 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Transfer Learning for Estimation of Pendubot Angular Position Using Deep Neural Networks
Jan 29, 2022
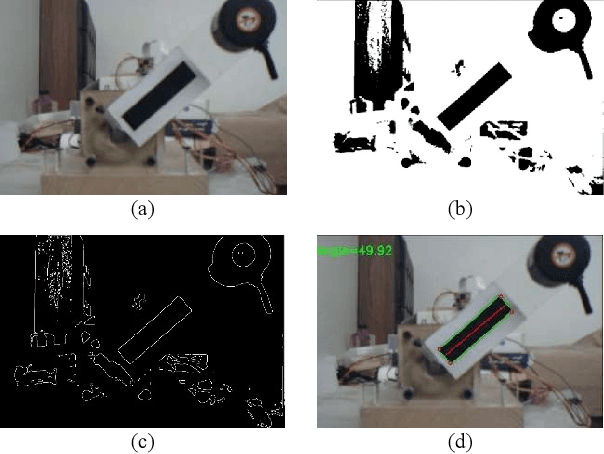

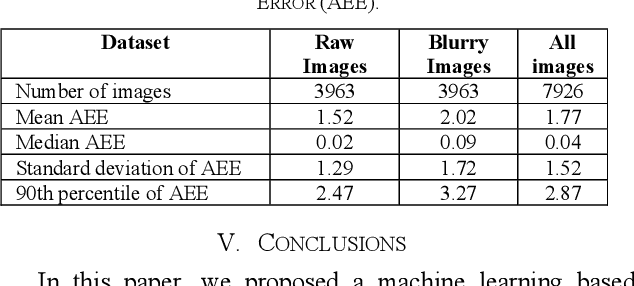
In this paper, a machine learning based approach is introduced to estimate Pendubot angular position from its captured images. Initially, a baseline algorithm is introduced to estimate the angle using conventional image processing technique. The baseline algorithm performs well for the cases that the Pendubot is not moving fast. However, when moving quickly due to a free fall, the Pendubot appears as a blurred object in the captured image in a way that the baseline algorithm fails to estimate the angle. Consequently, a Deep Neural Network (DNN) based algorithm is introduced to cope with this challenge. The approach relies on the concept of transfer learning to allow the training of the DNN on a very small fine-tuning dataset. The base algorithm is used to create the ground truth labels of the fine-tuning dataset. Experimental results on the held-out evaluation set show that the proposed approach achieves a median absolute error of 0.02 and 0.06 degrees for the sharp and blurry images respectively.
HiMODE: A Hybrid Monocular Omnidirectional Depth Estimation Model
Apr 11, 2022
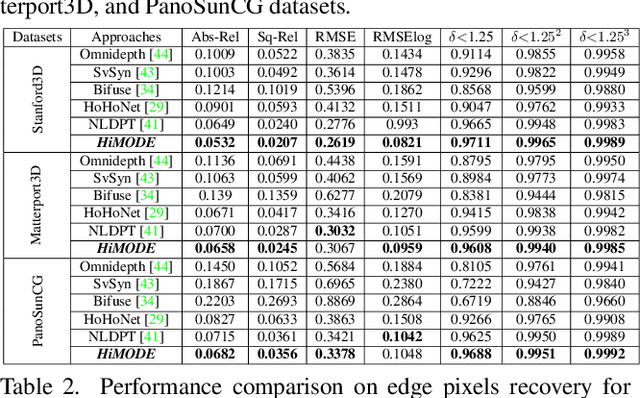
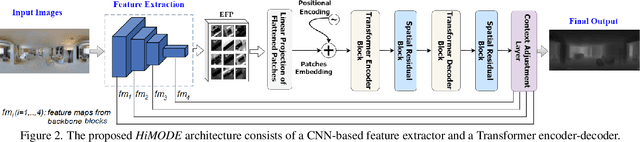
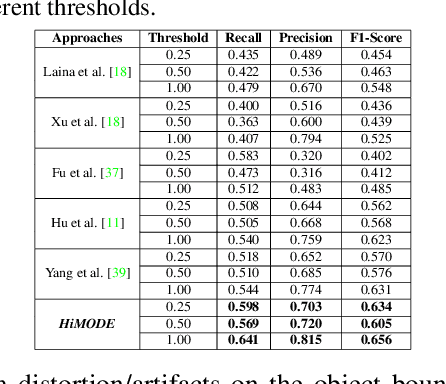
Monocular omnidirectional depth estimation is receiving considerable research attention due to its broad applications for sensing 360{\deg} surroundings. Existing approaches in this field suffer from limitations in recovering small object details and data lost during the ground-truth depth map acquisition. In this paper, a novel monocular omnidirectional depth estimation model, namely HiMODE is proposed based on a hybrid CNN+Transformer (encoder-decoder) architecture whose modules are efficiently designed to mitigate distortion and computational