 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Enhanced Transfer Learning Through Medical Imaging and Patient Demographic Data Fusion
Nov 29, 2021
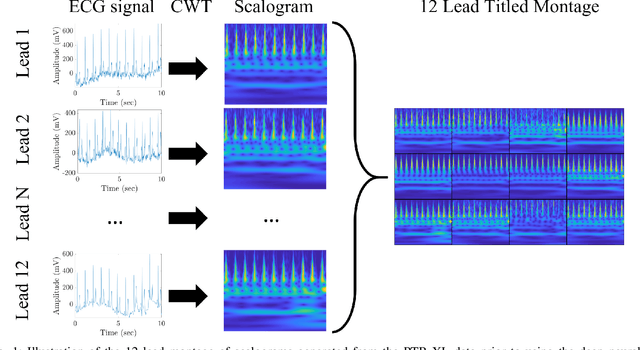
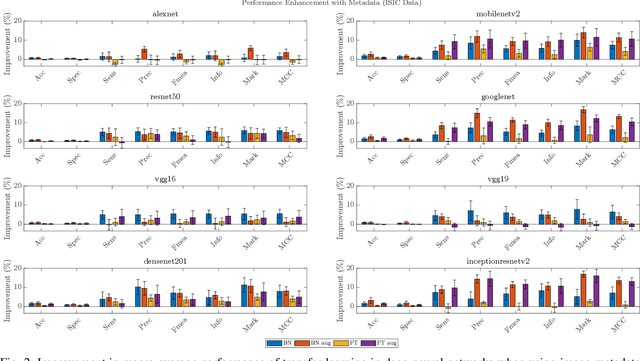
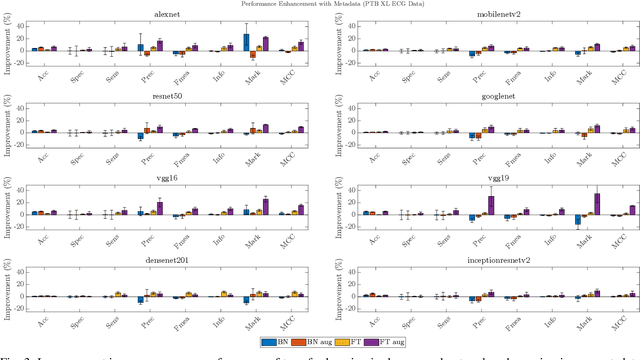
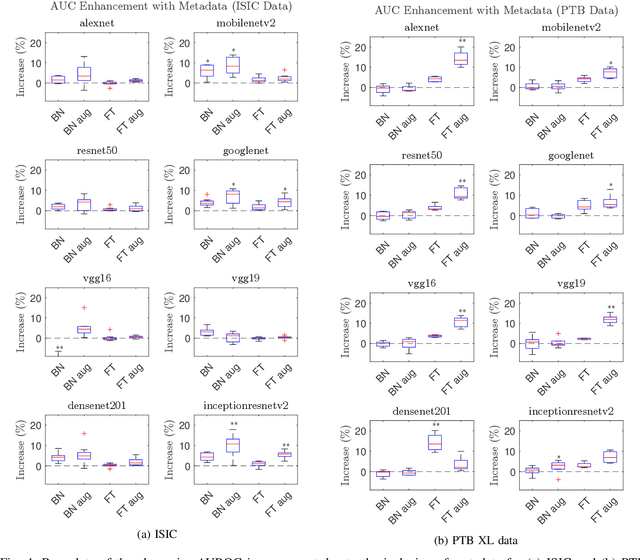
In this work we examine the performance enhancement in classification of medical imaging data when image features are combined with associated non-image data. We compare the performance of eight state-of-the-art deep neural networks in classification tasks when using only image features, compared to when these are combined with patient metadata. We utilise transfer learning with networks pretrained on ImageNet used directly as feature extractors and fine tuned on the target domain. Our experiments show that performance can be significantly enhanced with the inclusion of metadata and use interpretability methods to identify which features lead to these enhancements. Furthermore, our results indicate that the performance enhancement for natural medical imaging (e.g. optical images) benefit most from direct use of pre-trained models, whereas non natural images (e.g. representations of non imaging data) benefit most from fine tuning pre-trained networks. These enhancements come at a negligible additional cost in computation time, and therefore is a practical method for other applications.
