 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen and How Long? The Readout-Mediator Angle in Temporal Reasoning
May 27, 2026A linear probe can decode a representation almost perfectly and yet be completely irrelevant to how the model uses it. On calendar-date duration reasoning in language models, a $\sin$/$\cos$ probe recovers day-of-year from a layer's activations, yet ablating its direction has no effect on the model's answers -- while ablating a four-dimensional subspace found by Distributed Alignment Search (DAS) at the same layer collapses performance entirely. We measure the angle between these two subspaces -- the \emph{readout-mediator angle} -- and find it indistinguishable from the angle between two random subspaces (the Haar-uniform null), meaning the probe has learned a direction orthogonal to the model's actual computation. Reverse-engineering the circuit reveals why: attention heads route month-grained context through learned QK offsets at ${\pm}30$ and ${\pm}61$ days, and MLPs then convert \emph{when} (absolute date) into \emph{how long} (duration) -- all downstream of the causal subspace the probe never touches. Sparse-autoencoder decomposition confirms the split: probe-aligned and DAS-aligned features encode semantically disjoint concepts with negligible causal overlap. The dissociation replicates across four scales ($1.5$-$9\,$B) and two model families, with preliminary evidence on two further domains (spatial displacement, symbolic arithmetic), suggesting that readout-mediator orthogonality is a general failure mode of probe-based interpretability. This directly undermines proposals to deploy probes as runtime safety monitors: the probe can report high confidence on a direction the model has silently abandoned.
Beyond Consensus: Trace-Level Synthesis in Mixture of Agents
May 27, 2026When multiple LLM agents solve the same problem, standard practice compresses each agent's reasoning into a majority vote or layered synthesis, treating agreement as the finish line. We show this is unnecessarily lossy: an LLM aggregator that reads complete reasoning traces recovers correct solutions even when agents unanimously agree, with beneficial corrections consistently outweighing harmful ones -- the \emph{aggregation paradox}. Majority voting has a ceiling that perturbation diversity does not raise (error correlations are identical); the aggregator's gain comes from trace-level complementarity, assembling correct intermediate steps from minority chains that voting discards. These findings motivate Self-Consistent Mixture of Agents which generates trace diversity through semantic-preserving input perturbations, safeguards the majority via anchored refinement with provable non-degradation guarantees, and always synthesizes -- never gates on consensus. A single model with perturbation-induced trace variation outperforms heterogeneous model pools across structured reasoning, PhD-level science, competition mathematics, and competitive programming. The unit of aggregation should be the reasoning trace, not the answer.
Leverage-Weighted Conformal Prediction
Feb 13, 2026Split conformal prediction provides distribution-free prediction intervals with finite-sample marginal coverage, but produces constant-width intervals that overcover in low-variance regions and undercover in high-variance regions. Existing adaptive methods require training auxiliary models. We propose Leverage-Weighted Conformal Prediction (LWCP), which weights nonconformity scores by a function of the statistical leverage -- the diagonal of the hat matrix -- deriving adaptivity from the geometry of the design matrix rather than from auxiliary model fitting. We prove that LWCP preserves finite-sample marginal validity for any weight function; achieves asymptotically optimal conditional coverage at essentially no width cost when heteroscedasticity factors through leverage; and recovers the form and width of classical prediction intervals under Gaussian assumptions while retaining distribution-free guarantees. We further establish that randomized leverage approximations preserve coverage exactly with controlled width perturbation, and that vanilla CP suffers a persistent, sample-size-independent conditional coverage gap that LWCP eliminates. The method requires no hyperparameters beyond the choice of weight function and adds negligible computational overhead to vanilla CP. Experiments on synthetic and real data confirm the theoretical predictions, demonstrating substantial reductions in conditional coverage disparity across settings.
MEGAN: Mixture of Experts for Robust Uncertainty Estimation in Endoscopy Videos
Sep 16, 2025


Reliable uncertainty quantification (UQ) is essential in medical AI. Evidential Deep Learning (EDL) offers a computationally efficient way to quantify model uncertainty alongside predictions, unlike traditional methods such as Monte Carlo (MC) Dropout and Deep Ensembles (DE). However, all these methods often rely on a single expert's annotations as ground truth for model training, overlooking the inter-rater variability in healthcare. To address this issue, we propose MEGAN, a Multi-Expert Gating Network that aggregates uncertainty estimates and predictions from multiple AI experts via EDL models trained with diverse ground truths and modeling strategies. MEGAN's gating network optimally combines predictions and uncertainties from each EDL model, enhancing overall prediction confidence and calibration. We extensively benchmark MEGAN on endoscopy videos for Ulcerative colitis (UC) disease severity estimation, assessed by visual labeling of Mayo Endoscopic Subscore (MES), where inter-rater variability is prevalent. In large-scale prospective UC clinical trial, MEGAN achieved a 3.5% improvement in F1-score and a 30.5% reduction in Expected Calibration Error (ECE) compared to existing methods. Furthermore, MEGAN facilitated uncertainty-guided sample stratification, reducing the annotation burden and potentially increasing efficiency and consistency in UC trials.
