 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Practical Learned Lossless JPEG Recompression with Multi-Level Cross-Channel Entropy Model in the DCT Domain
Mar 30, 2022
JPEG is a popular image compression method widely used by individuals, data center, cloud storage and network filesystems. However, most recent progress on image compression mainly focuses on uncompressed images while ignoring trillions of already-existing JPEG images. To compress these JPEG images adequately and restore them back to JPEG format losslessly when needed, we propose a deep learning based JPEG recompression method that operates on DCT domain and propose a Multi-Level Cross-Channel Entropy Model to compress the most informative Y component. Experiments show that our method achieves state-of-the-art performance compared with traditional JPEG recompression methods including Lepton, JPEG XL and CMIX. To the best of our knowledge, this is the first learned compression method that losslessly transcodes JPEG images to more storage-saving bitstreams.
High-fidelity GAN Inversion with Padding Space
Mar 21, 2022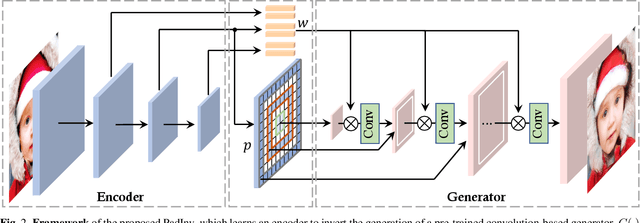



Inverting a Generative Adversarial Network (GAN) facilitates a wide range of image editing tasks using pre-trained generators. Existing methods typically employ the latent space of GANs as the inversion space yet observe the insufficient recovery of spatial details. In this work, we propose to involve the padding space of the generator to complement the latent space with spatial information. Concretely, we replace the constant padding (e.g., usually zeros) used in convolution layers with some instance-aware coefficients. In this way, the inductive bias assumed in the pre-trained model can be appropriately adapted to fit each individual image. Through learning a carefully designed encoder, we manage to improve the inversion quality both qualitatively and quantitatively, outperforming existing alternatives. We then demonstrate that such a space extension barely affects the native GAN manifold, hence we can still reuse the prior knowledge learned by GANs for various downstream applications. Beyond the editing tasks explored in prior arts, our approach allows a more flexible image manipulation, such as the separate control of face contour and facial details, and enables a novel editing manner where users can customize their own manipulations highly efficiently.
Multi-organ Segmentation Network with Adversarial Performance Validator
Apr 16, 2022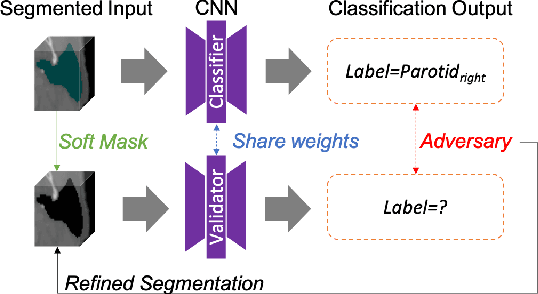
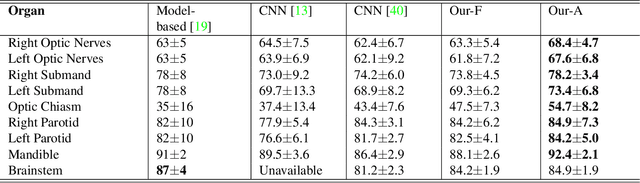
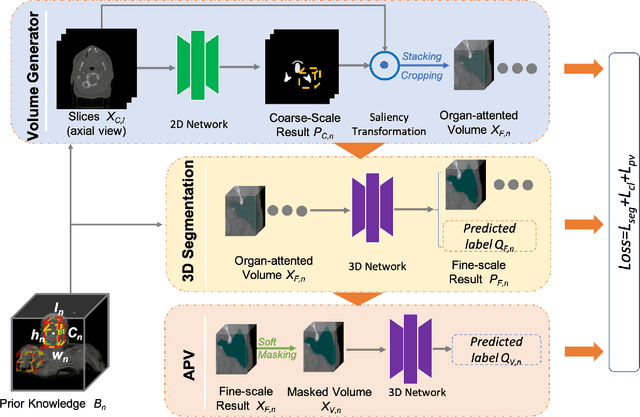
