 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Hamilton-Jacobi equations on graphs with applications to semi-supervised learning and data depth
Feb 17, 2022
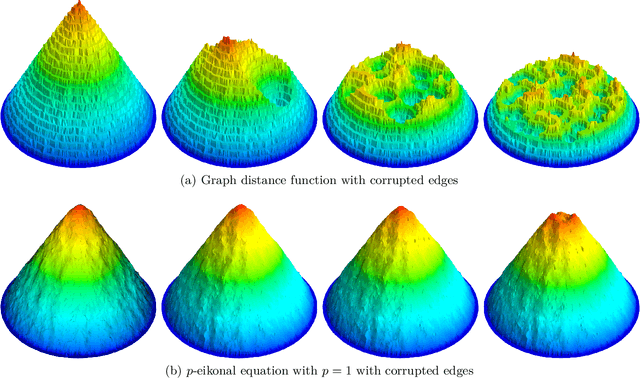
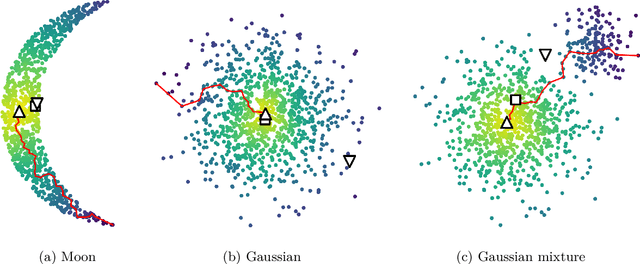
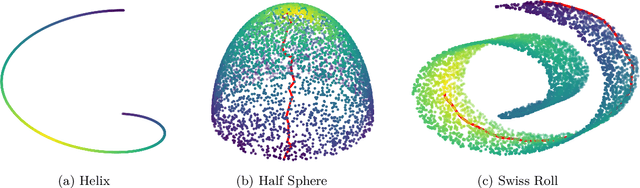
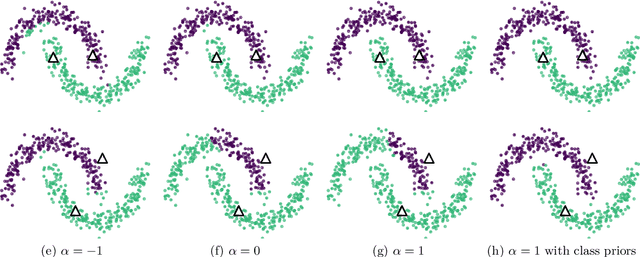
Shortest path graph distances are widely used in data science and machine learning, since they can approximate the underlying geodesic distance on the data manifold. However, the shortest path distance is highly sensitive to the addition of corrupted edges in the graph, either through noise or an adversarial perturbation. In this paper we study a family of Hamilton-Jacobi equations on graphs that we call the $p$-eikonal equation. We show that the $p$-eikonal equation with $p=1$ is a provably robust distance-type function on a graph, and the $p\to \infty$ limit recovers shortest path distances. While the $p$-eikonal equation does not correspond to a shortest-path graph distance, we nonetheless show that the continuum limit of the $p$-eikonal equation on a random geometric graph recovers a geodesic density weighted distance in the continuum. We consider applications of the $p$-eikonal equation to data depth and semi-supervised learning, and use the continuum limit to prove asymptotic consistency results for both applications. Finally, we show the results of experiments with data depth and semi-supervised learning on real image datasets, including MNIST, FashionMNIST and CIFAR-10, which show that the $p$-eikonal equation offers significantly better results compared to shortest path distances.
