 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Evolving Architectures with Gradient Misalignment toward Low Adversarial Transferability
Sep 13, 2021
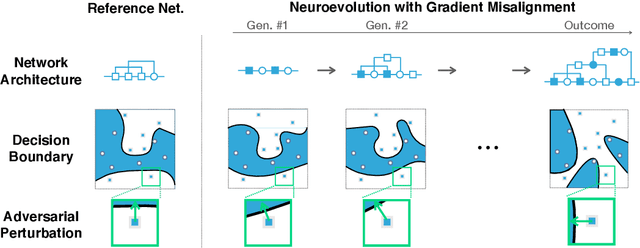

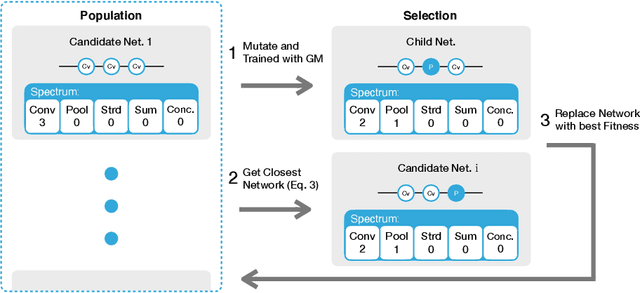
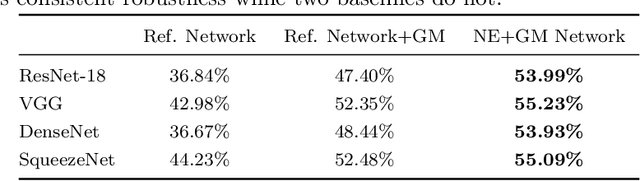
Deep neural network image classifiers are known to be susceptible not only to adversarial examples created for them but even those created for others. This phenomenon poses a potential security risk in various black-box systems relying on image classifiers. The reason behind such transferability of adversarial examples is not yet fully understood and many studies have proposed training methods to obtain classifiers with low transferability. In this study, we address this problem from a novel perspective through investigating the contribution of the network architecture to transferability. Specifically, we propose an architecture searching framework that employs neuroevolution to evolve network architectures and the gradient misalignment loss to encourage networks to converge into dissimilar functions after training. Our experiments show that the proposed framework successfully discovers architectures that reduce transferability from four standard networks including ResNet and VGG, while maintaining a good accuracy on unperturbed images. In addition, the evolved networks trained with gradient misalignment exhibit significantly lower transferability compared to standard networks trained with gradient misalignment, which indicates that the network architecture plays an important role in reducing transferability. This study demonstrates that designing or exploring proper network architectures is a promising approach to tackle the transferability issue and train adversarially robust image classifiers.
Gaussian-Hermite Moment Invariants of General Vector Functions to Rotation-Affine Transform
Jan 03, 2022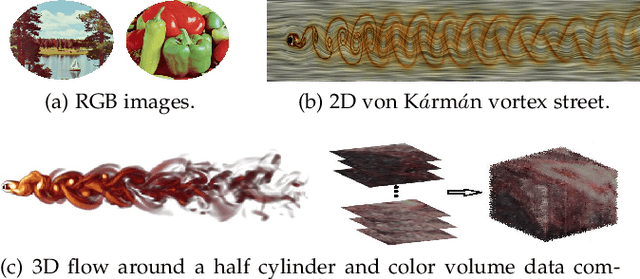



With the development of data acquisition technology, multi-channel data is collected and widely used in many fields. Most of them can be expressed as various types of vector functions. Feature extraction of vector functions for identifying certain patterns of interest is a critical but challenging task. In this paper, we focus on constructing moment invariants of general vector functions. Specifically, we define rotation-affine transform to describe real deformations of general vector functions, and then design a structural frame to systematically generate Gaussian-Hermite moment invariants to this transform model. This is the first time that a uniform frame has been proposed in the literature to construct orthogonal moment invariants of general vector functions. Given a certain type of multi-channel data, we demonstrate how to utilize the new method to derive all possible invariants and to eliminate various dependences among them. For RGB images, 2D and 3D flow fields, we obtain the complete and independent sets of the invariants with low orders and low degrees. Based on synthetic and popular datasets of vector-valued data, the experiments are carried out to evaluate the stability and discriminability of these invariants, and also their robustness to noise. The results clearly show that the moment invariants proposed in our paper have better performance than other previously used moment invariants of vector functions in RGB image classification, vortex detection in 2D vector fields and template matching for 3D flow fields.
