adversarial examples. Finally, we demonstrate that adversarial training using our new attack yields image classification models that exhibit high robustness against the physically realizable attacks we study, offering the first effective generic defense against such attacks.
Automated risk classification of colon biopsies based on semantic segmentation of histopathology images
Sep 16, 2021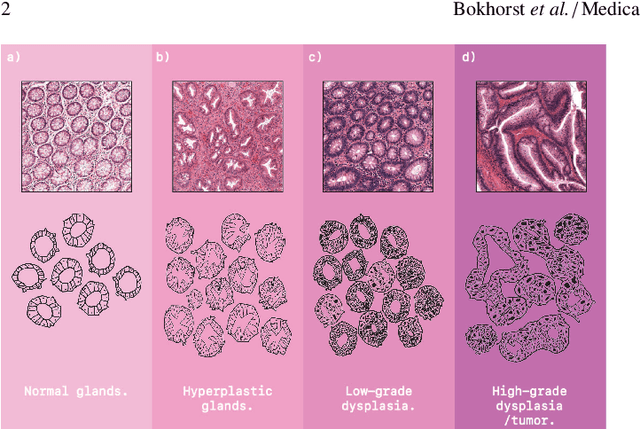
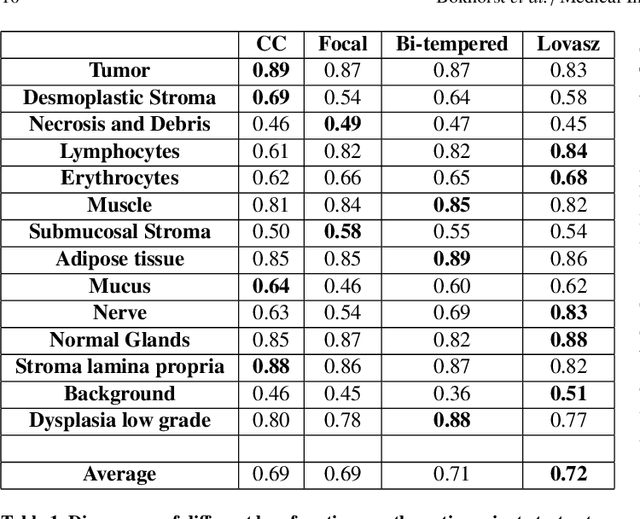
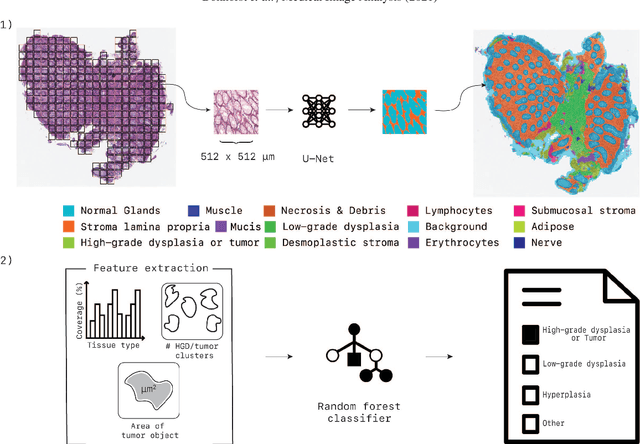
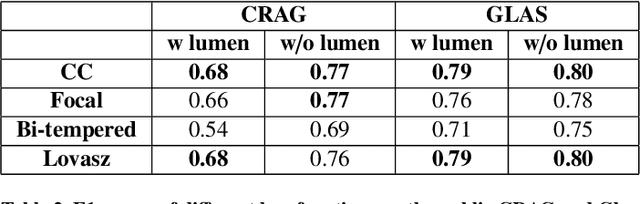
Artificial Intelligence (AI) can potentially support histopathologists in the diagnosis of a broad spectrum of cancer types. In colorectal cancer (CRC), AI can alleviate the laborious task of characterization and reporting on resected biopsies, including polyps, the numbers of which are increasing as a result of CRC population screening programs, ongoing in many countries all around the globe. Here, we present an approach to address two major challenges in automated assessment of CRC histopathology whole-slide images. First, we present an AI-based method to segment multiple tissue compartments in the H\&E-stained whole-slide image, which provides a different, more perceptible picture of tissue morphology and composition. We test and compare a panel of state-of-the-art loss functions available for segmentation models, and provide indications about their use in histopathology image segmentation, based on the analysis of a) a multi-centric cohort of CRC cases from five medical centers in the Netherlands and Germany, and b) two publicly available datasets on segmentation in CRC. Second, we use the best performing AI model as the basis for a computer-aided diagnosis system (CAD) that classifies colon biopsies into four main categories that are relevant pathologically. We report the performance of this system on an independent cohort of more than 1,000 patients. The results show the potential of such an AI-based system to assist pathologists in diagnosis of CRC in the context of population screening. We have made the segmentation model available for research use on https://grand-challenge.org/algorithms/colon-tissue-segmentation/.