Making GAN-Generated Images Difficult To Spot: A New Attack Against Synthetic Image Detectors
Apr 25, 2021
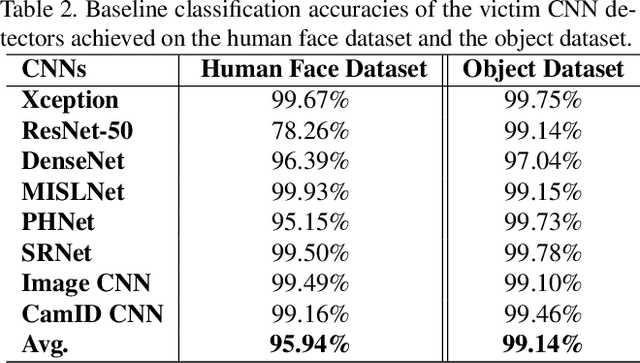

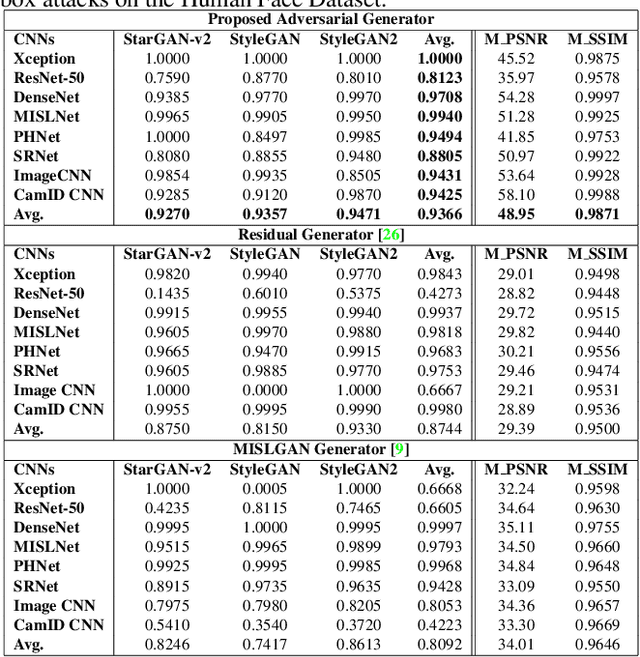
Visually realistic GAN-generated images have recently emerged as an important misinformation threat. Research has shown that these synthetic images contain forensic traces that are readily identifiable by forensic detectors. Unfortunately, these detectors are built upon neural networks, which are vulnerable to recently developed adversarial attacks. In this paper, we propose a new anti-forensic attack capable of fooling GAN-generated image detectors. Our attack uses an adversarially trained generator to synthesize traces that these detectors associate with real images. Furthermore, we propose a technique to train our attack so that it can achieve transferability, i.e. it can fool unknown CNNs that it was not explicitly trained against. We demonstrate the performance of our attack through an extensive set of experiments, where we show that our attack can fool eight state-of-the-art detection CNNs with synthetic images created using seven different GANs.
Lossless Compression with Probabilistic Circuits
Nov 23, 2021
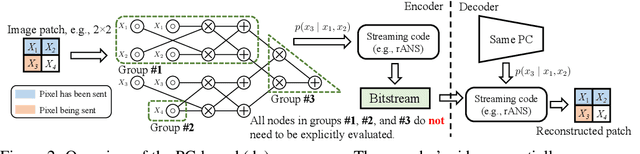
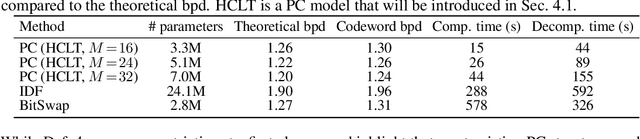
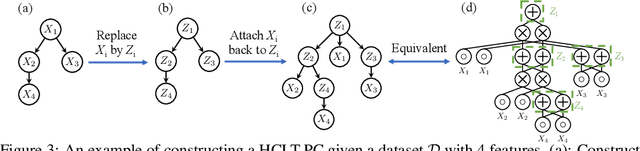
Despite extensive progress on image generation, deep generative models are suboptimal when applied to lossless compression. For example, models such as VAEs suffer from a compression cost overhead due to their latent variables that can only be partially eliminated with elaborated schemes such as bits-back coding, resulting in oftentimes poor single-sample compression rates. To overcome such problems, we establish a new class of tractable lossless compression models that permit efficient encoding and decoding: Probabilistic Circuits (PCs). These are a class of neural networks involving $|p|$ computational units that support efficient marginalization over arbitrary subsets of the $D$ feature dimensions, enabling efficient arithmetic coding. We derive efficient encoding and decoding schemes that both have time complexity $\mathcal{O} (\log(D) \cdot |p|)$, where a naive scheme would have linear costs in $D$ and $|p|$, making the approach highly scalable. Empirically, our PC-based (de)compression algorithm runs 5-20x faster than neural compression algorithms that achieve similar bitrates. By scaling up the traditional PC structure learning pipeline, we achieved state-of-the-art results on image datasets such as MNIST. Furthermore, PCs can be naturally integrated with existing neural compression algorithms to improve the performance of these base models on natural image datasets. Our results highlight the potential impact that non-standard learning architectures may have on neural data compression.