Arges: Spatio-Temporal Transformer for Ulcerative Colitis Severity Assessment in Endoscopy Videos
Oct 01, 2024Accurate assessment of disease severity from endoscopy videos in ulcerative colitis (UC) is crucial for evaluating drug efficacy in clinical trials. Severity is often measured by the Mayo Endoscopic Subscore (MES) and Ulcerative Colitis Endoscopic Index of Severity (UCEIS) score. However, expert MES/UCEIS annotation is time-consuming and susceptible to inter-rater variability, factors addressable by automation. Automation attempts with frame-level labels face challenges in fully-supervised solutions due to the prevalence of video-level labels in clinical trials. CNN-based weakly-supervised models (WSL) with end-to-end (e2e) training lack generalization to new disease scores and ignore spatio-temporal information crucial for accurate scoring. To address these limitations, we propose "Arges", a deep learning framework that utilizes a transformer with positional encoding to incorporate spatio-temporal information from frame features to estimate disease severity scores in endoscopy video. Extracted features are derived from a foundation model (ArgesFM), pre-trained on a large diverse dataset from multiple clinical trials (61M frames, 3927 videos). We evaluate four UC disease severity scores, including MES and three UCEIS component scores. Test set evaluation indicates significant improvements, with F1 scores increasing by 4.1% for MES and 18.8%, 6.6%, 3.8% for the three UCEIS component scores compared to state-of-the-art methods. Prospective validation on previously unseen clinical trial data further demonstrates the model's successful generalization.
PainPoints: A Framework for Language-based Detection of Chronic Pain and Expert-Collaborative Text-Summarization
Sep 14, 2022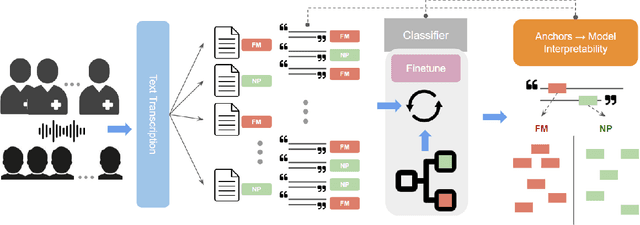

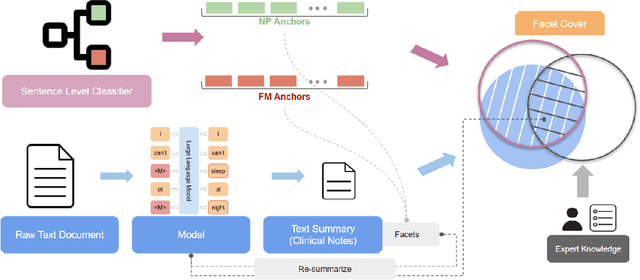
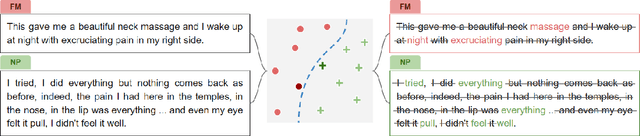
Chronic pain is a pervasive disorder which is often very disabling and is associated with comorbidities such as depression and anxiety. Neuropathic Pain (NP) is a common sub-type which is often caused due to nerve damage and has a known pathophysiology. Another common sub-type is Fibromyalgia (FM) which is described as musculoskeletal, diffuse pain that is widespread through the body. The pathophysiology of FM is poorly understood, making it very hard to diagnose. Standard medications and treatments for FM and NP differ from one another and if misdiagnosed it can cause an increase in symptom severity. To overcome this difficulty, we propose a novel framework, PainPoints, which accurately detects the sub-type of pain and generates clinical notes via summarizing the patient interviews. Specifically, PainPoints makes use of large language models to perform sentence-level classification of the text obtained from interviews of FM and NP patients with a reliable AUC of 0.83. Using a sufficiency-based interpretability approach, we explain how the fine-tuned model accurately picks up on the nuances that patients use to describe their pain. Finally, we generate summaries of these interviews via expert interventions by introducing a novel facet-based approach. PainPoints thus enables practitioners to add/drop facets and generate a custom summary based on the notion of "facet-coverage" which is also introduced in this work.
