 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Real-time Rendering for Integral Imaging Light Field Displays Based on a Voxel-Pixel Lookup Table
Jan 20, 2022
A real-time elemental image array (EIA) generation method which does not sacrifice accuracy nor rely on high-performance hardware is developed, through raytracing and pre-stored voxel-pixel lookup table (LUT). Benefiting from both offline and online working flow, experiments verified the effectiveness.
How to Exploit the Transferability of Learned Image Compression to Conventional Codecs
Dec 03, 2020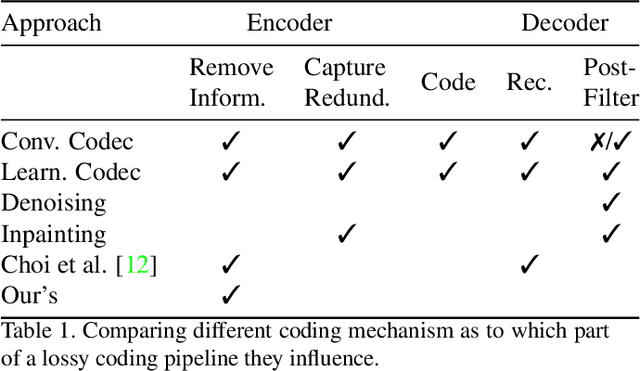
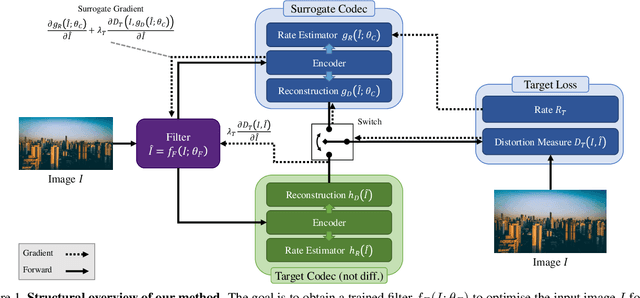
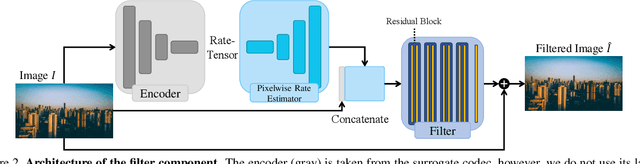

Lossy image compression is often limited by the simplicity of the chosen loss measure. Recent research suggests that generative adversarial networks have the ability to overcome this limitation and serve as a multi-modal loss, especially for textures. Together with learned image compression, these two techniques can be used to great effect when relaxing the commonly employed tight measures of distortion. However, convolutional neural network based algorithms have a large computational footprint. Ideally, an existing conventional codec should stay in place, which would ensure faster adoption and adhering to a balanced computational envelope. As a possible avenue to this goal, in this work, we propose and investigate how learned image coding can be used as a surrogate to optimize an image for encoding. The image is altered by a learned filter to optimise for a different performance measure or a particular task. Extending this idea with a generative adversarial network, we show how entire textures are replaced by ones that are less costly to encode but preserve sense of detail. Our approach can remodel a conventional codec to adjust for the MS-SSIM distortion with over 20% rate improvement without any decoding overhead. On task-aware image compression, we perform favourably against a similar but codec-specific approach.
