 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Synthetic-to-Real Domain Adaptation using Contrastive Unpaired Translation
Mar 17, 2022
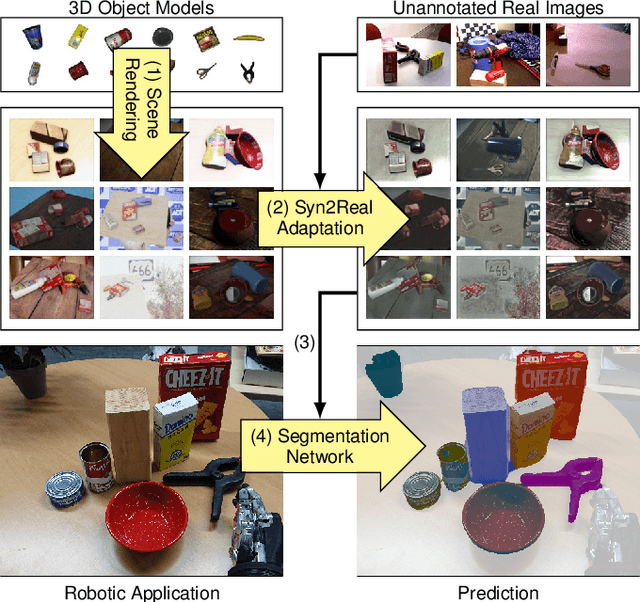

The usefulness of deep learning models in robotics is largely dependent on the availability of training data. Manual annotation of training data is often infeasible. Synthetic data is a viable alternative, but suffers from domain gap. We propose a multi-step method to obtain training data without manual annotation effort: From 3D object meshes, we generate images using a modern synthesis pipeline. We utilize a state-of-the-art image-to-image translation method to adapt the synthetic images to the real domain, minimizing the domain gap in a learned manner. The translation network is trained from unpaired images, i.e. just requires an un-annotated collection of real images. The generated and refined images can then be used to train deep learning models for a particular task. We also propose and evaluate extensions to the translation method that further increase performance, such as patch-based training, which shortens training time and increases global consistency. We evaluate our method and demonstrate its effectiveness on two robotic datasets. We finally give insight into the learned refinement operations.
Quality assessment of image matchers for DSM generation -- a comparative study based on UAV images
Aug 18, 2021
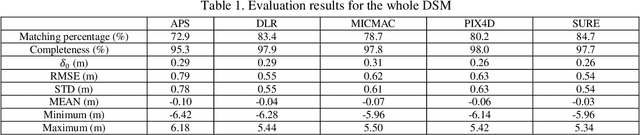
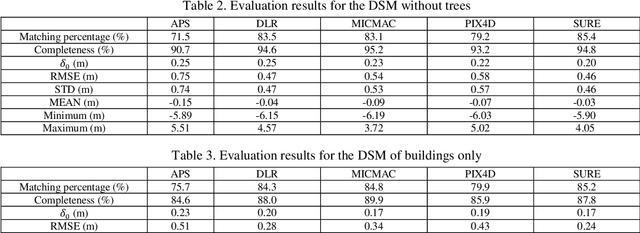
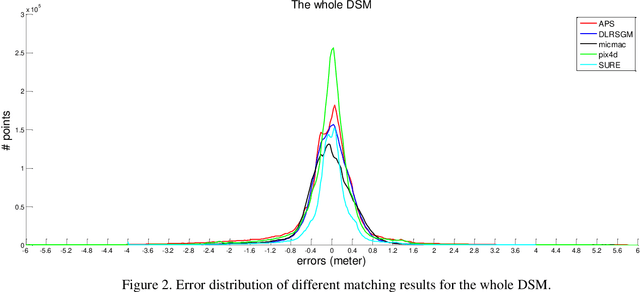
Recently developed automatic dense image matching algorithms are now being implemented for DSM/DTM production, with their pixel-level surface generation capability offering the prospect of partially alleviating the need for manual and semi-automatic stereoscopic measurements. In this paper, five commercial/public software packages for 3D surface generation are evaluated, using 5cm GSD imagery recorded from a UAV. Generated surface models are assessed against point clouds generated from mobile LiDAR and manual stereoscopic measurements. The software packages considered are APS, MICMAC, SURE, Pix4UAV and an SGM implementation from DLR.
