 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
CREAM: Weakly Supervised Object Localization via Class RE-Activation Mapping
May 27, 2022
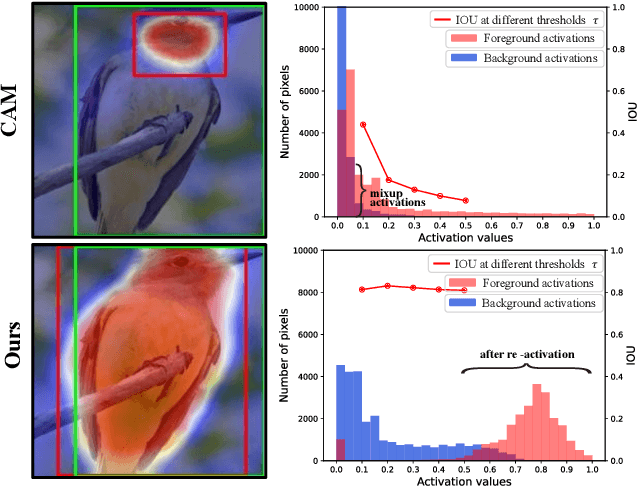
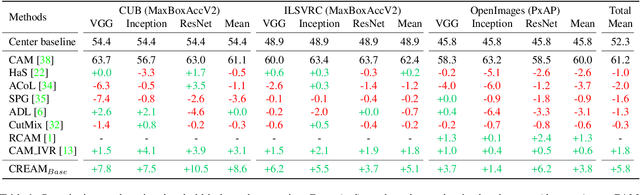
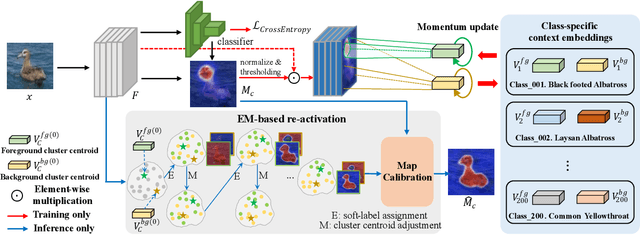
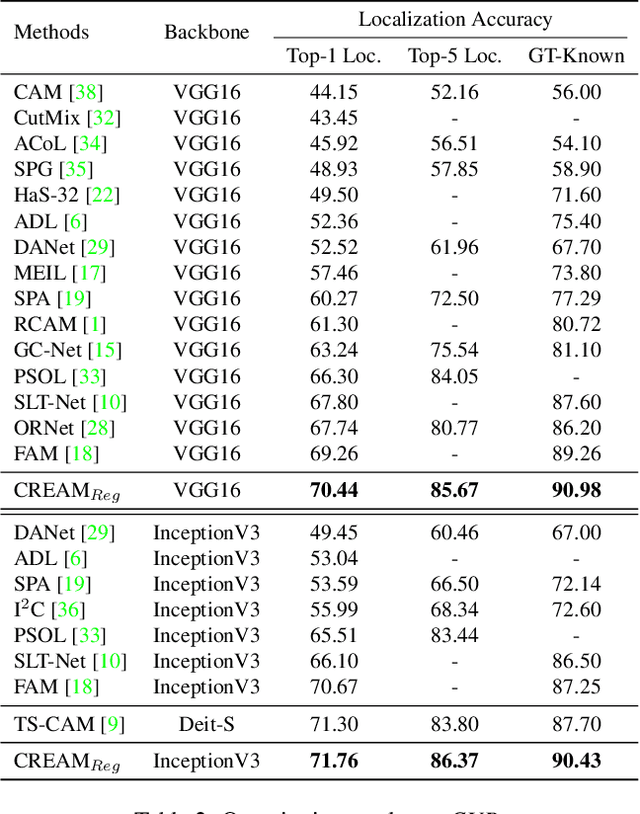
Weakly Supervised Object Localization (WSOL) aims to localize objects with image-level supervision. Existing works mainly rely on Class Activation Mapping (CAM) derived from a classification model. However, CAM-based methods usually focus on the most discriminative parts of an object (i.e., incomplete localization problem). In this paper, we empirically prove that this problem is associated with the mixup of the activation values between less discriminative foreground regions and the background. To address it, we propose Class RE-Activation Mapping (CREAM), a novel clustering-based approach to boost the activation values of the integral object regions. To this end, we introduce class-specific foreground and background context embeddings as cluster centroids. A CAM-guided momentum preservation strategy is developed to learn the context embeddings during training. At the inference stage, the re-activation mapping is formulated as a parameter estimation problem under Gaussian Mixture Model, which can be solved by deriving an unsupervised Expectation-Maximization based soft-clustering algorithm. By simply integrating CREAM into various WSOL approaches, our method significantly improves their performance. CREAM achieves the state-of-the-art performance on CUB, ILSVRC and OpenImages benchmark datasets. Code will be available at https://github.com/Jazzcharles/CREAM.