cost, without performance degradation. Firstly, we design a feature pyramid network based on the HNet block to extract high-resolution features near the edges. The performance is further improved, benefiting from a self and cross attention layer and spatial/temporal patches in the Transformer encoder and decoder, respectively. Besides, a spatial residual block is employed to reduce the number of parameters. By jointly passing the deep features extracted from an input image at each backbone block, along with the raw depth maps predicted by the transformer encoder-decoder, through a context adjustment layer, our model can produce resulting depth maps with better visual quality than the ground-truth. Comprehensive ablation studies demonstrate the significance of each individual module. Extensive experiments conducted on three datasets; Stanford3D, Matterport3D, and SunCG, demonstrate that HiMODE can achieve state-of-the-art performance for 360{\deg} monocular depth estimation.
A Benchmark and Baseline for Language-Driven Image Editing
Oct 05, 2020

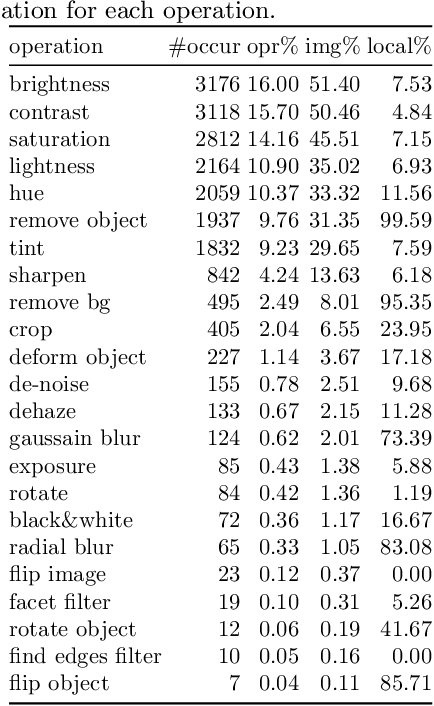
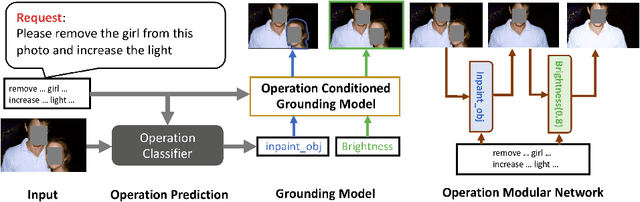
Language-driven image editing can significantly save the laborious image editing work and be friendly to the photography novice. However, most similar work can only deal with a specific image domain or can only do global retouching. To solve this new task, we first present a new language-driven image editing dataset that supports both local and global editing with editing operation and mask annotations. Besides, we also propose a baseline method that fully utilizes the annotation to solve this problem. Our new method treats each editing operation as a sub-module and can automatically predict operation parameters. Not only performing well on challenging user data, but such an approach is also highly interpretable. We believe our work, including both the benchmark and the baseline, will advance the image editing area towards a more general and free-form level.