Pre-demosaic Graph-based Light Field Image Compression
Feb 15, 2021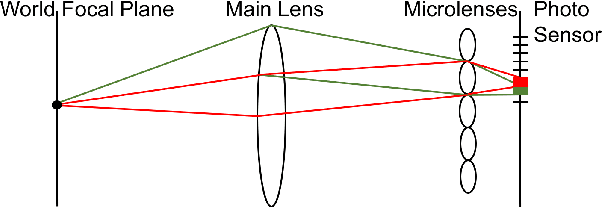

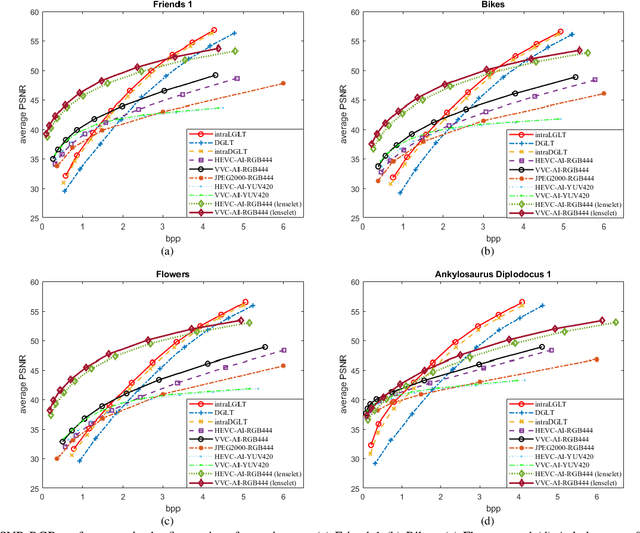
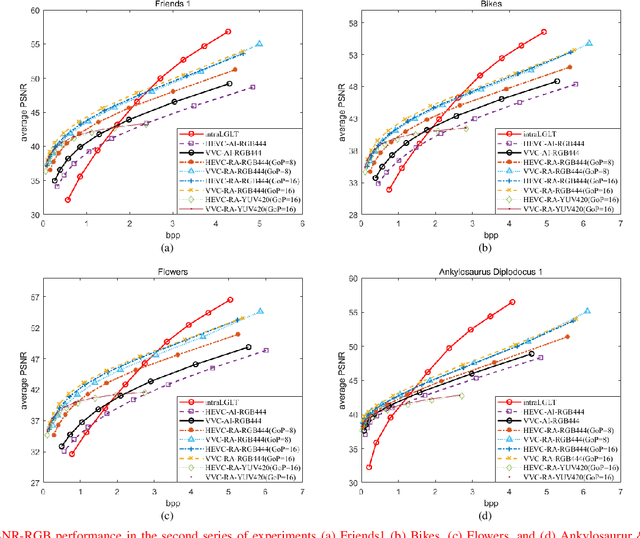
A plenoptic light field (LF) camera places an array of microlenses in front of an image sensor in order to separately capture different directional rays arriving at an image pixel. Using a conventional Bayer pattern, data captured at each pixel is a single color component (R, G or B). The sensed data then undergoes demosaicking (interpolation of RGB components per pixel) and conversion to an array of sub-aperture images (SAIs). In this paper, we propose a new LF image coding scheme based on graph lifting transform (GLT), where the acquired sensor data are coded in the original captured form without pre-processing. Specifically, we directly map raw sensed color data to the SAIs, resulting in sparsely distributed color pixels on 2D grids, and perform demosaicking at the receiver after decoding. To exploit spatial correlation among the sparse pixels, we propose a novel intra-prediction scheme, where the prediction kernel is determined according to the local gradient estimated from already coded neighboring pixel blocks. We then connect the pixels by forming a graph, modeling the prediction residuals statistically as a Gaussian Markov Random Field (GMRF). The optimal edge weights are computed via a graph learning method using a set of training SAIs. The residual data is encoded via low-complexity GLT. Experiments show that at high PSNRs -- important for archiving and instant storage scenarios -- our method outperformed significantly a conventional light field image coding scheme with demosaicking followed by High Efficiency Video Coding (HEVC).
