 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHotelMatch-LLM: Joint Multi-Task Training of Small and Large Language Models for Efficient Multimodal Hotel Retrieval
Jun 08, 2025



We present HotelMatch-LLM, a multimodal dense retrieval model for the travel domain that enables natural language property search, addressing the limitations of traditional travel search engines which require users to start with a destination and editing search parameters. HotelMatch-LLM features three key innovations: (1) Domain-specific multi-task optimization with three novel retrieval, visual, and language modeling objectives; (2) Asymmetrical dense retrieval architecture combining a small language model (SLM) for efficient online query processing and a large language model (LLM) for embedding hotel data; and (3) Extensive image processing to handle all property image galleries. Experiments on four diverse test sets show HotelMatch-LLM significantly outperforms state-of-the-art models, including VISTA and MARVEL. Specifically, on the test set -- main query type -- we achieve 0.681 for HotelMatch-LLM compared to 0.603 for the most effective baseline, MARVEL. Our analysis highlights the impact of our multi-task optimization, the generalizability of HotelMatch-LLM across LLM architectures, and its scalability for processing large image galleries.
Controlling Summarization Length Through EOS Token Weighting
Jun 05, 2025Controlling the length of generated text can be crucial in various text-generation tasks, including summarization. Existing methods often require complex model alterations, limiting compatibility with pre-trained models. We address these limitations by developing a simple approach for controlling the length of automatic text summaries by increasing the importance of correctly predicting the EOS token in the cross-entropy loss computation. The proposed methodology is agnostic to architecture and decoding algorithms and orthogonal to other inference-time techniques to control the generation length. We tested it with encoder-decoder and modern GPT-style LLMs, and show that this method can control generation length, often without affecting the quality of the summary.
