 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Gradual Network for Single Image De-raining
Sep 20, 2019

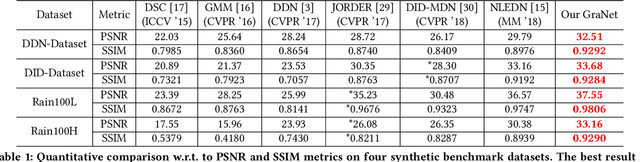
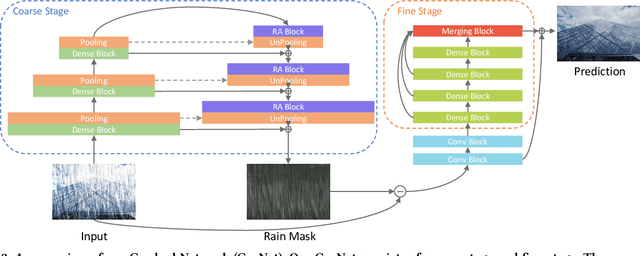
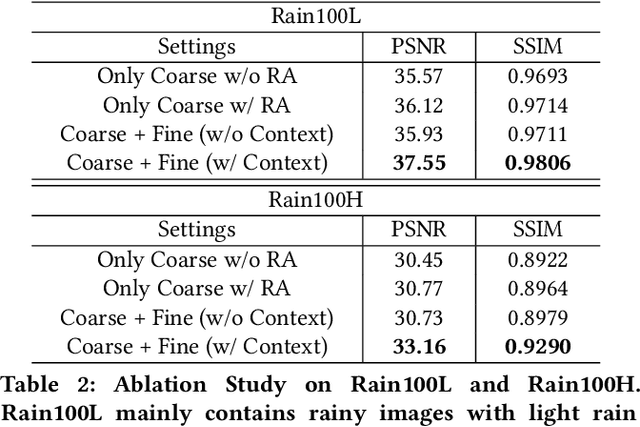
Most advances in single image de-raining meet a key challenge, which is removing rain streaks with different scales and shapes while preserving image details. Existing single image de-raining approaches treat rain-streak removal as a process of pixel-wise regression directly. However, they are lacking in mining the balance between over-de-raining (e.g. removing texture details in rain-free regions) and under-de-raining (e.g. leaving rain streaks). In this paper, we firstly propose a coarse-to-fine network called Gradual Network (GraNet) consisting of coarse stage and fine stage for delving into single image de-raining with different granularities. Specifically, to reveal coarse-grained rain-streak characteristics (e.g. long and thick rain streaks/raindrops), we propose a coarse stage by utilizing local-global spatial dependencies via a local-global subnetwork composed of region-aware blocks. Taking the residual result (the coarse de-rained result) between the rainy image sample (i.e. the input data) and the output of coarse stage (i.e. the learnt rain mask) as input, the fine stage continues to de-rain by removing the fine-grained rain streaks (e.g. light rain streaks and water mist) to get a rain-free and well-reconstructed output image via a unified contextual merging sub-network with dense blocks and a merging block. Solid and comprehensive experiments on synthetic and real data demonstrate that our GraNet can significantly outperform the state-of-the-art methods by removing rain streaks with various densities, scales and shapes while keeping the image details of rain-free regions well-preserved.