GroupViT: Semantic Segmentation Emerges from Text Supervision
Feb 22, 2022
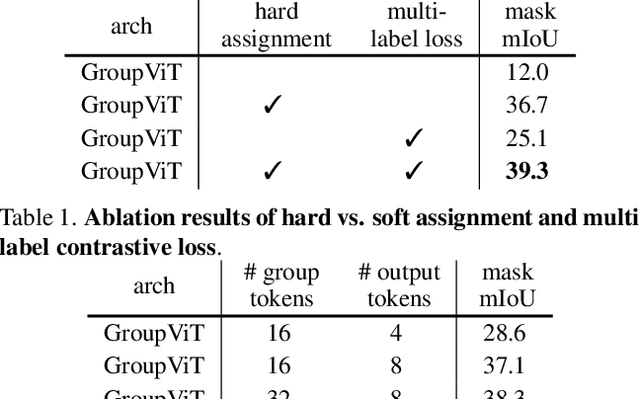
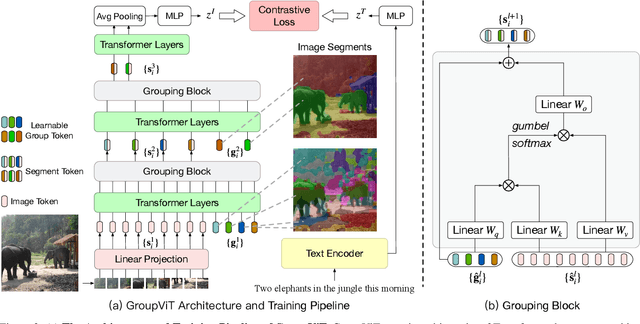
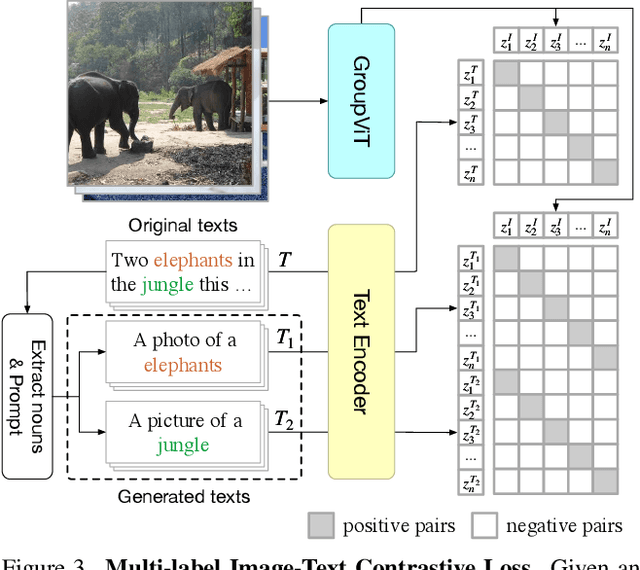
Grouping and recognition are important components of visual scene understanding, e.g., for object detection and semantic segmentation. With end-to-end deep learning systems, grouping of image regions usually happens implicitly via top-down supervision from pixel-level recognition labels. Instead, in this paper, we propose to bring back the grouping mechanism into deep networks, which allows semantic segments to emerge automatically with only text supervision. We propose a hierarchical Grouping Vision Transformer (GroupViT), which goes beyond the regular grid structure representation and learns to group image regions into progressively larger arbitrary-shaped segments. We train GroupViT jointly with a text encoder on a large-scale image-text dataset via contrastive losses. With only text supervision and without any pixel-level annotations, GroupViT learns to group together semantic regions and successfully transfers to the task of semantic segmentation in a zero-shot manner, i.e., without any further fine-tuning. It achieves a zero-shot accuracy of 51.2% mIoU on the PASCAL VOC 2012 and 22.3% mIoU on PASCAL Context datasets, and performs competitively to state-of-the-art transfer-learning methods requiring greater levels of supervision. Project page is available at https://jerryxu.net/GroupViT.