A Robust Method for Image Stitching
Apr 08, 2020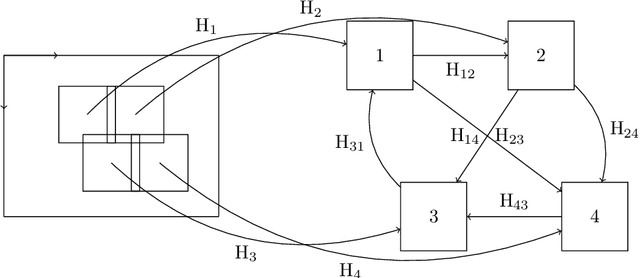
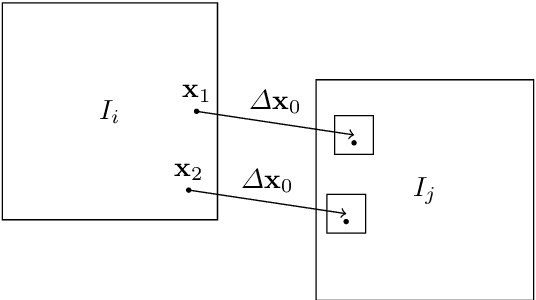

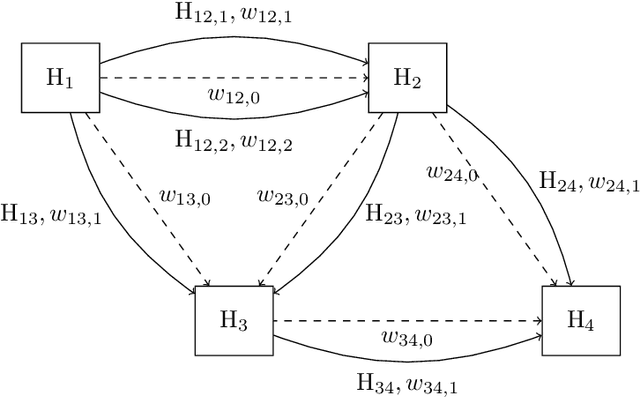
We propose a novel method for image stitching that is robust against repetitive patterns and featureless regions in the imaginary. In such cases, typical image stitching methods easily produce stitching artifacts, since they may produce false pairwise image registrations that are in conflict within the global connectivity graph. By contrast, our method collects all the plausible pairwise image registration candidates, among which globally consistent candidates are chosen. This enables the method to determine the correct pairwise registrations by utilizing all the available information from the whole imaginary, such as unambiguous registrations outside the repeating pattern and featureless regions. We formalize the method as a weighted multigraph whose nodes represent the individual image transformations from the composite image, and whose sets of multiple edges between two nodes represent all the plausible transformations between the pixel coordinates of the two images. The edge weights represent the plausibility of the transformations. The image transformations and the edge weights are solved from a non-linear minimization problem with linear constraints, for which a projection method is used. As an example, we apply the method in a scanning application where the transformations are primarily translations with only slight rotation and scaling component.