On the Minimal Recognizable Image Patch
Oct 12, 2020
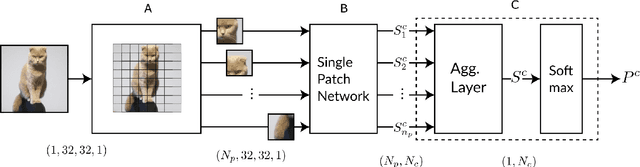
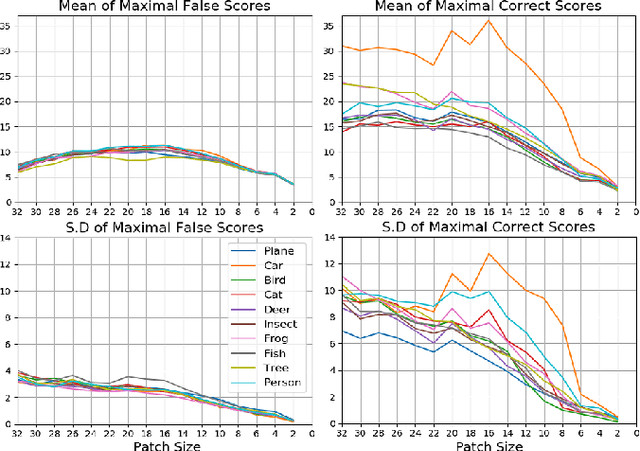
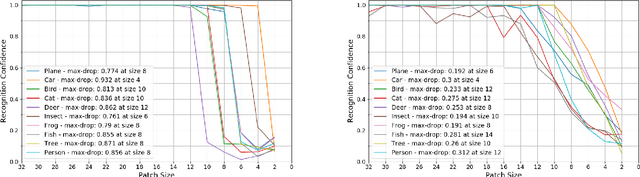
In contrast to human vision, common recognition algorithms often fail on partially occluded images. We propose characterizing, empirically, the algorithmic limits by finding a minimal recognizable patch (MRP) that is by itself sufficient to recognize the image. A specialized deep network allows us to find the most informative patches of a given size, and serves as an experimental tool. A human vision study recently characterized related (but different) minimally recognizable configurations (MIRCs) [1], for which we specify computational analogues (denoted cMIRCs). The drop in human decision accuracy associated with size reduction of these MIRCs is substantial and sharp. Interestingly, such sharp reductions were also found for the computational versions we specified.