Bi-Directional Domain Translation for Zero-Shot Sketch-Based Image Retrieval
Nov 29, 2019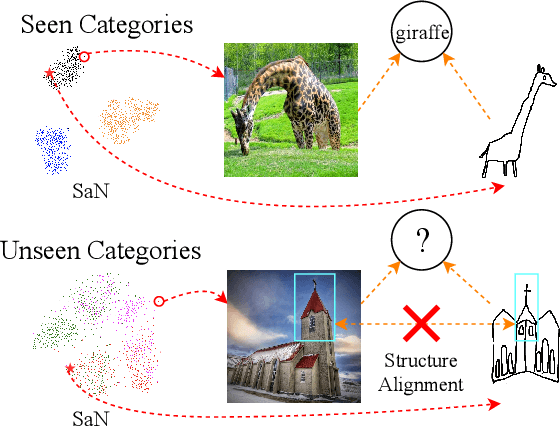
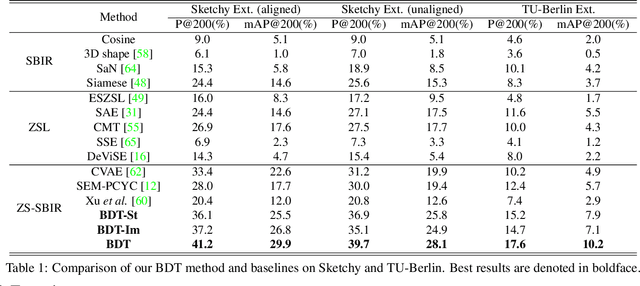
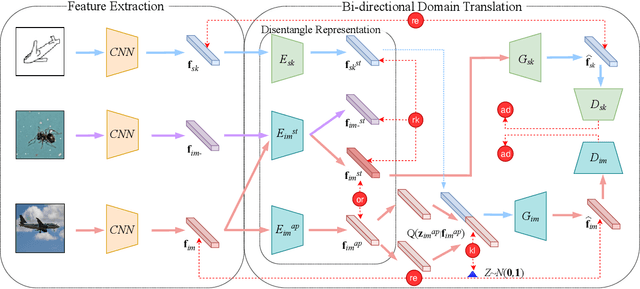
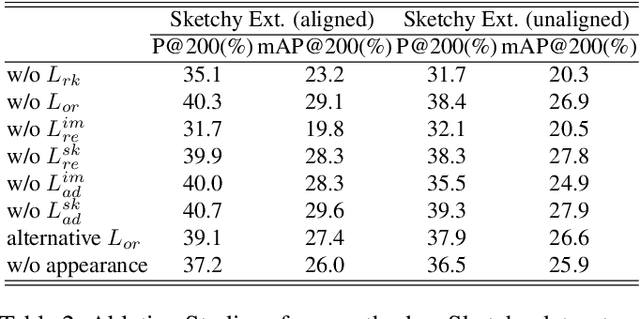
The goal of Sketch-Based Image Retrieval (SBIR) is using free-hand sketches to retrieve images of the same category from a natural image gallery. However, SBIR requires all categories to be seen during training, which cannot be guaranteed in real-world applications. So we investigate more challenging Zero-Shot SBIR (ZS-SBIR), in which test categories do not appear in the training stage. Traditional SBIR methods are prone to be category-based retrieval and cannot generalize well from seen categories to unseen ones. In contrast, we disentangle image features into structure features and appearance features to facilitate structure-based retrieval. To assist feature disentanglement and take full advantage of disentangled information, we propose a Bi-directional Domain Translation (BDT) framework for ZS-SBIR, in which the image domain and sketch domain can be translated to each other through disentangled structure and appearance features. Finally, we perform retrieval in both structure feature space and image feature space. Extensive experiments demonstrate that our proposed approach remarkably outperforms state-of-the-art approaches by about 8% on the Sketchy dataset and over 5% on the TU-Berlin dataset.