Grasping the Arrow of Time from the Singularity: Decoding Micromotion in Low-dimensional Latent Spaces from StyleGAN
Apr 27, 2022
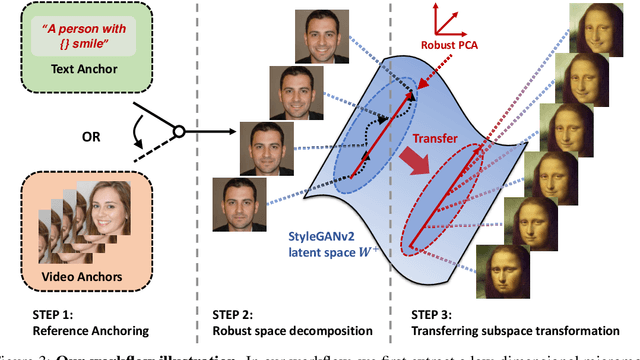


The disentanglement of StyleGAN latent space has paved the way for realistic and controllable image editing, but does StyleGAN know anything about temporal motion, as it was only trained on static images? To study the motion features in the latent space of StyleGAN, in this paper, we hypothesize and demonstrate that a series of meaningful, natural, and versatile small, local movements (referred to as "micromotion", such as expression, head movement, and aging effect) can be represented in low-rank spaces extracted from the latent space of a conventionally pre-trained StyleGAN-v2 model for face generation, with the guidance of proper "anchors" in the form of either short text or video clips. Starting from one target face image, with the editing direction decoded from the low-rank space, its micromotion features can be represented as simple as an affine transformation over its latent feature. Perhaps more surprisingly, such micromotion subspace, even learned from just single target face, can be painlessly transferred to other unseen face images, even those from vastly different domains (such as oil painting, cartoon, and sculpture faces). It demonstrates that the local feature geometry corresponding to one type of micromotion is aligned across different face subjects, and hence that StyleGAN-v2 is indeed "secretly" aware of the subject-disentangled feature variations caused by that micromotion. We present various successful examples of applying our low-dimensional micromotion subspace technique to directly and effortlessly manipulate faces, showing high robustness, low computational overhead, and impressive domain transferability. Our codes are available at https://github.com/wuqiuche/micromotion-StyleGAN.