Learning to Deblur and Rotate Motion-Blurred Faces
Dec 14, 2021
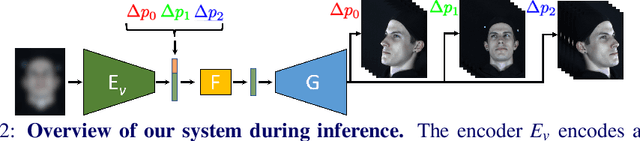
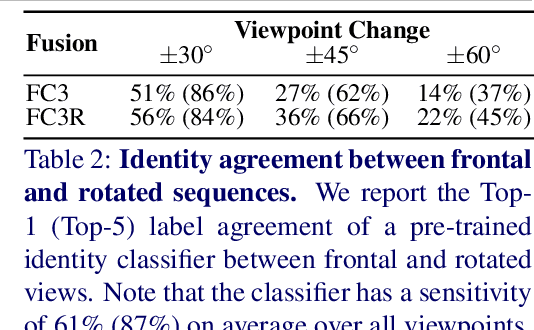
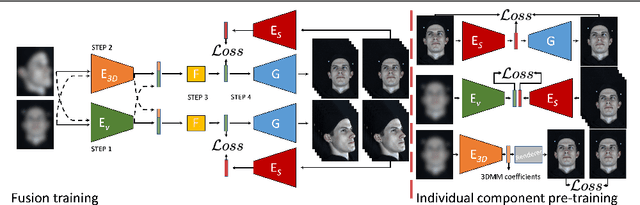
We propose a solution to the novel task of rendering sharp videos from new viewpoints from a single motion-blurred image of a face. Our method handles the complexity of face blur by implicitly learning the geometry and motion of faces through the joint training on three large datasets: FFHQ and 300VW, which are publicly available, and a new Bern Multi-View Face Dataset (BMFD) that we built. The first two datasets provide a large variety of faces and allow our model to generalize better. BMFD instead allows us to introduce multi-view constraints, which are crucial to synthesizing sharp videos from a new camera view. It consists of high frame rate synchronized videos from multiple views of several subjects displaying a wide range of facial expressions. We use the high frame rate videos to simulate realistic motion blur through averaging. Thanks to this dataset, we train a neural network to reconstruct a 3D video representation from a single image and the corresponding face gaze. We then provide a camera viewpoint relative to the estimated gaze and the blurry image as input to an encoder-decoder network to generate a video of sharp frames with a novel camera viewpoint. We demonstrate our approach on test subjects of our multi-view dataset and VIDTIMIT.
Aesthetics and neural network image representations
Sep 16, 2021



We analyze the spaces of images encoded by generative networks of the BigGAN architecture. We find that generic multiplicative perturbations away from the photo-realistic point often lead to images which appear as "artistic renditions" of the corresponding objects. This demonstrates an emergence of aesthetic properties directly from the structure of the photo-realistic environment coupled with its neural network parametrization. Moreover, modifying a deep semantic part of the neural network encoding leads to the appearance of symbolic visual representations.
An Efficient Framework for Zero-Shot Sketch-Based Image Retrieval
Feb 08, 2021
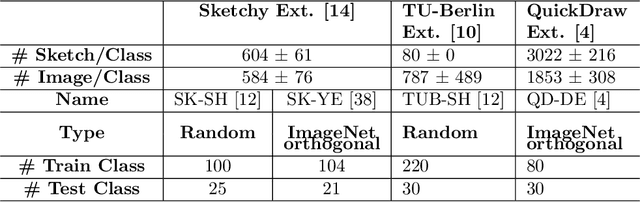
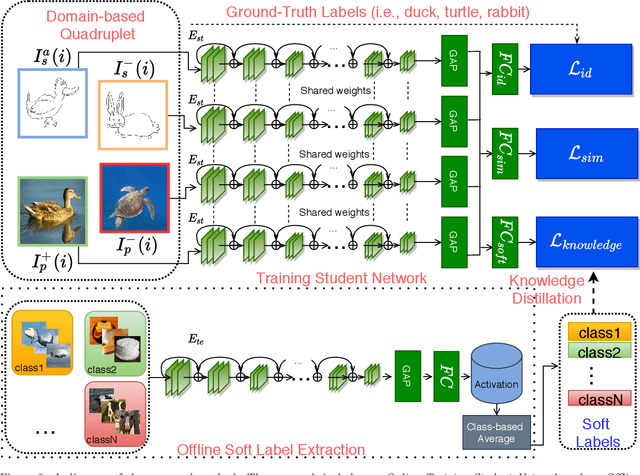
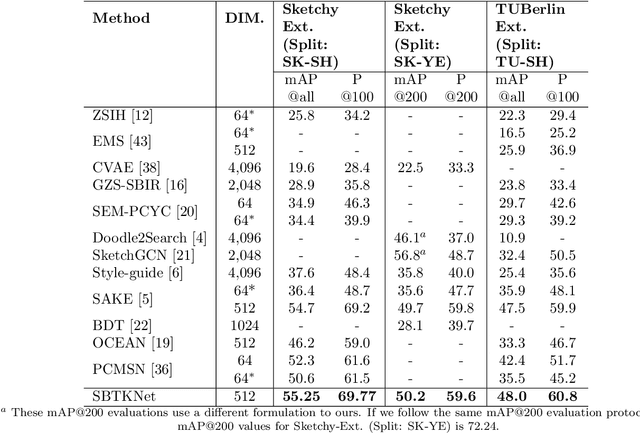