Encryption and encoding of facial images into quick response and high capacity color 2d code for biometric passport security system
Mar 17, 2022
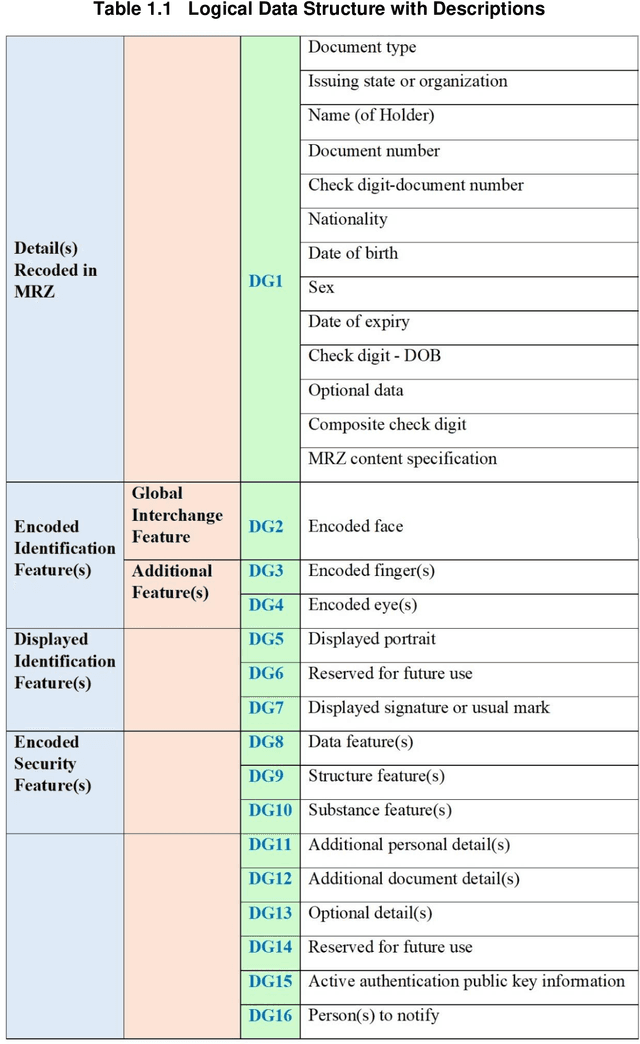

In this thesis, a multimodal biometric, secure encrypted data and encrypted biometric encoded into the QR code-based biometric-passport authentication method is proposed for national security applications. Firstly, using the Extended Profile - Local Binary Patterns (EP-LBP), a Canny edge detector, and the Scale Invariant Feature Transform (SIFT) algorithm with Image File Information (IMFINFO) process, the facial mark size recognition is initially achieved. Secondly, by using the Active Shape Model (ASM) into Active Appearance Model (AAM) to follow the hand and infusion the hand geometry characteristics for verification and identification, hand geometry recognition is achieved. Thirdly, the encrypted biometric passport information that is publicly accessible is encoded into the QR code and inserted into the electronic passport to improve protection. Further, Personal information and biometric data are encrypted by applying the Advanced Encryption Standard (AES) and the Secure Hash Algorithm (SHA) 256 algorithm. It will enhance the biometric passport security system.
Birds of A Feather Flock Together: Category-Divergence Guidance for Domain Adaptive Segmentation
Apr 05, 2022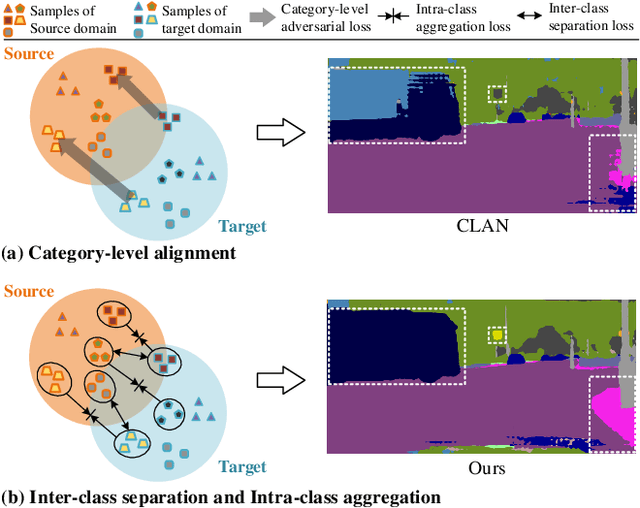

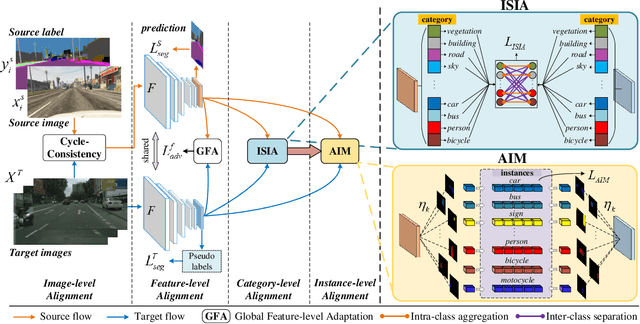
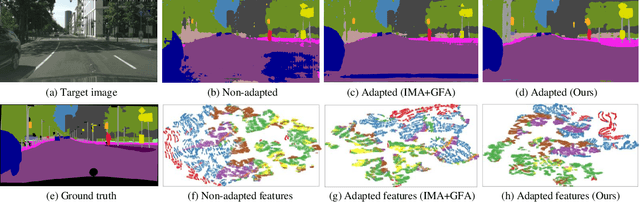
Unsupervised domain adaptation (UDA) aims to enhance the generalization capability of a certain model from a source domain to a target domain. Present UDA models focus on alleviating the domain shift by minimizing the feature discrepancy between the source domain and the target domain but usually ignore the class confusion problem. In this work, we propose an Inter-class Separation and Intra-class Aggregation (ISIA) mechanism. It encourages the cross-domain representative consistency between the same categories and differentiation among diverse categories. In this way, the features belonging to the same categories are aligned together and the confusable categories are separated. By measuring the align complexity of each category, we design an Adaptive-weighted Instance Matching (AIM) strategy to further optimize the instance-level adaptation. Based on our proposed methods, we also raise