 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learned Image Compression with Discretized Gaussian-Laplacian-Logistic Mixture Model and Concatenated Residual Modules
Jul 18, 2021
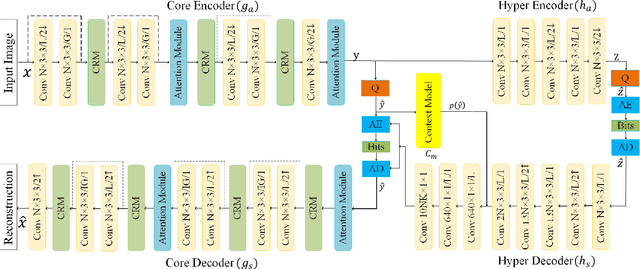
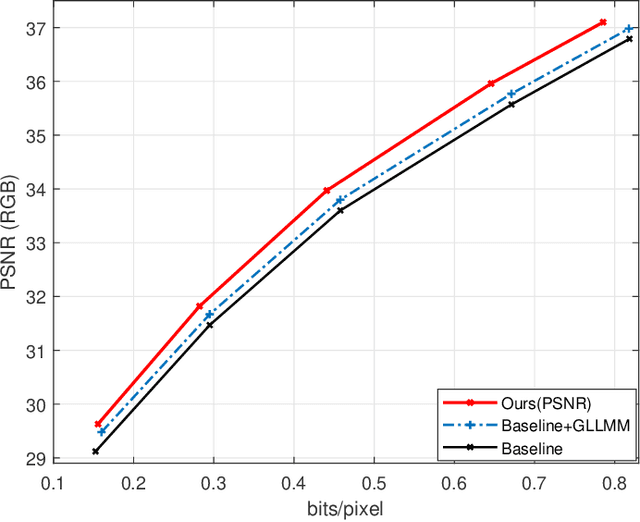
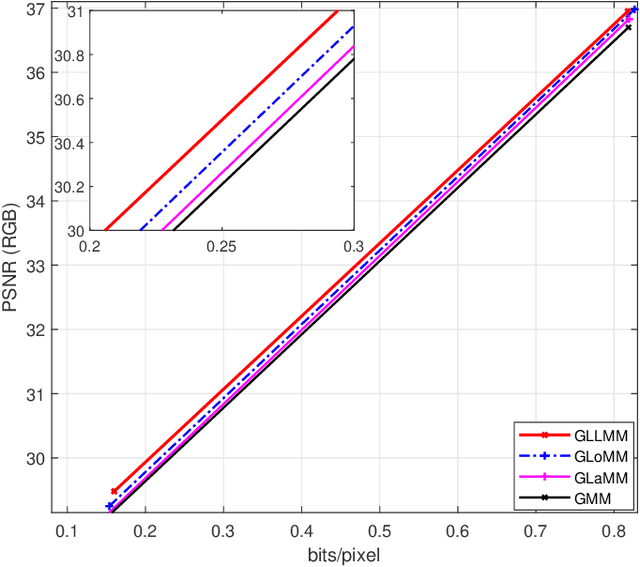
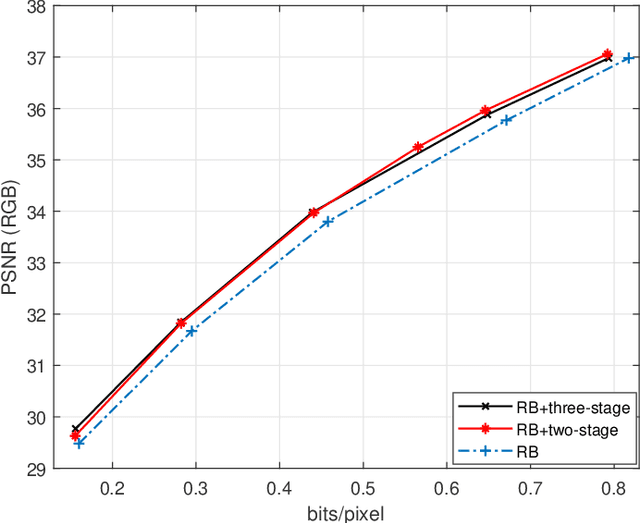
Recently deep learning-based image compression methods have achieved significant achievements and gradually outperformed traditional approaches including the latest standard Versatile Video Coding (VVC) in both PSNR and MS-SSIM metrics. Two key components of learned image compression frameworks are the entropy model of the latent representations and the encoding/decoding network architectures. Various models have been proposed, such as autoregressive, softmax, logistic mixture, Gaussian mixture, and Laplacian. Existing schemes only use one of these models. However, due to the vast diversity of images, it is not optimal to use one model for all images, even different regions of one image. In this paper, we propose a more flexible discretized Gaussian-Laplacian-Logistic mixture model (GLLMM) for the latent representations, which can adapt to different contents in different images and different regions of one image more accurately. Besides, in the encoding/decoding network design part, we propose a concatenated residual blocks (CRB), where multiple residual blocks are serially connected with additional shortcut connections. The CRB can improve the learning ability of the network, which can further improve the compression performance. Experimental results using the Kodak and Tecnick datasets show that the proposed scheme outperforms all the state-of-the-art learning-based methods and existing compression standards including VVC intra coding (4:4:4 and 4:2:0) in terms of the PSNR and MS-SSIM. The project page is at \url{https://github.com/fengyurenpingsheng/Learned-image-compression-with-GLLMM}