Recently, Zero-shot Sketch-based Image Retrieval (ZS-SBIR) has attracted the attention of the computer vision community due to it's real-world applications, and the more realistic and challenging setting than found in SBIR. ZS-SBIR inherits the main challenges of multiple computer vision problems including content-based Image Retrieval (CBIR), zero-shot learning and domain adaptation. The majority of previous studies using deep neural networks have achieved improved results through either projecting sketch and images into a common low-dimensional space or transferring knowledge from seen to unseen classes. However, those approaches are trained with complex frameworks composed of multiple deep convolutional neural networks (CNNs) and are dependent on category-level word labels. This increases the requirements on training resources and datasets. In comparison, we propose a simple and efficient framework that does not require high computational training resources, and can be trained on datasets without semantic categorical labels. Furthermore, at training and inference stages our method only uses a single CNN. In this work, a pre-trained ImageNet CNN (e.g., ResNet50) is fine-tuned with three proposed learning objects: domain-aware quadruplet loss, semantic classification loss, and semantic knowledge preservation loss. The domain-aware quadruplet and semantic classification losses are introduced to learn discriminative, semantic and domain invariant features through considering ZS-SBIR as object detection and verification problem. ...
Detection of multiple retinal diseases in ultra-widefield fundus images using deep learning: data-driven identification of relevant regions
Mar 11, 2022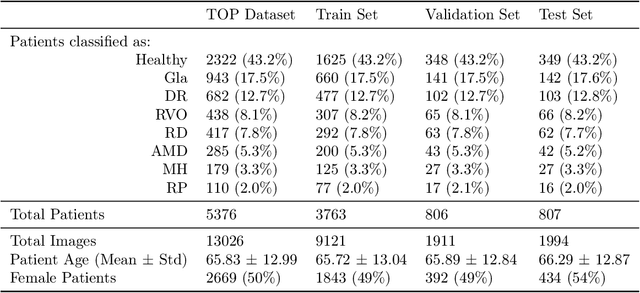
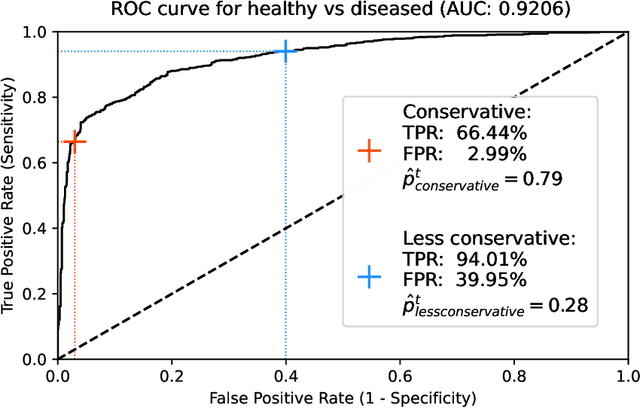

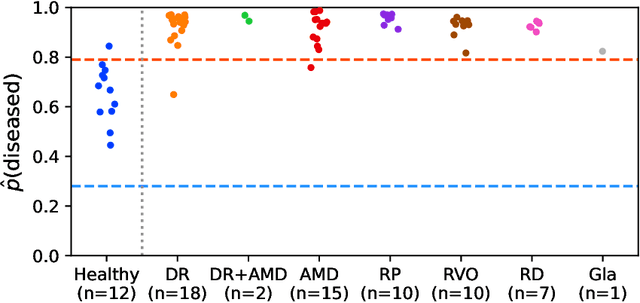
Ultra-widefield (UWF) imaging is a promising modality that captures a larger retinal field of view compared to traditional fundus photography. Previous studies showed that deep learning (DL) models are effective for detecting retinal disease in UWF images, but primarily considered individual diseases under less-than-realistic conditions (excluding images with other diseases, artefacts, comorbidities, or borderline cases; and balancing healthy and diseased images) and did not systematically investigate which regions of the UWF images are relevant for disease detection. We first improve on the state of the field by proposing a DL model that can recognise multiple retinal diseases under more realistic conditions. We then use global explainability methods to identify which regions of the UWF images the model generally attends to. Our model performs very well, separating between healthy and diseased retinas with an area under the curve (AUC) of 0.9206 on an internal test set, and an AUC of 0.9841 on a challenging, external test set. When diagnosing specific diseases, the model attends to regions where we would expect those diseases to occur. We further identify the posterior pole as the most important region in a purely data-driven fashion. Surprisingly, 10% of the image around the posterior pole is sufficient for achieving comparable performance to having the full images available.