Gastrointestinal Polyps and Tumors Detection Based on Multi-scale Feature-fusion with WCE Sequences
Apr 03, 2022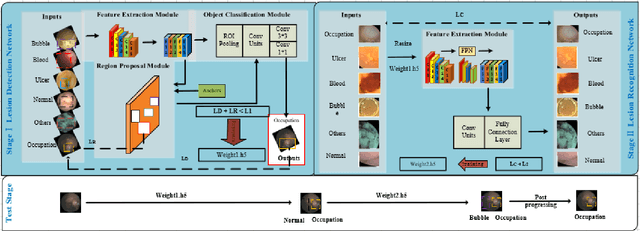

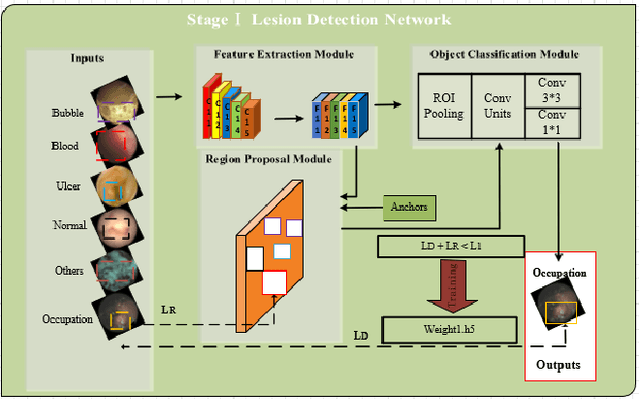
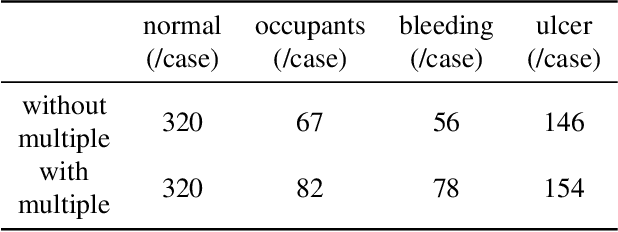
Wireless Capsule Endoscopy(WCE) has been widely used for the screening of gastrointestinal(GI) diseases, especially the small intestine, due to its advantages of non-invasive and painless imaging of the entire digestive tract.However, the huge amount of image data captured by WCE makes manual reading a process that requires a huge amount of tasks and can easily lead to missed detection and false detection of lesions.Therefore, In this paper, we propose a \textbf{T}wo-stage \textbf{M}ulti-scale \textbf{F}eature-fusion learning network(\textbf{TMFNet}) to automatically detect small intestinal polyps and tumors in WCE image sequences. Specifically, TMFNet consists of lesion detection network and lesion identification network. Among them, the former improves the feature extraction module and detection module based on the traditional Faster R-CNN network, and readjusts the parameters of the anchor in the region proposal network(RPN) module;the latter combines residual structure and feature pyramid structure are used to build a small intestinal lesion recognition network based on feature fusion, for reducing the false positive rate of the former and improve the overall accuracy.We used 22,335 WCE images in the experiment, with a total of 123,092 lesion regions used to train the detection framework of this paper. In the experiment, the detection framework is trained and tested on the real WCE image dataset provided by the hospital gastroenterology department. The sensitivity, false positive and accuracy of the final model on the RPM are 98.81$\%$, 7.43$\%$ and 92.57$\%$, respectively.Meanwhile,the corresponding results on the lesion images were 98.75$\%$, 5.62$\%$ and 94.39$\%$. The algorithm model proposed in this paper is obviously superior to other detection algorithms in detection effect and performance
To Find Waldo You Need Contextual Cues: Debiasing Who's Waldo
Mar 30, 2022
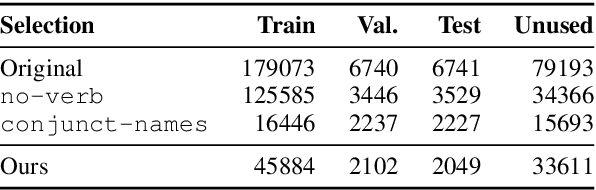
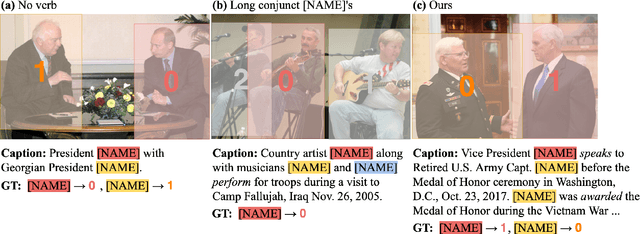
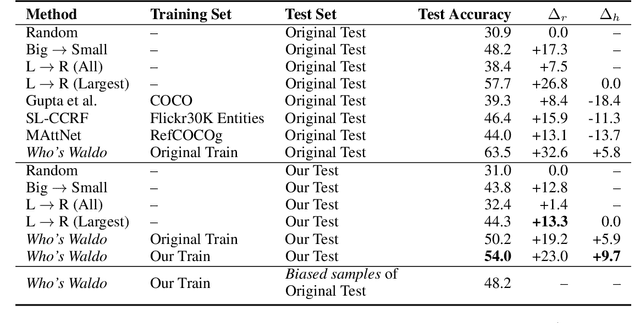
We present a debiased dataset for the Person-centric Visual Grounding (PCVG) task first proposed by Cui et al. (2021) in the Who's Waldo dataset. Given an image and a caption, PCVG requires pairing up a person's name mentioned in a caption with a bounding box that points to the person in the image. We find that the original Who's Waldo dataset compiled for this task contains a large number of biased samples that are solvable simply by heuristic methods; for instance, in many cases the first name in the sentence corresponds to the largest bounding box, or the sequence of names in the sentence corresponds to an exact left-to-right order in the image. Naturally, models trained on these biased data lead to over-estimation of performance on the benchmark. To enforce models being correct for the correct reasons, we design automated tools to filter and debias the original dataset by ruling out all examples of insufficient context, such as those with no verb or with a long chain of conjunct names in their captions. Our experiments show that our new sub-sampled dataset contains less bias with much lowered heuristic performances and widened gaps between heuristic and supervised methods. We also demonstrate the same benchmark model trained on our debiased training set outperforms that trained on the original biased (and larger) training set on our debiased test set. We argue our debiased dataset offers the PCVG task a more practical baseline for reliable benchmarking and future improvements.