Unpaired Cross-lingual Image Caption Generation with Self-Supervised Rewards
Aug 15, 2019
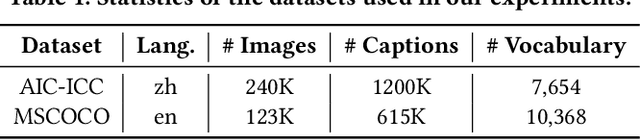
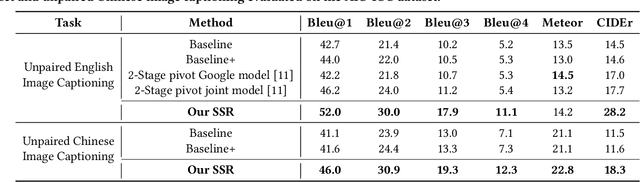
Generating image descriptions in different languages is essential to satisfy users worldwide. However, it is prohibitively expensive to collect large-scale paired image-caption dataset for every target language which is critical for training descent image captioning models. Previous works tackle the unpaired cross-lingual image captioning problem through a pivot language, which is with the help of paired image-caption data in the pivot language and pivot-to-target machine translation models. However, such language-pivoted approach suffers from inaccuracy brought by the pivot-to-target translation, including disfluency and visual irrelevancy errors. In this paper, we propose to generate cross-lingual image captions with self-supervised rewards in the reinforcement learning framework to alleviate these two types of errors. We employ self-supervision from mono-lingual corpus in the target language to provide fluency reward, and propose a multi-level visual semantic matching model to provide both sentence-level and concept-level visual relevancy rewards. We conduct extensive experiments for unpaired cross-lingual image captioning in both English and Chinese respectively on two widely used image caption corpora. The proposed approach achieves significant performance improvement over state-of-the-art methods.
Lifting 2D Human Pose to 3D with Domain Adapted 3D Body Concept
Nov 23, 2021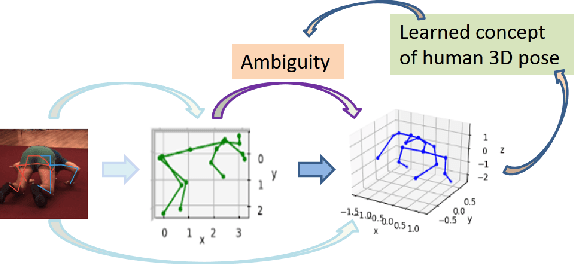

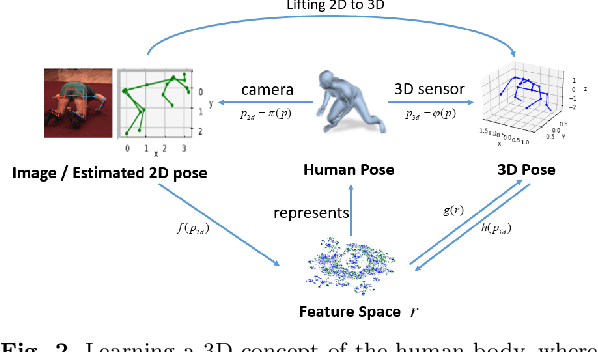
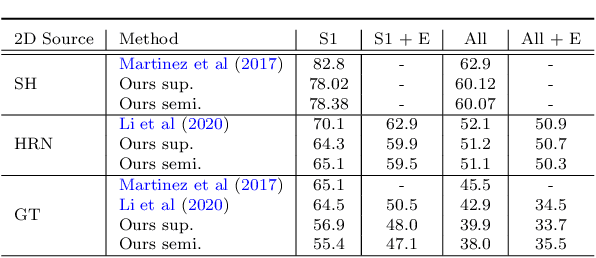
Lifting the 2D human pose to the 3D pose is an important yet challenging task. Existing 3D pose estimation suffers from 1) the inherent ambiguity between the 2D and 3D data, and 2) the lack of well labeled 2D-3D pose pairs in the wild. Human beings are able to imagine the human 3D pose from a 2D image or a set of 2D body key-points with the least ambiguity, which should be attributed to the prior knowledge of the human body that we have acquired in our mind. Inspired by this, we propose a new framework that leverages the labeled 3D human poses to learn a 3D concept of the human body to reduce the ambiguity. To have consensus on the body concept from 2D pose, our key insight is to treat the 2D human pose and the 3D human pose as two different domains. By adapting the two domains, the body knowledge learned from 3D poses is applied to 2D poses and guides the 2D pose encoder to generate informative 3D "imagination" as embedding in pose lifting. Benefiting from the domain adaptation perspective, the proposed framework unifies the supervised and semi-supervised 3D pose estimation in a principled framework. Extensive experiments demonstrate that the proposed approach can achieve state-of-the-art performance on standard benchmarks. More importantly, it is validated that the explicitly learned 3D body concept effectively alleviates the 2D-3D ambiguity in 2D pose lifting, improves the generalization, and enables the network to exploit the abundant unlabeled 2D data.
