 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Web image search engine based on LSH index and CNN Resnet50
Aug 20, 2021
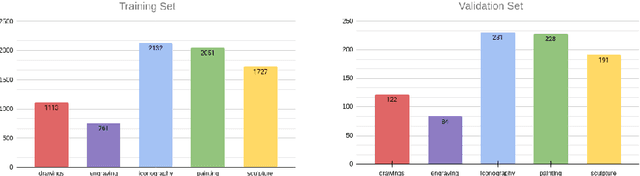

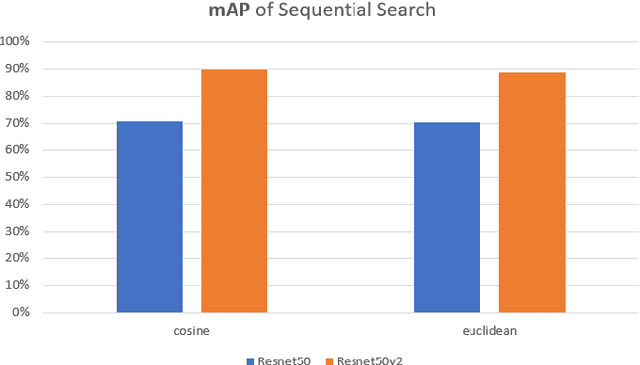
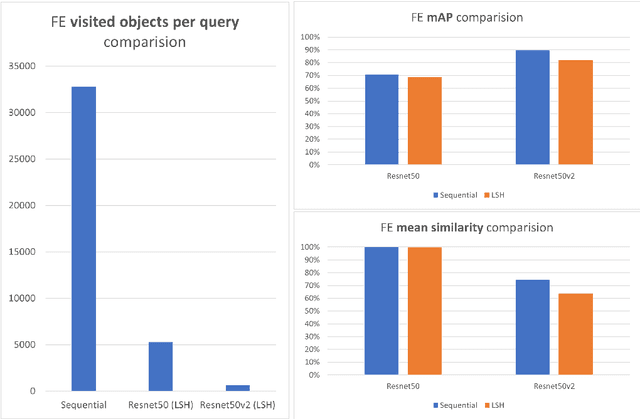
To implement a good Content Based Image Retrieval (CBIR) system, it is essential to adopt efficient search methods. One way to achieve this results is by exploiting approximate search techniques. In fact, when we deal with very large collections of data, using an exact search method makes the system very slow. In this project, we adopt the Locality Sensitive Hashing (LSH) index to implement a CBIR system that allows us to perform fast similarity search on deep features. Specifically, we exploit transfer learning techniques to extract deep features from images; this phase is done using two famous Convolutional Neural Networks (CNNs) as features extractors: Resnet50 and Resnet50v2, both pre-trained on ImageNet. Then we try out several fully connected deep neural networks, built on top of both of the previously mentioned CNNs in order to fine-tuned them on our dataset. In both of previous cases, we index the features within our LSH index implementation and within a sequential scan, to better understand how much the introduction of the index affects the results. Finally, we carry out a performance analysis: we evaluate the relevance of the result set, computing the mAP (mean Average Precision) value obtained during the different experiments with respect to the number of done comparison and varying the hyper-parameter values of the LSH index.
Indoor Navigation Assistance for Visually Impaired People via Dynamic SLAM and Panoptic Segmentation with an RGB-D Sensor
Apr 03, 2022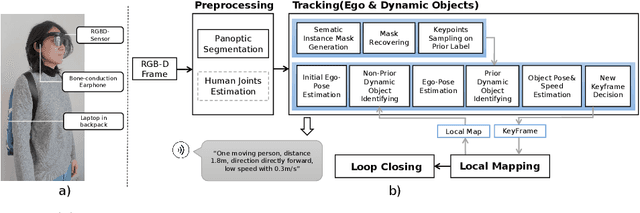


Exploring an unfamiliar indoor environment and avoiding obstacles is challenging for visually impaired people. Currently, several approaches achieve the avoidance of static obstacles based on the mapping of indoor scenes. To solve the issue of distinguishing dynamic obstacles, we propose an assistive system with an RGB-D sensor to detect dynamic information of a scene. Once the system captures an image, panoptic segmentation is performed to obtain the prior dynamic object information. With sparse feature points extracted from images and the depth information, poses of the user can be estimated. After the ego-motion estimation, the dynamic object can be identified and tracked. Then, poses and speed of tracked dynamic objects can be estimated, which are passed to the users through acoustic feedback.