Spectral Variability Augmented Sparse Unmixing of Hyperspectral Images
Oct 21, 2021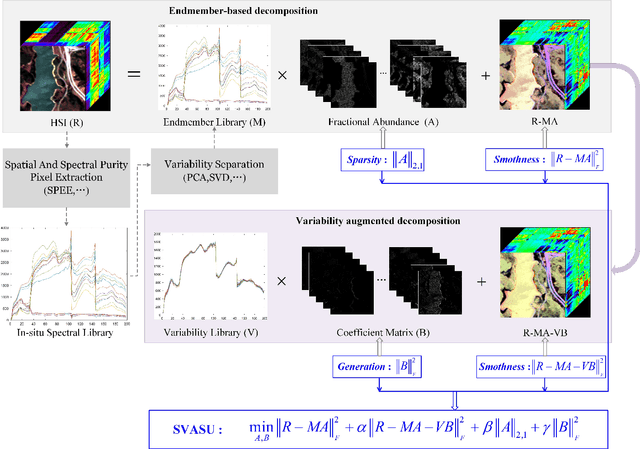
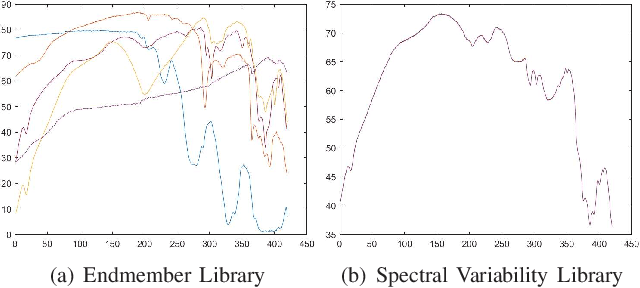
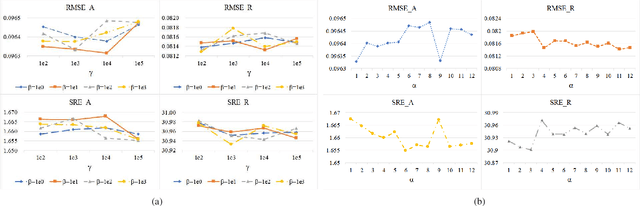
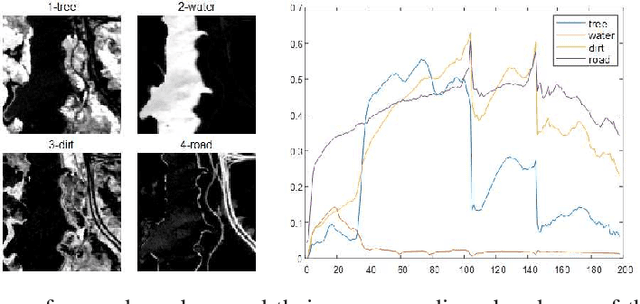
Spectral unmixing (SU) expresses the mixed pixels existed in hyperspectral images as the product of endmember and abundance, which has been widely used in hyperspectral imagery analysis. However, the influence of light, acquisition conditions and the inherent properties of materials, results in that the identified endmembers can vary spectrally within a given image (construed as spectral variability). To address this issue, recent methods usually use a priori obtained spectral library to represent multiple characteristic spectra of the same object, but few of them extracted the spectral variability explicitly. In this paper, a spectral variability augmented sparse unmixing model (SVASU) is proposed, in which the spectral variability is extracted for the first time. The variable spectra are divided into two parts of intrinsic spectrum and spectral variability for spectral reconstruction, and modeled synchronously in the SU model adding the regular terms restricting the sparsity of abundance and the generalization of the variability coefficient. It is noted that the spectral variability library and the intrinsic spectral library are all constructed from the In-situ observed image. Experimental results over both synthetic and real-world data sets demonstrate that the augmented decomposition by spectral variability significantly improves the unmixing performance than the decomposition only by spectral library, as well as compared to state-of-the-art algorithms.