Time-series image denoising of pressure-sensitive paint data by projected multivariate singular spectrum analysis
Mar 15, 2022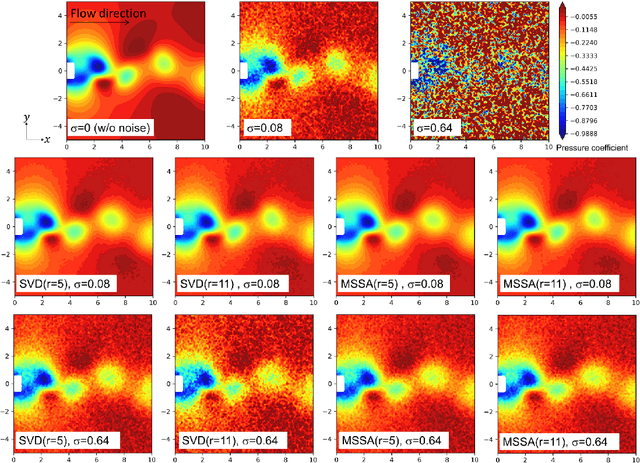
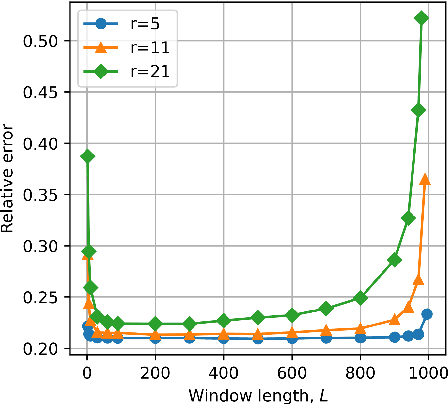
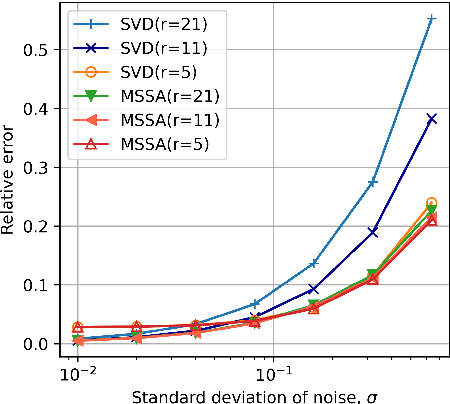
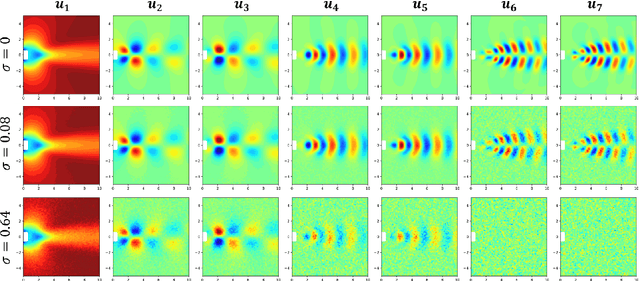
Time-series data, such as unsteady pressure-sensitive paint (PSP) measurement data, may contain a significant amount of random noise. Thus, in this study, we investigated a noise-reduction method that combines multivariate singular spectrum analysis (MSSA) with low-dimensional data representation. MSSA is a state-space reconstruction technique that utilizes time-delay embedding, and the low-dimensional representation is achieved by projecting data onto the singular value decomposition (SVD) basis. The noise-reduction performance of the proposed method for unsteady PSP data, i.e., the projected MSSA, is compared with that of the truncated SVD method, one of the most employed noise-reduction methods. The result shows that the projected MSSA exhibits better performance in reducing random noise than the truncated SVD method. Additionally, in contrast to that of the truncated SVD method, the performance of the projected MSSA is less sensitive to the truncation rank. Furthermore, the projected MSSA achieves denoising effectively by extracting smooth trajectories in a state space from noisy input data. Expectedly, the projected MSSA will be effective for reducing random noise in not only PSP measurement data, but also various high-dimensional time-series data.
