 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly Guided and Autoregressive Beamformer Parameterization for Generalizable Moving Speaker Extraction in Higher-Order Ambisonics
Jul 05, 2026Linear spatial filters (beamformers) enable robust, generalizable and interpretable speech enhancement with performance guarantees under ideal parameterization. Modern beamformers are often parameterized by deep neural networks, whose performance degrades in dynamic scenarios with multiple moving speakers of unknown directions. We propose a data-driven beamforming pipeline, which only requires an estimate of the target's initial direction. Building on a higher-order ambisonics representation, we show that neural temporal-spectral processing can be decoupled from linear spatial processing, and thereby achieve generalizable and array-agnostic enhancement. By incorporating autoregression into a frame-wise causal framework, we maintain consistent performance throughout fast speaker motion and long recordings. Evaluation on synthetic data demonstrates robust enhancement under challenging conditions with closely spaced and crossing speakers. Real-world recordings in a dynamic office meeting scenario complement these findings and show generalizability across varying ambisonics orders.
Your U-Net Dereverberation Model is Secretly an RIR Encoder
Jun 08, 2026In this work, we analyze the ability of NCSN++ U-Net based audio dereverberation models to capture global room characteristics in their intermediate representations. Through an empirical study of both a state-of-the-art diffusion-based model and a discriminative counterpart, we show that deeper layers encode structured room impulse response (RIR)-dependent embeddings. Moreover, the discriminative ability of this implicit room representation correlates with dereverberation performance across objective metrics. Motivated by this observation, we propose a training strategy that explicitly conditions the network on pre-trained RIR embeddings, obtained via self-supervised contrastive learning. Incorporating RIR conditioning improves representation quality, accelerates convergence, and enhances dereverberation performance, while significantly reducing the number of reverse diffusion steps required by the diffusion-based model during inference.
Bone-conduction Guided Multimodal Speech Enhancement with Conditional Diffusion Models
Jan 18, 2026Single-channel speech enhancement models face significant performance degradation in extremely noisy environments. While prior work has shown that complementary bone-conducted speech can guide enhancement, effective integration of this noise-immune modality remains a challenge. This paper introduces a novel multimodal speech enhancement framework that integrates bone-conduction sensors with air-conducted microphones using a conditional diffusion model. Our proposed model significantly outperforms previously established multimodal techniques and a powerful diffusion-based single-modal baseline across a wide range of acoustic conditions.
Transfer Learning for Estimation of Pendubot Angular Position Using Deep Neural Networks
Jan 29, 2022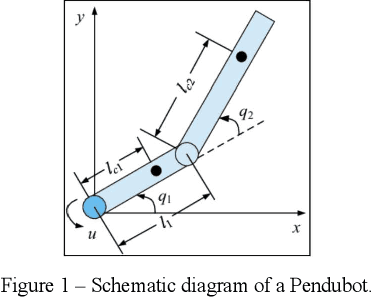
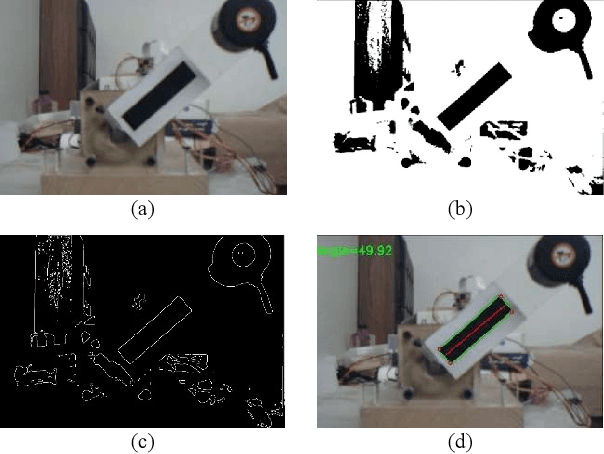

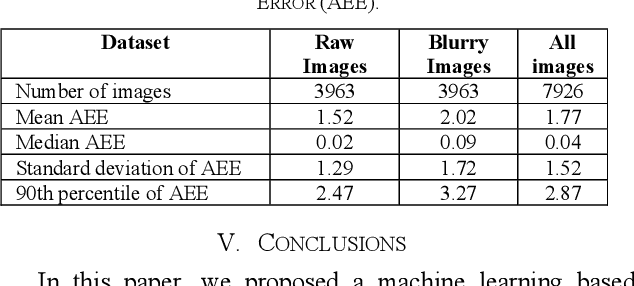
In this paper, a machine learning based approach is introduced to estimate Pendubot angular position from its captured images. Initially, a baseline algorithm is introduced to estimate the angle using conventional image processing technique. The baseline algorithm performs well for the cases that the Pendubot is not moving fast. However, when moving quickly due to a free fall, the Pendubot appears as a blurred object in the captured image in a way that the baseline algorithm fails to estimate the angle. Consequently, a Deep Neural Network (DNN) based algorithm is introduced to cope with this challenge. The approach relies on the concept of transfer learning to allow the training of the DNN on a very small fine-tuning dataset. The base algorithm is used to create the ground truth labels of the fine-tuning dataset. Experimental results on the held-out evaluation set show that the proposed approach achieves a median absolute error of 0.02 and 0.06 degrees for the sharp and blurry images respectively.