Curriculum Meta-Learning for Few-shot Classification
Dec 06, 2021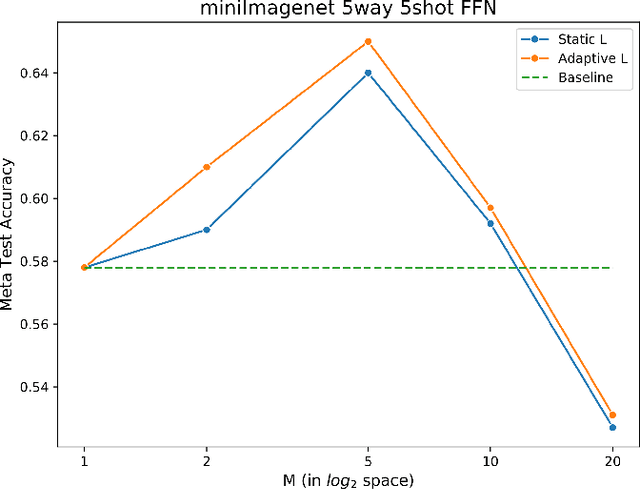
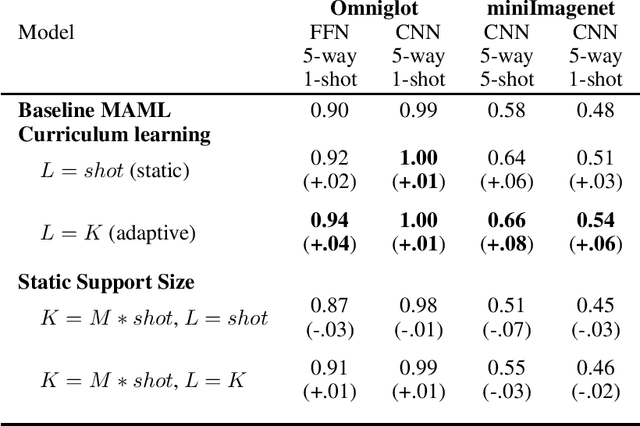
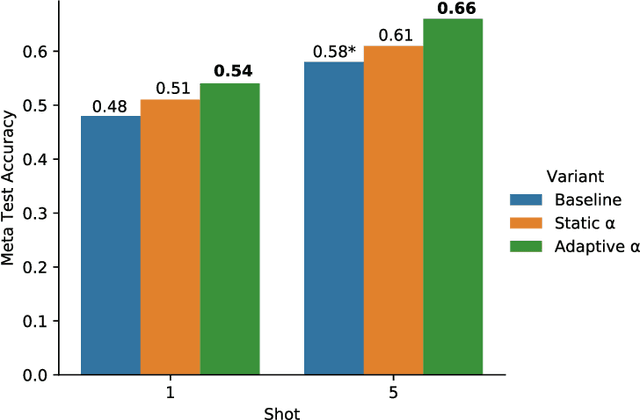
We propose an adaptation of the curriculum training framework, applicable to state-of-the-art meta learning techniques for few-shot classification. Curriculum-based training popularly attempts to mimic human learning by progressively increasing the training complexity to enable incremental concept learning. As the meta-learner's goal is learning how to learn from as few samples as possible, the exact number of those samples (i.e. the size of the support set) arises as a natural proxy of a given task's difficulty. We define a simple yet novel curriculum schedule that begins with a larger support size and progressively reduces it throughout training to eventually match the desired shot-size of the test setup. This proposed method boosts the learning efficiency as well as the generalization capability. Our experiments with the MAML algorithm on two few-shot image classification tasks show significant gains with the curriculum training framework. Ablation studies corroborate the independence of our proposed method from the model architecture as well as the meta-learning hyperparameters
Multi-Domain Adaptation in Neural Machine Translation Through Multidimensional Tagging
Feb 19, 2021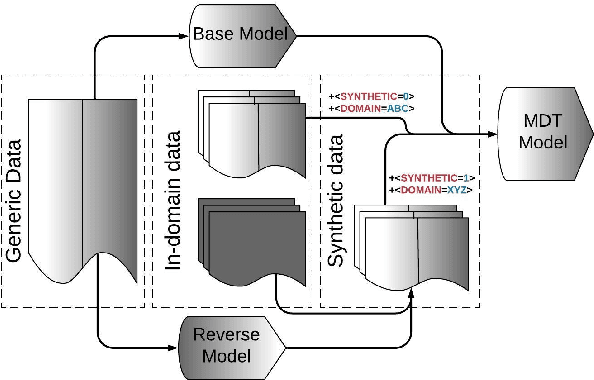
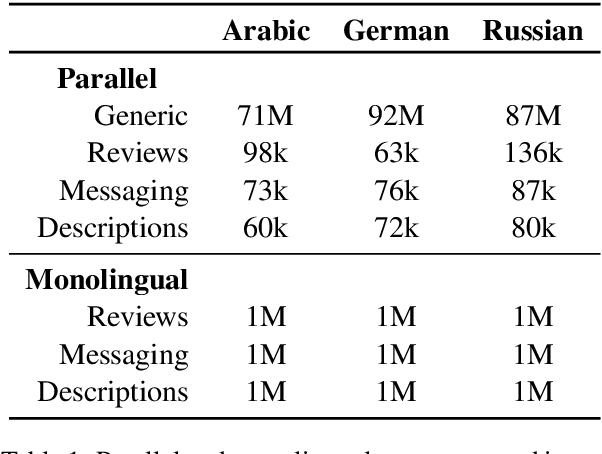
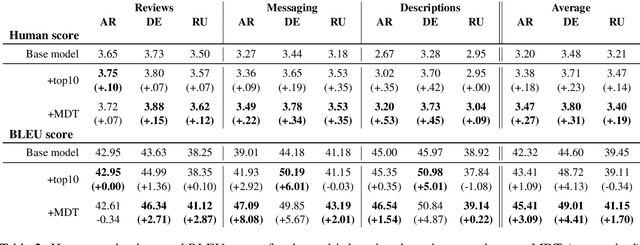
Many modern Neural Machine Translation (NMT) systems are trained on nonhomogeneous datasets with several distinct dimensions of variation (e.g. domain, source, generation method, style, etc.). We describe and empirically evaluate multidimensional tagging (MDT), a simple yet effective method for passing sentence-level information to the model. Our human and BLEU evaluation results show that MDT can be applied to the problem of multi-domain adaptation and significantly reduce training costs without sacrificing the translation quality on any of the constituent domains.