DRIT++: Diverse Image-to-Image Translation via Disentangled Representations
May 02, 2019
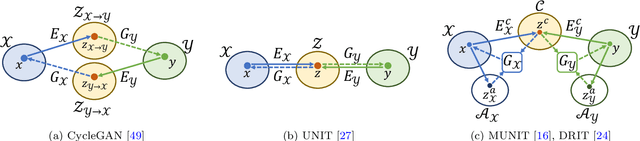
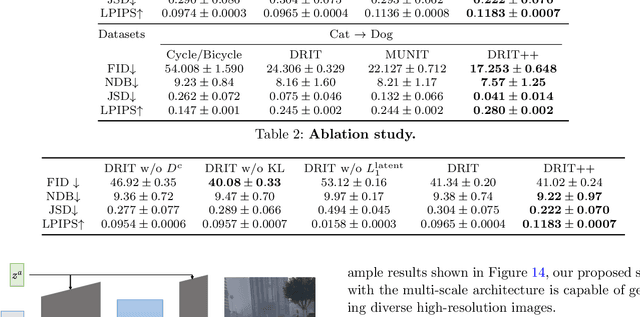
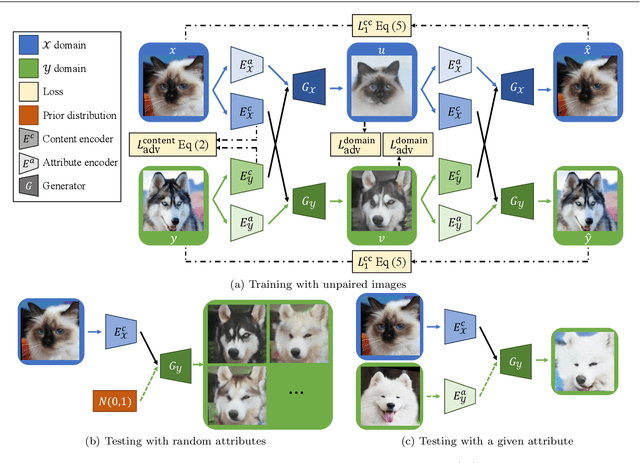
Image-to-image translation aims to learn the mapping between two visual domains. There are two main challenges for this task: 1) lack of aligned training pairs and 2) multiple possible outputs from a single input image. In this work, we present an approach based on disentangled representation for generating diverse outputs without paired training images. To synthesize diverse outputs, we propose to embed images onto two spaces: a domain-invariant content space capturing shared information across domains and a domain-specific attribute space. Our model takes the encoded content features extracted from a given input and attribute vectors sampled from the attribute space to synthesize diverse outputs at test time. To handle unpaired training data, we introduce a cross-cycle consistency loss based on disentangled representations. Qualitative results show that our model can generate diverse and realistic images on a wide range of tasks without paired training data. For quantitative evaluations, we measure realism with user study and Fr\'{e}chet inception distance, and measure diversity with the perceptual distance metric, Jensen-Shannon divergence, and number of statistically-different bins.
In-N-Out: Towards Good Initialization for Inpainting and Outpainting
Jun 26, 2021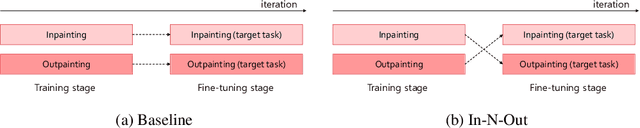
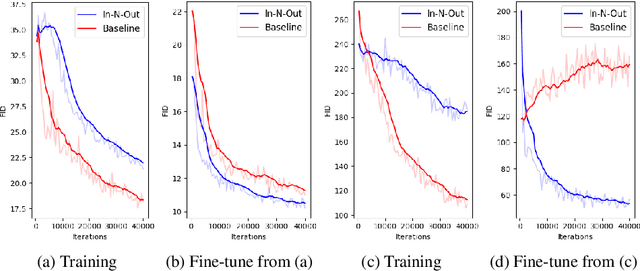

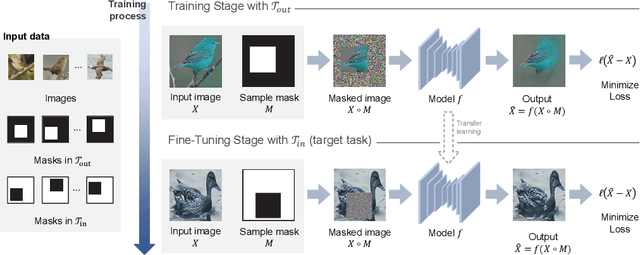
In computer vision, recovering spatial information by filling in masked regions, e.g., inpainting, has been widely investigated for its usability and wide applicability to other various applications: image inpainting, image extrapolation, and environment map estimation. Most of them are studied separately depending on the applications. Our focus, however, is on accommodating the opposite task, e.g., image outpainting, which would benefit the target applications, e.g., image inpainting. Our self-supervision method, In-N-Out, is summarized as a training approach that leverages the knowledge of the opposite task into the target model. We empirically show that In-N-Out -- which explores the complementary information -- effectively takes advantage over the traditional pipelines where only task-specific learning takes place in training. In experiments, we compare our method to the traditional procedure and analyze the effectiveness of our method on different applications: image inpainting, image extrapolation, and environment map estimation. For these tasks, we demonstrate that In-N-Out consistently improves the performance of the recent works with In-N-Out self-supervision to their training procedure. Also, we show that our approach achieves better results than an existing training approach for outpainting.