Few-Shot Object Detection with Fully Cross-Transformer
Mar 28, 2022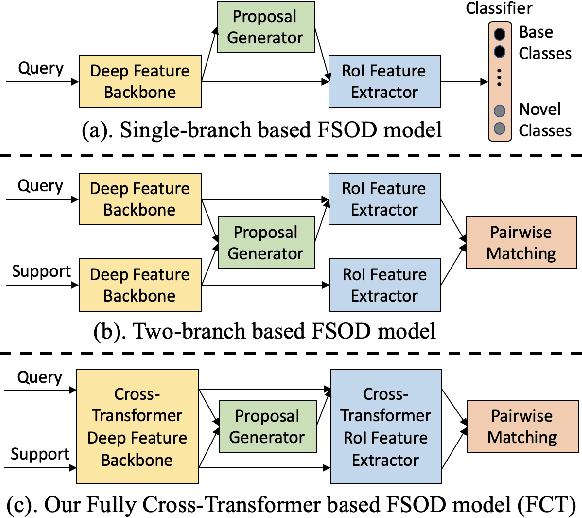
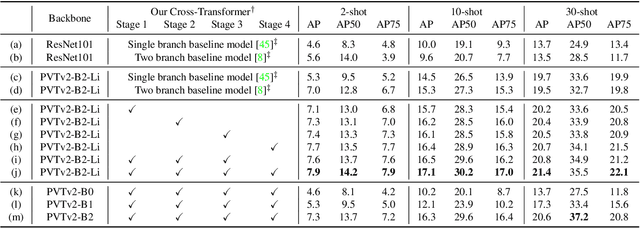
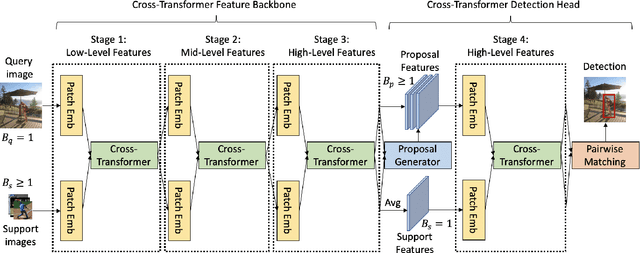
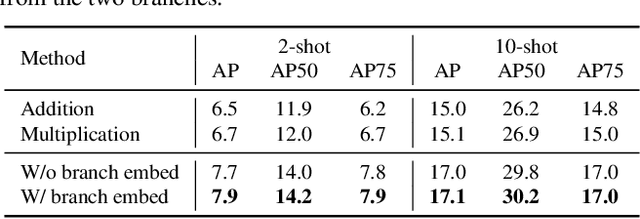
Few-shot object detection (FSOD), with the aim to detect novel objects using very few training examples, has recently attracted great research interest in the community. Metric-learning based methods have been demonstrated to be effective for this task using a two-branch based siamese network, and calculate the similarity between image regions and few-shot examples for detection. However, in previous works, the interaction between the two branches is only restricted in the detection head, while leaving the remaining hundreds of layers for separate feature extraction. Inspired by the recent work on vision transformers and vision-language transformers, we propose a novel Fully Cross-Transformer based model (FCT) for FSOD by incorporating cross-transformer into both the feature backbone and detection head. The asymmetric-batched cross-attention is proposed to aggregate the key information from the two branches with different batch sizes. Our model can improve the few-shot similarity learning between the two branches by introducing the multi-level interactions. Comprehensive experiments on both PASCAL VOC and MSCOCO FSOD benchmarks demonstrate the effectiveness of our model.
Optimizing Elimination Templates by Greedy Parameter Search
Mar 28, 2022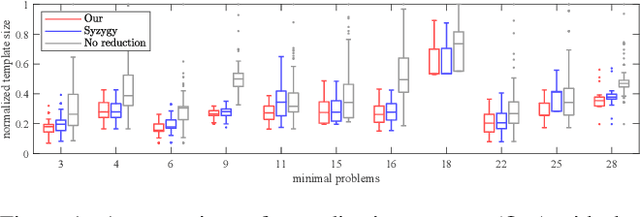
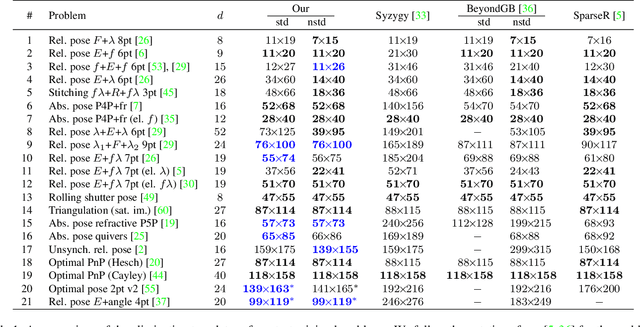
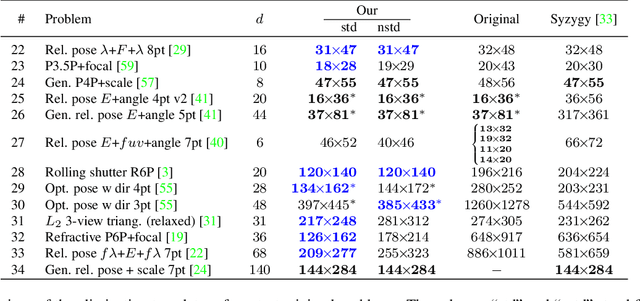
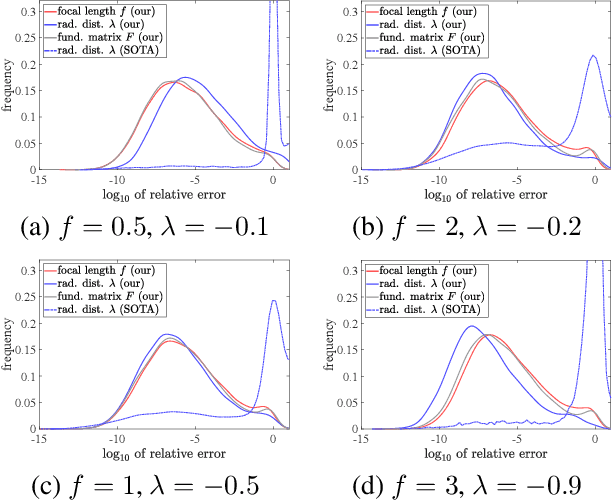
We propose a new method for constructing elimination templates for efficient polynomial system solving of minimal problems in structure from motion, image matching, and camera tracking. We first construct a particular affine parameterization of the elimination templates for systems with a finite number of distinct solutions. Then, we use a heuristic