a hierarchical unsupervised domain adaptation framework for cross-domain semantic segmentation task. Through performing the image-level, feature-level, category-level and instance-level alignment, our method achieves a stronger generalization performance of the model from the source domain to the target domain. In two typical cross-domain semantic segmentation tasks, i.e., GTA5 to Cityscapes and SYNTHIA to Cityscapes, our method achieves the state-of-the-art segmentation accuracy. We also build two cross-domain semantic segmentation datasets based on the publicly available data, i.e., remote sensing building segmentation and road segmentation, for domain adaptive segmentation.
3D Brain Reconstruction by Hierarchical Shape-Perception Network from a Single Incomplete Image
Jul 23, 2021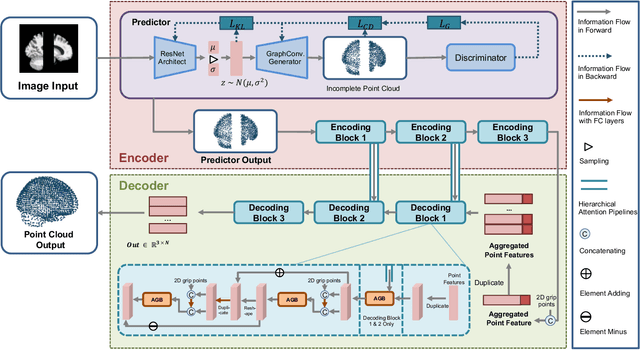
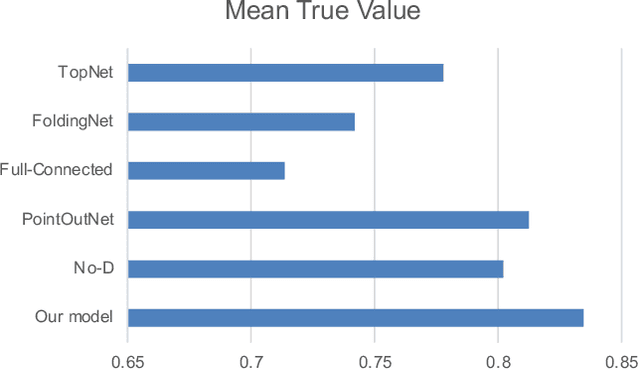
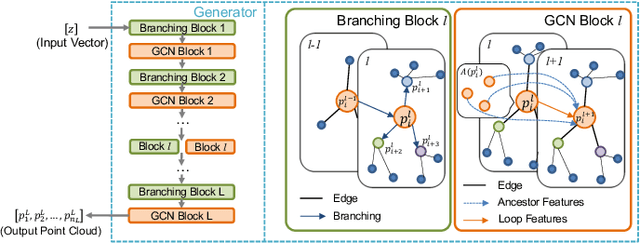
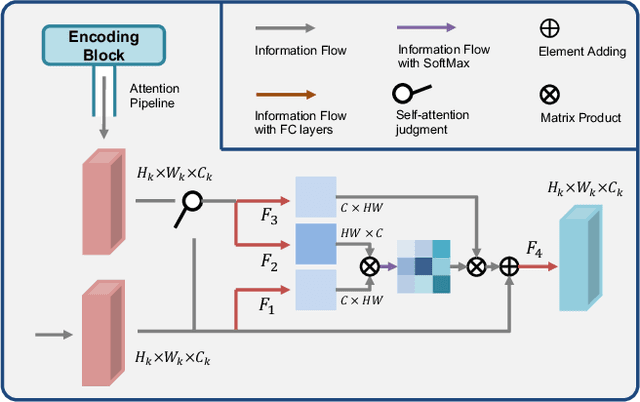
3D shape reconstruction is essential in the navigation of minimally-invasive and auto robot-guided surgeries whose operating environments are indirect and narrow, and there have been some works that focused on reconstructing the 3D shape of the surgical organ through limited 2D information available. However, the lack and incompleteness of such information caused by intraoperative emergencies (such as bleeding) and risk control conditions have not been considered. In this paper, a novel hierarchical shape-perception network (HSPN) is proposed to reconstruct the 3D point clouds (PCs) of specific brains from one single incomplete image with low latency. A tree-structured predictor and several hierarchical attention pipelines are constructed to generate point clouds that accurately describe the incomplete images and then complete these point clouds with high quality. Meanwhile, attention gate blocks (AGBs) are designed to efficiently aggregate geometric local features of incomplete PCs transmitted by hierarchical attention pipelines and internal features of reconstructing point clouds. With the proposed HSPN, 3D shape perception and completion can be achieved spontaneously. Comprehensive results measured by Chamfer distance and PC-to-PC error demonstrate that the performance of the proposed HSPN outperforms other competitive methods in terms of qualitative displays, quantitative experiment, and classification evaluation.