Online progressive instance-balanced sampling for weakly supervised object detection
Jun 21, 2022
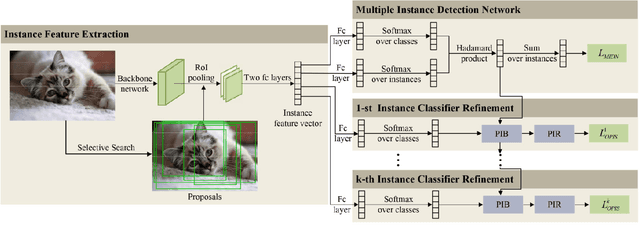
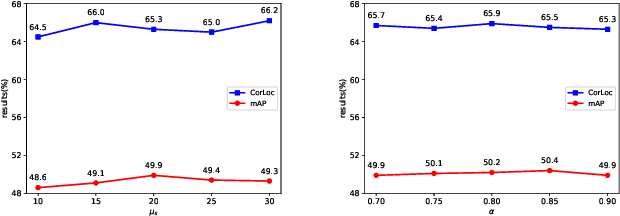
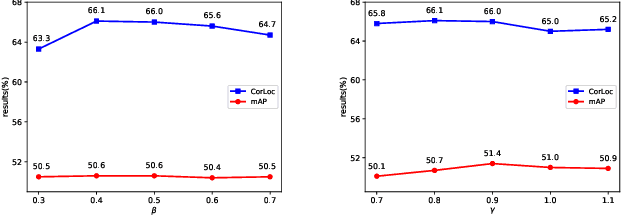
Based on multiple instance detection networks (MIDN), plenty of works have contributed tremendous efforts to weakly supervised object detection (WSOD). However, most methods neglect the fact that the overwhelming negative instances exist in each image during the training phase, which would mislead the training and make the network fall into local minima. To tackle this problem, an online progressive instance-balanced sampling (OPIS) algorithm based on hard sampling and soft sampling is proposed in this paper. The algorithm includes two modules: a progressive instance balance (PIB) module and a progressive instance reweighting (PIR) module. The PIB module combining random sampling and IoU-balanced sampling progressively mines hard negative instances while balancing positive instances and negative instances. The PIR module further utilizes classifier scores and IoUs of adjacent refinements to reweight the weights of positive instances for making the network focus on positive instances. Extensive experimental results on the PASCAL VOC 2007 and 2012 datasets demonstrate the proposed method can significantly improve the baseline, which is also comparable to many existing state-of-the-art results. In addition, compared to the baseline, the proposed method requires no extra network parameters and the supplementary training overheads are small, which could be easily integrated into other methods based on the instance classifier refinement paradigm.