EVC-Net: Multi-scale V-Net with Conditional Random Fields for Brain Extraction
Jun 08, 2022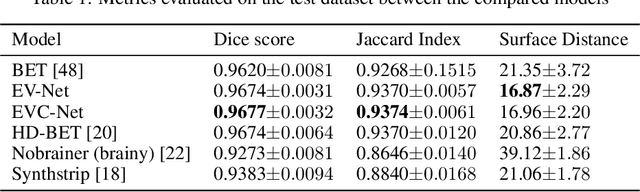

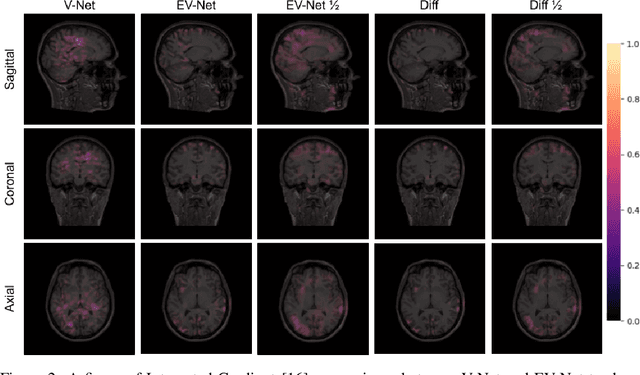

Brain extraction is one of the first steps of pre-processing 3D brain MRI data. It is a prerequisite for any forthcoming brain imaging analyses. However, it is not a simple segmentation problem due to the complex structure of the brain and human head. Although multiple solutions have been proposed in the literature, we are still far from having truly robust methods. While previous methods have used machine learning with structural/geometric priors, with the development of deep learning in computer vision tasks, there has been an increase in proposed convolutional neural network architectures for this semantic segmentation task. Yet, most models focus on improving the training data and loss functions with little change in the architecture. In this paper, we propose a novel architecture we call EVC-Net. EVC-Net adds lower scale inputs on each encoder block. This enhances the multi-scale scheme of the V-Net architecture, hence increasing the efficiency of the model. Conditional Random Fields, a popular approach for image segmentation before the deep learning era, are re-introduced here as an additional step for refining the network's output to capture fine-grained results in segmentation. We compare our model to state-of-the-art methods such as HD-BET, Synthstrip and brainy. Results show that even with limited training resources, EVC-Net achieves higher Dice Coefficient and Jaccard Index along with lower surface distance.
NUQ: A Noise Metric for Diffusion MRI via Uncertainty Discrepancy Quantification
Mar 04, 2022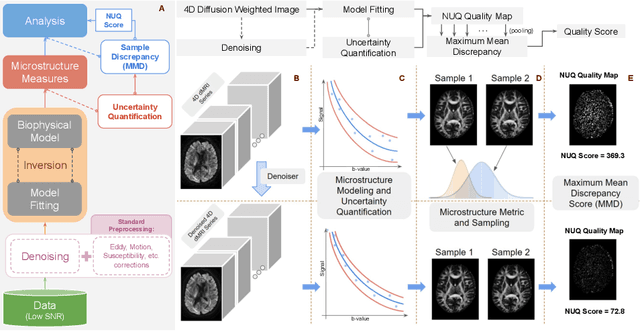
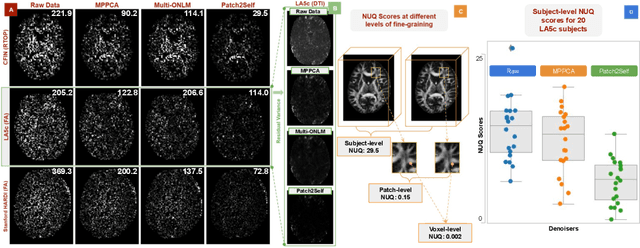
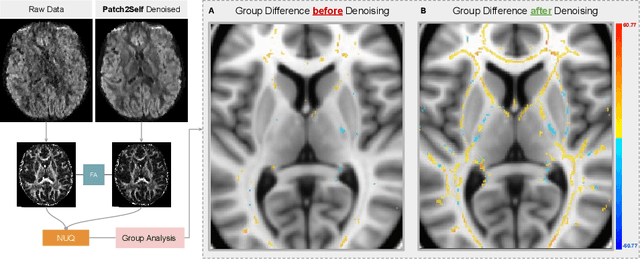
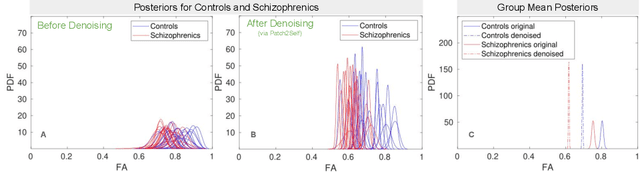
Diffusion MRI (dMRI) is the only non-invasive technique sensitive to tissue micro-architecture, which can, in turn, be used to reconstruct tissue microstructure and white matter pathways. The accuracy of such tasks is hampered by the low signal-to-noise ratio in dMRI. Today, the noise is characterized mainly by visual inspection of residual maps and estimated