Cross-Modality Attentive Feature Fusion for Object Detection in Multispectral Remote Sensing Imagery
Dec 06, 2021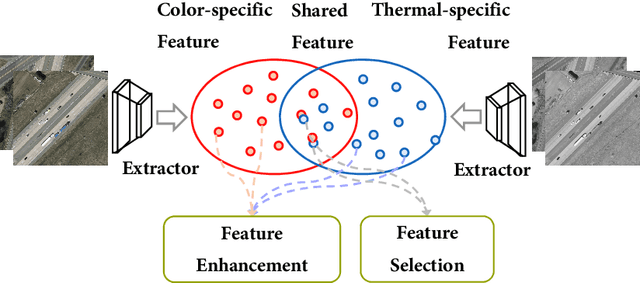
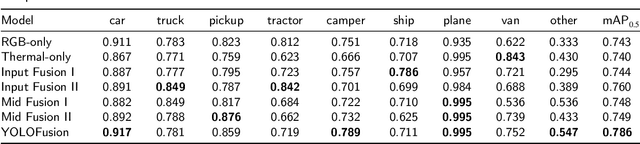
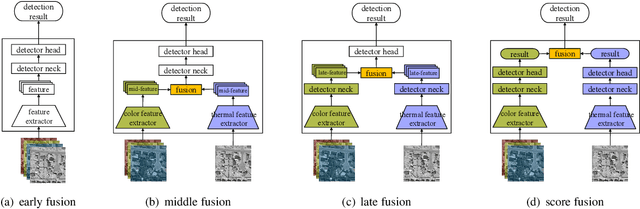
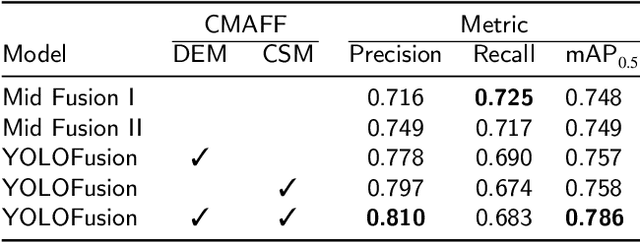
Cross-modality fusing complementary information of multispectral remote sensing image pairs can improve the perception ability of detection algorithms, making them more robust and reliable for a wider range of applications, such as nighttime detection. Compared with prior methods, we think different features should be processed specifically, the modality-specific features should be retained and enhanced, while the modality-shared features should be cherry-picked from the RGB and thermal IR modalities. Following this idea, a novel and lightweight multispectral feature fusion approach with joint common-modality and differential-modality attentions are proposed, named Cross-Modality Attentive Feature Fusion (CMAFF). Given the intermediate feature maps of RGB and IR images, our module parallel infers attention maps from two separate modalities, common- and differential-modality, then the attention maps are multiplied to the input feature map respectively for adaptive feature enhancement or selection. Extensive experiments demonstrate that our proposed approach can achieve the state-of-the-art performance at a low computation cost.