DaViT: Dual Attention Vision Transformers
Apr 07, 2022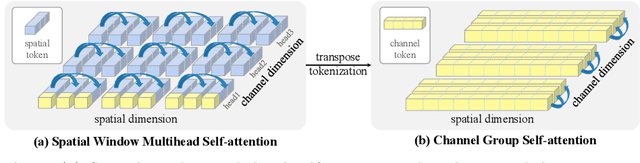
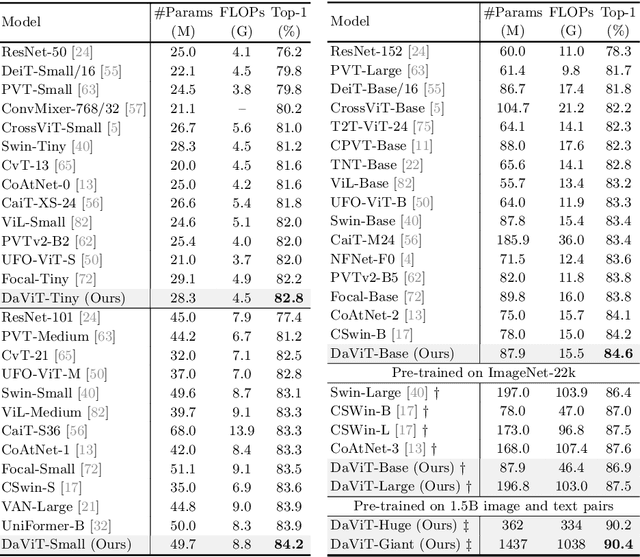
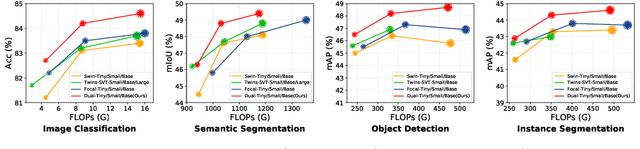
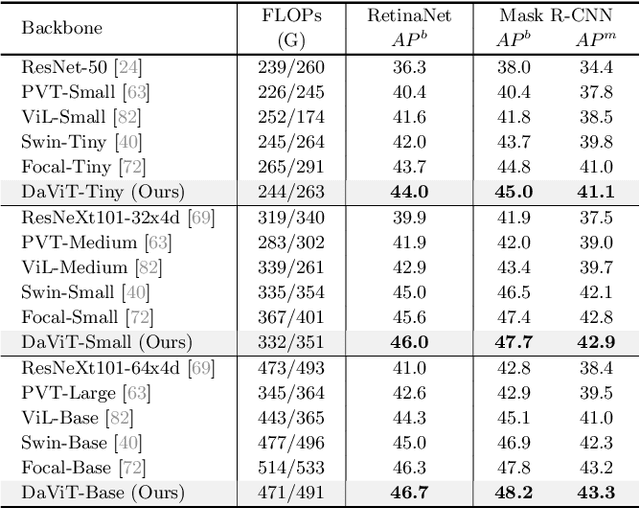
In this work, we introduce Dual Attention Vision Transformers (DaViT), a simple yet effective vision transformer architecture that is able to capture global context while maintaining computational efficiency. We propose approaching the problem from an orthogonal angle: exploiting self-attention mechanisms with both "spatial tokens" and "channel tokens". With spatial tokens, the spatial dimension defines the token scope, and the channel dimension defines the token feature dimension. With channel tokens, we have the inverse: the channel dimension defines the token scope, and the spatial dimension defines the token feature dimension. We further group tokens along the sequence direction for both spatial and channel tokens to maintain the linear complexity of the entire model. We show that these two self-attentions complement each other: (i) since each channel token contains an abstract representation of the entire image, the channel attention naturally captures global interactions and representations by taking all spatial positions into account when computing attention scores between channels; (ii) the spatial attention refines the local representations by performing fine-grained interactions across spatial locations, which in turn helps the global information modeling in channel attention. Extensive experiments show our DaViT achieves state-of-the-art performance on four different tasks with efficient computations. Without extra data, DaViT-Tiny, DaViT-Small, and DaViT-Base achieve 82.8%, 84.2%, and 84.6% top-1 accuracy on ImageNet-1K with 28.3M, 49.7M, and 87.9M parameters, respectively. When we further scale up DaViT with 1.5B weakly supervised image and text pairs, DaViT-Gaint reaches 90.4% top-1 accuracy on ImageNet-1K. Code is available at https://github.com/dingmyu/davit.