Confidence Dimension for Deep Learning based on Hoeffding Inequality and Relative Evaluation
Mar 17, 2022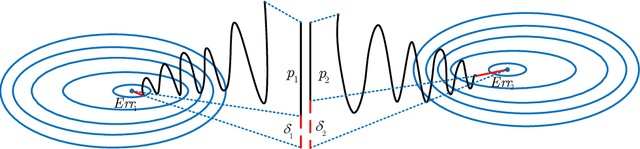
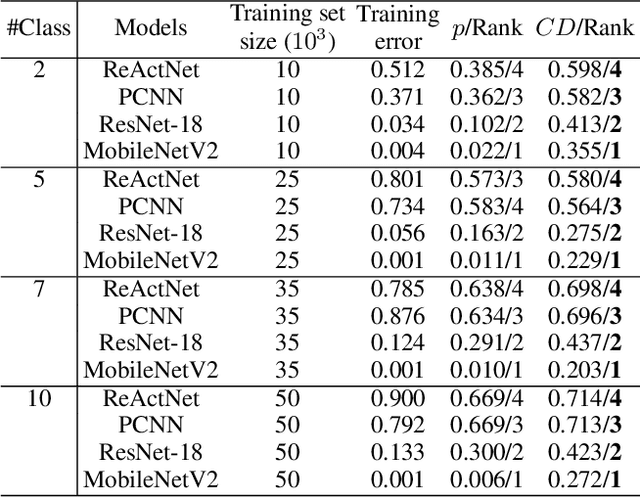
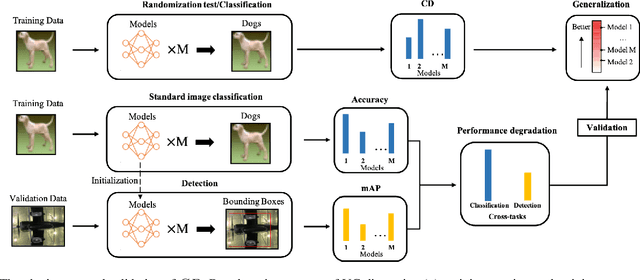
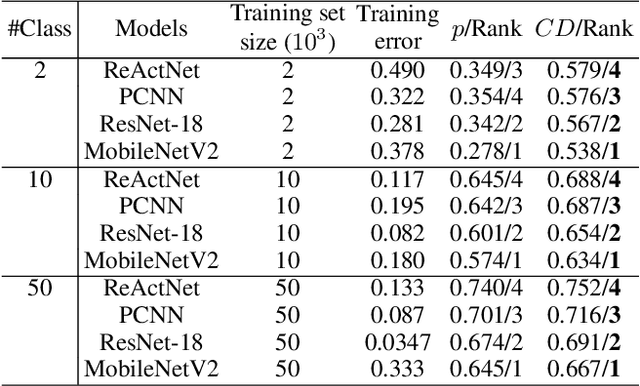
Research on the generalization ability of deep neural networks (DNNs) has recently attracted a great deal of attention. However, due to their complex architectures and large numbers of parameters, measuring the generalization ability of specific DNN models remains an open challenge. In this paper, we propose to use multiple factors to measure and rank the relative generalization of DNNs based on a new concept of confidence dimension (CD). Furthermore, we provide a feasible framework in our CD to theoretically calculate the upper bound of generalization based on the conventional Vapnik-Chervonenk dimension (VC-dimension) and Hoeffding's inequality. Experimental results on image classification and object detection demonstrate that our CD can reflect the relative generalization ability for different DNNs. In addition to full-precision DNNs, we also analyze the generalization ability of binary neural networks (BNNs), whose generalization ability remains an unsolved problem. Our CD yields a consistent and reliable measure and ranking for both full-precision DNNs and BNNs on all the tasks.