General Greedy De-bias Learning
Dec 21, 2021
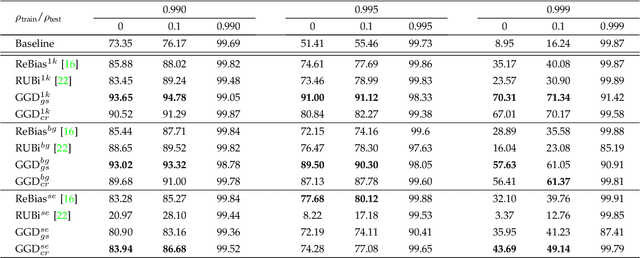
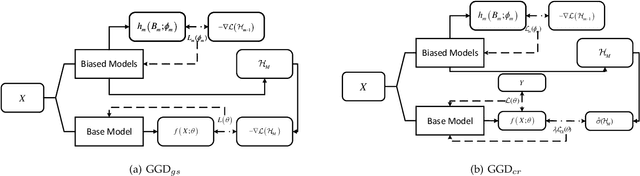
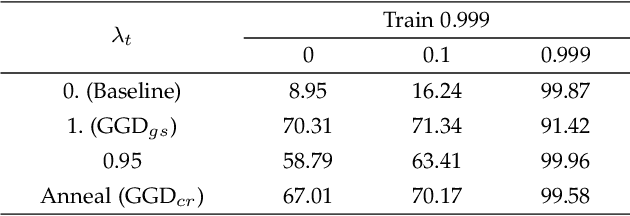
Neural networks often make predictions relying on the spurious correlations from the datasets rather than the intrinsic properties of the task of interest, facing sharp degradation on out-of-distribution (OOD) test data. Existing de-bias learning frameworks try to capture specific dataset bias by bias annotations, they fail to handle complicated OOD scenarios. Others implicitly identify the dataset bias by the special design on the low capability biased model or the loss, but they degrade when the training and testing data are from the same distribution. In this paper, we propose a General Greedy De-bias learning framework (GGD), which greedily trains the biased models and the base model like gradient descent in functional space. It encourages the base model to focus on examples that are hard to solve with biased models, thus remaining robust against spurious correlations in the test stage. GGD largely improves models' OOD generalization ability on various tasks, but sometimes over-estimates the bias level and degrades on the in-distribution test. We further re-analyze the ensemble process of GGD and introduce the Curriculum Regularization into GGD inspired by curriculum learning, which achieves a good trade-off between in-distribution and out-of-distribution performance. Extensive experiments on image classification, adversarial question answering, and visual question answering demonstrate the effectiveness of our method. GGD can learn a more robust base model under the settings of both task-specific biased models with prior knowledge and self-ensemble biased model without prior knowledge.
CAggNet: Crossing Aggregation Network for Medical Image Segmentation
Apr 16, 2020
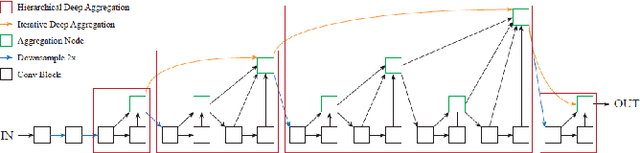
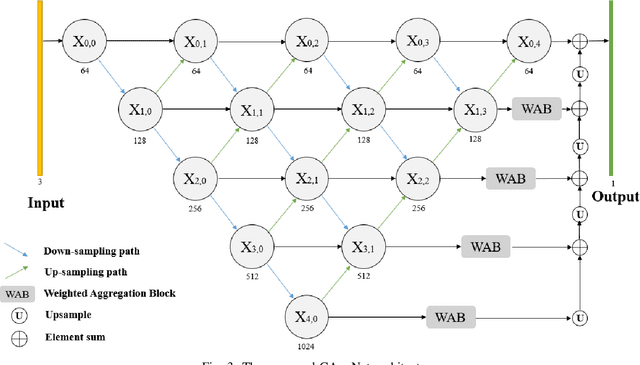
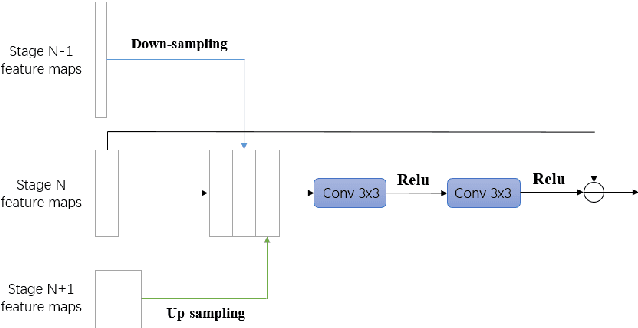
In this paper, we present Crossing Aggregation Network (CAggNet), a novel densely connected semantic segmentation method for medical image analysis. The crossing aggregation network absorbs the idea of deep layer aggregation and makes significant innovations in layer connection and semantic information fusion. In this architecture, the traditional skip-connection structure of general