Signature and Log-signature for the Study of Empirical Distributions Generated with GANs
Mar 12, 2022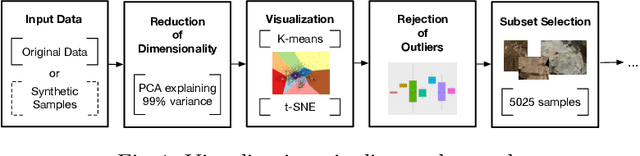


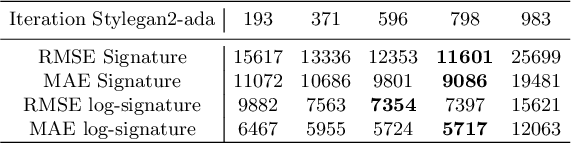
In this paper, we develop a new and systematic method to explore and analyze samples taken by NASA Perseverance on the surface of the planet Mars. A novel in this context PCA adaptive t-SNE is proposed, as well as the introduction of statistical measures to study the goodness of fit of the sample distribution. We go beyond visualization by generating synthetic imagery using Stylegan2-ADA that resemble the original terrain distribution. We also conduct synthetic image generation using the recently introduced Scored-based Generative Modeling. We bring forward the use of the recently developed Signature Transform as a way to measure the similarity between image distributions and provide detailed acquaintance and extensive evaluations. We are the first to pioneer RMSE and MAE Signature and log-signature as an alternative to measure GAN convergence. Insights on state-of-the-art instance segmentation of the samples by the use of a model DeepLabv3 are also given.
TFill: Image Completion via a Transformer-Based Architecture
Apr 02, 2021
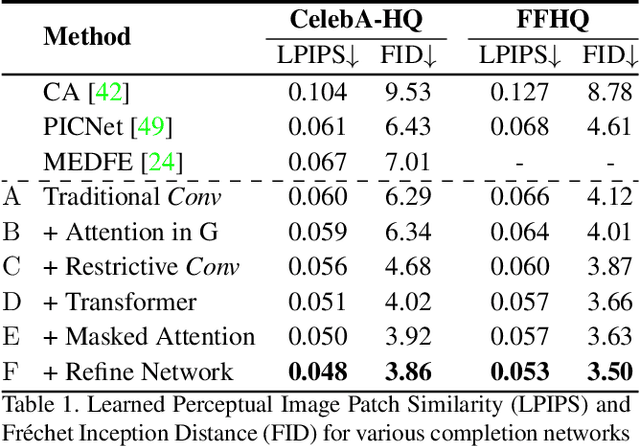
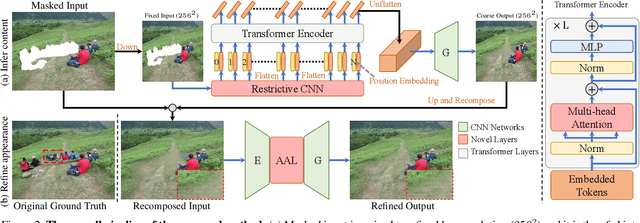
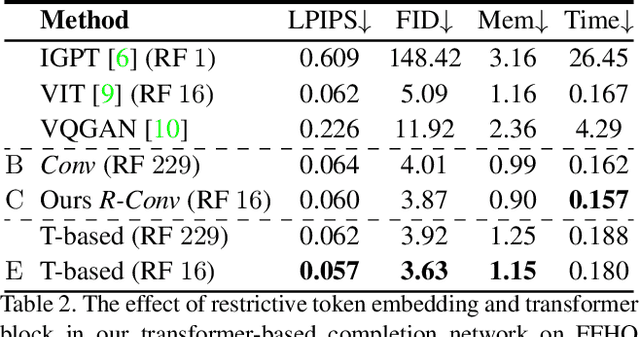
Bridging distant context interactions is important for high quality image completion with large masks. Previous methods attempting this via deep or large receptive field (RF) convolutions cannot escape from the dominance of nearby interactions, which may be inferior. In this paper, we propose treating image completion as a directionless sequence-to-sequence prediction task, and deploy a transformer to directly capture long-range dependence in the encoder in a first phase. Crucially, we employ a restrictive CNN with small and non-overlapping RF for token representation, which allows the transformer to explicitly model the long-range context relations with equal importance in all layers, without implicitly confounding neighboring tokens when larger RFs are used. In a second phase, to improve appearance consistency between visible and generated regions, a novel attention-aware layer (AAL) is introduced to better exploit distantly related features and also avoid the insular effect of standard attention. Overall, extensive experiments demonstrate superior performance compared to state-of-the-art methods on several datasets.