Increasing a microscope's effective field of view via overlapped imaging and machine learning
Oct 10, 2021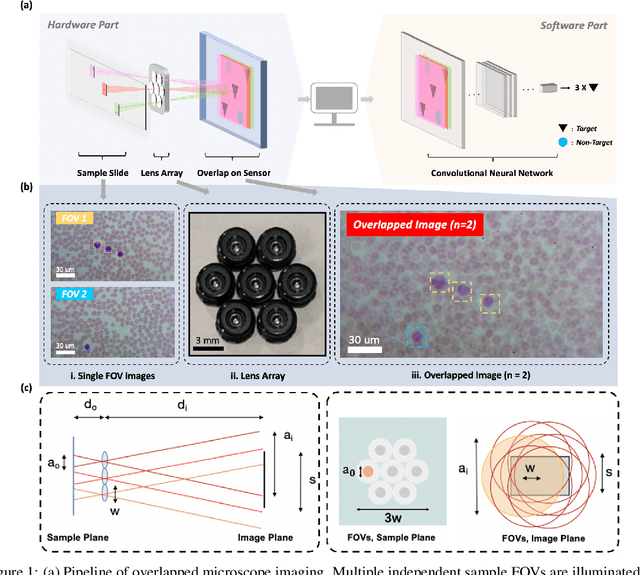
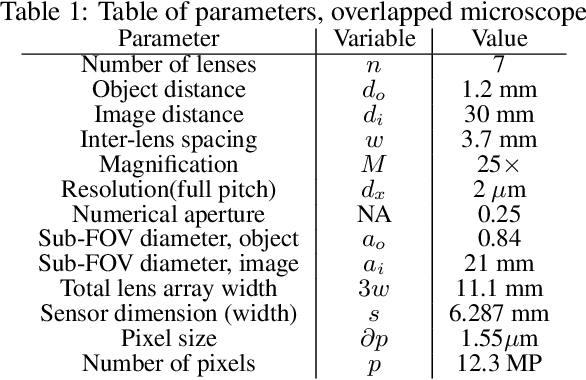
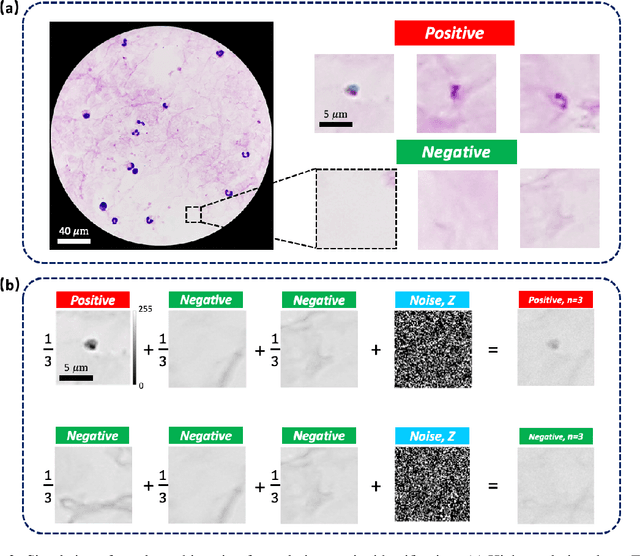
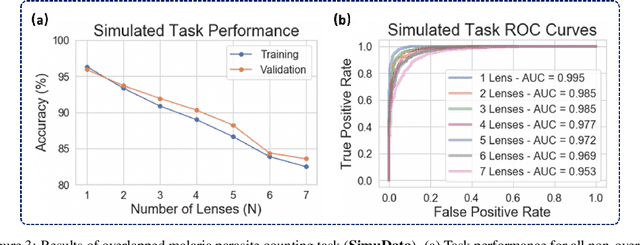
This work demonstrates a multi-lens microscopic imaging system that overlaps multiple independent fields of view on a single sensor for high-efficiency automated specimen analysis. Automatic detection, classification and counting of various morphological features of interest is now a crucial component of both biomedical research and disease diagnosis. While convolutional neural networks (CNNs) have dramatically improved the accuracy of counting cells and sub-cellular features from acquired digital image data, the overall throughput is still typically hindered by the limited space-bandwidth product (SBP) of conventional microscopes. Here, we show both in simulation and experiment that overlapped imaging and co-designed analysis software can achieve accurate detection of diagnostically-relevant features for several applications, including counting of white blood cells and the malaria parasite, leading to multi-fold increase in detection and processing throughput with minimal reduction in accuracy.