FaceScape: 3D Facial Dataset and Benchmark for Single-View 3D Face Reconstruction
Nov 01, 2021
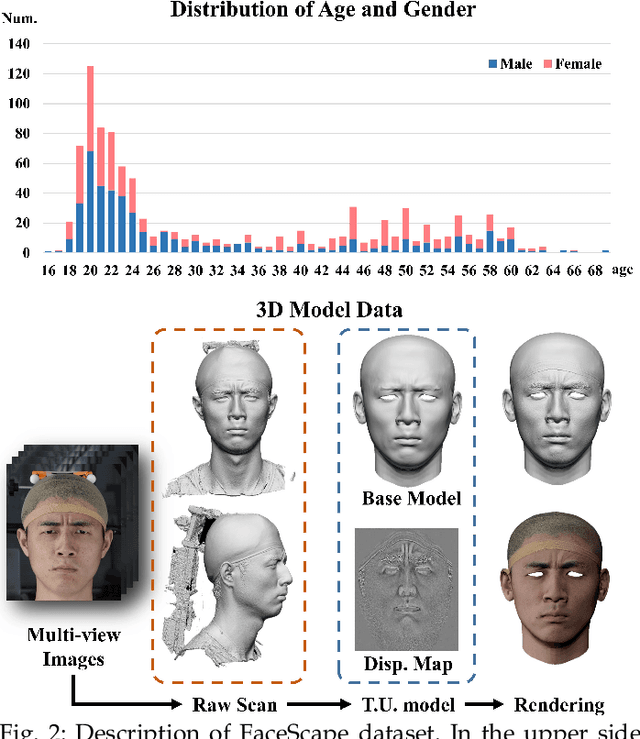
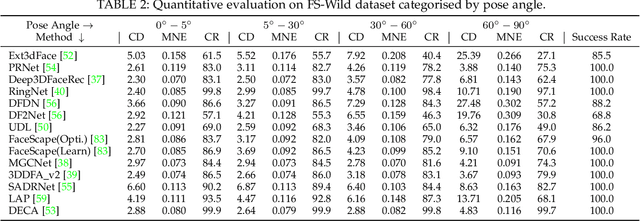
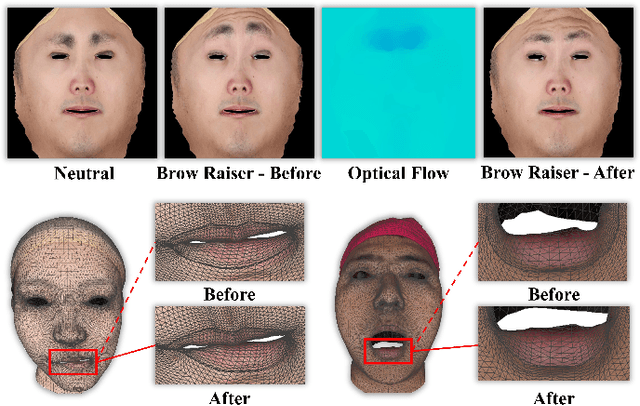
In this paper, we present a large-scale detailed 3D face dataset, FaceScape, and the corresponding benchmark to evaluate single-view facial 3D reconstruction. By training on FaceScape data, a novel algorithm is proposed to predict elaborate riggable 3D face models from a single image input. FaceScape dataset provides 18,760 textured 3D faces, captured from 938 subjects and each with 20 specific expressions. The 3D models contain the pore-level facial geometry that is also processed to be topologically uniformed. These fine 3D facial models can be represented as a 3D morphable model for rough shapes and displacement maps for detailed geometry. Taking advantage of the large-scale and high-accuracy dataset, a novel algorithm is further proposed to learn the expression-specific dynamic details using a deep neural network. The learned relationship serves as the foundation of our 3D face prediction system from a single image input. Different than the previous methods, our predicted 3D models are riggable with highly detailed geometry under different expressions. We also use FaceScape data to generate the in-the-wild and in-the-lab benchmark to evaluate recent methods of single-view face reconstruction. The accuracy is reported and analyzed on the dimensions of camera pose and focal length, which provides a faithful and comprehensive evaluation and reveals new challenges. The unprecedented dataset, benchmark, and code have been released to the public for research purpose.