Progressively Complementary Network for Fisheye Image Rectification Using Appearance Flow
Mar 31, 2021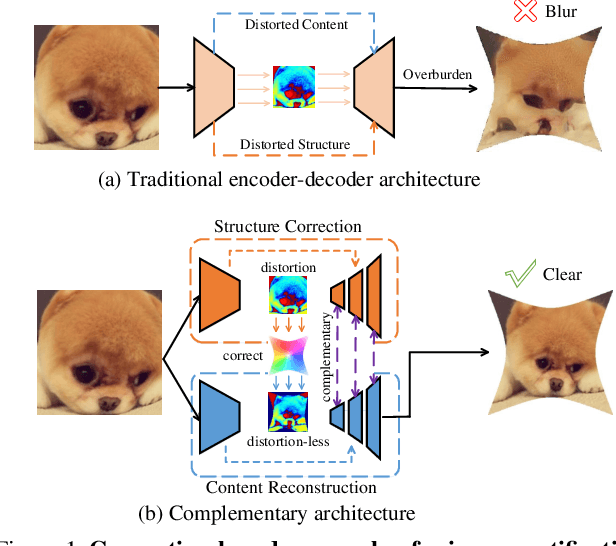
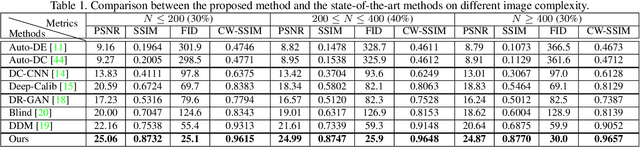
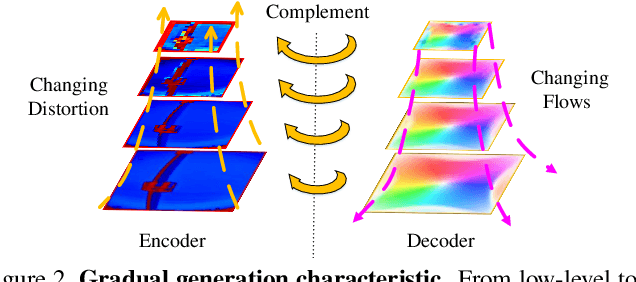
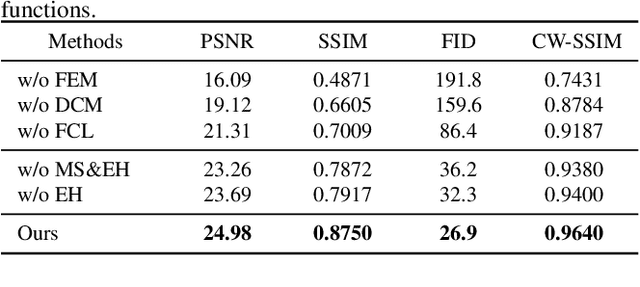
Distortion rectification is often required for fisheye images. The generation-based method is one mainstream solution due to its label-free property, but its naive skip-connection and overburdened decoder will cause blur and incomplete correction. First, the skip-connection directly transfers the image features, which may introduce distortion and cause incomplete correction. Second, the decoder is overburdened during simultaneously reconstructing the content and structure of the image, resulting in vague performance. To solve these two problems, in this paper, we focus on the interpretable correction mechanism of the distortion rectification network and propose a feature-level correction scheme. We embed a correction layer in skip-connection and leverage the appearance flows in different layers to pre-correct the image features. Consequently, the decoder can easily reconstruct a plausible result with the remaining distortion-less information. In addition, we propose a parallel complementary structure. It effectively reduces the burden of the decoder by separating content reconstruction and structure correction. Subjective and objective experiment results on different datasets demonstrate the superiority of our method.