Perception Consistency Ultrasound Image Super-resolution via Self-supervised CycleGAN
Dec 28, 2020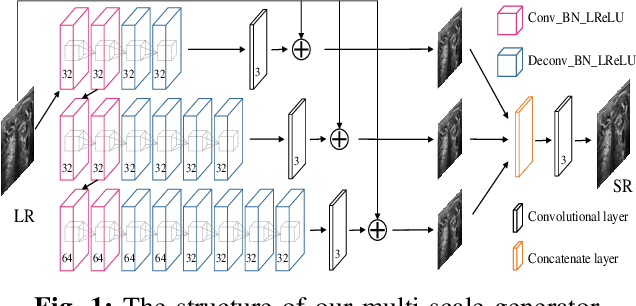
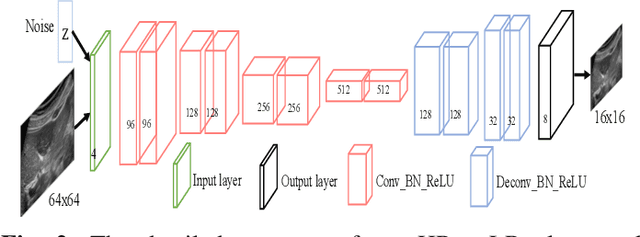
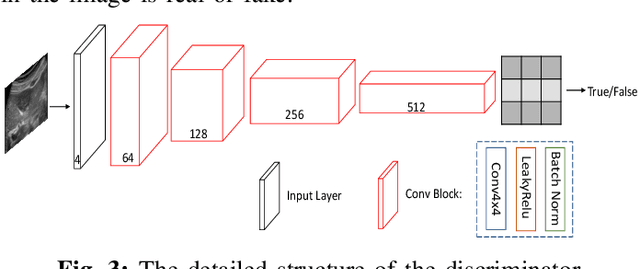
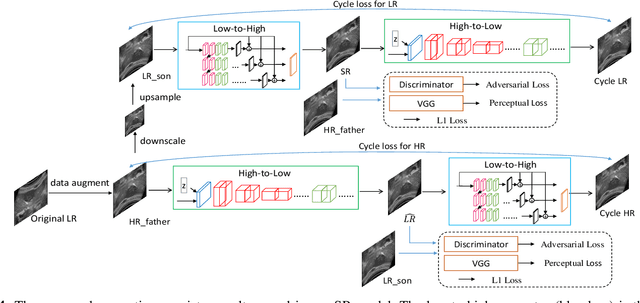
Due to the limitations of sensors, the transmission medium and the intrinsic properties of ultrasound, the quality of ultrasound imaging is always not ideal, especially its low spatial resolution. To remedy this situation, deep learning networks have been recently developed for ultrasound image super-resolution (SR) because of the powerful approximation capability. However, most current supervised SR methods are not suitable for ultrasound medical images because the medical image samples are always rare, and usually, there are no low-resolution (LR) and high-resolution (HR) training pairs in reality. In this work, based on self-supervision and cycle generative adversarial network (CycleGAN), we propose a new perception consistency ultrasound image super-resolution (SR) method, which only requires the LR ultrasound data and can ensure the re-degenerated image of the generated SR one to be consistent with the original LR image, and vice versa. We first generate the HR fathers and the LR sons of the test ultrasound LR image through image enhancement, and then make full use of the cycle loss of LR-SR-LR and HR-LR-SR and the adversarial characteristics of the discriminator to promote the generator to produce better perceptually consistent SR results. The evaluation of PSNR/IFC/SSIM, inference efficiency and visual effects under the benchmark CCA-US and CCA-US datasets illustrate our proposed approach is effective and superior to other state-of-the-art methods.