Amplitude-Phase Recombination: Rethinking Robustness of Convolutional Neural Networks in Frequency Domain
Aug 19, 2021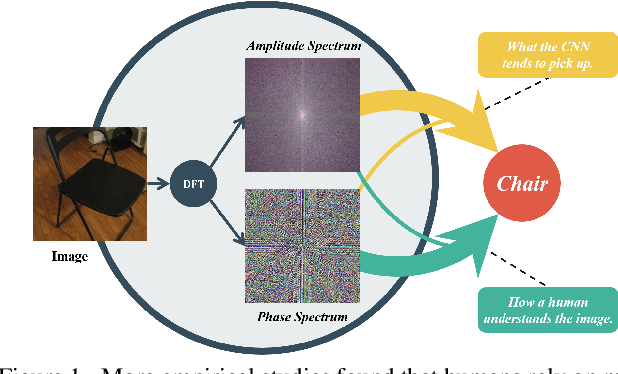
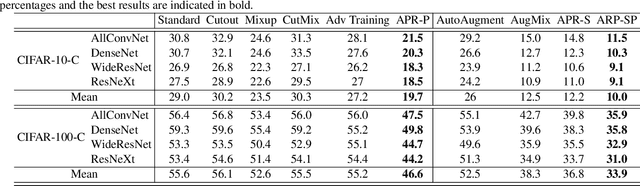

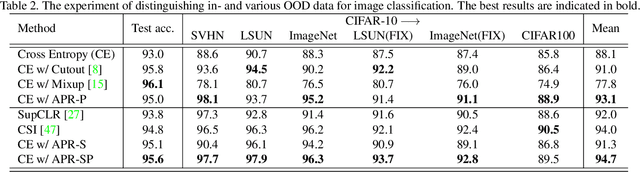
Recently, the generalization behavior of Convolutional Neural Networks (CNN) is gradually transparent through explanation techniques with the frequency components decomposition. However, the importance of the phase spectrum of the image for a robust vision system is still ignored. In this paper, we notice that the CNN tends to converge at the local optimum which is closely related to the high-frequency components of the training images, while the amplitude spectrum is easily disturbed such as noises or common corruptions. In contrast, more empirical studies found that humans rely on more phase components to achieve robust recognition. This observation leads to more explanations of the CNN's generalization behaviors in both robustness to common perturbations and out-of-distribution detection, and motivates a new perspective on data augmentation designed by re-combing the phase spectrum of the current image and the amplitude spectrum of the distracter image. That is, the generated samples force the CNN to pay more attention to the structured information from phase components and keep robust to the variation of the amplitude. Experiments on several image datasets indicate that the proposed method achieves state-of-the-art performances on multiple generalizations and calibration tasks, including adaptability for common corruptions and surface variations, out-of-distribution detection, and adversarial attack.
Unsupervised Depth Completion with Calibrated Backprojection Layers
Aug 24, 2021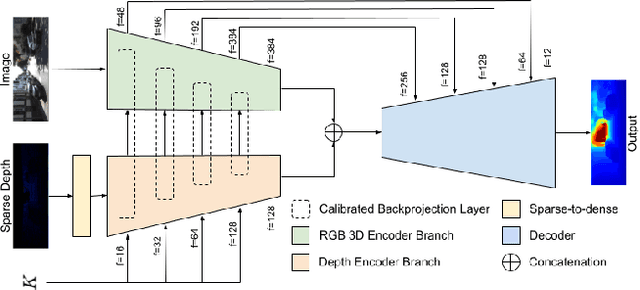

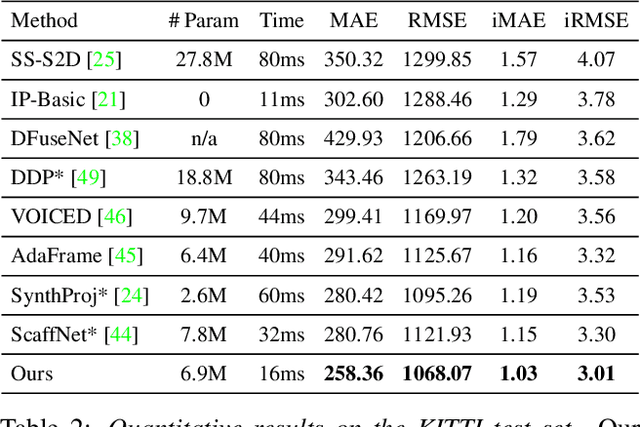
We propose a deep neural network architecture to infer dense depth from an image and a sparse point cloud. It is trained using a video stream and corresponding synchronized sparse point cloud, as obtained from a LIDAR or other range sensor, along with the intrinsic calibration parameters of the camera. At inference time, the calibration of the camera, which can be different than the one used for training, is fed as an input to the network along with the sparse point cloud and a single image. A Calibrated Backprojection Layer backprojects each pixel in the image to three-dimensional space using the calibration matrix and a depth feature descriptor. The resulting 3D positional encoding is concatenated with the image descriptor and the previous layer output to yield the input to the next layer of the encoder. A decoder, exploiting skip-connections, produces a dense depth map. The resulting Calibrated Backprojection Network, or KBNet, is trained without supervision by minimizing the photometric reprojection error. KBNet imputes missing depth value based on the training set, rather than on generic regularization. We test KBNet on public depth completion benchmarks, where it outperforms the state of the art by 30% indoor and 8% outdoor when the same camera is used for training and testing. When the test camera is different, the improvement reaches 62%. Code available at: https://github.com/alexklwong/calibrated-backprojection-network.