Coarse-to-Fine Embedded PatchMatch and Multi-Scale Dynamic Aggregation for Reference-based Super-Resolution
Jan 12, 2022
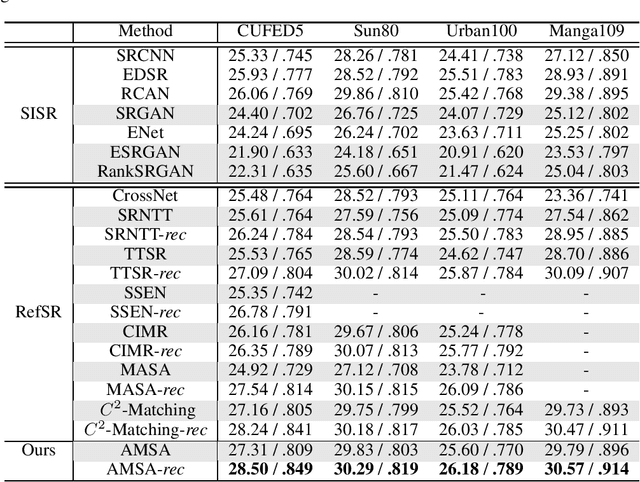
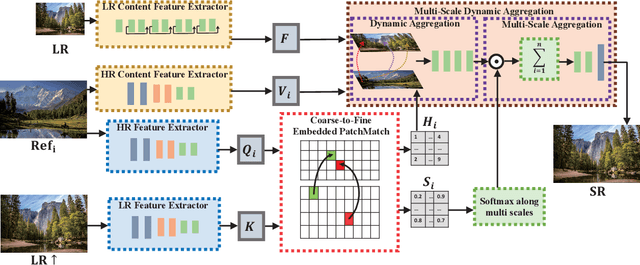
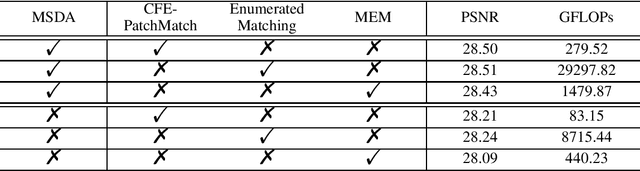
Reference-based super-resolution (RefSR) has made significant progress in producing realistic textures using an external reference (Ref) image. However, existing RefSR methods obtain high-quality correspondence matchings consuming quadratic computation resources with respect to the input size, limiting its application. Moreover, these approaches usually suffer from scale misalignments between the low-resolution (LR) image and Ref image. In this paper, we propose an Accelerated Multi-Scale Aggregation network (AMSA) for Reference-based Super-Resolution, including Coarse-to-Fine Embedded PatchMatch (CFE-PatchMatch) and Multi-Scale Dynamic Aggregation (MSDA) module. To improve matching efficiency, we design a novel Embedded PatchMacth scheme with random samples propagation, which involves end-to-end training with asymptotic linear computational cost to the input size. To further reduce computational cost and speed up convergence, we apply the coarse-to-fine strategy on Embedded PatchMacth constituting CFE-PatchMatch. To fully leverage reference information across multiple scales and enhance robustness to scale misalignment, we develop the MSDA module consisting of Dynamic Aggregation and Multi-Scale Aggregation. The Dynamic Aggregation corrects minor scale misalignment by dynamically aggregating features, and the Multi-Scale Aggregation brings robustness to large scale misalignment by fusing multi-scale information. Experimental results show that the proposed AMSA achieves superior performance over state-of-the-art approaches on both quantitative and qualitative evaluations.