Neural 3D Clothes Retargeting from a Single Image
Jan 29, 2021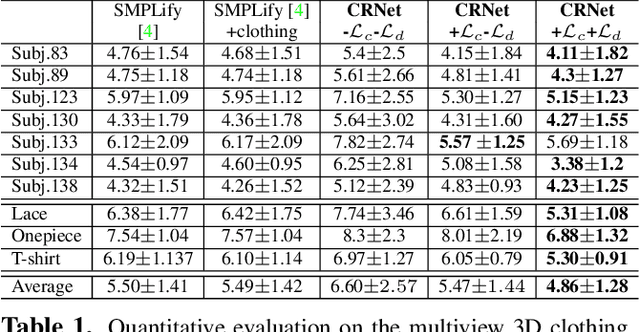

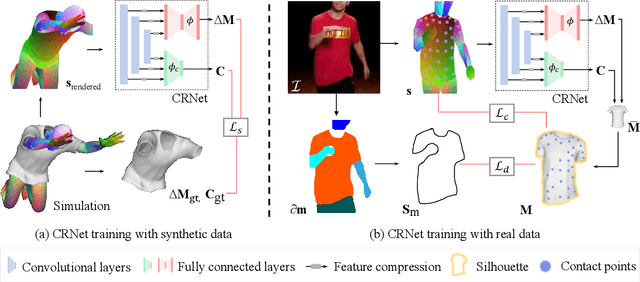
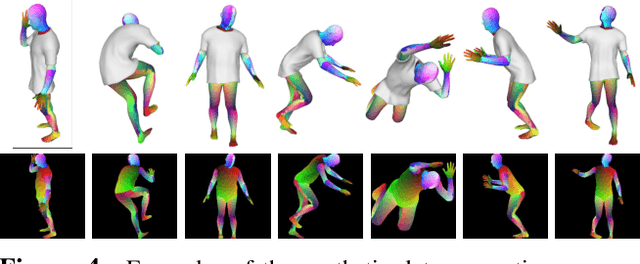
In this paper, we present a method of clothes retargeting; generating the potential poses and deformations of a given 3D clothing template model to fit onto a person in a single RGB image. The problem is fundamentally ill-posed as attaining the ground truth data is impossible, i.e., images of people wearing the different 3D clothing template model at exact same pose. We address this challenge by utilizing large-scale synthetic data generated from physical simulation, allowing us to map 2D dense body pose to 3D clothing deformation. With the simulated data, we propose a semi-supervised learning framework that validates the physical plausibility of the 3D deformation by matching with the prescribed body-to-cloth contact points and clothing silhouette to fit onto the unlabeled real images. A new neural clothes retargeting network (CRNet) is designed to integrate the semi-supervised retargeting task in an end-to-end fashion. In our evaluation, we show that our method can predict the realistic 3D pose and deformation field needed for retargeting clothes models in real-world examples.
Differentially Private Supervised Manifold Learning with Applications like Private Image Retrieval
Feb 22, 2021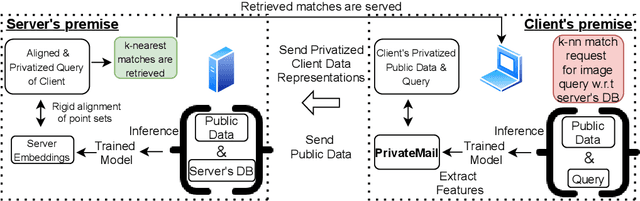
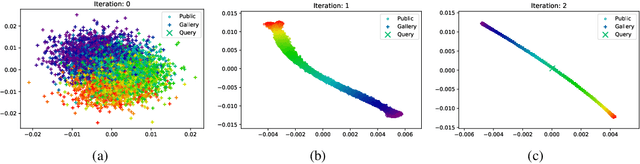

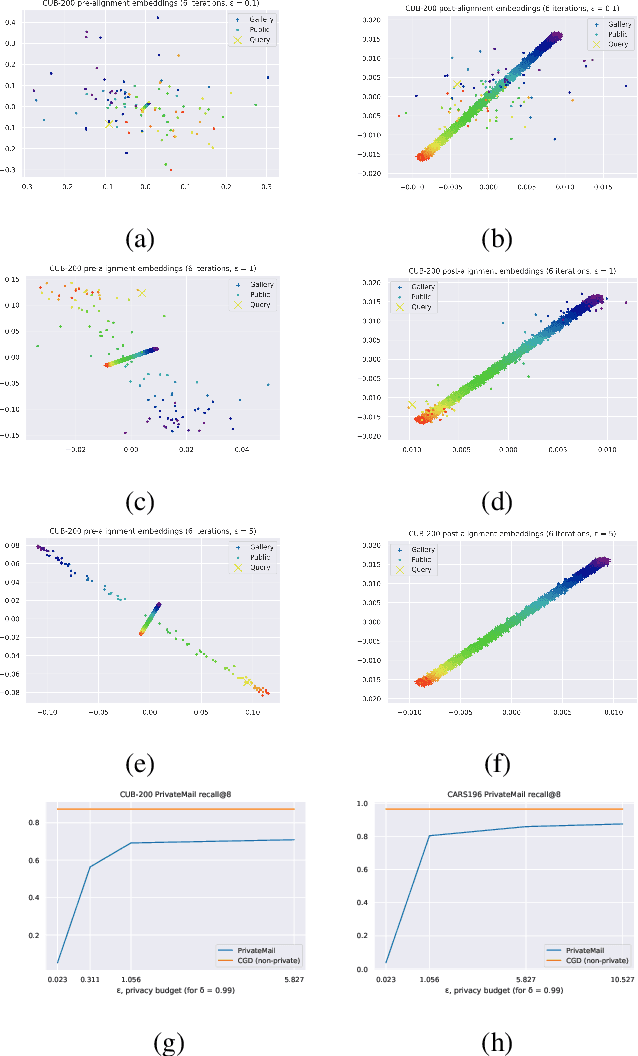
Differential Privacy offers strong guarantees such as immutable privacy under post processing. Thus it is often looked to as a solution to learning on scattered and isolated data. This work focuses on supervised manifold learning, a paradigm that can generate fine-tuned manifolds for a target use case. Our contributions are two fold. 1) We present a novel differentially private method \textit{PrivateMail} for supervised manifold learning, the first of its kind to our knowledge. 2) We provide a novel private geometric embedding scheme for our experimental use case. We experiment on private "content based image retrieval" - embedding and querying the nearest neighbors of images in a private manner - and show extensive privacy-utility tradeoff results, as well as the computational efficiency and practicality of our methods.