PanFormer: a Transformer Based Model for Pan-sharpening
Mar 06, 2022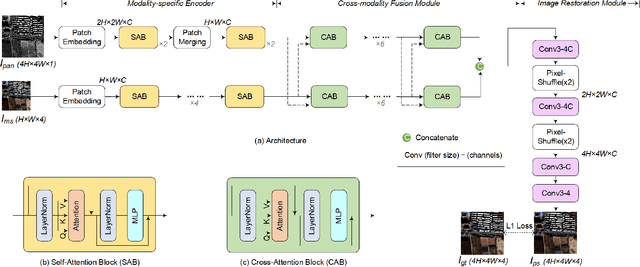
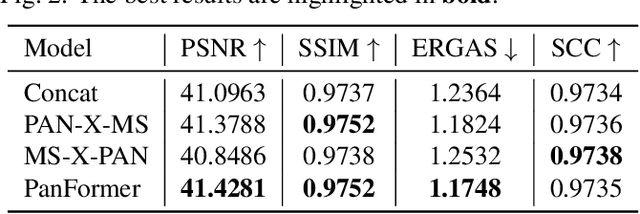
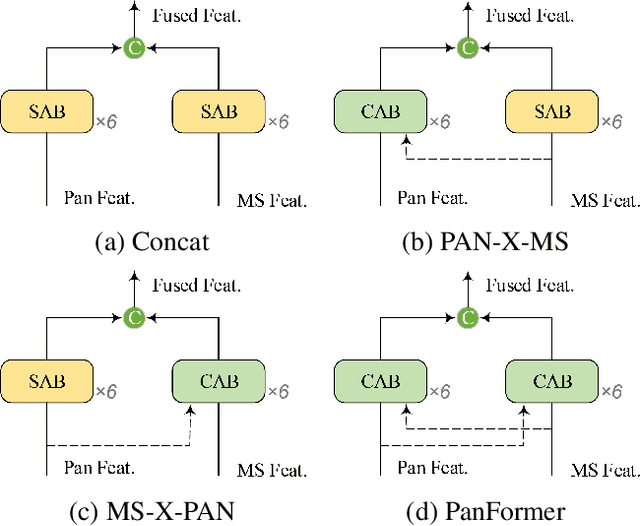
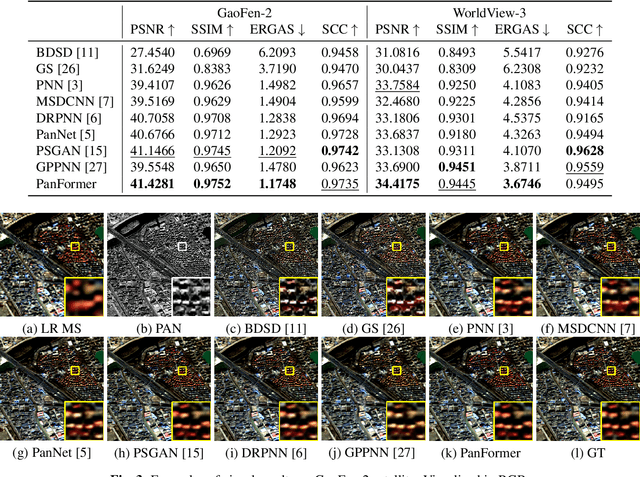
Pan-sharpening aims at producing a high-resolution (HR) multi-spectral (MS) image from a low-resolution (LR) multi-spectral (MS) image and its corresponding panchromatic (PAN) image acquired by a same satellite. Inspired by a new fashion in recent deep learning community, we propose a novel Transformer based model for pan-sharpening. We explore the potential of Transformer in image feature extraction and fusion. Following the successful development of vision transformers, we design a two-stream network with the self-attention to extract the modality-specific features from the PAN and MS modalities and apply a cross-attention module to merge the spectral and spatial features. The pan-sharpened image is produced from the enhanced fused features. Extensive experiments on GaoFen-2 and WorldView-3 images demonstrate that our Transformer based model achieves impressive results and outperforms many existing CNN based methods, which shows the great potential of introducing Transformer to the pan-sharpening task. Codes are available at https://github.com/zhysora/PanFormer.