standard deviation. However, it is hard to estimate the impact of noise on downstream tasks based only on such qualitative assessments. To address this issue, we introduce a novel metric, Noise Uncertainty Quantification (NUQ), for quantitative image quality analysis in the absence of a ground truth reference image. NUQ uses a recent Bayesian formulation of dMRI models to estimate the uncertainty of microstructural measures. Specifically, NUQ uses the maximum mean discrepancy metric to compute a pooled quality score by comparing samples drawn from the posterior distribution of the microstructure measures. We show that NUQ allows a fine-grained analysis of noise, capturing details that are visually imperceptible. We perform qualitative and quantitative comparisons on real datasets, showing that NUQ generates consistent scores across different denoisers and acquisitions. Lastly, by using NUQ on a cohort of schizophrenics and controls, we quantify the substantial impact of denoising on group differences.
ThetA -- fast and robust clustering via a distance parameter
Mar 01, 2021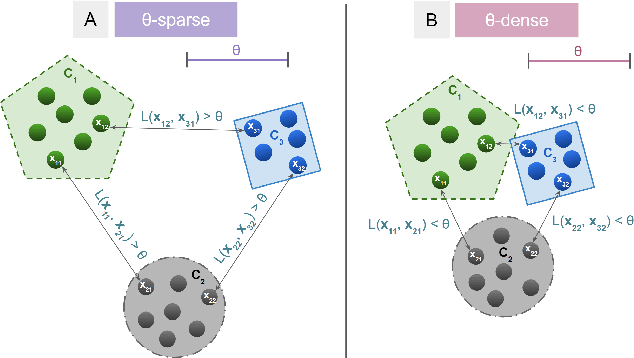
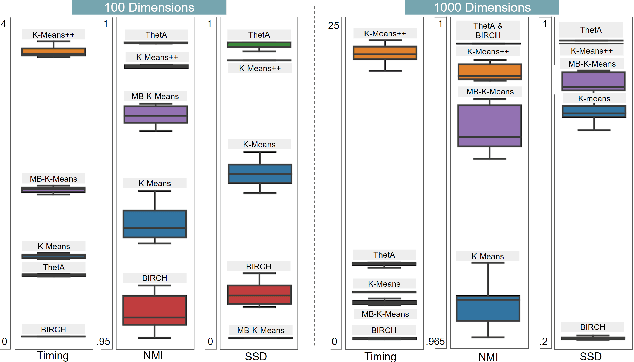
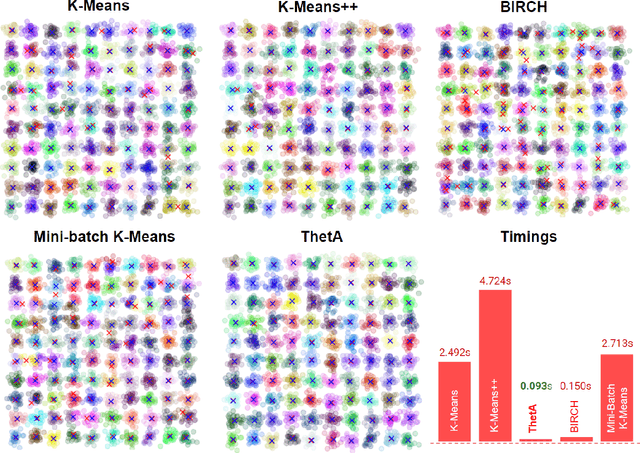
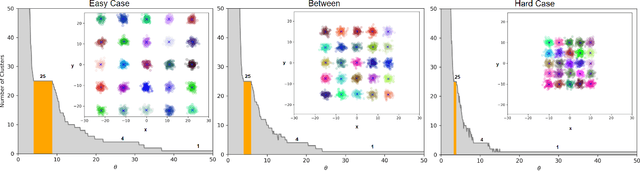
Clustering is a fundamental problem in machine learning where distance-based approaches have dominated the field for many decades. This set of problems is often tackled by partitioning the data into K clusters where the number of clusters is chosen apriori. While significant progress has been made on these lines over the years, it is well established that as the number of clusters or dimensions increase, current approaches dwell in local minima resulting in suboptimal solutions. In this work, we propose a new set of distance threshold methods called Theta-based Algorithms (ThetA). Via experimental comparisons and complexity analyses we show that our proposed approach outperforms existing approaches in: a) clustering accuracy and b) time complexity. Additionally, we show that for a large class of problems, learning the optimal threshold is straightforward in comparison to learning K. Moreover, we show how ThetA can infer the sparsity of datasets in higher dimensions.