DGSS : Domain Generalized Semantic Segmentation using Iterative Style Mining and Latent Representation Alignment
Feb 26, 2022

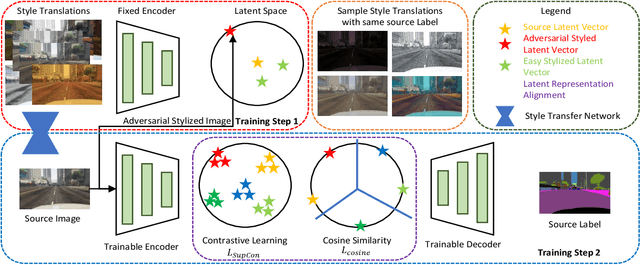

Semantic segmentation algorithms require access to well-annotated datasets captured under diverse illumination conditions to ensure consistent performance. However, poor visibility conditions at varying illumination conditions result in laborious and error-prone labeling. Alternatively, using synthetic samples to train segmentation algorithms has gained interest with the drawback of domain gap that results in sub-optimal performance. While current state-of-the-art (SoTA) have proposed different mechanisms to bridge the domain gap, they still perform poorly in low illumination conditions with an average performance drop of - 10.7 mIOU. In this paper, we focus upon single source domain generalization to overcome the domain gap and propose a two-step framework wherein we first identify an adversarial style that maximizes the domain gap between stylized and source images. Subsequently, these stylized images are used to categorically align features such that features belonging to the same class are clustered together in latent space, irrespective of domain gap. Furthermore, to increase intra-class variance while training, we propose a style mixing mechanism wherein the same objects from different styles are mixed to construct a new training image. This framework allows us to achieve a domain generalized semantic segmentation algorithm with consistent performance without prior information of the target domain while relying on a single source. Based on extensive experiments, we match SoTA performance on SYNTHIA $\to$ Cityscapes, GTAV $\to$ Cityscapes while setting new SoTA on GTAV $\to$ Dark Zurich and GTAV $\to$ Night Driving benchmarks without retraining.