Omni-Seg: A Single Dynamic Network for Multi-label Renal Pathology Image Segmentation using Partially Labeled Data
Dec 23, 2021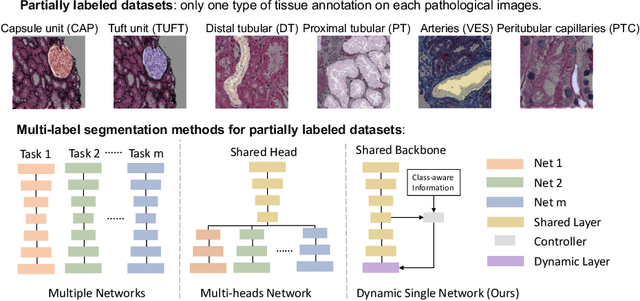
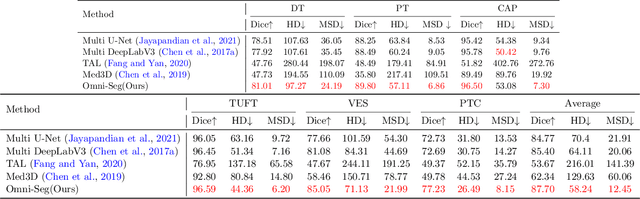
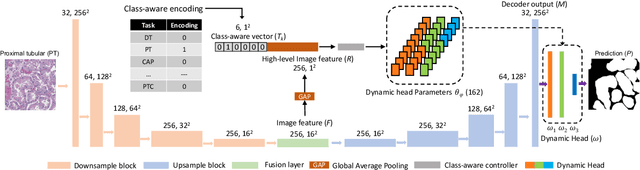
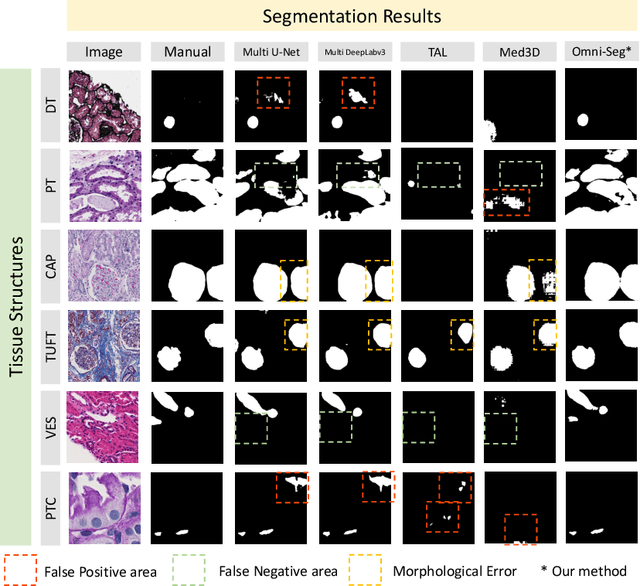
Computer-assisted quantitative analysis on Giga-pixel pathology images has provided a new avenue in precision medicine. The innovations have been largely focused on cancer pathology (i.e., tumor segmentation and characterization). In non-cancer pathology, the learning algorithms can be asked to examine more comprehensive tissue types simultaneously, as a multi-label setting. The prior arts typically needed to train multiple segmentation networks in order to match the domain-specific knowledge for heterogeneous tissue types (e.g., glomerular tuft, glomerular unit, proximal tubular, distal tubular, peritubular capillaries, and arteries). In this paper, we propose a dynamic single segmentation network (Omni-Seg) that learns to segment multiple tissue types using partially labeled images (i.e., only one tissue type is labeled for each training image) for renal pathology. By learning from ~150,000 patch-wise pathological images from six tissue types, the proposed Omni-Seg network achieved superior segmentation accuracy and less resource consumption when compared to the previous the multiple-network and multi-head design. In the testing stage, the proposed method obtains "completely labeled" tissue segmentation results using only "partially labeled" training images. The source code is available at https://github.com/ddrrnn123/Omni-Seg.