Curriculum Meta-Learning for Few-shot Classification
Dec 06, 2021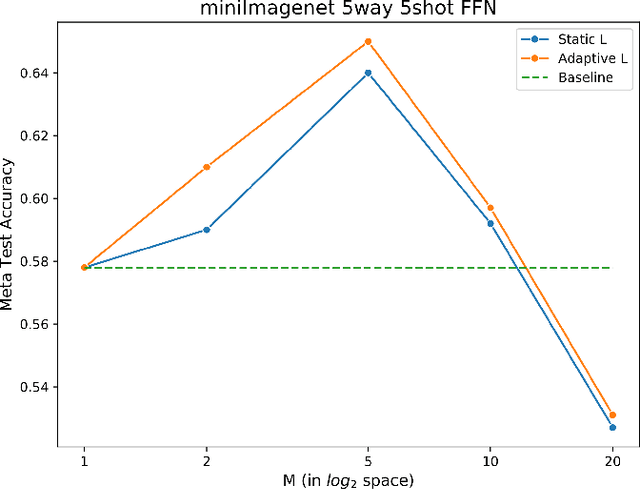
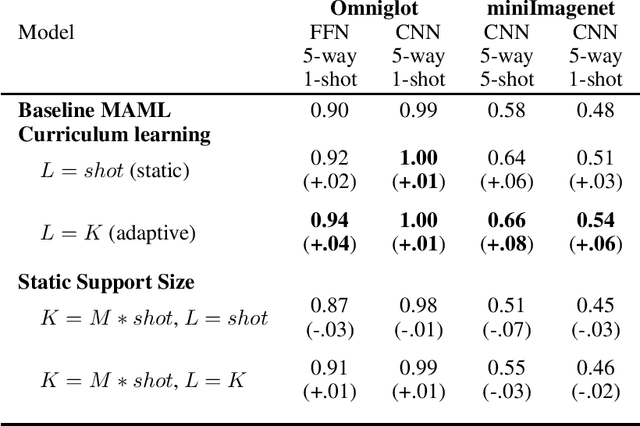
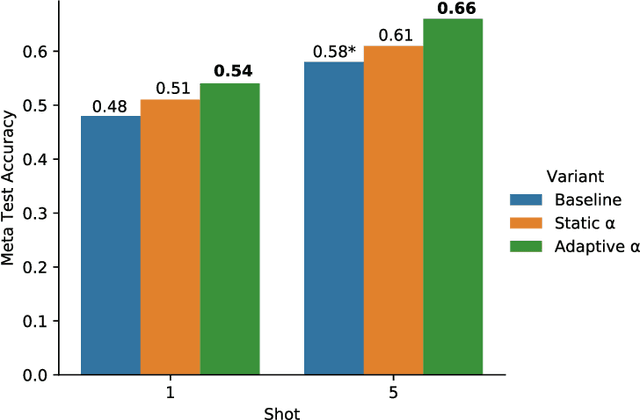
We propose an adaptation of the curriculum training framework, applicable to state-of-the-art meta learning techniques for few-shot classification. Curriculum-based training popularly attempts to mimic human learning by progressively increasing the training complexity to enable incremental concept learning. As the meta-learner's goal is learning how to learn from as few samples as possible, the exact number of those samples (i.e. the size of the support set) arises as a natural proxy of a given task's difficulty. We define a simple yet novel curriculum schedule that begins with a larger support size and progressively reduces it throughout training to eventually match the desired shot-size of the test setup. This proposed method boosts the learning efficiency as well as the generalization capability. Our experiments with the MAML algorithm on two few-shot image classification tasks show significant gains with the curriculum training framework. Ablation studies corroborate the independence of our proposed method from the model architecture as well as the meta-learning hyperparameters