Bridging the Gap: Point Clouds for Merging Neurons in Connectomics
Dec 10, 2021
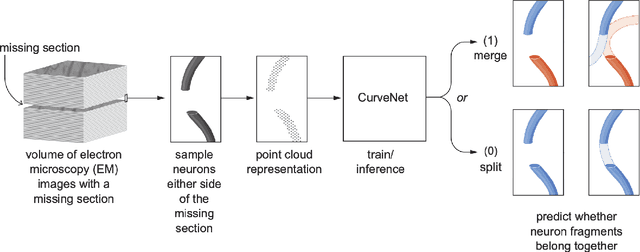

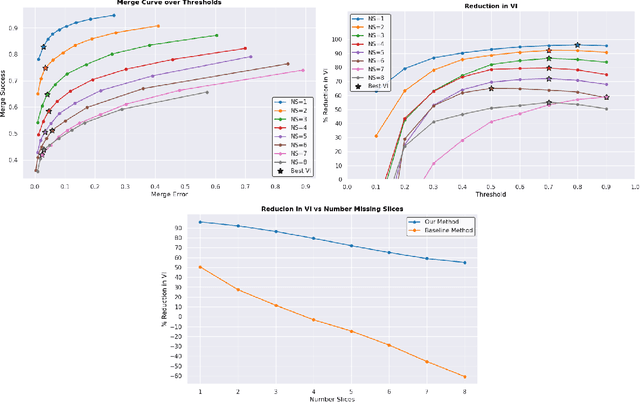
In the field of Connectomics, a primary problem is that of 3D neuron segmentation. Although deep learning-based methods have achieved remarkable accuracy, errors still exist, especially in regions with image defects. One common type of defect is that of consecutive missing image sections. Here, data is lost along some axis, and the resulting neuron segmentations are split across the gap. To address this problem, we propose a novel method based on point cloud representations of neurons. We formulate the problem as a classification problem and train CurveNet, a state-of-the-art point cloud classification model, to identify which neurons should be merged. We show that our method not only performs strongly but also scales reasonably to gaps well beyond what other methods have attempted to address. Additionally, our point cloud representations are highly efficient in terms of data, maintaining high performance with an amount of data that would be unfeasible for other methods. We believe that this is an indicator of the viability of using point cloud representations for other proofreading tasks.
PointFlow: Flowing Semantics Through Points for Aerial Image Segmentation
Mar 11, 2021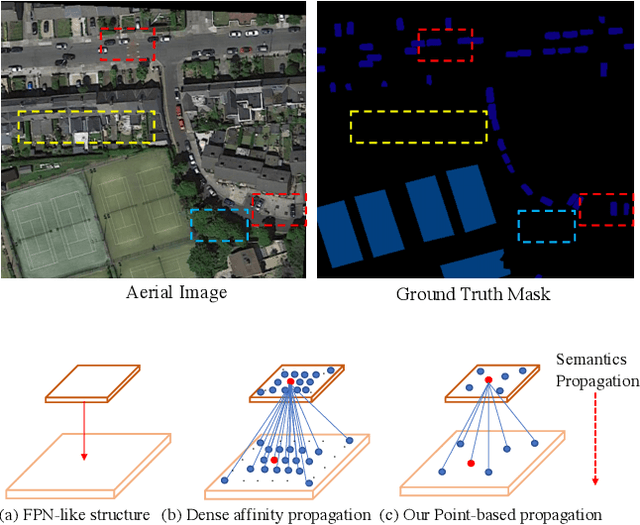
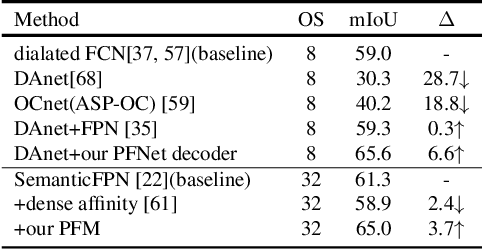
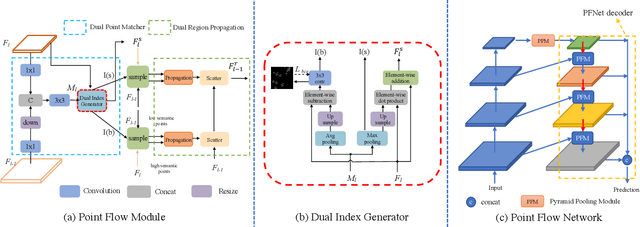
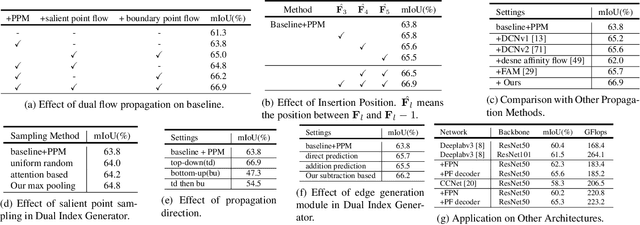
Aerial Image Segmentation is a particular semantic segmentation problem and has several challenging characteristics that general semantic segmentation does not have. There are two critical issues: The one is an extremely foreground-background imbalanced distribution, and the other is multiple small objects along with the complex background. Such problems make the recent dense affinity context modeling perform poorly even compared with baselines due to over-introduced