Self-supervised Low Light Image Enhancement and Denoising
Mar 01, 2021
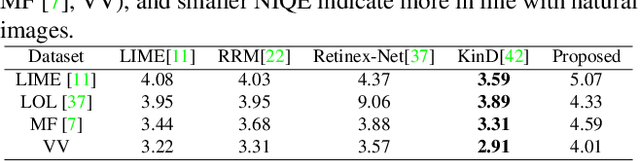
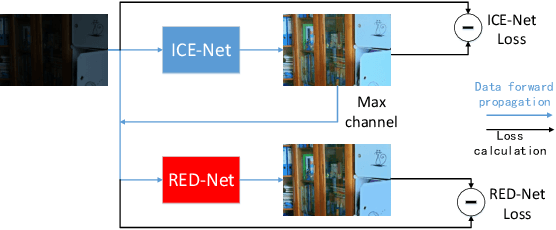
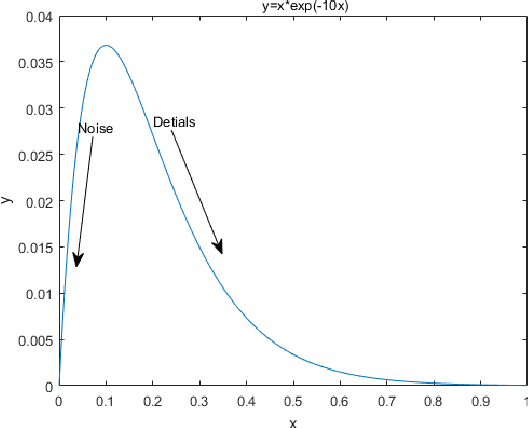
This paper proposes a self-supervised low light image enhancement method based on deep learning, which can improve the image contrast and reduce noise at the same time to avoid the blur caused by pre-/post-denoising. The method contains two deep sub-networks, an Image Contrast Enhancement Network (ICE-Net) and a Re-Enhancement and Denoising Network (RED-Net). The ICE-Net takes the low light image as input and produces a contrast enhanced image. The RED-Net takes the result of ICE-Net and the low light image as input, and can re-enhance the low light image and denoise at the same time. Both of the networks can be trained with low light images only, which is achieved by a Maximum Entropy based Retinex (ME-Retinex) model and an assumption that noises are independently distributed. In the ME-Retinex model, a new constraint on the reflectance image is introduced that the maximum channel of the reflectance image conforms to the maximum channel of the low light image and its entropy should be the largest, which converts the decomposition of reflectance and illumination in Retinex model to a non-ill-conditioned problem and allows the ICE-Net to be trained with a self-supervised way. The loss functions of RED-Net are carefully formulated to separate the noises and details during training, and they are based on the idea that, if noises are independently distributed, after the processing of smoothing filters (\eg mean filter), the gradient of the noise part should be smaller than the gradient of the detail part. It can be proved qualitatively and quantitatively through experiments that the proposed method is efficient.