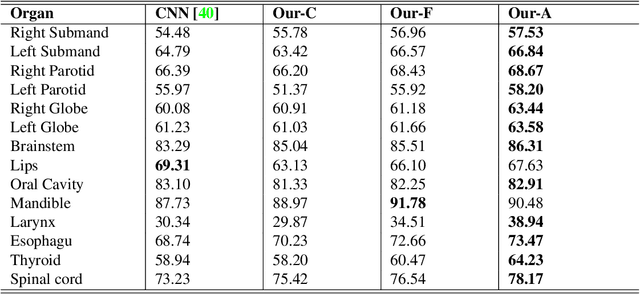
CT organ segmentation on computed tomography (CT) images becomes a significant brick for modern medical image analysis, supporting clinic workflows in multiple domains. Previous segmentation methods include 2D convolution neural networks (CNN) based approaches, fed by CT image slices that lack the structural knowledge in axial view, and 3D CNN-based methods with the expensive computation cost in multi-organ segmentation applications. This paper introduces an adversarial performance validation network into a 2D-to-3D segmentation framework. The classifier and performance validator competition contribute to accurate segmentation results via back-propagation. The proposed network organically converts the 2D-coarse result to 3D high-quality segmentation masks in a coarse-to-fine manner, allowing joint optimization to improve segmentation accuracy. Besides, the structural information of one specific organ is depicted by a statistics-meaningful prior bounding box, which is transformed into a global feature leveraging the learning process in 3D fine segmentation. The experiments on the NIH pancreas segmentation dataset demonstrate the proposed network achieves state-of-the-art accuracy on small organ segmentation and outperforms the previous best. High accuracy is also reported on multi-organ segmentation in a dataset collected by ourselves.
Keypoint-Based Category-Level Object Pose Tracking from an RGB Sequence with Uncertainty Estimation
May 23, 2022
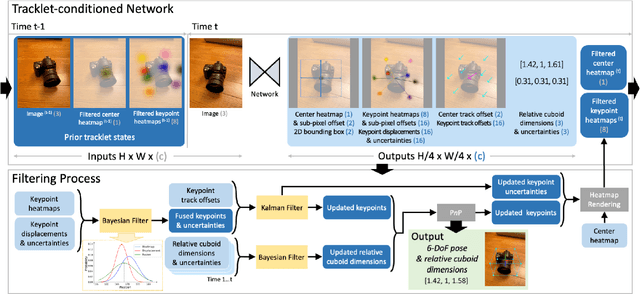
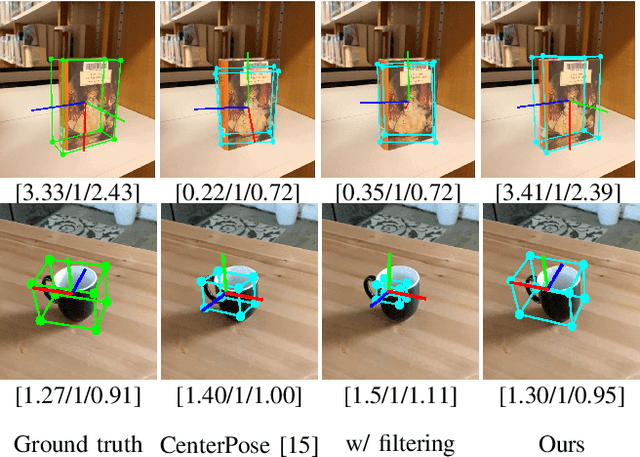
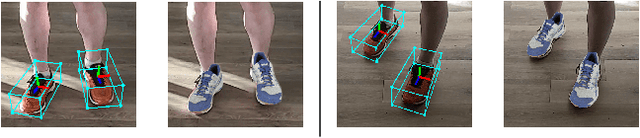
We propose a single-stage, category-level 6-DoF pose estimation algorithm that simultaneously detects and tracks instances of objects within a known category. Our method takes as input the previous and current frame from a monocular RGB video, as well as predictions from the previous frame, to predict the bounding cuboid and 6-DoF pose (up to scale). Internally, a deep network predicts distributions over object keypoints (vertices of the bounding cuboid) in image coordinates, after which a novel probabilistic filtering process integrates across estimates before computing the final pose using PnP. Our framework allows the system to take previous uncertainties into consideration when predicting the current frame, resulting in predictions that are more accurate and stable than single frame methods. Extensive experiments show that our method outperforms existing approaches on the challenging Objectron benchmark of annotated object videos. We also demonstrate the usability of our work in an augmented reality setting.