Patch2Self: Denoising Diffusion MRI with Self-Supervised Learning
Nov 02, 2020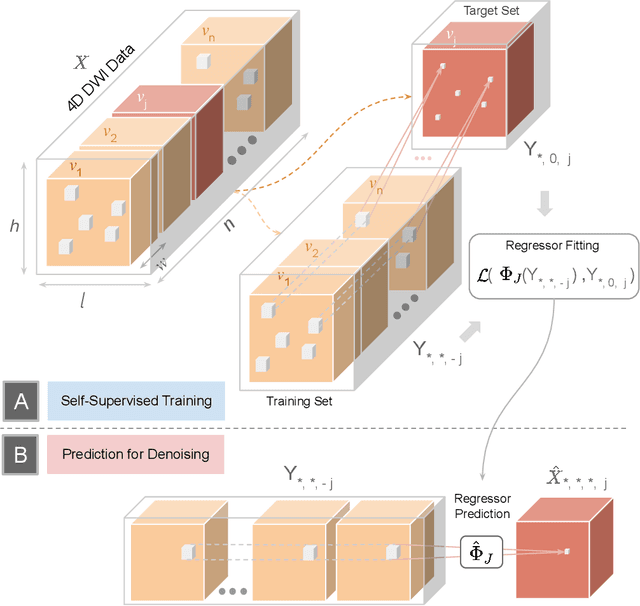
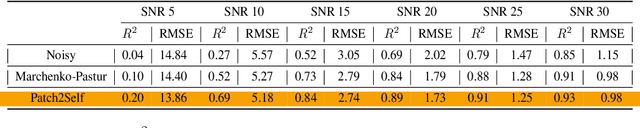
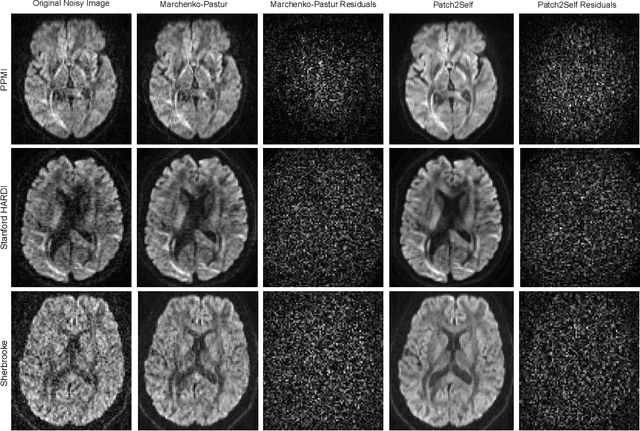
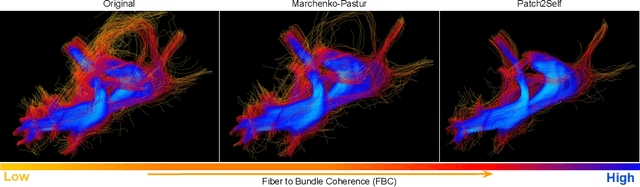
Diffusion-weighted magnetic resonance imaging (DWI) is the only noninvasive method for quantifying microstructure and reconstructing white-matter pathways in the living human brain. Fluctuations from multiple sources create significant additive noise in DWI data which must be suppressed before subsequent microstructure analysis. We introduce a self-supervised learning method for denoising DWI data, Patch2Self, which uses the entire volume to learn a full-rank locally linear denoiser for that volume. By taking advantage of the oversampled q-space of DWI data, Patch2Self can separate structure from noise without requiring an explicit model for either. We demonstrate the effectiveness of Patch2Self via quantitative and qualitative improvements in microstructure modeling, tracking (via fiber bundle coherency) and model estimation relative to other unsupervised methods on real and simulated data.