Document AI: Benchmarks, Models and Applications
Nov 16, 2021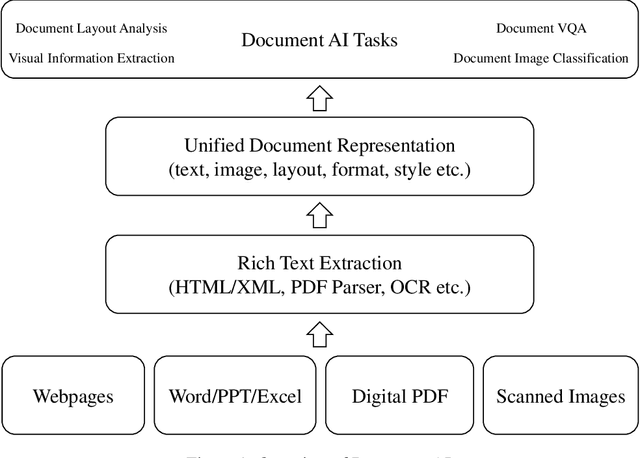
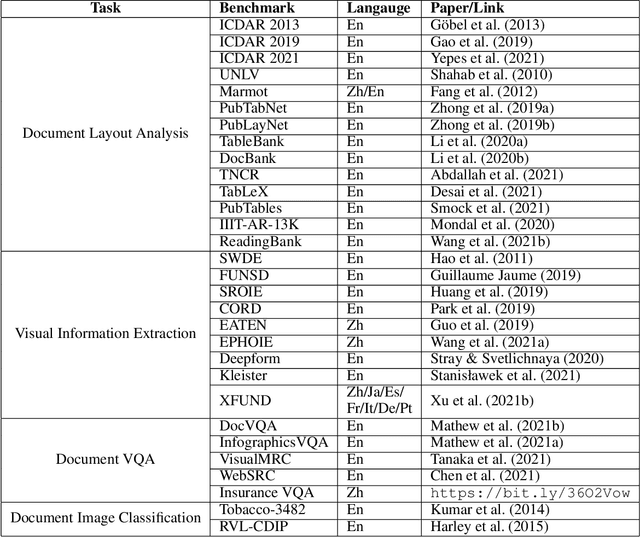
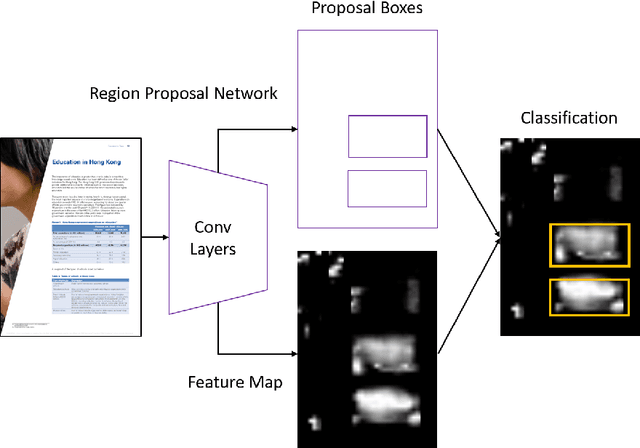
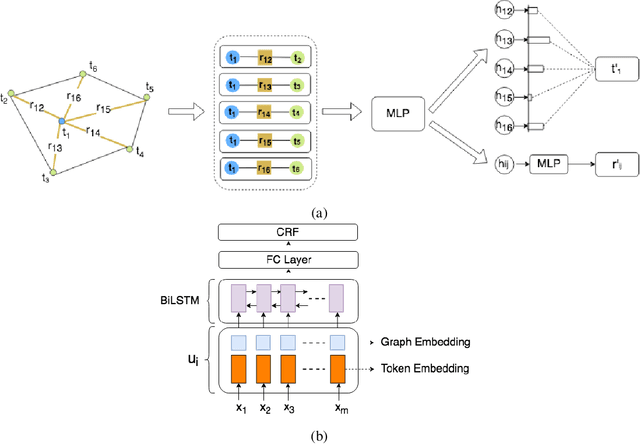
Document AI, or Document Intelligence, is a relatively new research topic that refers to the techniques for automatically reading, understanding, and analyzing business documents. It is an important research direction for natural language processing and computer vision. In recent years, the popularity of deep learning technology has greatly advanced the development of Document AI, such as document layout analysis, visual information extraction, document visual question answering, document image classification, etc. This paper briefly reviews some of the representative models, tasks, and benchmark datasets. Furthermore, we also introduce early-stage heuristic rule-based document analysis, statistical machine learning algorithms, and deep learning approaches especially pre-training methods. Finally, we look into future directions for Document AI research.