greedy optimization strategy over the space of parameters to get a template with a small size. We test our method on 34 minimal problems in computer vision. For all of them, we found the templates either of the same or smaller size compared to the state-of-the-art. For some difficult examples, our templates are, e.g., 2.1, 2.5, 3.8, 6.6 times smaller. For the problem of refractive absolute pose estimation with unknown focal length, we have found a template that is 20 times smaller. Our experiments on synthetic data also show that the new solvers are fast and numerically accurate. We also present a fast and numerically accurate solver for the problem of relative pose estimation with unknown common focal length and radial distortion.
Center-wise Local Image Mixture For Contrastive Representation Learning
Nov 05, 2020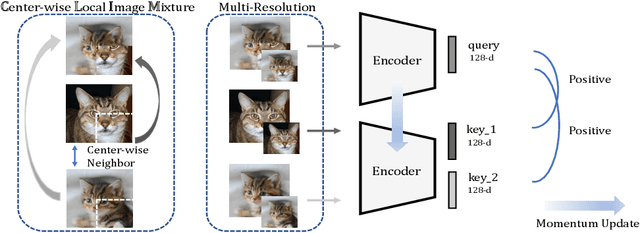
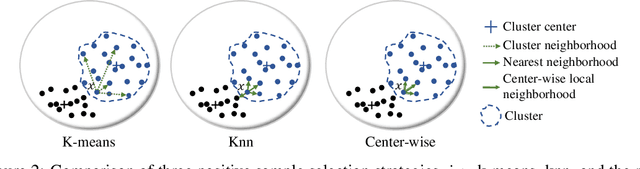
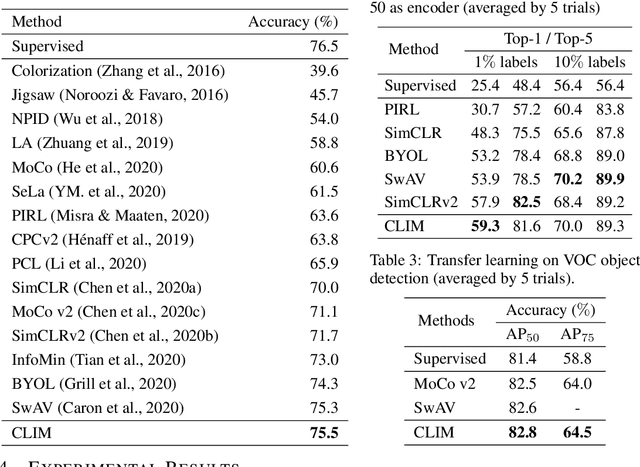
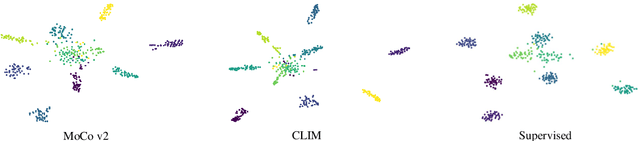
Recent advances in unsupervised representation learning have experienced remarkable progress, especially with the achievements of contrastive learning, which regards each image as well its augmentations as a separate class, while does not consider the semantic similarity among images. This paper proposes a new kind of data augmentation, named Center-wise Local Image Mixture, to expand the neighborhood space of an image. CLIM encourages both local similarity and global aggregation while pulling similar images. This is achieved by searching local similar samples of an image, and only selecting images that are closer to the corresponding cluster center, which we denote as center-wise local selection. As a result, similar representations are progressively approaching the clusters, while do not break the local similarity. Furthermore, image mixture is used as a smoothing regularization to avoid overconfidence on the selected samples. Besides, we introduce multi-resolution augmentation, which enables the representation