Embracing New Techniques in Deep Learning for Estimating Image Memorability
May 21, 2021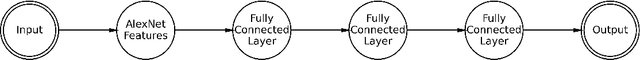
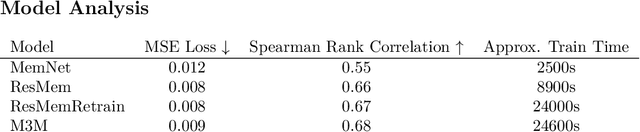
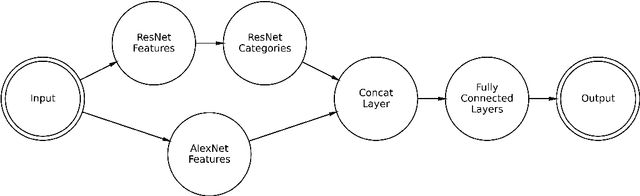
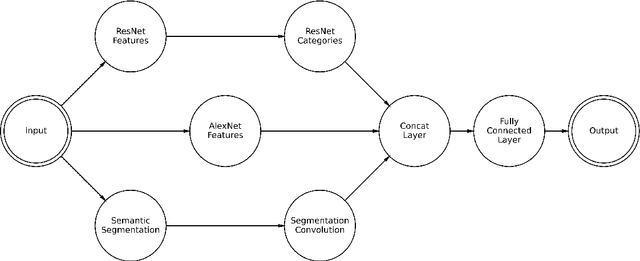
Various work has suggested that the memorability of an image is consistent across people, and thus can be treated as an intrinsic property of an image. Using computer vision models, we can make specific predictions about what people will remember or forget. While older work has used now-outdated deep learning architectures to predict image memorability, innovations in the field have given us new techniques to apply to this problem. Here, we propose and evaluate five alternative deep learning models which exploit developments in the field from the last five years, largely the introduction of residual neural networks, which are intended to allow the model to use semantic information in the memorability estimation process. These new models were tested against the prior state of the art with a combined dataset built to optimize both within-category and across-category predictions. Our findings suggest that the key prior memorability network had overstated its generalizability and was overfit on its training set. Our new models outperform this prior model, leading us to conclude that Residual Networks outperform simpler convolutional neural networks in memorability regression. We make our new state-of-the-art model readily available to the research community, allowing memory researchers to make predictions about memorability on a wider range of images.
