 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnmasking On-Policy Distillation: Where It Helps, Where It Hurts, and Why
May 11, 2026On-policy distillation offers dense, per-token supervision for training reasoning models; however, it remains unclear under which conditions this signal is beneficial and under which it is detrimental. Which teacher model should be used, and in the case of self-distillation, which specific context should serve as the supervisory signal? Does the optimal choice vary from one token to the next? At present, addressing these questions typically requires costly training runs whose aggregate performance metrics obscure the dynamics at the level of individual tokens. We introduce a training-free diagnostic framework that operates at the highest resolution: per token, per question, and per teacher. We derive an ideal per-node gradient defined as the parameter update that maximally increases the student's probability of success. We then develop a scalable targeted-rollout algorithm to estimate this gradient efficiently, even for long chains of intermediate thoughts. The gradient alignment score, defined as the cosine similarity between this ideal gradient and any given distillation gradient, quantifies the extent to which a particular configuration approximates the ideal signal. Across a range of self-distillation settings and external teacher models, we observe that distillation guidance exhibits substantially higher alignment with the ideal on incorrect rollouts than on correct ones, where the student already performs well and the teacher's signal tends to become noisy. Furthermore, we find that the optimal distillation context depends jointly on the student model's capacity and the target task, and that no single universally effective configuration emerges. These findings motivate the use of per-task, per-token diagnostic analyses for distillation.
Your LLM Knows the Future: Uncovering Its Multi-Token Prediction Potential
Jul 16, 2025



Autoregressive language models are constrained by their inherently sequential nature, generating one token at a time. This paradigm limits inference speed and parallelism, especially during later stages of generation when the direction and semantics of text are relatively certain. In this work, we propose a novel framework that leverages the inherent knowledge of vanilla autoregressive language models about future tokens, combining techniques to realize this potential and enable simultaneous prediction of multiple subsequent tokens. Our approach introduces several key innovations: (1) a masked-input formulation where multiple future tokens are jointly predicted from a common prefix; (2) a gated LoRA formulation that preserves the original LLM's functionality, while equipping it for multi-token prediction; (3) a lightweight, learnable sampler module that generates coherent sequences from the predicted future tokens; (4) a set of auxiliary training losses, including a consistency loss, to enhance the coherence and accuracy of jointly generated tokens; and (5) a speculative generation strategy that expands tokens quadratically in the future while maintaining high fidelity. Our method achieves significant speedups through supervised fine-tuning on pretrained models. For example, it generates code and math nearly 5x faster, and improves general chat and knowledge tasks by almost 2.5x. These gains come without any loss in quality.
SeedLM: Compressing LLM Weights into Seeds of Pseudo-Random Generators
Oct 14, 2024



Large Language Models (LLMs) have transformed natural language processing, but face significant challenges in widespread deployment due to their high runtime cost. In this paper, we introduce SeedLM, a novel post-training compression method that uses seeds of pseudo-random generators to encode and compress model weights. Specifically, for each block of weights, we find a seed that is fed into a Linear Feedback Shift Register (LFSR) during inference to efficiently generate a random matrix. This matrix is then linearly combined with compressed coefficients to reconstruct the weight block. SeedLM reduces memory access and leverages idle compute cycles during inference, effectively speeding up memory-bound tasks by trading compute for fewer memory accesses. Unlike state-of-the-art compression methods that rely on calibration data, our approach is data-free and generalizes well across diverse tasks. Our experiments with Llama 3 70B, which is particularly challenging to compress, show that SeedLM achieves significantly better zero-shot accuracy retention at 4- and 3-bit than state-of-the-art techniques, while maintaining performance comparable to FP16 baselines. Additionally, FPGA-based tests demonstrate that 4-bit SeedLM, as model size increases to 70B, approaches a 4x speed-up over an FP16 Llama 2/3 baseline.