CLMLF:A Contrastive Learning and Multi-Layer Fusion Method for Multimodal Sentiment Detection
Apr 12, 2022
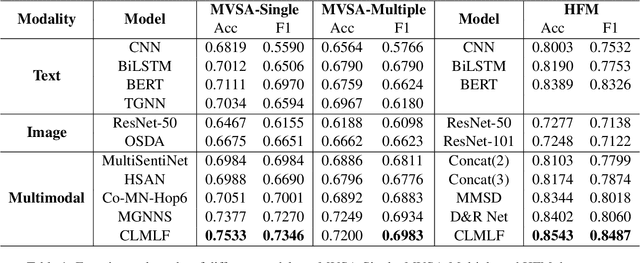
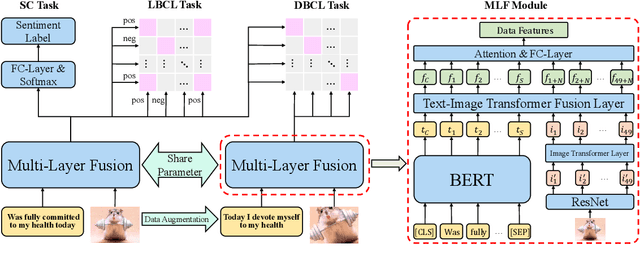
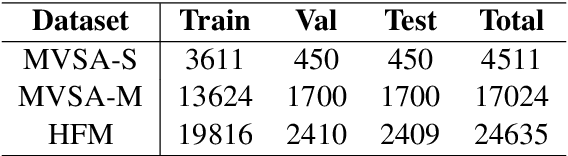
Compared with unimodal data, multimodal data can provide more features to help the model analyze the sentiment of data. Previous research works rarely consider token-level feature fusion, and few works explore learning the common features related to sentiment in multimodal data to help the model fuse multimodal features. In this paper, we propose a Contrastive Learning and Multi-Layer Fusion (CLMLF) method for multimodal sentiment detection. Specifically, we first encode text and image to obtain hidden representations, and then use a multi-layer fusion module to align and fuse the token-level features of text and image. In addition to the sentiment analysis task, we also designed two contrastive learning tasks, label based contrastive learning and data based contrastive learning tasks, which will help the model learn common features related to sentiment in multimodal data. Extensive experiments conducted on three publicly available multimodal datasets demonstrate the effectiveness of our approach for multimodal sentiment detection compared with existing methods. The codes are available for use at https://github.com/Link-Li/CLMLF
Self-Conditioned Generative Adversarial Networks for Image Editing
Feb 08, 2022