Adaptively Re-weighting Multi-Loss Untrained Transformer for Sparse-View Cone-Beam CT Reconstruction
Mar 23, 2022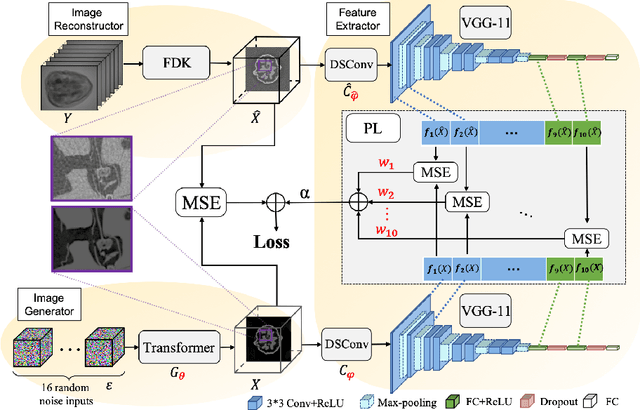
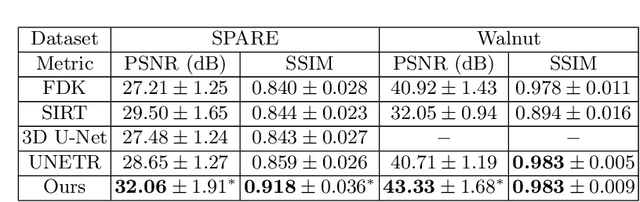
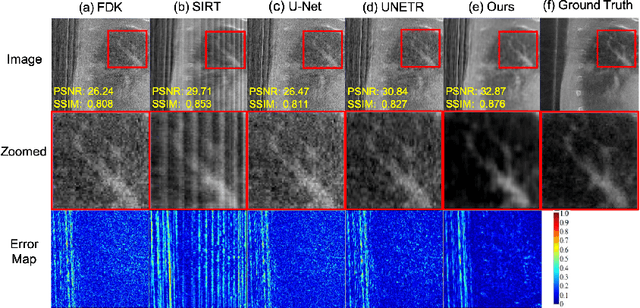
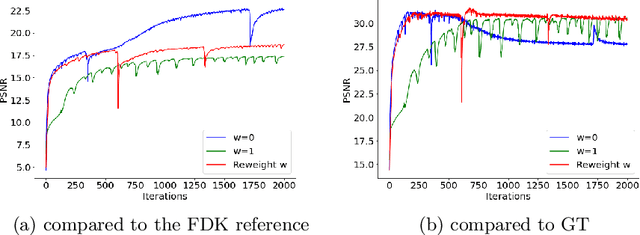
Cone-Beam Computed Tomography (CBCT) has been proven useful in diagnosis, but how to shorten scanning time with lower radiation dosage and how to efficiently reconstruct 3D image remain as the main issues for clinical practice. The recent development of tomographic image reconstruction on sparse-view measurements employs deep neural networks in a supervised way to tackle such issues, whereas the success of model training requires quantity and quality of the given paired measurements/images. We propose a novel untrained Transformer to fit the CBCT inverse solver without training data. It is mainly comprised of an untrained 3D Transformer of billions of network weights and a multi-level loss function with variable weights. Unlike conventional deep neural networks (DNNs), there is no requirement of training steps in our approach. Upon observing the hardship of optimising Transformer, the variable weights within the loss function are designed to automatically update together with the iteration process, ultimately stabilising its optimisation. We evaluate the proposed approach on two publicly available datasets: SPARE and Walnut. The results show a significant performance improvement on image quality metrics with streak artefact reduction in the visualisation. We also provide a clinical report by an experienced radiologist to assess our reconstructed images in a diagnosis point of view. The source code and the optimised models are available from the corresponding author on request at the moment.