MultiPathGAN: Structure Preserving Stain Normalization using Unsupervised Multi-domain Adversarial Network with Perception Loss
Apr 20, 2022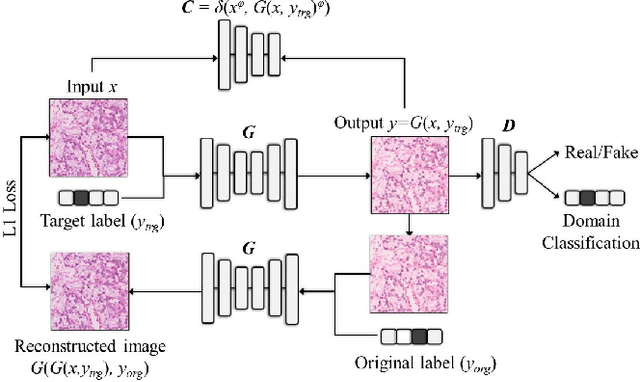
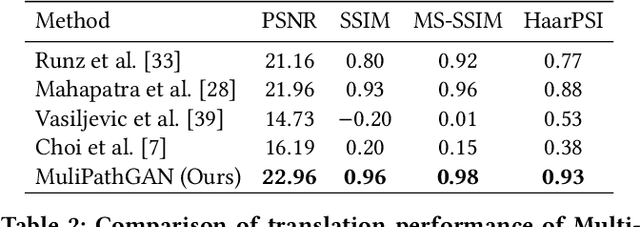
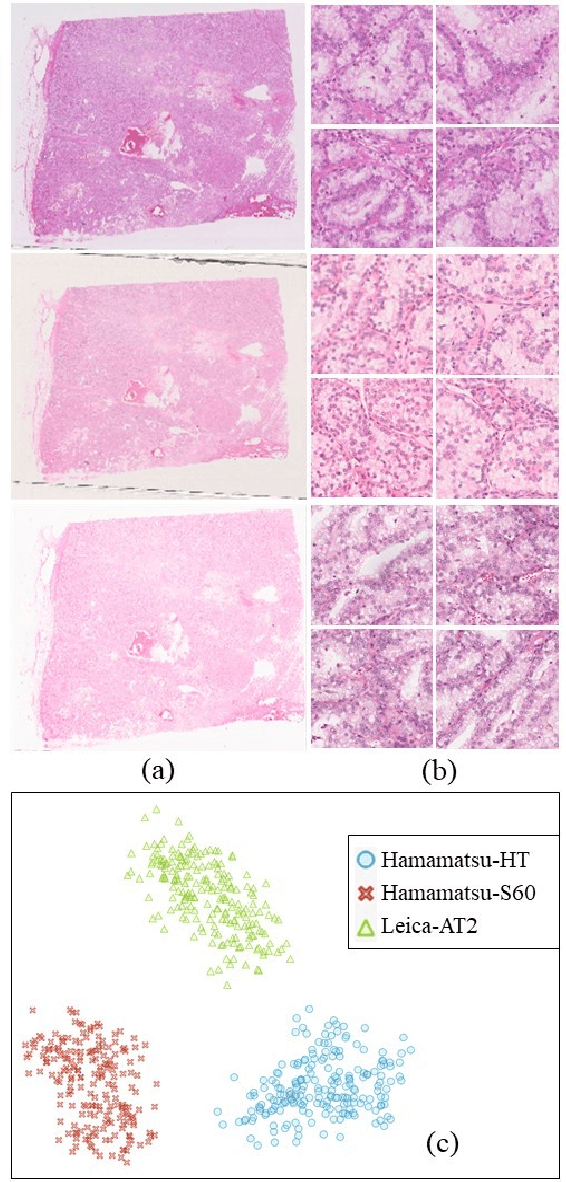
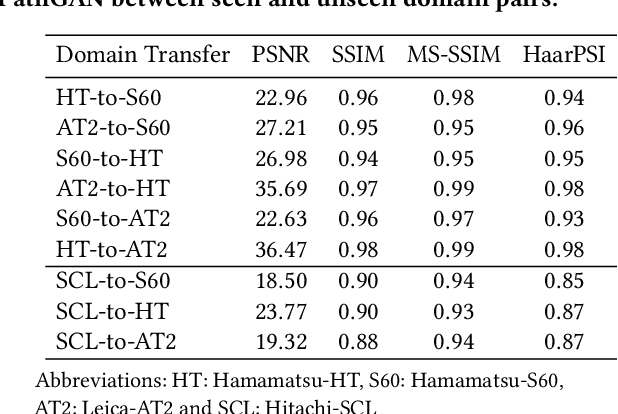
Histopathology relies on the analysis of microscopic tissue images to diagnose disease. A crucial part of tissue preparation is staining whereby a dye is used to make the salient tissue components more distinguishable. However, differences in laboratory protocols and scanning devices result in significant confounding appearance variation in the corresponding images. This variation increases both human error and the inter-rater variability, as well as hinders the performance of automatic or semi-automatic methods. In the present paper we introduce an unsupervised adversarial network to translate (and hence normalize) whole slide images across multiple data acquisition domains. Our key contributions are: (i) an adversarial architecture which learns across multiple domains with a single generator-discriminator network using an information flow branch which optimizes for perceptual loss, and (ii) the inclusion of an additional feature extraction network during training which guides the transformation network