 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhase-Separated Complex Hilbert PCA on Markerless 3D Pose Estimation Data: A Global Phase Network and Its Extension to a Continuous Field on the Body Surface
Apr 27, 2026Quantitative analysis of the kinematic chain in sports motion is essential for performance evaluation and injury prevention. Conventional methods such as the kinematic-sequence (KS) and continuous relative phase (CRP) are confined to adjacent joint pairs and lack a unified framework for whole-body coordination, while segmental power-flow analysis requires force plates and inertial parameters that restrict it to laboratory environments. We apply Complex Hilbert Principal Component Analysis (CHPCA) separately to each motion phase (backswing and downswing) on markerless 3D pose estimation data, extracting the dominant whole-body phase pattern as a single complex eigenvector. The pipeline further includes a fully automatic signal-based phase segmentation (no priors on strike count or rest location) and an extension to 1,079 body-surface mesh vertices, so that the kinematic chain is represented as a continuous phase field across the body. On 14 hammer-striking trials of a single subject, the framework reveals (i) a trunk-anchored global phase architecture, (ii) a functional asymmetry between preparation and execution phases quantified by Mode-1 contribution (45.5% vs. 70.5%) and inter-trial Spearman consistency (0.38 vs. 0.58), and (iii) a consistent reorganisation across both skeletal joints and mesh vertices ($p < 10^{-10}$ on 1,079 vertices). As a methodological consistency check, pairwise phase differences from the Mode-1 eigenvector are compared against CRP on all 190 joint pairs by a permutation test ($ρ= 0.473$, $p = 0.0005$). A correspondence analysis between Mode-1 amplitude and kinetic-energy mobilisation variance further shows a strong positive correlation in the downswing ($ρ\approx 0.71$ on both skeleton and mesh) and no correlation in the backswing, indicating that the proposed framework bridges kinematic and kinetic descriptions of coordination through phase structure.
Towards Native Intelligence: 6G-LLM Trained with Reinforcement Learning from NDT Feedback
Jan 15, 2026Owing to its comprehensive understanding of upper-layer application requirements and the capabilities of practical communication systems, the 6G-LLM (6G domain large language model) offers a promising pathway toward realizing network native intelligence. Serving as the system orchestrator, the 6G-LLM drives a paradigm shift that fundamentally departs from existing rule-based approaches, which primarily rely on modular, experience-driven optimization. By contrast, the 6G-LLM substantially enhances network flexibility and adaptability. Nevertheless, current efforts to construct 6G-LLMs are constrained by their reliance on large-scale, meticulously curated, human-authored corpora, which are impractical to obtain in real-world scenarios. Moreover, purely offline-trained models lack the capacity for continual self-improvement, limiting their ability to adapt to the highly dynamic requirements of wireless communication environments. To overcome these limitations, we propose a novel training paradigm termed RLDTF (Reinforcement Learning from Digital Twin Feedback) for 6G-LLMs. This framework leverages network digital twins to generate reward signals based on orchestration outcomes, while employing reinforcement learning to guide the model toward optimal decision-making dynamically. Furthermore, we introduce a weighted token mechanism to improve output accuracy. Comprehensive experimental results demonstrate that our proposed framework significantly outperforms state-of-the-art baselines in orchestration accuracy and solution optimality.
Learning Pseudorandom Numbers with Transformers: Permuted Congruential Generators, Curricula, and Interpretability
Oct 30, 2025We study the ability of Transformer models to learn sequences generated by Permuted Congruential Generators (PCGs), a widely used family of pseudo-random number generators (PRNGs). PCGs introduce substantial additional difficulty over linear congruential generators (LCGs) by applying a series of bit-wise shifts, XORs, rotations and truncations to the hidden state. We show that Transformers can nevertheless successfully perform in-context prediction on unseen sequences from diverse PCG variants, in tasks that are beyond published classical attacks. In our experiments we scale moduli up to $2^{22}$ using up to $50$ million model parameters and datasets with up to $5$ billion tokens. Surprisingly, we find even when the output is truncated to a single bit, it can be reliably predicted by the model. When multiple distinct PRNGs are presented together during training, the model can jointly learn them, identifying structures from different permutations. We demonstrate a scaling law with modulus $m$: the number of in-context sequence elements required for near-perfect prediction grows as $\sqrt{m}$. For larger moduli, optimization enters extended stagnation phases; in our experiments, learning moduli $m \geq 2^{20}$ requires incorporating training data from smaller moduli, demonstrating a critical necessity for curriculum learning. Finally, we analyze embedding layers and uncover a novel clustering phenomenon: the model spontaneously groups the integer inputs into bitwise rotationally-invariant clusters, revealing how representations can transfer from smaller to larger moduli.