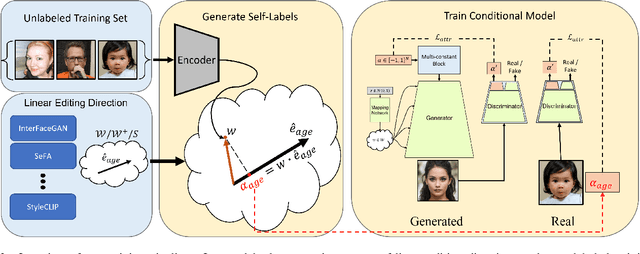
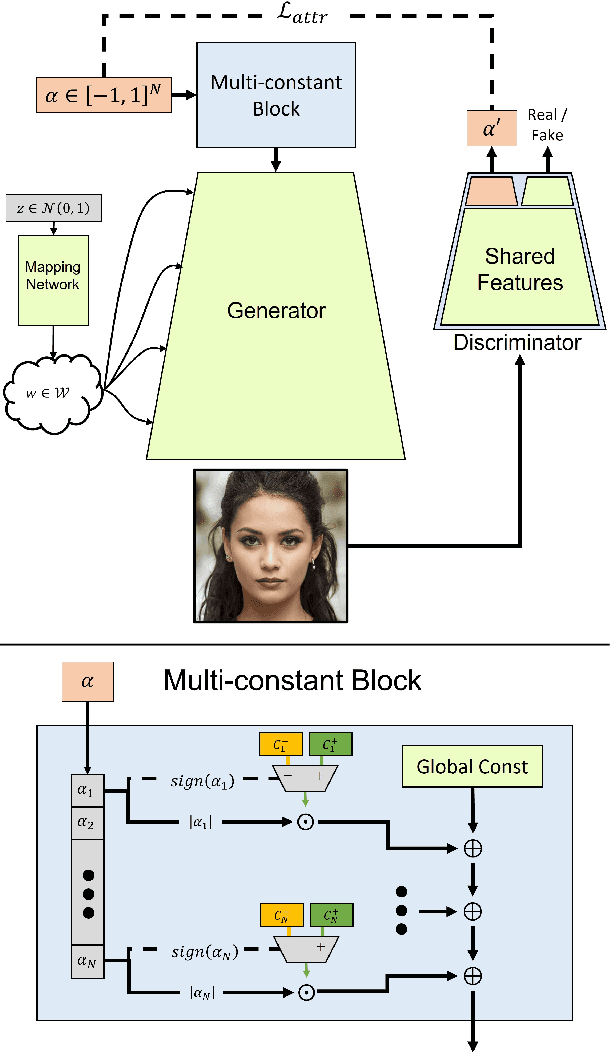

Generative Adversarial Networks (GANs) are susceptible to bias, learned from either the unbalanced data, or through mode collapse. The networks focus on the core of the data distribution, leaving the tails - or the edges of the distribution - behind. We argue that this bias is responsible not only for fairness concerns, but that it plays a key role in the collapse of latent-traversal editing methods when deviating away from the distribution's core. Building on this observation, we outline a method for mitigating generative bias through a self-conditioning process, where distances in the latent-space of a pre-trained generator are used to provide initial labels for the data. By fine-tuning the generator on a re-sampled distribution drawn from these self-labeled data, we force the generator to better contend with rare semantic attributes and enable more realistic generation of these properties. We compare our models to a wide range of latent editing methods, and show that by alleviating the bias they achieve finer semantic control and better identity preservation through a wider range of transformations. Our code and models will be available at https://github.com/yzliu567/sc-gan
MultiPathGAN: Structure Preserving Stain Normalization using Unsupervised Multi-domain Adversarial Network with Perception Loss
Apr 20, 2022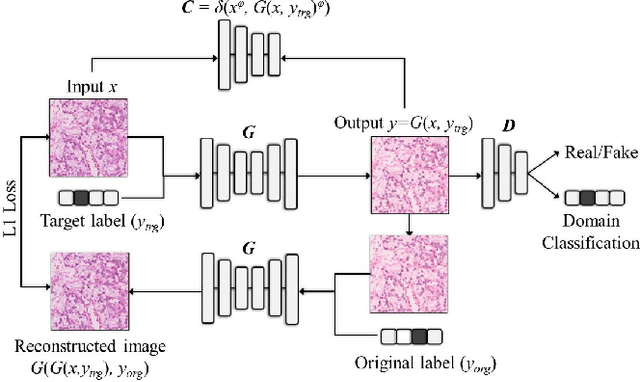