to keep all the structural features in the tissue image intact. We: (i) demonstrate the effectiveness of the proposed method firstly on H\&E slides of 120 cases of kidney cancer, as well as (ii) show the benefits of the approach on more general problems, such as flexible illumination based natural image enhancement and light source adaptation.
Believe The HiPe: Hierarchical Perturbation for Fast and Robust Explanation of Black Box Models
Feb 22, 2021
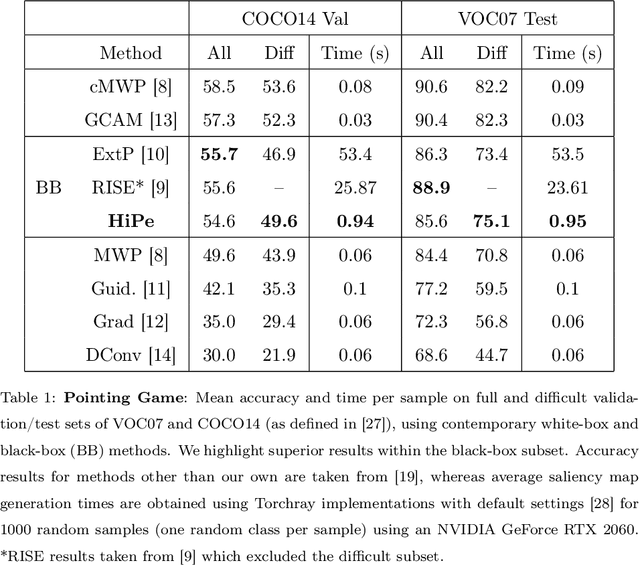
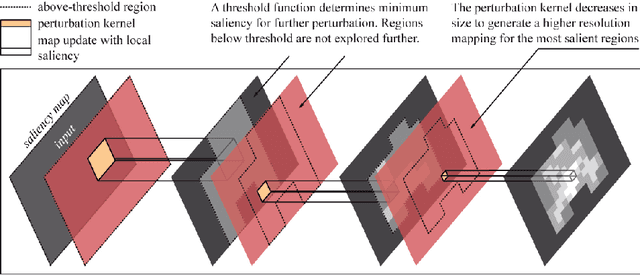
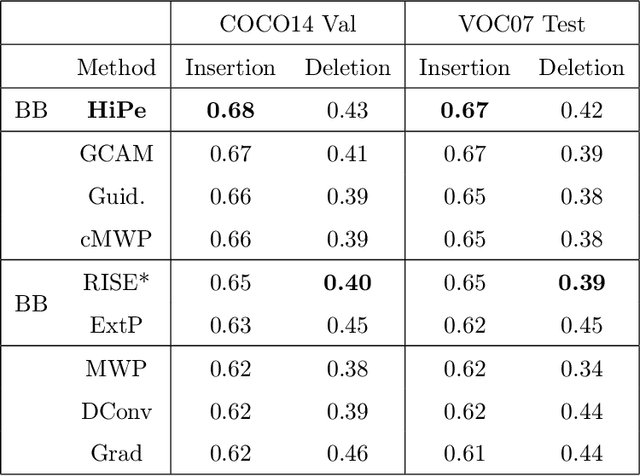
Understanding the predictions made by Artificial Intelligence (AI) systems is becoming more and more important as deep learning models are used for increasingly complex and high-stakes tasks. Saliency mapping - an easily interpretable visual attribution method - is one important tool for this, but existing formulations are limited by either computational cost or architectural constraints. We therefore propose Hierarchical Perturbation, a very fast and completely model-agnostic method for explaining model predictions with robust saliency maps. Using standard benchmarks and datasets, we show that our saliency maps are of competitive or superior quality to those generated by existing black-box methods - and are over 20x faster to compute.