U-Net is replaced by aggregations of multilevel down-sampling and up-sampling layers. This enables the network to fuse information interactively flows at different levels of layers in semantic segmentation. It also introduces weighted aggregation module to aggregate multi-scale output information. We have evaluated and compared our CAggNet with several advanced U-Net based methods in two public medical image datasets, including the 2018 Data Science Bowl nuclei detection dataset and the 2015 MICCAI gland segmentation competition dataset. Experimental results indicate that CAggNet improves medical object recognition and achieves a more accurate and efficient segmentation compared to existing improved U-Net and UNet++ structure.
Neural Radiance Fields Approach to Deep Multi-View Photometric Stereo
Oct 11, 2021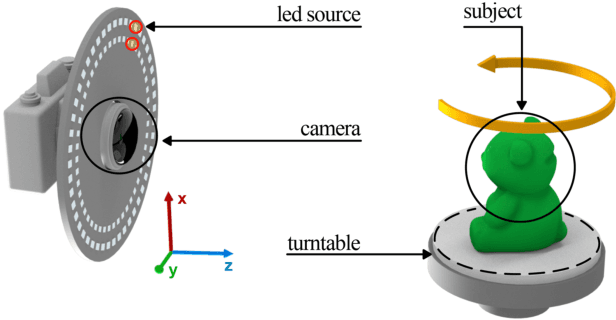

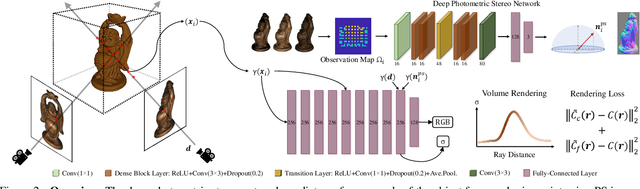
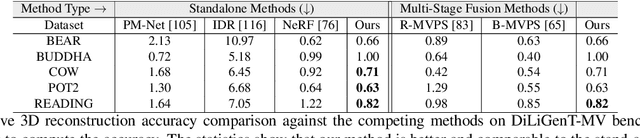
We present a modern solution to the multi-view photometric stereo problem (MVPS). Our work suitably exploits the image formation model in a MVPS experimental setup to recover the dense 3D reconstruction of an object from images. We procure the surface orientation using a photometric stereo (PS) image formation model and blend it with a multi-view neural radiance field representation to recover the object's surface geometry. Contrary to the previous multi-staged framework to MVPS, where the position, iso-depth contours, or orientation measurements are estimated independently and then fused later, our method is simple to implement and realize. Our method performs neural rendering of multi-view images while utilizing surface normals estimated by a deep photometric stereo network. We render the MVPS images by considering the object's surface normals for each 3D sample point along the viewing direction rather than explicitly using the density gradient in the volume space via 3D occupancy information. We optimize the proposed neural radiance field representation for the MVPS setup efficiently using a fully connected deep network to recover the 3D geometry of an object. Extensive evaluation on the DiLiGenT-MV benchmark dataset shows that our method performs better than the approaches that perform only PS or only multi-view stereo (MVS) and provides comparable results against the state-of-the-art multi-stage fusion methods.