background context. To handle these problems, we propose a point-wise affinity propagation module based on the Feature Pyramid Network (FPN) framework, named PointFlow. Rather than dense affinity learning, a sparse affinity map is generated upon selected points between the adjacent features, which reduces the noise introduced by the background while keeping efficiency. In particular, we design a dual point matcher to select points from the salient area and object boundaries, respectively. Experimental results on three different aerial segmentation datasets suggest that the proposed method is more effective and efficient than state-of-the-art general semantic segmentation methods. Especially, our methods achieve the best speed and accuracy trade-off on three aerial benchmarks. Further experiments on three general semantic segmentation datasets prove the generality of our method. Code will be provided in (https: //github.com/lxtGH/PFSegNets).
SketchyCOCO: Image Generation from Freehand Scene Sketches
Apr 07, 2020
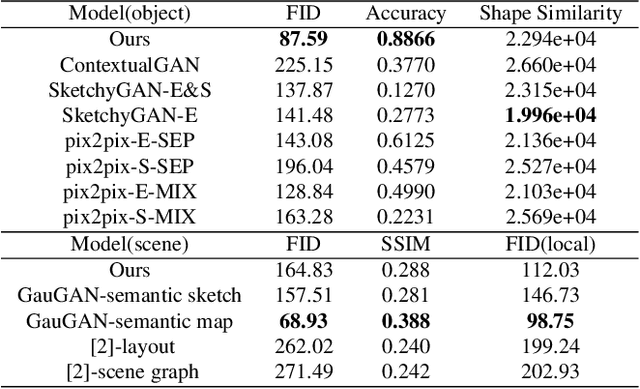
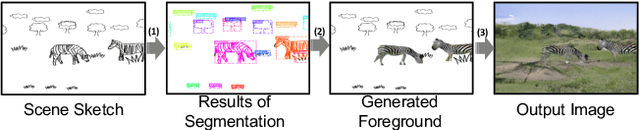
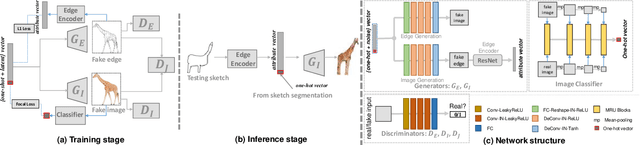
We introduce the first method for automatic image generation from scene-level freehand sketches. Our model allows for controllable image generation by specifying the synthesis goal via freehand sketches. The key contribution is an attribute vector bridged Generative Adversarial Network called EdgeGAN, which supports high visual-quality object-level image content generation without using freehand sketches as training data. We have built a large-scale composite dataset called SketchyCOCO to support and evaluate the solution. We validate our approach on the tasks of both object-level and scene-level image generation on SketchyCOCO. Through quantitative, qualitative results, human evaluation and ablation studies, we demonstrate the method's capacity to generate realistic complex scene-level images from various freehand sketches.