to be scale invariant. Integrating the two augmentations produces better feature representation on several unsupervised benchmarks. Notably, we reach 75.5% top-1 accuracy with linear evaluation over ResNet-50, and 59.3% top-1 accuracy when fine-tuned with only 1% labels, as well as consistently outperforming supervised pretraining on several downstream transfer tasks.
PetroGAN: A novel GAN-based approach to generate realistic, label-free petrographic datasets
Apr 07, 2022
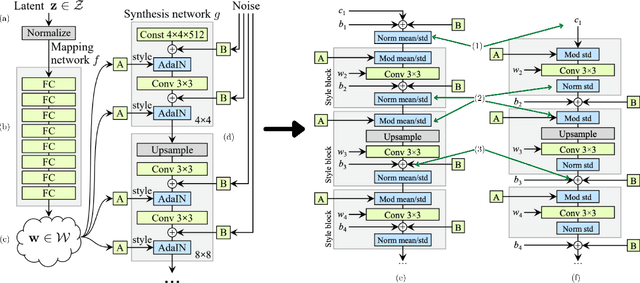


Deep learning architectures have enriched data analytics in the geosciences, complementing traditional approaches to geological problems. Although deep learning applications in geosciences show encouraging signs, the actual potential remains untapped. This is primarily because geological datasets, particularly petrography, are limited, time-consuming, and expensive to obtain, requiring in-depth knowledge to provide a high-quality labeled dataset. We approached these issues by developing a novel deep learning framework based on generative adversarial networks (GANs) to create the first realistic synthetic petrographic dataset. The StyleGAN2 architecture is selected to allow robust replication of statistical and esthetical characteristics, and improving the internal variance of petrographic data. The training dataset consists of 10070 images of rock thin sections both in plane- and cross-polarized light. The algorithm trained for 264 GPU hours and reached a state-of-the-art Fr\'echet Inception Distance (FID) score of 12.49 for petrographic images. We further observed the FID values vary with lithology type and image resolution. Our survey established that subject matter experts found the generated images were indistinguishable from real images. This study highlights that GANs are a powerful method for generating realistic synthetic data, experimenting with the latent space, and as a future tool for self-labelling, reducing the effort of creating geological datasets.