Speech Recognition: Keyword Spotting Through Image Recognition
Mar 10, 2018
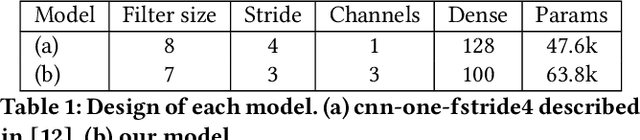
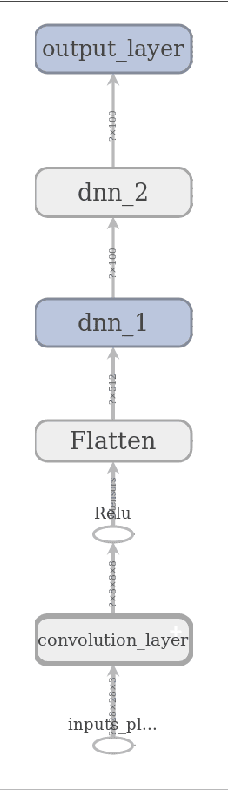
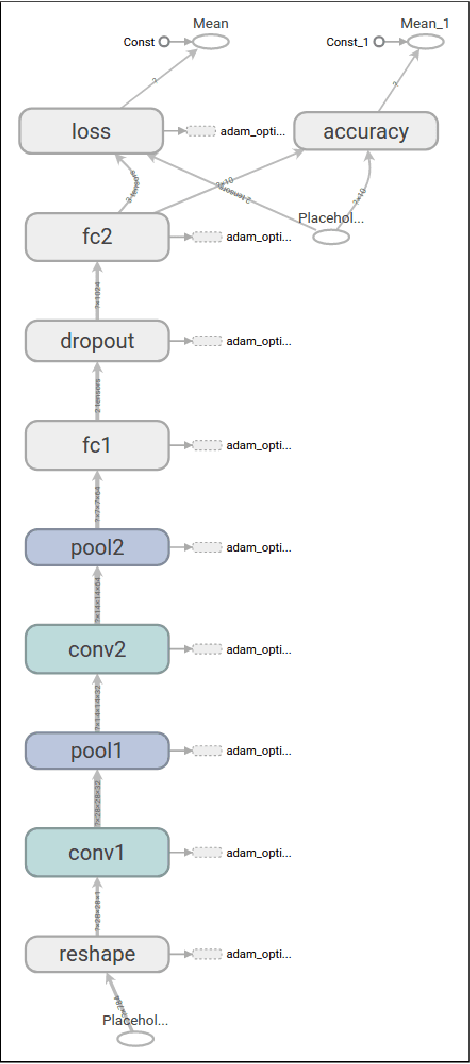
The problem of identifying voice commands has always been a challenge due to the presence of noise and variability in speed, pitch, etc. We will compare the efficacies of several neural network architectures for the speech recognition problem. In particular, we will build a model to determine whether a one second audio clip contains a particular word (out of a set of 10), an unknown word, or silence. The models to be implemented are a CNN recommended by the Tensorflow Speech Recognition tutorial, a low-latency CNN, and an adversarially trained CNN. The result is a demonstration of how to convert a problem in audio recognition to the better-studied domain of image classification, where the powerful techniques of convolutional neural networks are fully developed. Additionally, we demonstrate the applicability of the technique of Virtual Adversarial Training (VAT) to this problem domain, functioning as a powerful regularizer with promising potential future applications.