 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Anchors to Supervision: Memory-Graph Guided Corpus-Free Unlearning for Large Language Models
Apr 15, 2026Large language models (LLMs) may memorize sensitive or copyrighted content, raising significant privacy and legal concerns. While machine unlearning has emerged as a potential remedy, prevailing paradigms rely on user-provided forget sets, making unlearning requests difficult to audit and exposing systems to secondary leakage and malicious abuse. We propose MAGE, a Memory-grAph Guided Erasure framework for user-minimized, corpus-free unlearning. Given only a lightweight user anchor that identifies a target entity, MAGE probes the target LLM to recover target-related memorization, organizes it into a weighted local memory graph, and synthesizes scoped supervision for unlearning. MAGE is model-agnostic, can be plugged into standard unlearning methods, and requires no access to the original training corpus. Experiments on two benchmarks, TOFU and RWKU, demonstrate that MAGE's self-generated supervision achieves effective unlearning performance comparable to supervision generated with external reference, while preserving overall utility. These results support a practical and auditable unlearning workflow driven by minimal anchors rather than user-supplied forget corpora.
ReDiPrune: Relevance-Diversity Pre-Projection Token Pruning for Efficient Multimodal LLMs
Mar 25, 2026Recent multimodal large language models are computationally expensive because Transformers must process a large number of visual tokens. We present \textbf{ReDiPrune}, a training-free token pruning method applied before the vision-language projector, where visual features remain rich and discriminative. Unlike post-projection pruning methods that operate on compressed representations, ReDiPrune selects informative tokens directly from vision encoder outputs, preserving fine-grained spatial and semantic cues. Each token is scored by a lightweight rule that jointly consider text-conditioned relevance and max-min diversity, ensuring the selected tokens are both query-relevant and non-redundant. ReDiPrune is fully plug-and-play, requiring no retraining or architectural modifications, and can be seamlessly inserted between the encoder and projector. Across four video and five image benchmarks, it consistently improves the accuracy-efficiency trade-off. For example, on EgoSchema with LLaVA-NeXT-Video-7B, retaining only 15\% of visual tokens yields a +2.0\% absolute accuracy gain while reducing computation by more than $6\times$ in TFLOPs. Code is available at https://github.com/UA-CVML/ReDiPrune.
SMART: Shot-Aware Multimodal Video Moment Retrieval with Audio-Enhanced MLLM
Nov 18, 2025Video Moment Retrieval is a task in video understanding that aims to localize a specific temporal segment in an untrimmed video based on a natural language query. Despite recent progress in moment retrieval from videos using both traditional techniques and Multimodal Large Language Models (MLLM), most existing methods still rely on coarse temporal understanding and a single visual modality, limiting performance on complex videos. To address this, we introduce \textit{S}hot-aware \textit{M}ultimodal \textit{A}udio-enhanced \textit{R}etrieval of \textit{T}emporal \textit{S}egments (SMART), an MLLM-based framework that integrates audio cues and leverages shot-level temporal structure. SMART enriches multimodal representations by combining audio and visual features while applying \textbf{Shot-aware Token Compression}, which selectively retains high-information tokens within each shot to reduce redundancy and preserve fine-grained temporal details. We also refine prompt design to better utilize audio-visual cues. Evaluations on Charades-STA and QVHighlights show that SMART achieves significant improvements over state-of-the-art methods, including a 1.61\% increase in R1@0.5 and 2.59\% gain in R1@0.7 on Charades-STA.
A New Benchmark and Model for Challenging Image Manipulation Detection
Nov 23, 2023



The ability to detect manipulation in multimedia data is vital in digital forensics. Existing Image Manipulation Detection (IMD) methods are mainly based on detecting anomalous features arisen from image editing or double compression artifacts. All existing IMD techniques encounter challenges when it comes to detecting small tampered regions from a large image. Moreover, compression-based IMD approaches face difficulties in cases of double compression of identical quality factors. To investigate the State-of-The-Art (SoTA) IMD methods in those challenging conditions, we introduce a new Challenging Image Manipulation Detection (CIMD) benchmark dataset, which consists of two subsets, for evaluating editing-based and compression-based IMD methods, respectively. The dataset images were manually taken and tampered with high-quality annotations. In addition, we propose a new two-branch network model based on HRNet that can better detect both the image-editing and compression artifacts in those challenging conditions. Extensive experiments on the CIMD benchmark show that our model significantly outperforms SoTA IMD methods on CIMD.
Improving Text to Image Generation using Mode-seeking Function
Sep 18, 2020
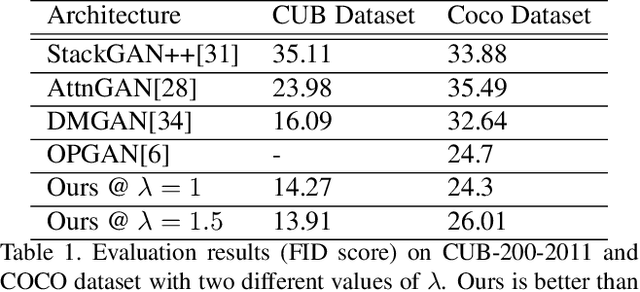


Generative Adversarial Networks (GANs) have long been used to understand the semantic relationship between the text and image. However, there are problems with mode collapsing in the image generation that causes some preferred output modes. Our aim is to improve the training of the network by using a specialized mode-seeking loss function to avoid this issue. In the text to image synthesis, our loss function differentiates two points in latent space for the generation of distinct images. We validate our model on the Caltech Birds (CUB) dataset and the Microsoft COCO dataset by changing the intensity of the loss function during the training. Experimental results demonstrate that our model works very well compared to some state-of-the-art approaches.