Fine-Grained Few Shot Learning with Foreground Object Transformation
Sep 13, 2021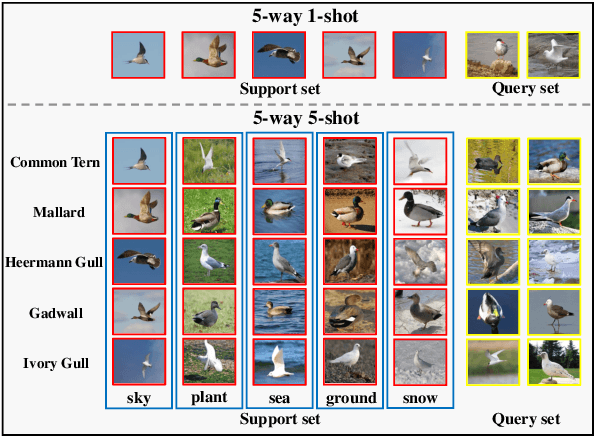
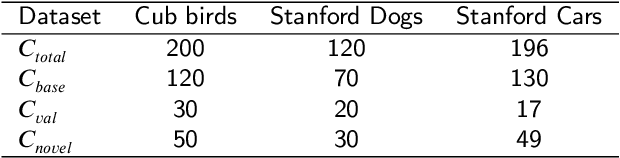
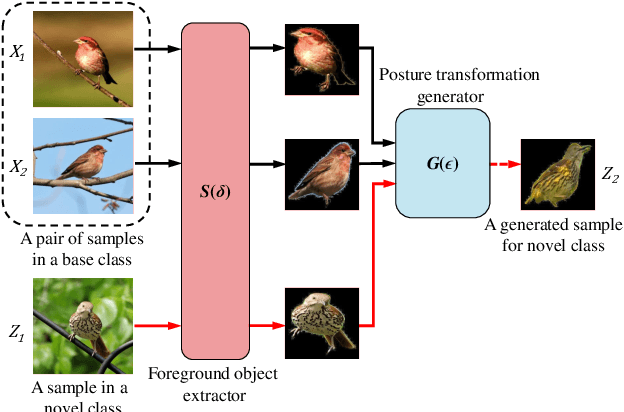
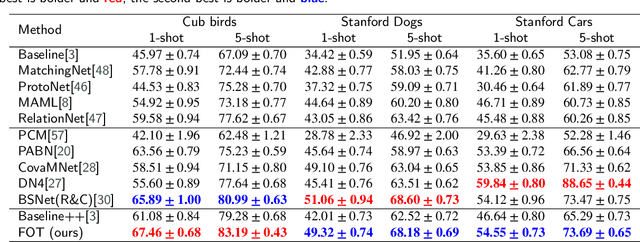
Traditional fine-grained image classification generally requires abundant labeled samples to deal with the low inter-class variance but high intra-class variance problem. However, in many scenarios we may have limited samples for some novel sub-categories, leading to the fine-grained few shot learning (FG-FSL) setting. To address this challenging task, we propose a novel method named foreground object transformation (FOT), which is composed of a foreground object extractor and a posture transformation generator. The former aims to remove image background, which tends to increase the difficulty of fine-grained image classification as it amplifies the intra-class variance while reduces inter-class variance. The latter transforms the posture of the foreground object to generate additional samples for the novel sub-category. As a data augmentation method, FOT can be conveniently applied to any existing few shot learning algorithm and greatly improve its performance on FG-FSL tasks. In particular, in combination with FOT, simple fine-tuning baseline methods can be competitive with the state-of-the-art methods both in inductive setting and transductive setting. Moreover, FOT can further boost the performances of latest excellent methods and bring them up to the new state-of-the-art. In addition, we also show the effectiveness of FOT on general FSL tasks.