Improve ROI with Causal Learning and Conformal Prediction
Jul 01, 2024


In the commercial sphere, such as operations and maintenance, advertising, and marketing recommendations, intelligent decision-making utilizing data mining and neural network technologies is crucial, especially in resource allocation to optimize ROI. This study delves into the Cost-aware Binary Treatment Assignment Problem (C-BTAP) across different industries, with a focus on the state-of-the-art Direct ROI Prediction (DRP) method. However, the DRP model confronts issues like covariate shift and insufficient training data, hindering its real-world effectiveness. Addressing these challenges is essential for ensuring dependable and robust predictions in varied operational contexts. This paper presents a robust Direct ROI Prediction (rDRP) method, designed to address challenges in real-world deployment of neural network-based uplift models, particularly under conditions of covariate shift and insufficient training data. The rDRP method, enhancing the standard DRP model, does not alter the model's structure or require retraining. It utilizes conformal prediction and Monte Carlo dropout for interval estimation, adapting to model uncertainty and data distribution shifts. A heuristic calibration method, inspired by a Kaggle competition, combines point and interval estimates. The effectiveness of these approaches is validated through offline tests and online A/B tests in various settings, demonstrating significant improvements in target rewards compared to the state-of-the-art method.
Interpretable Cascading Mixture-of-Experts for Urban Traffic Congestion Prediction
Jun 14, 2024



Rapid urbanization has significantly escalated traffic congestion, underscoring the need for advanced congestion prediction services to bolster intelligent transportation systems. As one of the world's largest ride-hailing platforms, DiDi places great emphasis on the accuracy of congestion prediction to enhance the effectiveness and reliability of their real-time services, such as travel time estimation and route planning. Despite numerous efforts have been made on congestion prediction, most of them fall short in handling heterogeneous and dynamic spatio-temporal dependencies (e.g., periodic and non-periodic congestions), particularly in the presence of noisy and incomplete traffic data. In this paper, we introduce a Congestion Prediction Mixture-of-Experts, CP-MoE, to address the above challenges. We first propose a sparsely-gated Mixture of Adaptive Graph Learners (MAGLs) with congestion-aware inductive biases to improve the model capacity for efficiently capturing complex spatio-temporal dependencies in varying traffic scenarios. Then, we devise two specialized experts to help identify stable trends and periodic patterns within the traffic data, respectively. By cascading these experts with MAGLs, CP-MoE delivers congestion predictions in a more robust and interpretable manner. Furthermore, an ordinal regression strategy is adopted to facilitate effective collaboration among diverse experts. Extensive experiments on real-world datasets demonstrate the superiority of our proposed method compared with state-of-the-art spatio-temporal prediction models. More importantly, CP-MoE has been deployed in DiDi to improve the accuracy and reliability of the travel time estimation system.