TeachAugment: Data Augmentation Optimization Using Teacher Knowledge
Mar 07, 2022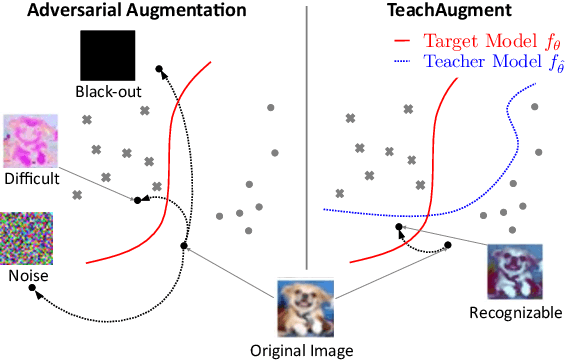

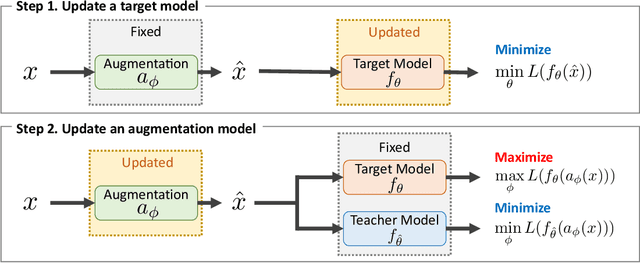
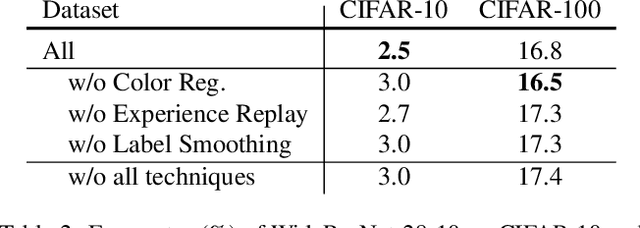
Optimization of image transformation functions for the purpose of data augmentation has been intensively studied. In particular, adversarial data augmentation strategies, which search augmentation maximizing task loss, show significant improvement in the model generalization for many tasks. However, the existing methods require careful parameter tuning to avoid excessively strong deformations that take away image features critical for acquiring generalization. In this paper, we propose a data augmentation optimization method based on the adversarial strategy called TeachAugment, which can produce informative transformed images to the model without requiring careful tuning by leveraging a teacher model. Specifically, the augmentation is searched so that augmented images are adversarial for the target model and recognizable for the teacher model. We also propose data augmentation using neural networks, which simplifies the search space design and allows for updating of the data augmentation using the gradient method. We show that TeachAugment outperforms existing methods in experiments of image classification, semantic segmentation, and unsupervised representation learning tasks.
StructToken : Rethinking Semantic Segmentation with Structural Prior
Apr 01, 2022
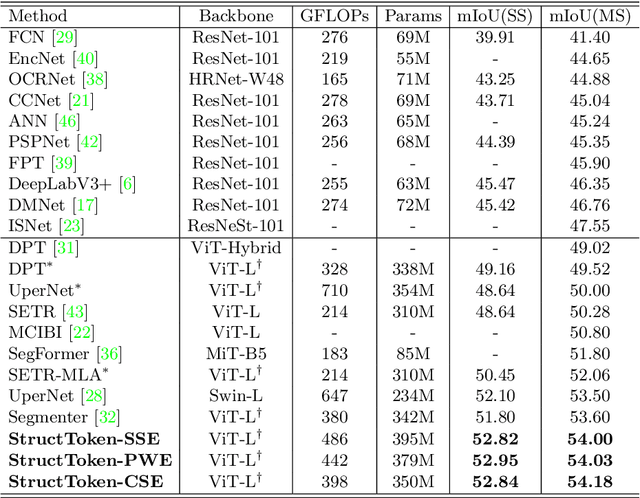
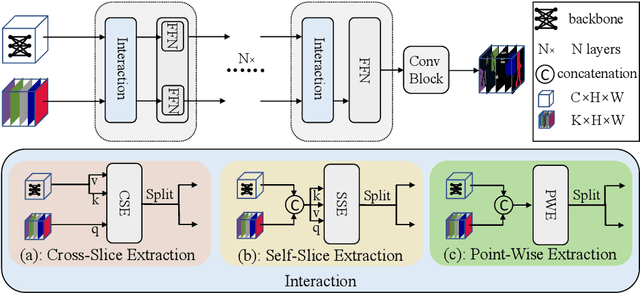
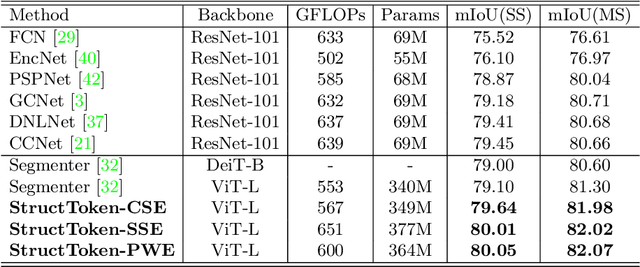
In this paper, we present structure token (StructToken), a new paradigm for semantic segmentation. From a perspective on semantic segmentation as per-pixel classification, the previous deep learning-based methods learn the per-pixel representation first through an encoder and a decoder head and then classify each pixel representation to a specific category to obtain the semantic masks. Differently, we propose a structure-aware algorithm that takes structural information as prior to predict semantic masks directly without per-pixel classification. Specifically, given an input image, the learnable structure token interacts with the image representations to reason the final semantic masks. Three interaction approaches are explored and the results not only outperform the state-of-the-art methods but also contain more structural information. Experiments are conducted on three widely used datasets including ADE20k, Cityscapes, and COCO-Stuff 10K. We hope that structure token could serve as an alternative for semantic segmentation and inspire future research.