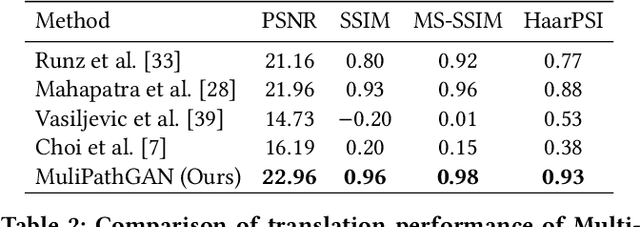
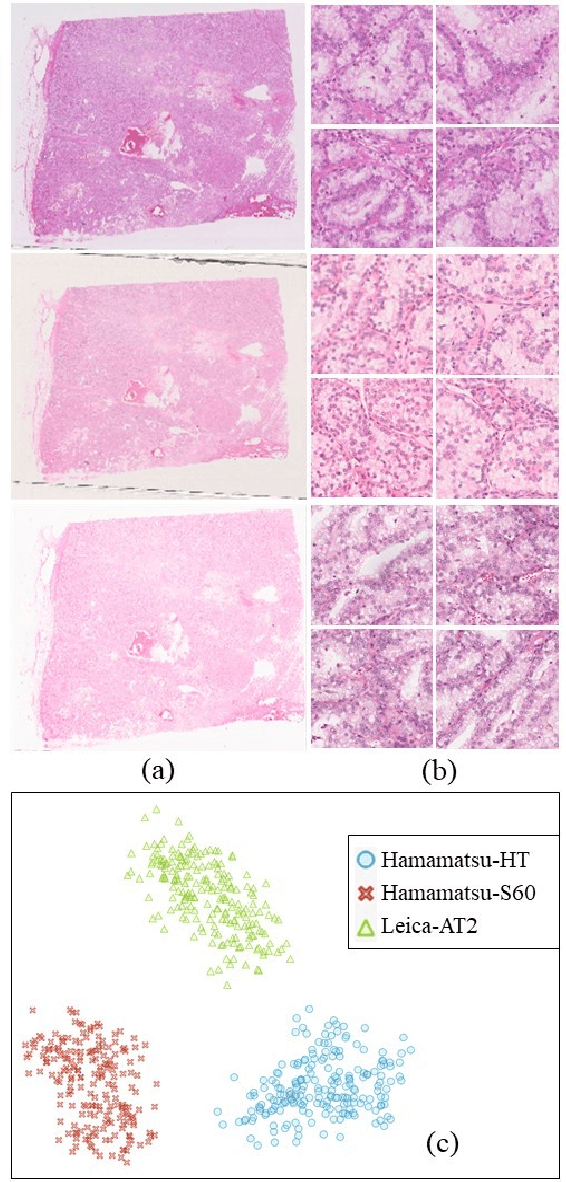
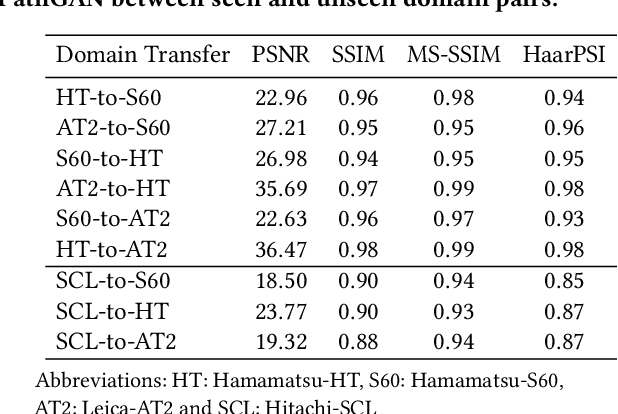
Histopathology relies on the analysis of microscopic tissue images to diagnose disease. A crucial part of tissue preparation is staining whereby a dye is used to make the salient tissue components more distinguishable. However, differences in laboratory protocols and scanning devices result in significant confounding appearance variation in the corresponding images. This variation increases both human error and the inter-rater variability, as well as hinders the performance of automatic or semi-automatic methods. In the present paper we introduce an unsupervised adversarial network to translate (and hence normalize) whole slide images across multiple data acquisition domains. Our key contributions are: (i) an adversarial architecture which learns across multiple domains with a single generator-discriminator network using an information flow branch which optimizes for perceptual loss, and (ii) the inclusion of an additional feature extraction network during training which guides the transformation network to keep all the structural features in the tissue image intact. We: (i) demonstrate the effectiveness of the proposed method firstly on H\&E slides of 120 cases of kidney cancer, as well as (ii) show the benefits of the approach on more general problems, such as flexible illumination based natural image enhancement and light source adaptation.