Adversarial Machine Learning Attacks Against Video Anomaly Detection Systems
Apr 07, 2022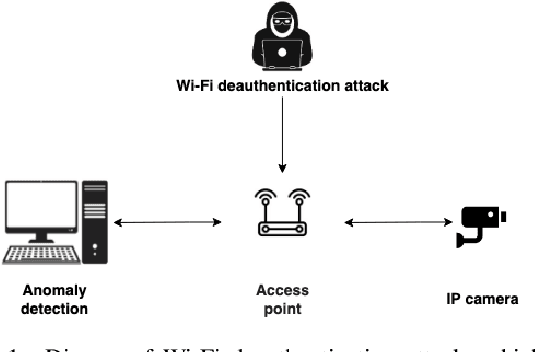
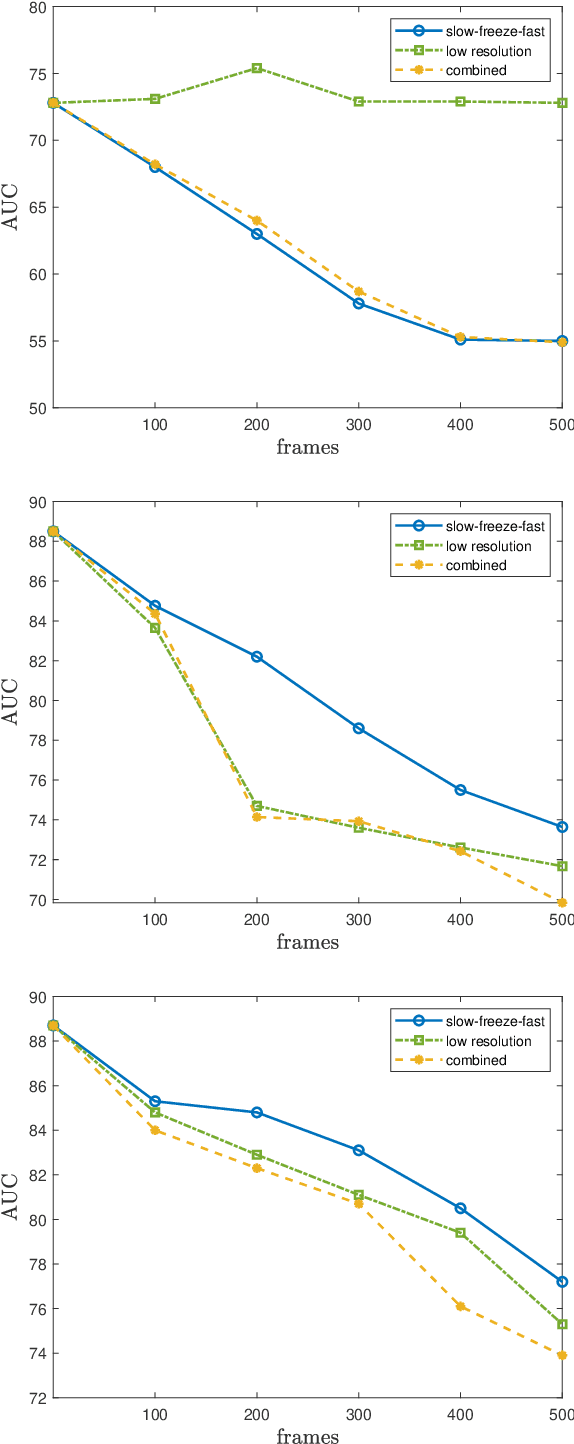
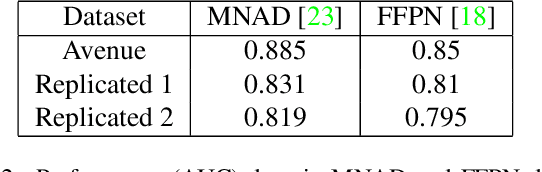
Anomaly detection in videos is an important computer vision problem with various applications including automated video surveillance. Although adversarial attacks on image understanding models have been heavily investigated, there is not much work on adversarial machine learning targeting video understanding models and no previous work which focuses on video anomaly detection. To this end, we investigate an adversarial machine learning attack against video anomaly detection systems, that can be implemented via an easy-to-perform cyber-attack. Since surveillance cameras are usually connected to the server running the anomaly detection model through a wireless network, they are prone to cyber-attacks targeting the wireless connection. We demonstrate how Wi-Fi deauthentication attack, a notoriously easy-to-perform and effective denial-of-service (DoS) attack, can be utilized to generate adversarial data for video anomaly detection systems. Specifically, we apply several effects caused by the Wi-Fi deauthentication attack on video quality (e.g., slow down, freeze, fast forward, low resolution) to the popular benchmark datasets for video anomaly detection. Our experiments with several state-of-the-art anomaly detection models show that the attackers can significantly undermine the reliability of video anomaly detection systems by causing frequent false alarms and hiding physical anomalies from the surveillance system.