Dual Embodied-Symbolic Concept Representations for Deep Learning
Mar 01, 2022Motivated by recent findings from cognitive neural science, we advocate the use of a dual-level model for concept representations: the embodied level consists of concept-oriented feature representations, and the symbolic level consists of concept graphs. Embodied concept representations are modality specific and exist in the form of feature vectors in a feature space. Symbolic concept representations, on the other hand, are amodal and language specific, and exist in the form of word / knowledge-graph embeddings in a concept / knowledge space. The human conceptual system comprises both embodied representations and symbolic representations, which typically interact to drive conceptual processing. As such, we further advocate the use of dual embodied-symbolic concept representations for deep learning. To demonstrate their usage and value, we discuss two important use cases: embodied-symbolic knowledge distillation for few-shot class incremental learning, and embodied-symbolic fused representation for image-text matching. Dual embodied-symbolic concept representations are the foundation for deep learning and symbolic AI integration. We discuss two important examples of such integration: scene graph generation with knowledge graph bridging, and multimodal knowledge graphs.
Spot the Difference: A Cooperative Object-Referring Game in Non-Perfectly Co-Observable Scene
Mar 16, 2022
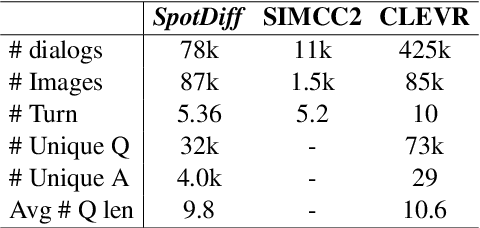
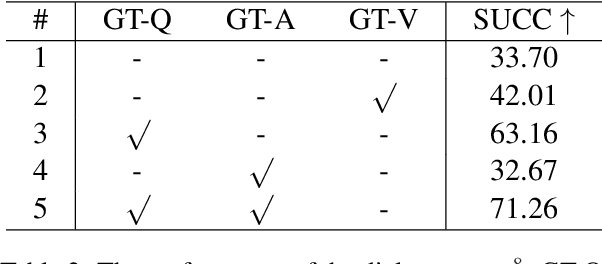
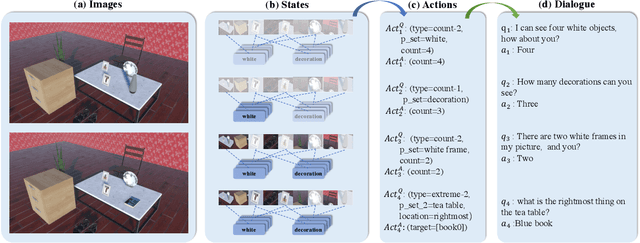
Visual dialog has witnessed great progress after introducing various vision-oriented goals into the conversation, especially such as GuessWhich and GuessWhat, where the only image is visible by either and both of the questioner and the answerer, respectively. Researchers explore more on visual dialog tasks in such kind of single- or perfectly co-observable visual scene, while somewhat neglect the exploration on tasks of non perfectly co-observable visual scene, where the images accessed by two agents may not be exactly the same, often occurred in practice. Although building common ground in non-perfectly co-observable visual scene through conversation is significant for advanced dialog agents, the lack of such dialog task and corresponding large-scale dataset makes it impossible to