EVC-Net: Multi-scale V-Net with Conditional Random Fields for Brain Extraction
Jun 08, 2022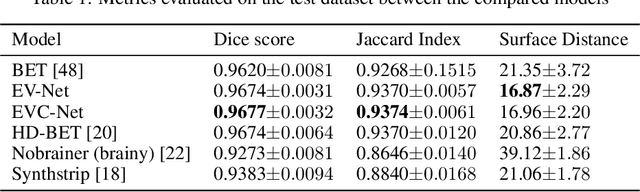

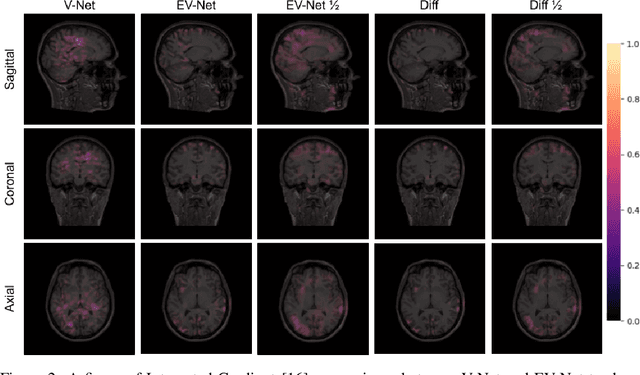

Brain extraction is one of the first steps of pre-processing 3D brain MRI data. It is a prerequisite for any forthcoming brain imaging analyses. However, it is not a simple segmentation problem due to the complex structure of the brain and human head. Although multiple solutions have been proposed in the literature, we are still far from having truly robust methods. While previous methods have used machine learning with structural/geometric priors, with the development of deep learning in computer vision tasks, there has been an increase in proposed convolutional neural network architectures for this semantic segmentation task. Yet, most models focus on improving the training data and loss functions with little change in the architecture. In this paper, we propose a novel architecture we call EVC-Net. EVC-Net adds lower scale inputs on each encoder block. This enhances the multi-scale scheme of the V-Net architecture, hence increasing the efficiency of the model. Conditional Random Fields, a popular approach for image segmentation before the deep learning era, are re-introduced here as an additional step for refining the network's output to capture fine-grained results in segmentation. We compare our model to state-of-the-art methods such as HD-BET, Synthstrip and brainy. Results show that even with limited training resources, EVC-Net achieves higher Dice Coefficient and Jaccard Index along with lower surface distance.
On the Kullback-Leibler divergence between pairwise isotropic Gaussian-Markov random fields
Mar 24, 2022
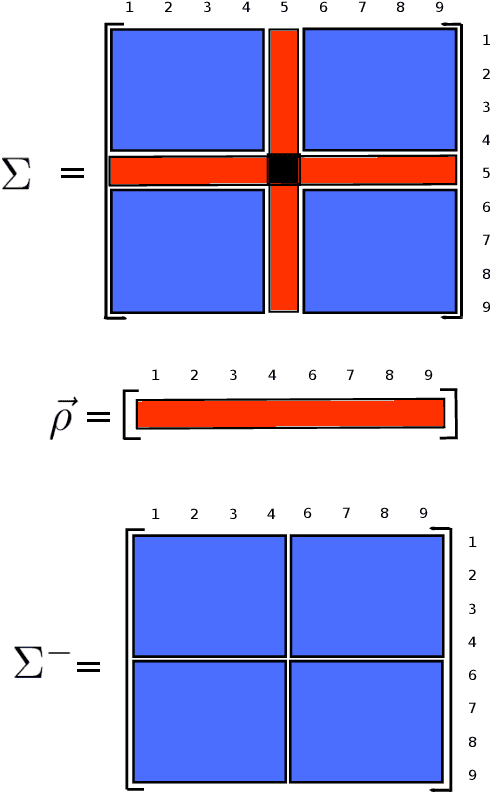
The Kullback-Leibler divergence or relative entropy is an information-theoretic measure between statistical models that play an important role in measuring a distance between random variables. In the study of complex systems, random fields are mathematical structures that models the interaction between these variables by means of an inverse temperature parameter, responsible for controlling the spatial dependence structure along the field. In this paper, we derive closed-form expressions for the Kullback-Leibler divergence between two pairwise isotropic Gaussian-Markov random fields in both univariate and multivariate cases. The proposed equation allows the development of novel similarity measures in image processing and machine learning applications, such as image denoising and unsupervised metric learning.