Unsupervised Novel View Synthesis from a Single Image
Feb 05, 2021

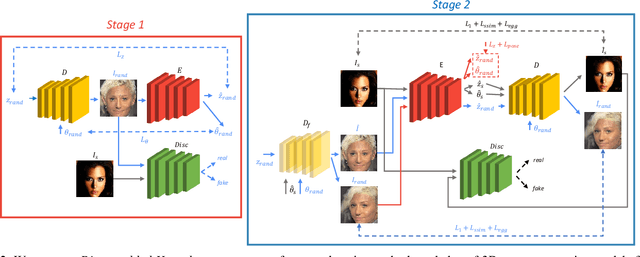
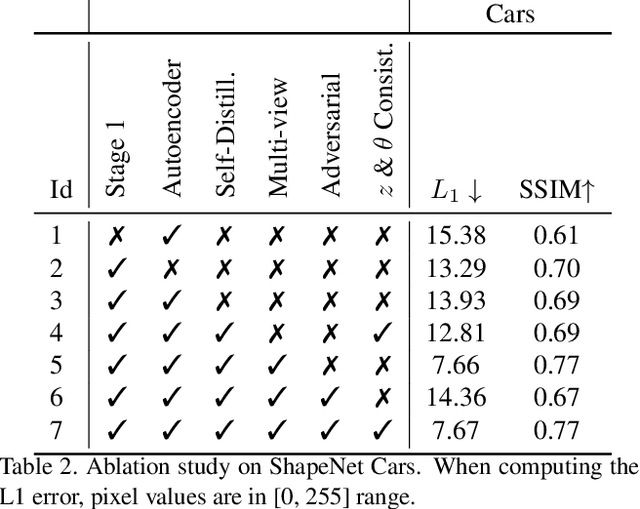
Novel view synthesis from a single image aims at generating novel views from a single input image of an object. Several works recently achieved remarkable results, though require some form of multi-view supervision at training time, therefore limiting their deployment in real scenarios. This work aims at relaxing this assumption enabling training of conditional generative model for novel view synthesis in a completely unsupervised manner. We first pre-train a purely generative decoder model using a GAN formulation while at the same time training an encoder network to invert the mapping from latent code to images. Then we swap encoder and decoder and train the network as a conditioned GAN with a mixture of auto-encoder-like objective and self-distillation. At test time, given a view of an object, our model first embeds the image content in a latent code and regresses its pose w.r.t. a canonical reference system, then generates novel views of it by keeping the code and varying the pose. We show that our framework achieves results comparable to the state of the art on ShapeNet and that it can be employed on unconstrained collections of natural images, where no competing method can be trained.
Beyond Deterministic Translation for Unsupervised Domain Adaptation
Feb 15, 2022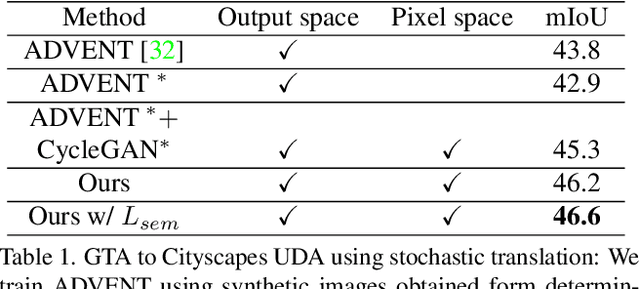


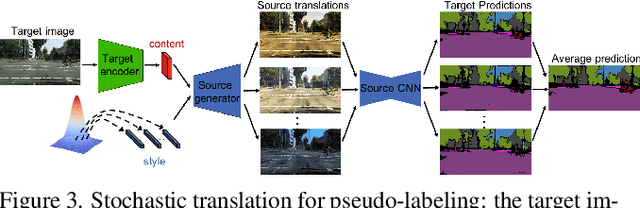
In this work we challenge the common approach of using a one-to-one mapping ('translation') between the source and target domains in unsupervised domain adaptation (UDA). Instead, we rely on stochastic translation to capture inherent translation ambiguities. This allows us to (i) train more accurate target networks by generating multiple outputs conditioned on the same source image, leveraging both accurate translation and data augmentation for appearance variability, (ii) impute robust pseudo-labels for the target data by averaging the predictions of a source network on multiple translated versions of a single target image and (iii) train and ensemble diverse networks in the target domain by modulating the degree of stochasticity in the translations. We report improvements over strong recent baselines, leading to state-of-the-art UDA results on two challenging semantic segmentation benchmarks.