Continuous Generative Neural Networks
May 29, 2022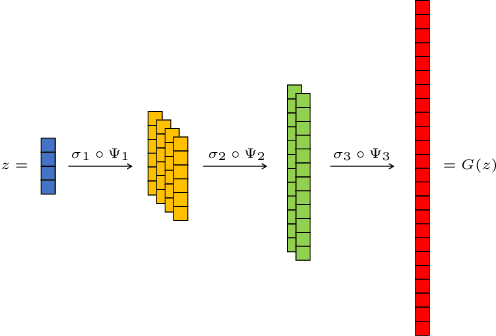
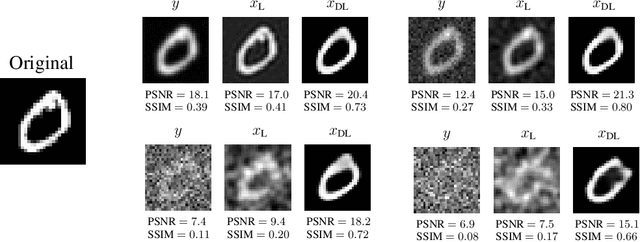
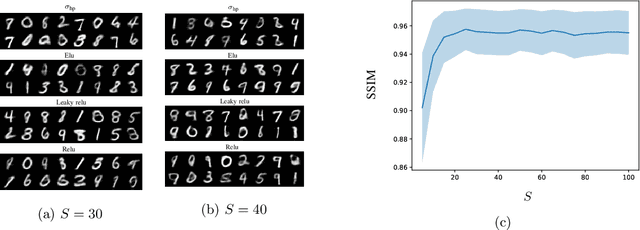
In this work, we present and study Continuous Generative Neural Networks (CGNNs), namely, generative models in the continuous setting. The architecture is inspired by DCGAN, with one fully connected layer, several convolutional layers and nonlinear activation functions. In the continuous $L^2$ setting, the dimensions of the spaces of each layer are replaced by the scales of a multiresolution analysis of a compactly supported wavelet. We present conditions on the convolutional filters and on the nonlinearity that guarantee that a CGNN is injective. This theory finds applications to inverse problems, and allows for deriving Lipschitz stability estimates for (possibly nonlinear) infinite-dimensional inverse problems with unknowns belonging to the manifold generated by a CGNN. Several numerical simulations, including image deblurring, illustrate and validate this approach.
A Survey: Deep Learning for Hyperspectral Image Classification with Few Labeled Samples
Dec 03, 2021

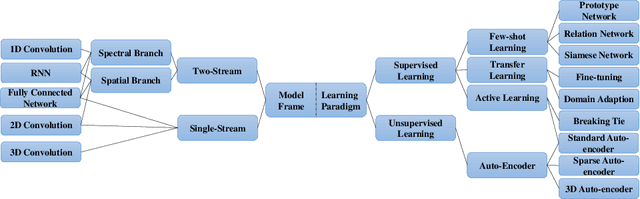
With the rapid development of deep learning technology and improvement in computing capability, deep learning has been widely used in the field of hyperspectral image (HSI) classification. In general, deep learning models often contain many trainable parameters and require a massive number of labeled samples to achieve optimal performance. However, in regard to HSI classification, a large number of labeled samples is generally difficult to acquire due to the difficulty and time-consuming nature of manual labeling. Therefore, many research works focus on building a deep learning model for HSI classification with few labeled samples. In this article, we concentrate on this topic and provide a systematic review of the relevant literature. Specifically, the contributions of this paper are twofold. First, the research progress of related methods is categorized according to the learning paradigm, including transfer learning, active learning and few-shot learning. Second, a number of experiments with various state-of-the-art approaches has been carried out, and the results are summarized to reveal the potential research directions. More importantly, it is notable that although there is a vast gap between deep learning models (that usually need sufficient labeled samples) and the HSI scenario with few labeled samples, the issues of small-sample sets can be well characterized by fusion of deep learning methods and related techniques, such as transfer learning and a lightweight model. For reproducibility, the source codes of the methods assessed in the paper can be found at https://github.com/ShuGuoJ/HSI-Classification.git.