Graph Invariant Learning with Subgraph Co-mixup for Out-Of-Distribution Generalization
Dec 18, 2023



Graph neural networks (GNNs) have been demonstrated to perform well in graph representation learning, but always lacking in generalization capability when tackling out-of-distribution (OOD) data. Graph invariant learning methods, backed by the invariance principle among defined multiple environments, have shown effectiveness in dealing with this issue. However, existing methods heavily rely on well-predefined or accurately generated environment partitions, which are hard to be obtained in practice, leading to sub-optimal OOD generalization performances. In this paper, we propose a novel graph invariant learning method based on invariant and variant patterns co-mixup strategy, which is capable of jointly generating mixed multiple environments and capturing invariant patterns from the mixed graph data. Specifically, we first adopt a subgraph extractor to identify invariant subgraphs. Subsequently, we design one novel co-mixup strategy, i.e., jointly conducting environment Mixup and invariant Mixup. For the environment Mixup, we mix the variant environment-related subgraphs so as to generate sufficiently diverse multiple environments, which is important to guarantee the quality of the graph invariant learning. For the invariant Mixup, we mix the invariant subgraphs, further encouraging to capture invariant patterns behind graphs while getting rid of spurious correlations for OOD generalization. We demonstrate that the proposed environment Mixup and invariant Mixup can mutually promote each other. Extensive experiments on both synthetic and real-world datasets demonstrate that our method significantly outperforms state-of-the-art under various distribution shifts.
Multi-agent Reinforcement Learning for Dynamic Resource Management in 6G in-X Subnetworks
May 10, 2022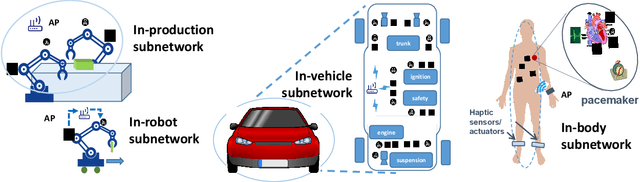
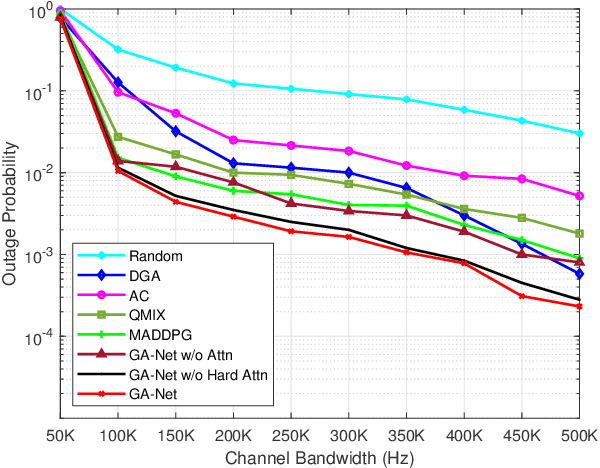
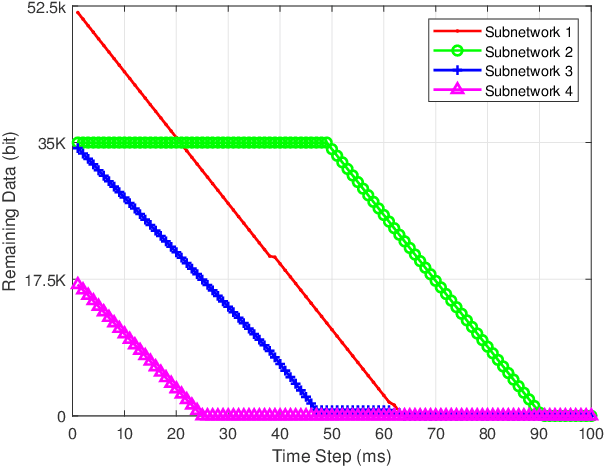
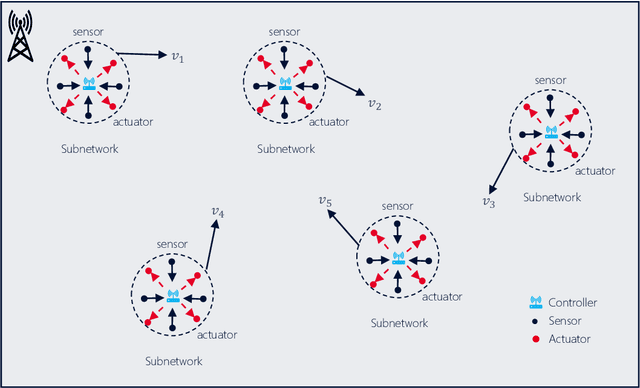
The 6G network enables a subnetwork-wide evolution, resulting in a "network of subnetworks". However, due to the dynamic mobility of wireless subnetworks, the data transmission of intra-subnetwork and inter-subnetwork will inevitably interfere with each other, which poses a great challenge to radio resource management. Moreover, most of the existing approaches require the instantaneous channel gain between subnetworks, which are usually difficult to be collected. To tackle these issues, in this paper we propose a novel effective intelligent