Nonlinear Transform Source-Channel Coding for Semantic Communications
Dec 21, 2021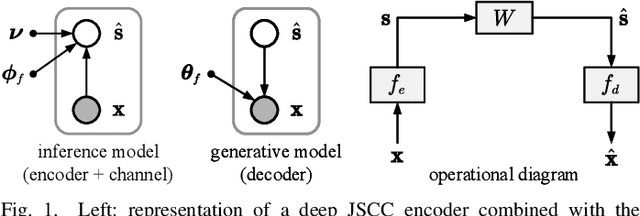
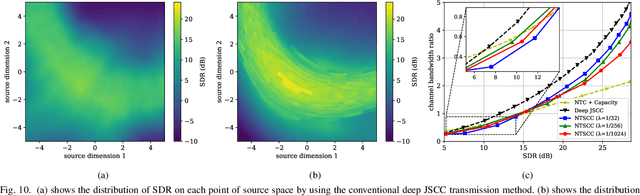
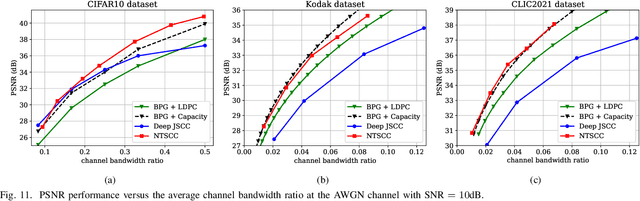
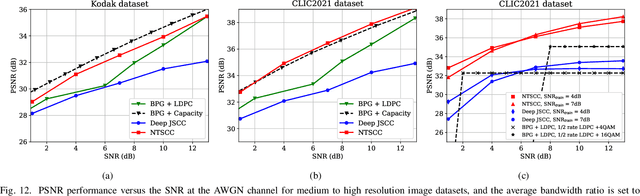
In this paper, we propose a new class of high-efficient deep joint source-channel coding methods that can closely adapt to the source distribution under the nonlinear transform, it can be collected under the name nonlinear transform source-channel coding (NTSCC). In the considered model, the transmitter first learns a nonlinear analysis transform to map the source data into latent space, then transmits the latent representation to the receiver via deep joint source-channel coding. Our model incorporates the nonlinear transform as a strong prior to effectively extract the source semantic features and provide side information for source-channel coding. Unlike existing conventional deep joint source-channel coding methods, the proposed NTSCC essentially learns both the source latent representation and an entropy model as the prior on the latent representation. Accordingly, novel adaptive rate transmission and hyperprior-aided codec refinement mechanisms are developed to upgrade deep joint source-channel coding. The whole system design is formulated as an optimization problem whose goal is to minimize the end-to-end transmission rate-distortion performance under established perceptual quality metrics. Across simple example sources and test image sources, we find that the proposed NTSCC transmission method generally outperforms both the analog transmission using the standard deep joint source-channel coding and the classical separation-based digital transmission. Notably, the proposed NTSCC method can potentially support future semantic communications due to its vigorous content-aware ability.
Entanglement and Tensor Networks for Supervised Image Classification
Jul 12, 2020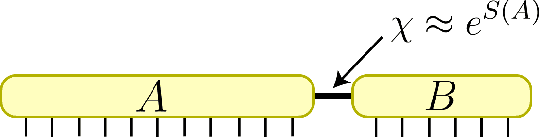
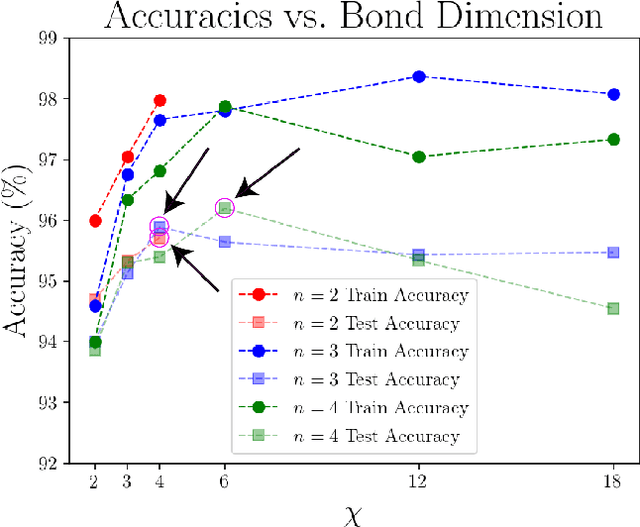
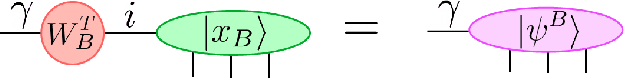
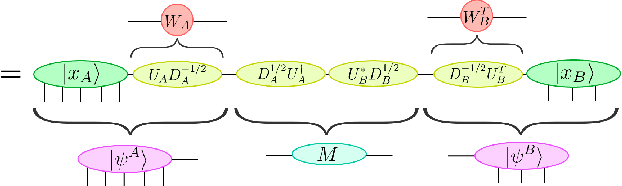