From a few Accurate 2D Correspondences to 3D Point Clouds
Jun 13, 2022



Key points, correspondences, projection matrices, point clouds and dense clouds are the skeletons in image-based 3D reconstruction, of which point clouds have the important role in generating a realistic and natural model for a 3D reconstructed object. To achieve a good 3D reconstruction, the point clouds must be almost everywhere in the surface of the object. In this article, with a main purpose to build the point clouds covering the entire surface of the object, we propose a new feature named a geodesic feature or geo-feature. Based on the new geo-feature, if there are several (given) initial world points on the object's surface along with all accurately estimated projection matrices, some new world points on the geodesics connecting any two of these given world points will be reconstructed. Then the regions on the surface bordering by these initial world points will be covered by the point clouds. Thus, if the initial world points are around the surface, the point clouds will cover the entire surface. This article proposes a new method to estimate the world points and projection matrices from their correspondences. This method derives the closed-form and iterative solutions for the world points and projection matrices and proves that when the number of world points is less than seven and the number of images is at least five, the proposed solutions are global optimal. We propose an algorithm named World points from their Correspondences (WPfC) to estimate the world points and projection matrices from their correspondences, and another algorithm named Creating Point Clouds (CrPC) to create the point clouds from the world points and projection matrices given by the first algorithm.
Visual Probing: Cognitive Framework for Explaining Self-Supervised Image Representations
Jun 21, 2021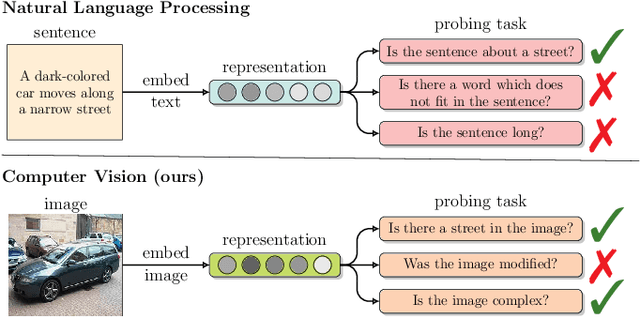
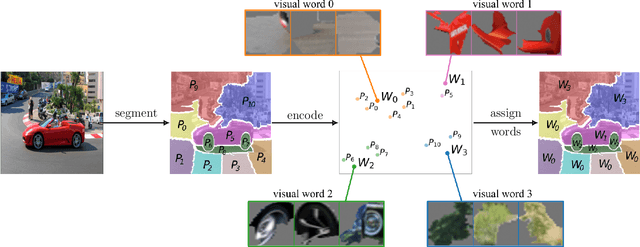
Recently introduced self-supervised methods for image representation learning provide on par or superior results to their fully supervised competitors, yet the corresponding efforts to explain the self-supervised approaches lag behind. Motivated by this observation, we introduce a novel visual probing framework for explaining the self-supervised models by leveraging probing tasks employed previously in natural language processing. The probing tasks require knowledge about semantic relationships between image parts. Hence, we propose a systematic approach to obtain analogs of natural language in vision, such as visual words, context, and taxonomy. Our proposal is grounded in Marr's computational theory of vision and concerns features like textures, shapes, and lines. We show the effectiveness and applicability of those analogs in the context of explaining self-supervised representations. Our key findings emphasize that relations between language and vision can serve as an effective yet intuitive tool for discovering how machine learning models work, independently of data modality. Our work opens a plethora of research pathways towards more explainable and transparent AI.