Morphence-2.0: Evasion-Resilient Moving Target Defense Powered by Out-of-Distribution Detection
Jun 15, 2022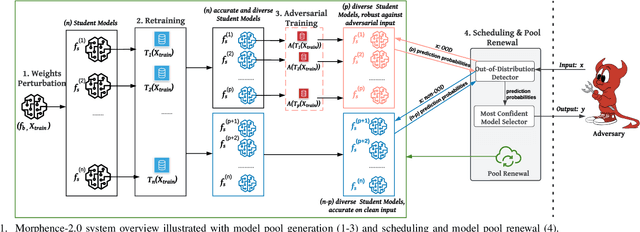
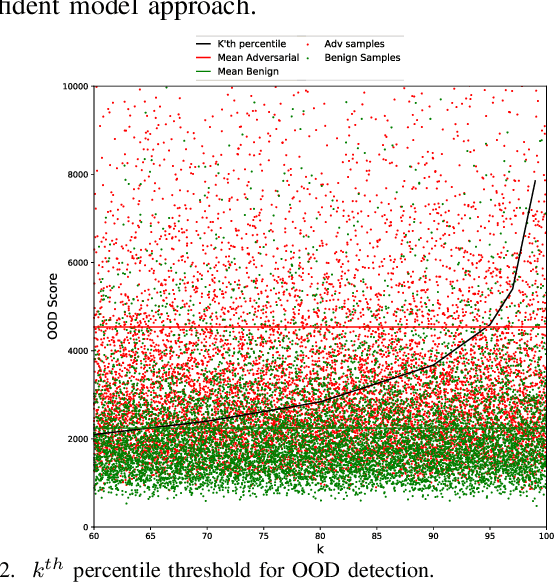
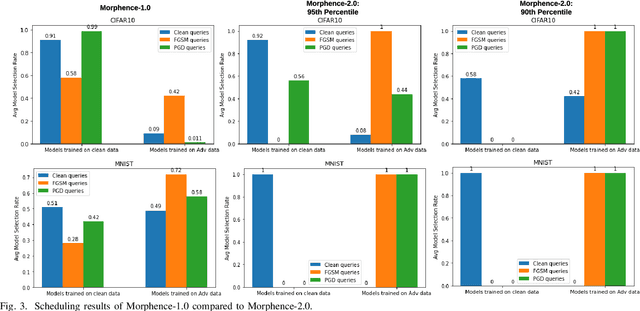
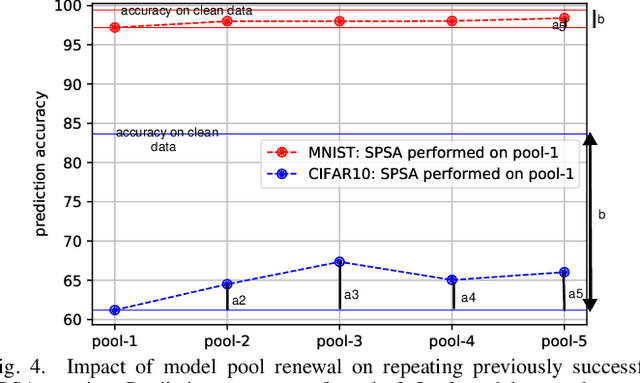
Evasion attacks against machine learning models often succeed via iterative probing of a fixed target model, whereby an attack that succeeds once will succeed repeatedly. One promising approach to counter this threat is making a model a moving target against adversarial inputs. To this end, we introduce Morphence-2.0, a scalable moving target defense (MTD) powered by out-of-distribution (OOD) detection to defend against adversarial examples. By regularly moving the decision function of a model, Morphence-2.0 makes it significantly challenging for repeated or correlated attacks to succeed. Morphence-2.0 deploys a pool of models generated from a base model in a manner that introduces sufficient randomness when it responds to prediction queries. Via OOD detection, Morphence-2.0 is equipped with a scheduling approach that assigns adversarial examples to robust decision functions and benign samples to an undefended accurate models. To ensure repeated or correlated attacks fail, the deployed pool of models automatically expires after a query budget is reached and the model pool is seamlessly replaced by a new model pool generated in advance. We evaluate Morphence-2.0 on two benchmark image classification datasets (MNIST and CIFAR10) against 4 reference attacks (3 white-box and 1 black-box). Morphence-2.0 consistently outperforms prior defenses while preserving accuracy on clean data and reducing attack transferability. We also show that, when powered by OOD detection, Morphence-2.0 is able to precisely make an input-based movement of the model's decision function that leads to higher prediction accuracy on both adversarial and benign queries.