Tensor networks, originally designed to address computational problems in quantum many-body physics, have recently been applied to machine learning tasks. However, compared to quantum physics, where the reasons for the success of tensor network approaches over the last 30 years is well understood, very little is yet known about why these techniques work for machine learning. The goal of this paper is to investigate entanglement properties of tensor network models in a current machine learning application, in order to uncover general principles that may guide future developments. We revisit the use of tensor networks for supervised image classification using the MNIST data set of handwritten digits, as pioneered by Stoudenmire and Schwab [Adv. in Neur. Inform. Proc. Sys. 29, 4799 (2016)]. Firstly we hypothesize about which state the tensor network might be learning during training. For that purpose, we propose a plausible candidate state $|\Sigma_{\ell}\rangle$ (built as a superposition of product states corresponding to images in the training set) and investigate its entanglement properties. We conclude that $|\Sigma_{\ell}\rangle$ is so robustly entangled that it cannot be approximated by the tensor network used in that work, which must therefore be representing a very different state. Secondly, we use tensor networks with a block product structure, in which entanglement is restricted within small blocks of $n \times n$ pixels/qubits. We find that these states are extremely expressive (e.g. training accuracy of $99.97 \%$ already for $n=2$), suggesting that long-range entanglement may not be essential for image classification. However, in our current implementation, optimization leads to over-fitting, resulting in test accuracies that are not competitive with other current approaches.
Cartesian dictionary-based native T1 and T2 mapping of the myocardium
Oct 05, 2021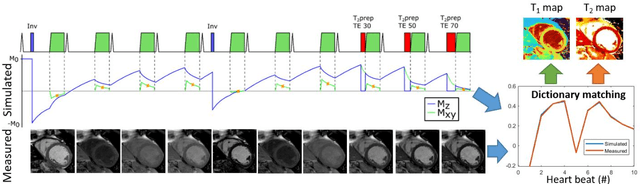
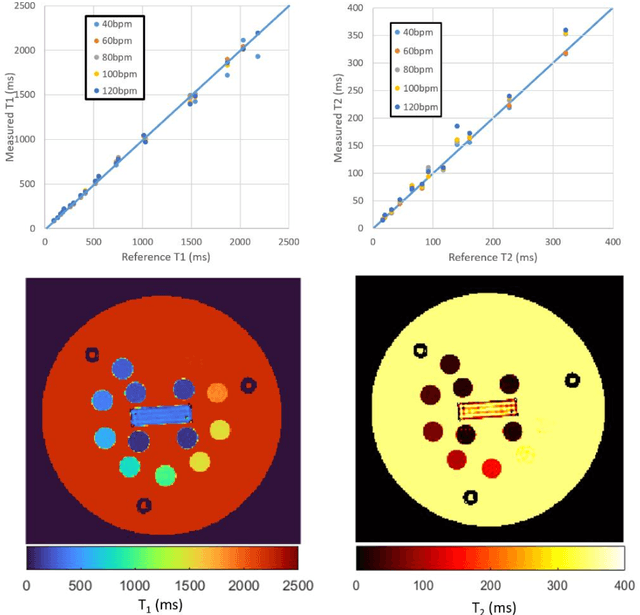
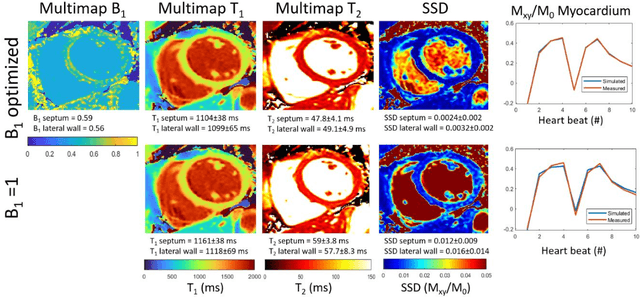
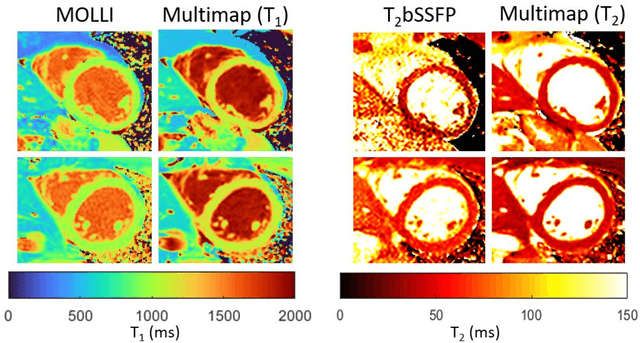