Curriculum Learning for Goal-Oriented Semantic Communications with a Common Language
Apr 21, 2022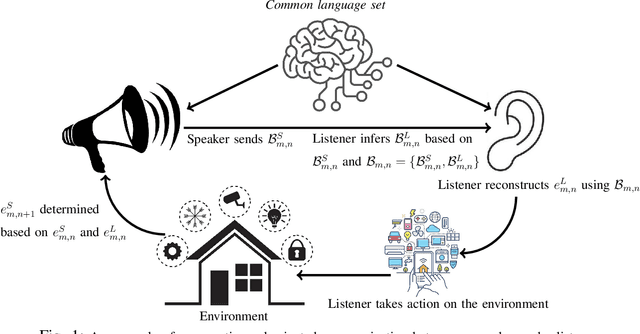
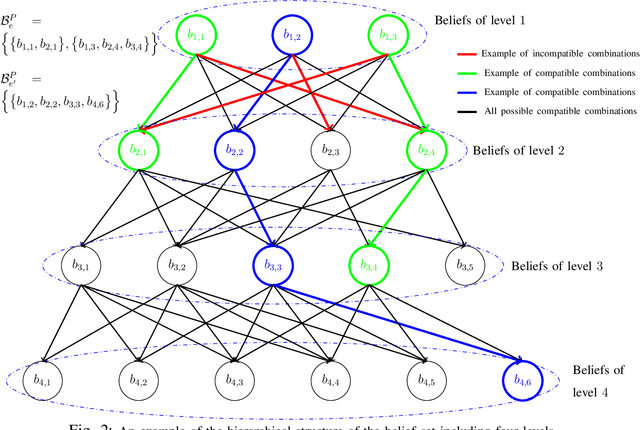
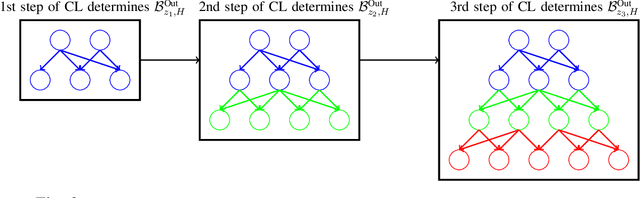
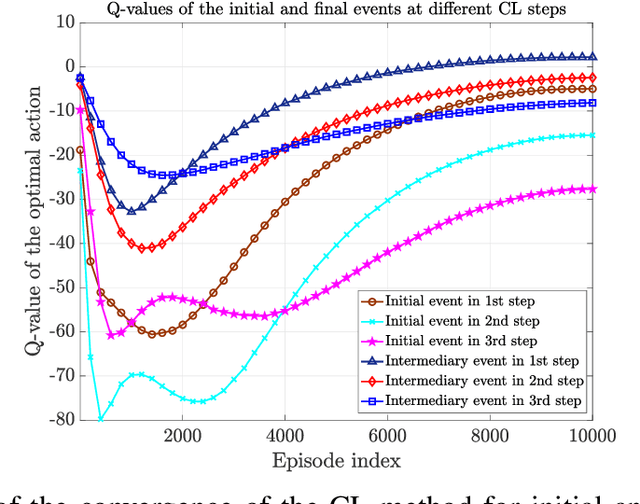
Goal-oriented semantic communication will be a pillar of next-generation wireless networks. Despite significant recent efforts in this area, most prior works are focused on specific data types (e.g., image or audio), and they ignore the goal and effectiveness aspects of semantic transmissions. In contrast, in this paper, a holistic goal-oriented semantic communication framework is proposed to enable a speaker and a listener to cooperatively execute a set of sequential tasks in a dynamic environment. A common language based on a hierarchical belief set is proposed to enable semantic communications between speaker and listener. The speaker, acting as an observer of the environment, utilizes the beliefs to transmit an initial description of its observation (called event) to the listener. The listener is then able to infer on the transmitted description and complete it by adding related beliefs to the transmitted beliefs of the speaker. As such, the listener reconstructs the observed event based on the completed description, and it then takes appropriate action in the environment based on the reconstructed event. An optimization problem is defined to determine the perfect and abstract description of the events while minimizing the transmission and inference costs with constraints on the task execution time and belief efficiency. Then, a novel bottom-up curriculum learning (CL) framework based on reinforcement learning is proposed to solve the optimization problem and enable the speaker and listener to gradually identify the structure of the belief set and the perfect and abstract description of the events. Simulation results show that the proposed CL method outperforms traditional RL in terms of convergence time, task execution cost and time, reliability, and belief efficiency.