PaddleSeg: A High-Efficient Development Toolkit for Image Segmentation
Jan 15, 2021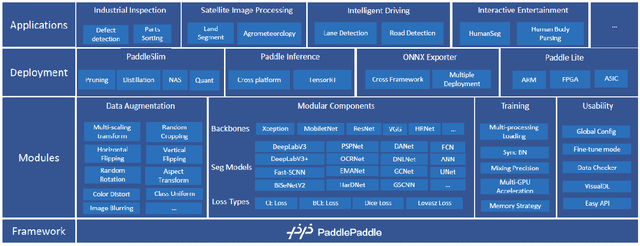
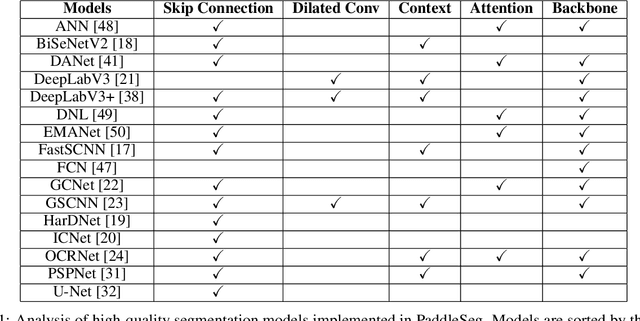

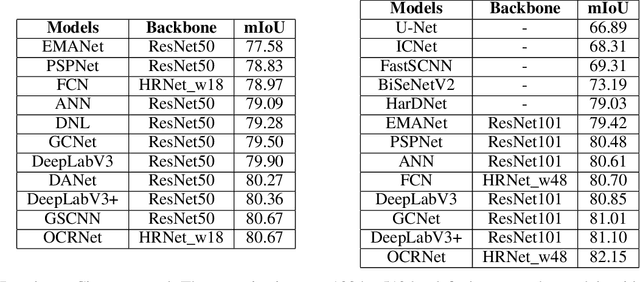
Image Segmentation plays an essential role in computer vision and image processing with various applications from medical diagnosis to autonomous car driving. A lot of segmentation algorithms have been proposed for addressing specific problems. In recent years, the success of deep learning techniques has tremendously influenced a wide range of computer vision areas, and the modern approaches of image segmentation based on deep learning are becoming prevalent. In this article, we introduce a high-efficient development toolkit for image segmentation, named PaddleSeg. The toolkit aims to help both developers and researchers in the whole process of designing segmentation models, training models, optimizing performance and inference speed, and deploying models. Currently, PaddleSeg supports around 20 popular segmentation models and more than 50 pre-trained models from real-time and high-accuracy levels. With modular components and backbone networks, users can easily build over one hundred models for different requirements. Furthermore, we provide comprehensive benchmarks and evaluations to show that these segmentation algorithms trained on our toolkit have more competitive accuracy. Also, we provide various real industrial applications and practical cases based on PaddleSeg. All codes and examples of PaddleSeg are available at https://github.com/PaddlePaddle/PaddleSeg.