Purpose: To implement and evaluate a new dictionary-based technique for native myocardial T1 and T2 mapping using Cartesian sampling. Methods: The proposed technique (Multimapping) consisted of single-shot Cartesian image acquisitions in 10 consecutive cardiac cycles, with inversion pulses in cycle 1 and 5, and T2 preparation (TE: 30ms, 50ms and 70ms) in cycles 8-10. Multimapping was simulated for different T1 and T2, where entries corresponding to the k-space centers were matched to acquired data. Experiments were performed in a phantom, 12 healthy subjects and three patients with cardiovascular disease. Results: Multimapping phantom measurements showed good agreement with reference values for both T1 and T2, with no discernable heart-rate dependency for T1 and T2 within the range of myocardium. In vivo mean T1 in healthy subjects was significantly higher using Multimapping (T1=1112+/-15ms) compared to the reference (T1=992+/-26ms) (p<0.01). Mean Multimapping T2 (47.3+/-1.4ms) and T2 spatial variability (6.0+/-1.1ms) was significantly lower compared to the reference (T2=54.9+/-2.4ms, p<0.001; spatial variability=8.6+/-2.2ms, p<0.01). Increased T1 and T2 was detected in all patients using Multimapping. Conclusions: Multimapping allows myocardial T1 and T2 mapping simultaneously, demonstrating promising in vivo image quality and parameter quantification results.
Distributional Shifts in Automated Diabetic Retinopathy Screening
Jul 25, 2021
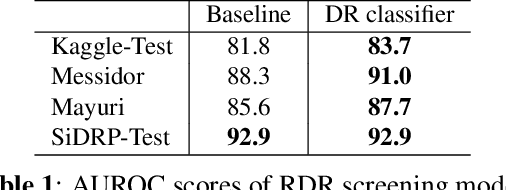

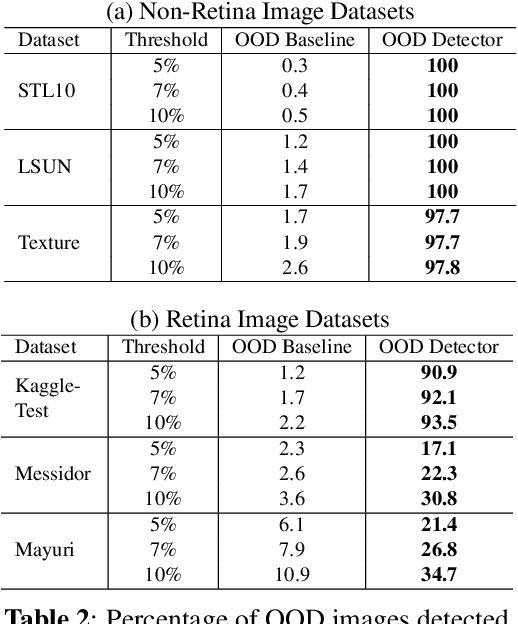
Deep learning-based models are developed to automatically detect if a retina image is `referable' in diabetic retinopathy (DR) screening. However, their classification accuracy degrades as the input images distributionally shift from their training distribution. Further, even if the input is not a retina image, a standard DR classifier produces a high confident prediction that the image is `referable'. Our paper presents a Dirichlet Prior Network-based framework to address this issue. It utilizes an out-of-distribution (OOD) detector model and a DR classification model to improve generalizability by identifying OOD images. Experiments on real-world datasets indicate that the proposed framework can eliminate the unknown non-retina images and identify the distributionally shifted retina images for human intervention.