Uncertainty Estimation in Medical Image Denoising with Bayesian Deep Image Prior
Aug 20, 2020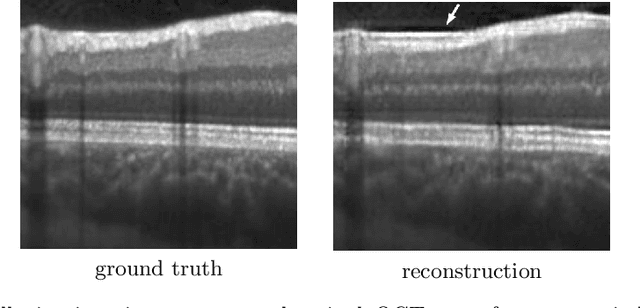


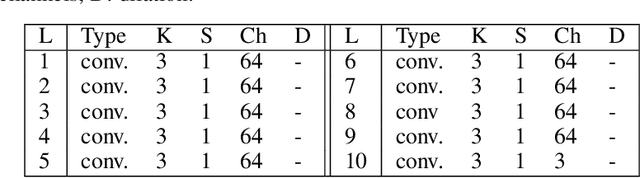
Uncertainty quantification in inverse medical imaging tasks with deep learning has received little attention. However, deep models trained on large data sets tend to hallucinate and create artifacts in the reconstructed output that are not anatomically present. We use a randomly initialized convolutional network as parameterization of the reconstructed image and perform gradient descent to match the observation, which is known as deep image prior. In this case, the reconstruction does not suffer from hallucinations as no prior training is performed. We extend this to a Bayesian approach with Monte Carlo dropout to quantify both aleatoric and epistemic uncertainty. The presented method is evaluated on the task of denoising different medical imaging modalities. The experimental results show that our approach yields well-calibrated uncertainty. That is, the predictive uncertainty correlates with the predictive error. This allows for reliable uncertainty estimates and can tackle the problem of hallucinations and artifacts in inverse medical imaging tasks.
Snapshot HDR Video Construction Using Coded Mask
Dec 05, 2021
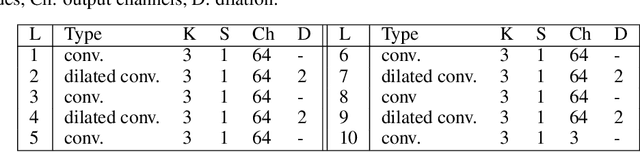
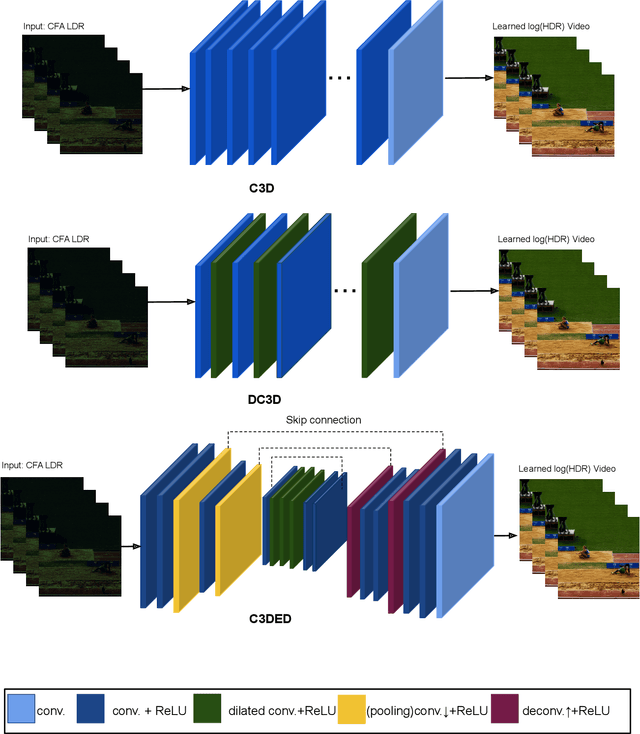
This paper study the reconstruction of High Dynamic Range (HDR) video from snapshot-coded LDR video. Constructing an HDR video requires restoring the HDR values for each frame and maintaining the consistency between successive frames. HDR image acquisition from single image capture, also known as snapshot HDR imaging, can be achieved in several ways. For example, the reconfigurable snapshot HDR camera is realized by introducing an optical element into the optical stack of the camera; by placing a coded mask at a small standoff distance in front of the sensor. High-quality HDR image can be recovered from the captured coded image using deep learning methods. This study utilizes 3D-CNNs to perform a joint demosaicking, denoising, and HDR video reconstruction from coded LDR video. We enforce more temporally consistent HDR video reconstruction by introducing a temporal loss function that considers the short-term and long-term consistency. The obtained results are promising and could lead to affordable HDR video capture using conventional cameras.