Modeling Coreference Relations in Visual Dialog
Mar 06, 2022
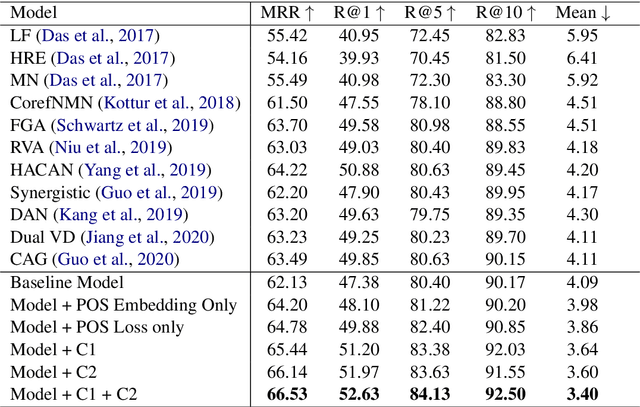

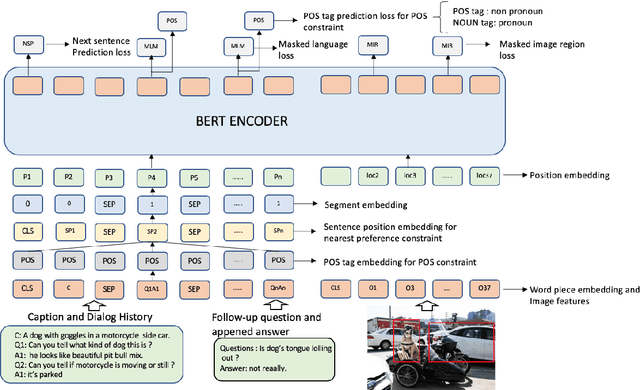
Visual dialog is a vision-language task where an agent needs to answer a series of questions grounded in an image based on the understanding of the dialog history and the image. The occurrences of coreference relations in the dialog makes it a more challenging task than visual question-answering. Most previous works have focused on learning better multi-modal representations or on exploring different ways of fusing visual and language features, while the coreferences in the dialog are mainly ignored. In this paper, based on linguistic knowledge and discourse features of human dialog we propose two soft constraints that can improve the model's ability of resolving coreferences in dialog in an unsupervised way. Experimental results on the VisDial v1.0 dataset shows that our model, which integrates two novel and linguistically inspired soft constraints in a deep transformer neural architecture, obtains new state-of-the-art performance in terms of recall at 1 and other evaluation metrics compared to current existing models and this without pretraining on other vision-language datasets. Our qualitative results also demonstrate the effectiveness of the method that we propose.
Self-Supervised Vision Transformers Learn Visual Concepts in Histopathology
Mar 01, 2022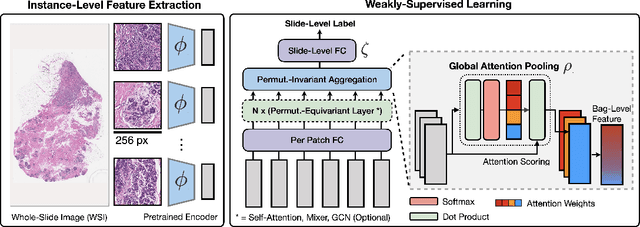
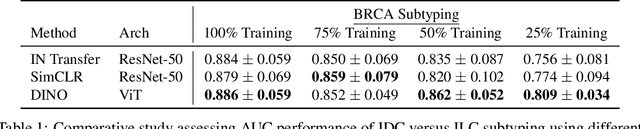
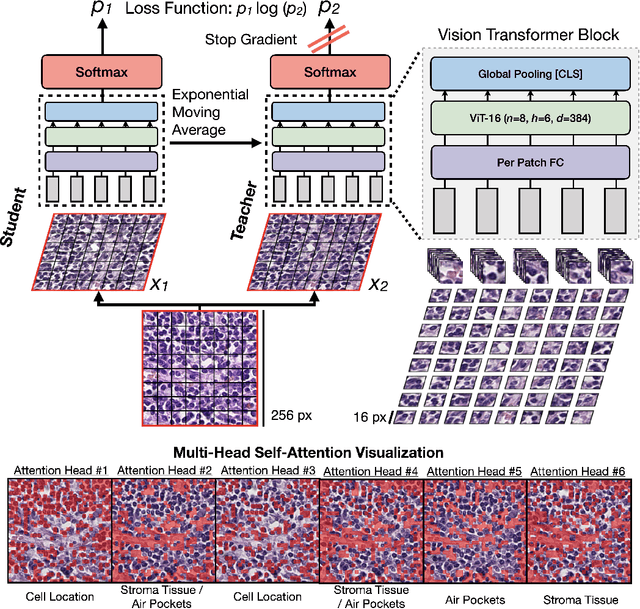
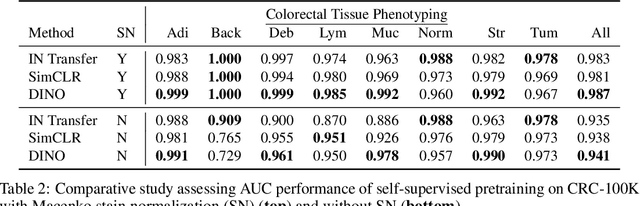
Tissue phenotyping is a fundamental task in learning objective characterizations of histopathologic biomarkers within the tumor-immune microenvironment in cancer pathology. However, whole-slide imaging (WSI) is a complex computer vision in which: 1) WSIs have enormous image resolutions with precludes large-scale pixel-level efforts in data curation, and 2) diversity of morphological phenotypes results in inter- and intra-observer variability in tissue labeling. To address these limitations, current efforts have proposed using pretrained image encoders (transfer learning from ImageNet, self-supervised pretraining) in extracting morphological features from pathology, but have not been extensively validated. In this work, we conduct a search for good representations in pathology by training a variety of self-supervised models with validation on a variety of weakly-supervised and patch-level tasks. Our key finding is in discovering that Vision Transformers using DINO-based knowledge distillation are able to learn data-efficient and interpretable features in histology images wherein the different attention heads learn distinct morphological phenotypes. We make evaluation code and pretrained weights publicly-available at: https://github.com/Richarizardd/Self-Supervised-ViT-Path.
