 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Invariance in Agentic AI
Mar 16, 2026Large Language Models (LLMs) increasingly serve as autonomous reasoning agents in decision support, scientific problem-solving, and multi-agent coordination systems. However, deploying LLM agents in consequential applications requires assurance that their reasoning remains stable under semantically equivalent input variations, a property we term semantic invariance. Standard benchmark evaluations, which assess accuracy on fixed, canonical problem formulations, fail to capture this critical reliability dimension. To address this shortcoming, in this paper we present a metamorphic testing framework for systematically assessing the robustness of LLM reasoning agents, applying eight semantic-preserving transformations (identity, paraphrase, fact reordering, expansion, contraction, academic context, business context, and contrastive formulation) across seven foundation models spanning four distinct architectural families: Hermes (70B, 405B), Qwen3 (30B-A3B, 235B-A22B), DeepSeek-R1, and gpt-oss (20B, 120B). Our evaluation encompasses 19 multi-step reasoning problems across eight scientific domains. The results reveal that model scale does not predict robustness: the smaller Qwen3-30B-A3B achieves the highest stability (79.6% invariant responses, semantic similarity 0.91), while larger models exhibit greater fragility.
LLM Constitutional Multi-Agent Governance
Mar 13, 2026Large Language Models (LLMs) can generate persuasive influence strategies that shift cooperative behavior in multi-agent populations, but a critical question remains: does the resulting cooperation reflect genuine prosocial alignment, or does it mask erosion of agent autonomy, epistemic integrity, and distributional fairness? We introduce Constitutional Multi-Agent Governance (CMAG), a two-stage framework that interposes between an LLM policy compiler and a networked agent population, combining hard constraint filtering with soft penalized-utility optimization that balances cooperation potential against manipulation risk and autonomy pressure. We propose the Ethical Cooperation Score (ECS), a multiplicative composite of cooperation, autonomy, integrity, and fairness that penalizes cooperation achieved through manipulative means. In experiments on scale-free networks of 80 agents under adversarial conditions (70% violating candidates), we benchmark three regimes: full CMAG, naive filtering, and unconstrained optimization. While unconstrained optimization achieves the highest raw cooperation (0.873), it yields the lowest ECS (0.645) due to severe autonomy erosion (0.867) and fairness degradation (0.888). CMAG attains an ECS of 0.741, a 14.9% improvement, while preserving autonomy at 0.985 and integrity at 0.995, with only modest cooperation reduction to 0.770. The naive ablation (ECS = 0.733) confirms that hard constraints alone are insufficient. Pareto analysis shows CMAG dominates the cooperation-autonomy trade-off space, and governance reduces hub-periphery exposure disparities by over 60%. These findings establish that cooperation is not inherently desirable without governance: constitutional constraints are necessary to ensure that LLM-mediated influence produces ethically stable outcomes rather than manipulative equilibria.
Cross-Platform Evaluation of Reasoning Capabilities in Foundation Models
Oct 30, 2025This paper presents a comprehensive cross-platform evaluation of reasoning capabilities in contemporary foundation models, establishing an infrastructure-agnostic benchmark across three computational paradigms: HPC supercomputing (MareNostrum 5), cloud platforms (Nebius AI Studio), and university clusters (a node with eight H200 GPUs). We evaluate 15 foundation models across 79 problems spanning eight academic domains (Physics, Mathematics, Chemistry, Economics, Biology, Statistics, Calculus, and Optimization) through three experimental phases: (1) Baseline establishment: Six models (Mixtral-8x7B, Phi-3, LLaMA 3.1-8B, Gemma-2-9b, Mistral-7B, OLMo-7B) evaluated on 19 problems using MareNostrum 5, establishing methodology and reference performance; (2) Infrastructure validation: The 19-problem benchmark repeated on university cluster (seven models including Falcon-Mamba state-space architecture) and Nebius AI Studio (nine state-of-the-art models: Hermes-4 70B/405B, LLaMA 3.1-405B/3.3-70B, Qwen3 30B/235B, DeepSeek-R1, GPT-OSS 20B/120B) to confirm infrastructure-agnostic reproducibility; (3) Extended evaluation: Full 79-problem assessment on both university cluster and Nebius platforms, probing generalization at scale across architectural diversity. The findings challenge conventional scaling assumptions, establish training data quality as more critical than model size, and provide actionable guidelines for model selection across educational, production, and research contexts. The tri-infrastructure methodology and 79-problem benchmark enable longitudinal tracking of reasoning capabilities as foundation models evolve.
Learning with Signatures
Apr 25, 2022
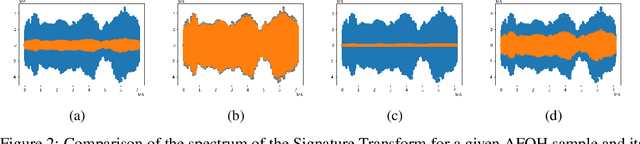
In this work we investigate the use of the Signature Transform in the context of Learning. Under this assumption, we advance a supervised framework that provides state-of-the-art classification accuracy with the use of very few labels without the need of credit assignment and with minimal or no overfitting. We leverage tools from harmonic analysis by the use of the signature and log-signature, and use as a score function RMSE and MAE Signature and log-signature. We develop a closed-form equation to compute probably good optimal scale factors. Classification is performed at the CPU level orders of magnitude faster than other methods. We report results on AFHQ, MNIST and CIFAR10 achieving 100% accuracy on all tasks assuming we can determine at test time which probably good optimal scale factor to use for each category.
Signature and Log-signature for the Study of Empirical Distributions Generated with GANs
Mar 12, 2022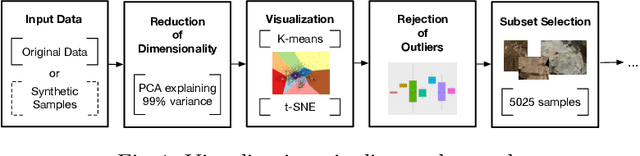


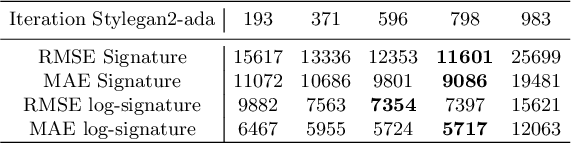
In this paper, we develop a new and systematic method to explore and analyze samples taken by NASA Perseverance on the surface of the planet Mars. A novel in this context PCA adaptive t-SNE is proposed, as well as the introduction of statistical measures to study the goodness of fit of the sample distribution. We go beyond visualization by generating synthetic imagery using Stylegan2-ADA that resemble the original terrain distribution. We also conduct synthetic image generation using the recently introduced Scored-based Generative Modeling. We bring forward the use of the recently developed Signature Transform as a way to measure the similarity between image distributions and provide detailed acquaintance and extensive evaluations. We are the first to pioneer RMSE and MAE Signature and log-signature as an alternative to measure GAN convergence. Insights on state-of-the-art instance segmentation of the samples by the use of a model DeepLabv3 are also given.