On Robust Classification using Contractive Hamiltonian Neural ODEs
Mar 22, 2022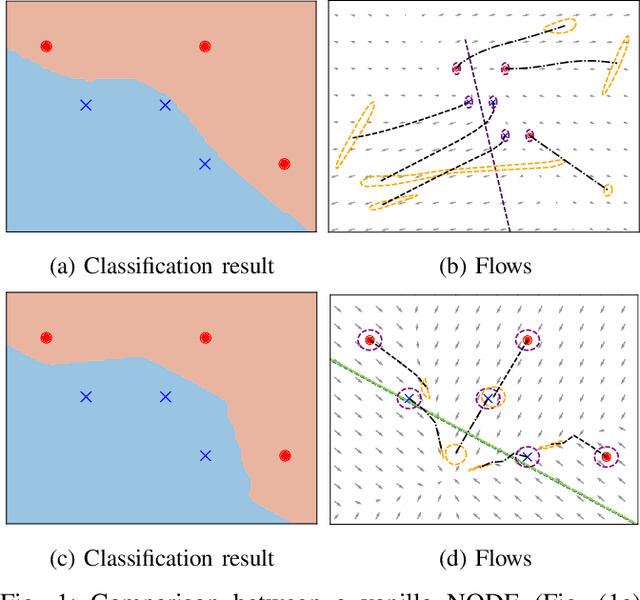

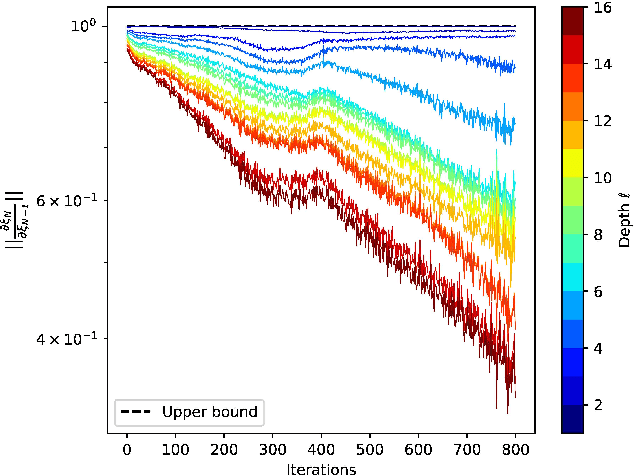
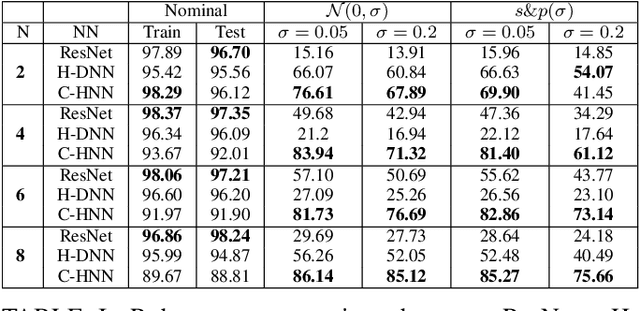
Deep neural networks can be fragile and sensitive to small input perturbations that might cause a significant change in the output. In this paper, we employ contraction theory to improve the robustness of neural ODEs (NODEs). A dynamical system is contractive if all solutions with different initial conditions converge to each other asymptotically. As a consequence, perturbations in initial conditions become less and less relevant over time. Since in NODEs, the input data corresponds to the initial condition of dynamical systems, we show contractivity can mitigate the effect of input perturbations. More precisely, inspired by NODEs with Hamiltonian dynamics, we propose a class of contractive Hamiltonian NODEs (CH-NODEs). By properly tuning a scalar parameter, CH-NODEs ensure contractivity by design and can be trained using standard backpropagation and gradient descent algorithms. Moreover, CH-NODEs enjoy built-in guarantees of non-exploding gradients, which ensures a well-posed training process. Finally, we demonstrate the robustness of CH-NODEs on the MNIST image classification problem with noisy test datasets.