 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Coreference Relations in Visual Dialog
Paper and Code

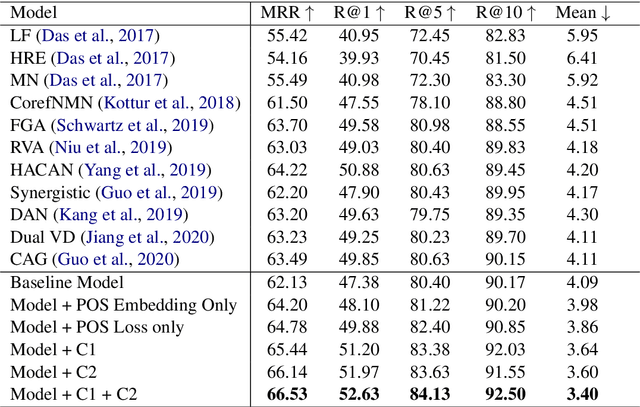

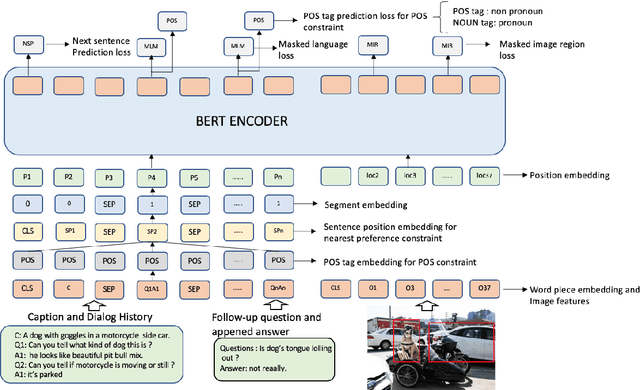
Visual dialog is a vision-language task where an agent needs to answer a series of questions grounded in an image based on the understanding of the dialog history and the image. The occurrences of coreference relations in the dialog makes it a more challenging task than visual question-answering. Most previous works have focused on learning better multi-modal representations or on exploring different ways of fusing visual and language features, while the coreferences in the dialog are mainly ignored. In this paper, based on linguistic knowledge and discourse features of human dialog we propose two soft constraints that can improve the model's ability of resolving coreferences in dialog in an unsupervised way. Experimental results on the VisDial v1.0 dataset shows that our model, which integrates two novel and linguistically inspired soft constraints in a deep transformer neural architecture, obtains new state-of-the-art performance in terms of recall at 1 and other evaluation metrics compared to current existing models and this without pretraining on other vision-language datasets. Our qualitative results also demonstrate the effectiveness of the method that we propose.