Length-Controllable Image Captioning
Jul 19, 2020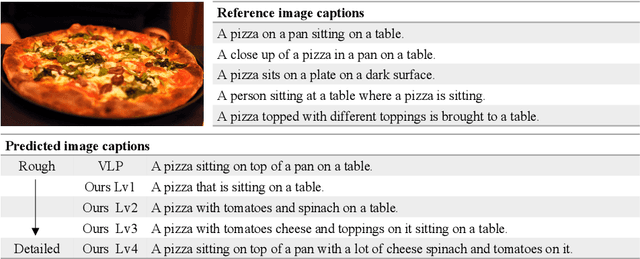
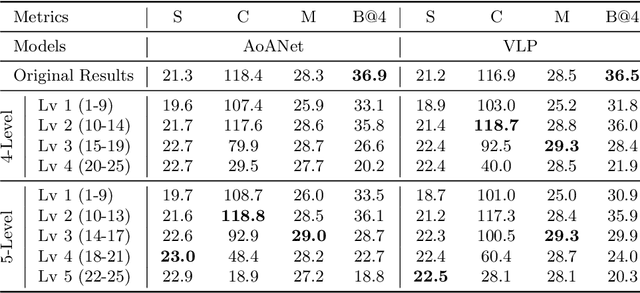
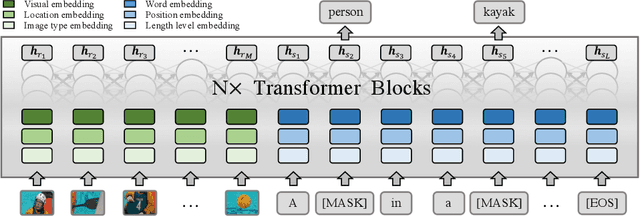

The last decade has witnessed remarkable progress in the image captioning task; however, most existing methods cannot control their captions, \emph{e.g.}, choosing to describe the image either roughly or in detail. In this paper, we propose to use a simple length level embedding to endow them with this ability. Moreover, due to their autoregressive nature, the computational complexity of existing models increases linearly as the length of the generated captions grows. Thus, we further devise a non-autoregressive image captioning approach that can generate captions in a length-irrelevant complexity. We verify the merit of the proposed length level embedding on three models: two state-of-the-art (SOTA) autoregressive models with different types of decoder, as well as our proposed non-autoregressive model, to show its generalization ability. In the experiments, our length-controllable image captioning models not only achieve SOTA performance on the challenging MS COCO dataset but also generate length-controllable and diverse image captions. Specifically, our non-autoregressive model outperforms the autoregressive baselines in terms of controllability and diversity, and also significantly improves the decoding efficiency for long captions. Our code and models are released at \textcolor{magenta}{\texttt{https://github.com/bearcatt/LaBERT}}.