A Survey on Intrinsic Images: Delving Deep Into Lambert and Beyond
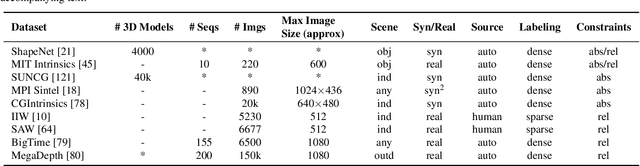
Dec 07, 2021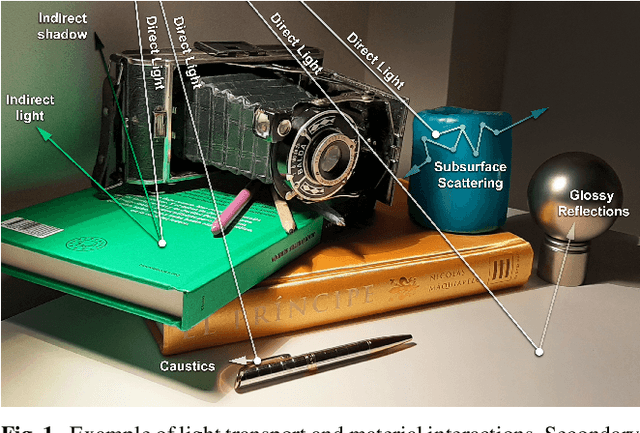
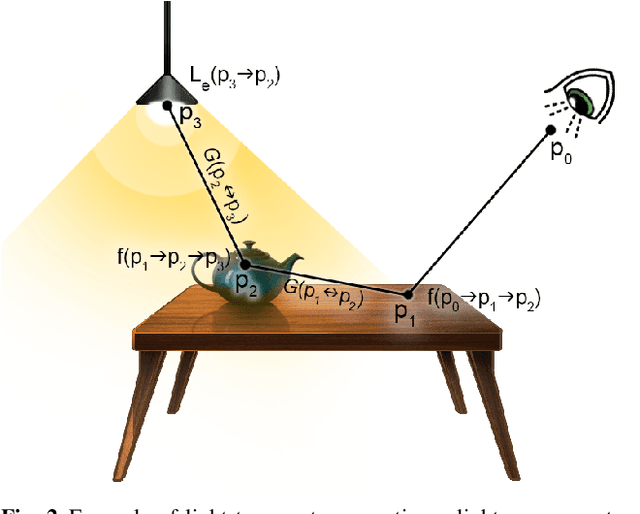
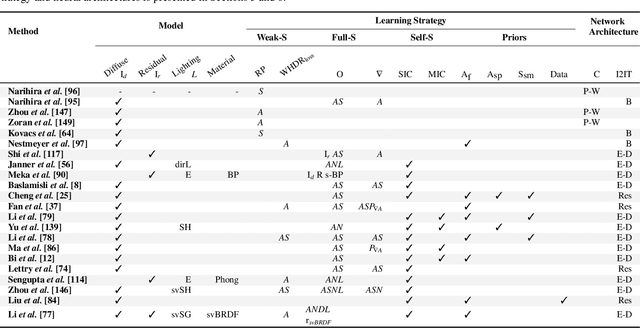
Intrinsic imaging or intrinsic image decomposition has traditionally been described as the problem of decomposing an image into two layers: a reflectance, the albedo invariant color of the material; and a shading, produced by the interaction between light and geometry. Deep learning techniques have been broadly applied in recent years to increase the accuracy of those separations. In this survey, we overview those results in context of well-known intrinsic image data sets and relevant metrics used in the literature, discussing their suitability to predict a desirable intrinsic image decomposition. Although the Lambertian assumption is still a foundational basis for many methods, we show that there is increasing awareness on the potential of more sophisticated physically-principled components of the image formation process, that is, optically accurate material models and geometry, and more complete inverse light transport estimations. We classify these methods in terms of the type of decomposition, considering the priors and models used, as well as the learning architecture and methodology driving the decomposition process. We also provide insights about future directions for research, given the recent advances in neural, inverse and differentiable rendering techniques.