radio resource management method using multi-agent deep reinforcement learning (MARL), which only needs the sum of received power, named received signal strength indicator (RSSI), on each channel instead of channel gains. However, to directly separate individual interference from RSSI is an almost impossible thing. To this end, we further propose a novel MARL architecture, named GA-Net, which integrates a hard attention layer to model the importance distribution of inter-subnetwork relationships based on RSSI and exclude the impact of unrelated subnetworks, and employs a graph attention network with a multi-head attention layer to exact the features and calculate their weights that will impact individual throughput. Experimental results prove that our proposed framework significantly outperforms both traditional and MARL-based methods in various aspects.
Perception Consistency Ultrasound Image Super-resolution via Self-supervised CycleGAN
Dec 28, 2020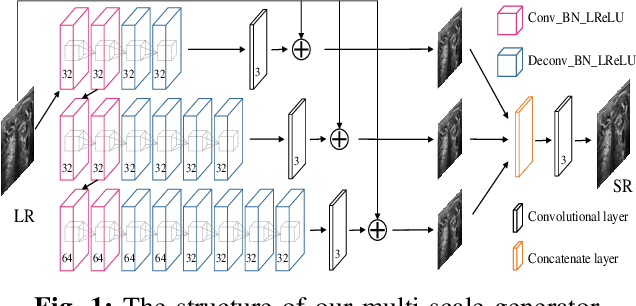
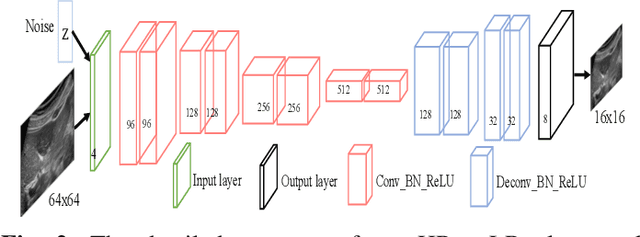
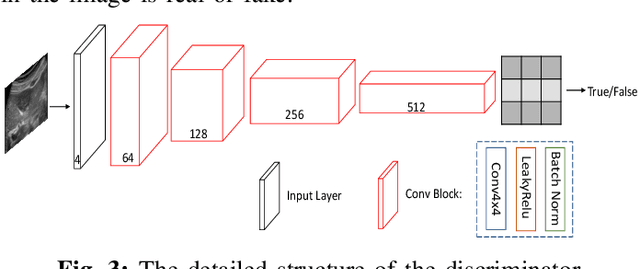
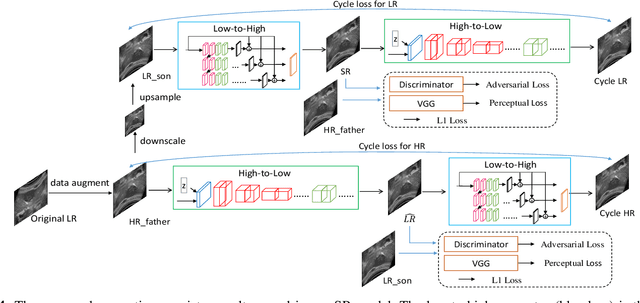
Due to the limitations of sensors, the transmission medium and the intrinsic properties of ultrasound, the quality of ultrasound imaging is always not ideal, especially its low spatial resolution. To remedy this situation, deep learning networks have been recently developed for ultrasound image super-resolution (SR) because of the powerful approximation capability. However, most current supervised SR methods are not suitable for ultrasound medical images because the medical image samples are always rare, and usually, there are no low-resolution (LR) and high-resolution (HR) training pairs in reality. In this work, based on self-supervision and cycle generative adversarial network (CycleGAN), we propose a new perception consistency ultrasound image super-resolution (SR) method, which only requires the LR ultrasound data and can ensure the re-degenerated image of the generated SR one to be consistent with the original LR image, and vice versa. We first generate the HR fathers and the LR sons of the test ultrasound LR image through image enhancement, and then make full use of the cycle loss of LR-SR-LR and HR-LR-SR and the adversarial characteristics of the discriminator to promote the generator to produce better perceptually consistent SR results. The evaluation of PSNR/IFC/SSIM, inference efficiency and visual effects under the benchmark CCA-US and CCA-US datasets illustrate our proposed approach is effective and superior to other state-of-the-art methods.