Hephaestus: A large scale multitask dataset towards InSAR understanding
Apr 20, 2022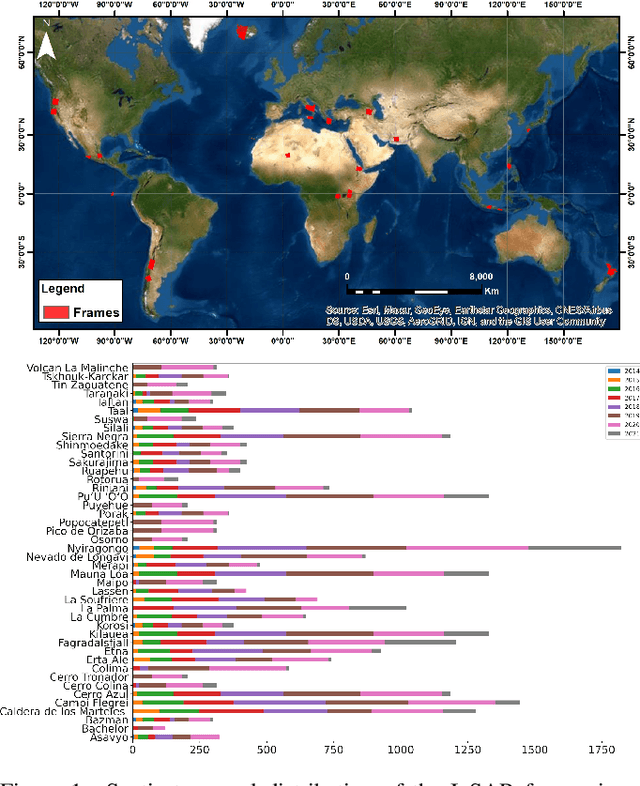
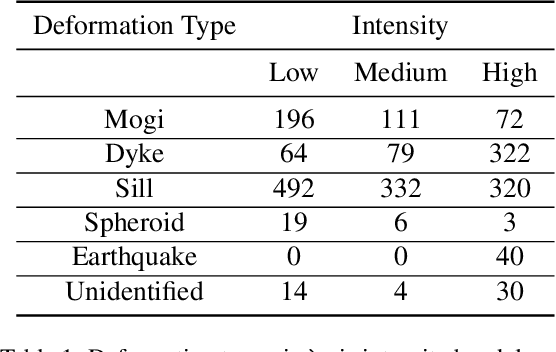
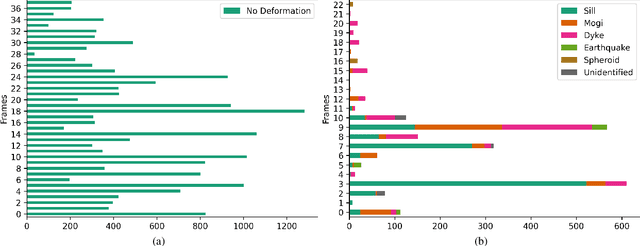
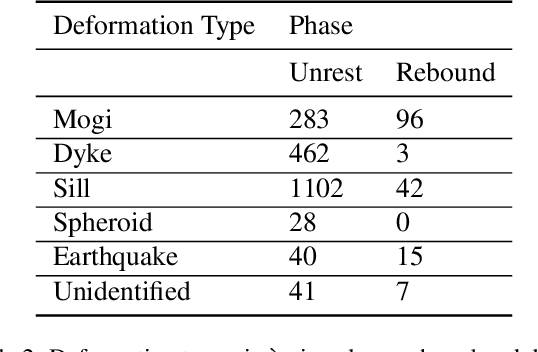
Synthetic Aperture Radar (SAR) data and Interferometric SAR (InSAR) products in particular, are one of the largest sources of Earth Observation data. InSAR provides unique information on diverse geophysical processes and geology, and on the geotechnical properties of man-made structures. However, there are only a limited number of applications that exploit the abundance of InSAR data and deep learning methods to extract such knowledge. The main barrier has been the lack of a large curated and annotated InSAR dataset, which would be costly to create and would require an interdisciplinary team of experts experienced on InSAR data interpretation. In this work, we put the effort to create and make available the first of its kind, manually annotated dataset that consists of 19,919 individual Sentinel-1 interferograms acquired over 44 different volcanoes globally, which are split into 216,106 InSAR patches. The annotated dataset is designed to address different computer vision problems, including volcano state classification, semantic segmentation of ground deformation, detection and classification of atmospheric signals in InSAR imagery, interferogram captioning, text to InSAR generation, and InSAR image quality assessment.