carry out in-depth research. To break this limitation, we propose an object-referring game in non-perfectly co-observable visual scene, where the goal is to spot the difference between the similar visual scenes through conversing in natural language. The task addresses challenges of the dialog strategy in non-perfectly co-observable visual scene and the ability of categorizing objects. Correspondingly, we construct a large-scale multimodal dataset, named SpotDiff, which contains 87k Virtual Reality images and 97k dialogs generated by self-play. Finally, we give benchmark models for this task, and conduct extensive experiments to evaluate its performance as well as analyze its main challenges.
Learning Accurate Entropy Model with Global Reference for Image Compression
Oct 29, 2020


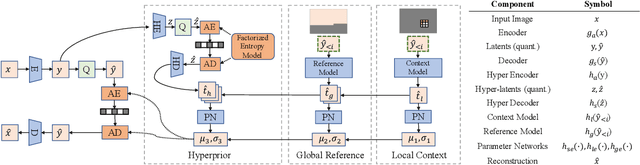
In recent deep image compression neural networks, the entropy model plays a critical role in estimating the prior distribution of deep image encodings. Existing methods combine hyperprior with local context in the entropy estimation function. This greatly limits their performance due to the absence of a global vision. In this work, we propose a novel Global Reference Model for image compression to effectively leverage both the local and the global context information, leading to an enhanced compression rate. The proposed method scans decoded latents and then finds the most relevant latent to assist the distribution estimating of the current latent. A by-product of this work is the innovation of a mean-shifting GDN module that further improves the performance. Experimental results demonstrate that the proposed model outperforms the rate-distortion performance of most of the state-of-the-art methods in the industry.
Improving Text to Image Generation using Mode-seeking Function
Sep 18, 2020
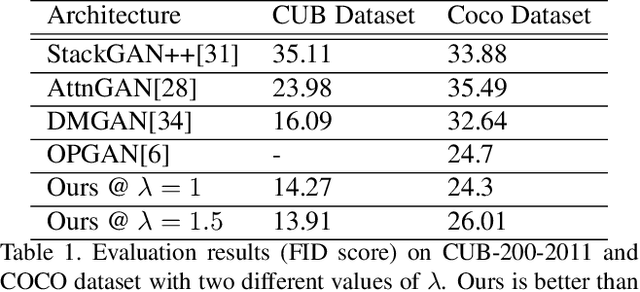


Generative Adversarial Networks (GANs) have long been used to understand the semantic relationship between the text and image. However, there are problems with mode collapsing in the image generation that causes some preferred output modes. Our aim is to improve the training of the network by using a specialized mode-seeking loss function to avoid this issue. In the text to image synthesis, our loss function differentiates two points in latent space for the generation of distinct images. We validate our model on the Caltech Birds (CUB) dataset and the Microsoft COCO dataset by changing the intensity of the loss function during the training. Experimental results demonstrate that our model works very well compared to some state-of-the-art approaches.