Iterative Grassmannian Optimization for Robust Image Alignment
Jun 20, 2013

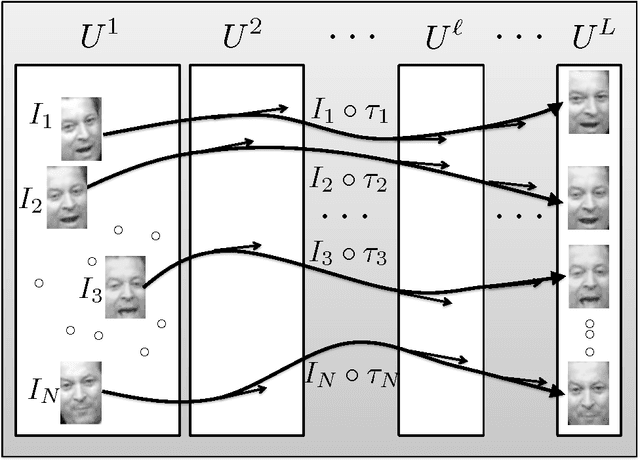
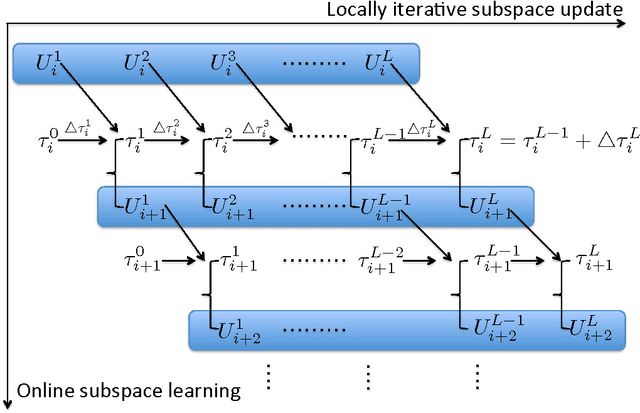
Robust high-dimensional data processing has witnessed an exciting development in recent years, as theoretical results have shown that it is possible using convex programming to optimize data fit to a low-rank component plus a sparse outlier component. This problem is also known as Robust PCA, and it has found application in many areas of computer vision. In image and video processing and face recognition, the opportunity to process massive image databases is emerging as people upload photo and video data online in unprecedented volumes. However, data quality and consistency is not controlled in any way, and the massiveness of the data poses a serious computational challenge. In this paper we present t-GRASTA, or "Transformed GRASTA (Grassmannian Robust Adaptive Subspace Tracking Algorithm)". t-GRASTA iteratively performs incremental gradient descent constrained to the Grassmann manifold of subspaces in order to simultaneously estimate a decomposition of a collection of images into a low-rank subspace, a sparse part of occlusions and foreground objects, and a transformation such as rotation or translation of the image. We show that t-GRASTA is 4 $\times$ faster than state-of-the-art algorithms, has half the memory requirement, and can achieve alignment for face images as well as jittered camera surveillance images.
* Preprint submitted to the special issue of the Image and Vision Computing Journal on the theme "The Best of Face and Gesture 2013"