OSLO: On-the-Sphere Learning for Omnidirectional images and its application to 360-degree image compression
Jul 19, 2021
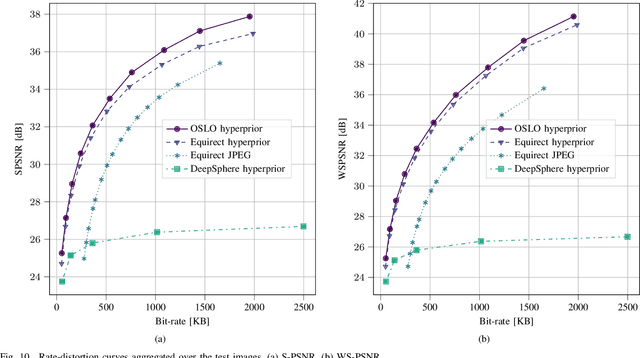
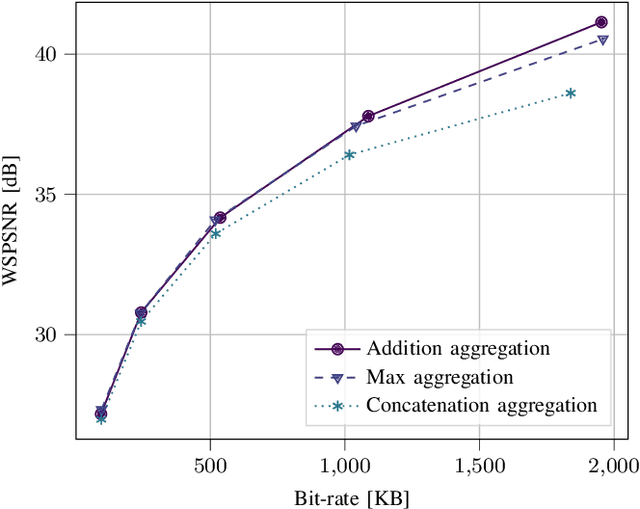
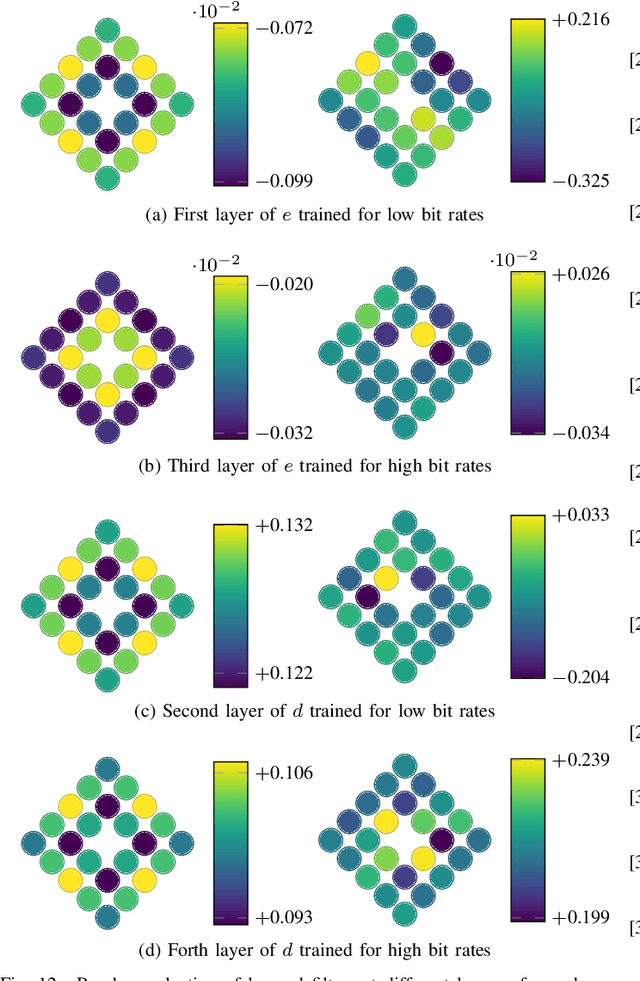
State-of-the-art 2D image compression schemes rely on the power of convolutional neural networks (CNNs). Although CNNs offer promising perspectives for 2D image compression, extending such models to omnidirectional images is not straightforward. First, omnidirectional images have specific spatial and statistical properties that can not be fully captured by current CNN models. Second, basic mathematical operations composing a CNN architecture, e.g., translation and sampling, are not well-defined on the sphere. In this paper, we study the learning of representation models for omnidirectional images and propose to use the properties of HEALPix uniform sampling of the sphere to redefine the mathematical tools used in deep learning models for omnidirectional images. In particular, we: i) propose the definition of a new convolution operation on the sphere that keeps the high expressiveness and the low complexity of a classical 2D convolution; ii) adapt standard CNN techniques such as stride, iterative aggregation, and pixel shuffling to the spherical domain; and then iii) apply our new framework to the task of omnidirectional image compression. Our experiments show that our proposed on-the-sphere solution leads to a better compression gain that can save 13.7% of the bit rate compared to similar learned models applied to equirectangular images. Also, compared to learning models based on graph convolutional networks, our solution supports more expressive filters that can preserve high frequencies and provide a better perceptual quality of the compressed images. Such results demonstrate the efficiency of the proposed framework, which opens new research venues for other omnidirectional vision tasks to be effectively implemented on the sphere manifold.