Online panoptic 3D reconstruction as a Linear Assignment Problem
Apr 01, 2022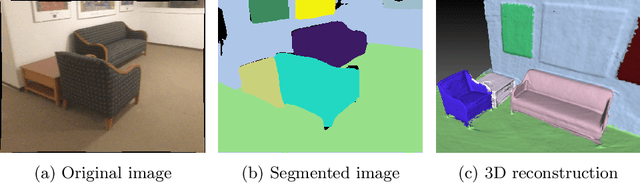
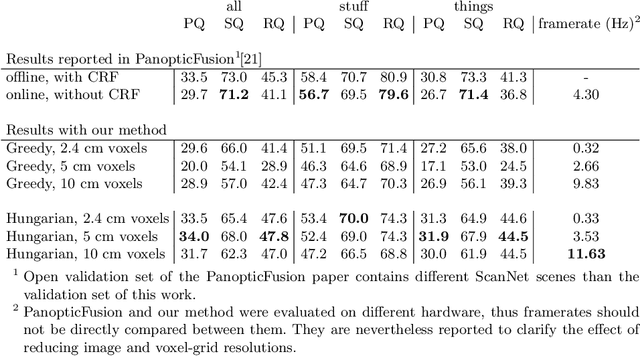

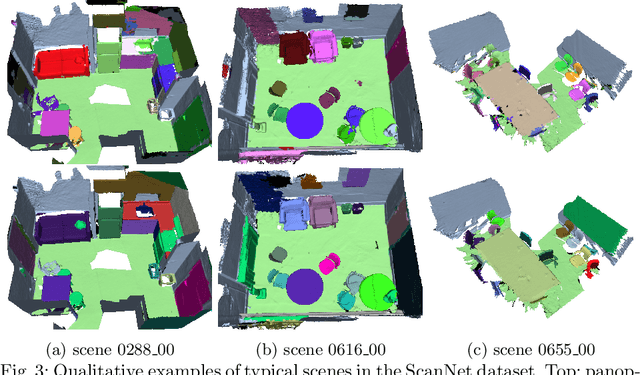
Real-time holistic scene understanding would allow machines to interpret their surrounding in a much more detailed manner than is currently possible. While panoptic image segmentation methods have brought image segmentation closer to this goal, this information has to be described relative to the 3D environment for the machine to be able to utilise it effectively. In this paper, we investigate methods for sequentially reconstructing static environments from panoptic image segmentations in 3D. We specifically target real-time operation: the algorithm must process data strictly online and be able to run at relatively fast frame rates. Additionally, the method should be scalable for environments large enough for practical applications. By applying a simple but powerful data-association algorithm, we outperform earlier similar works when operating purely online. Our method is also capable of reaching frame-rates high enough for real-time applications and is scalable to larger environments as well. Source code and further demonstrations are released to the public at: \url{https://tutvision.github.io/Online-Panoptic-3D/}
Adaptively Sparse Regularization for Blind Image Restoration
Jan 23, 2021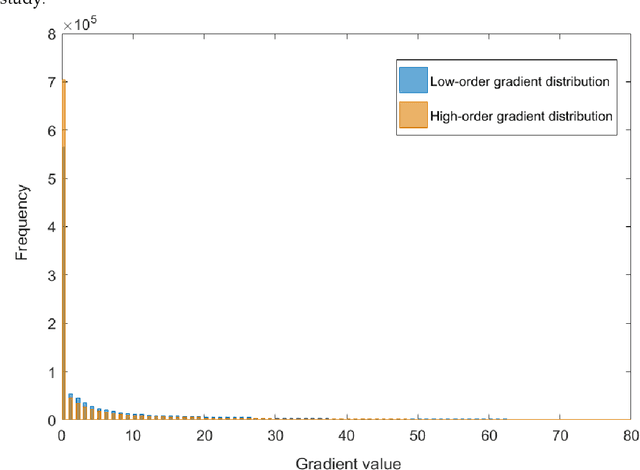
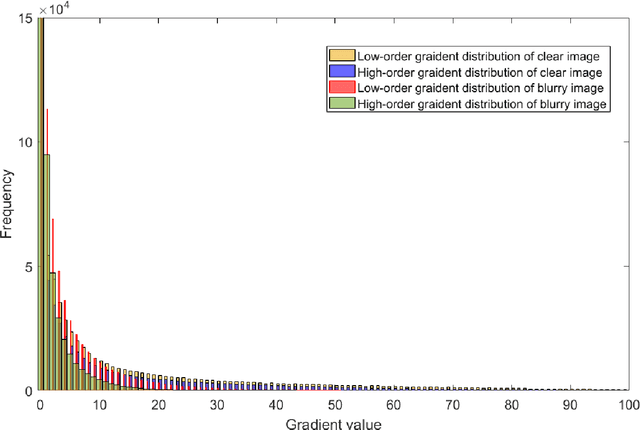

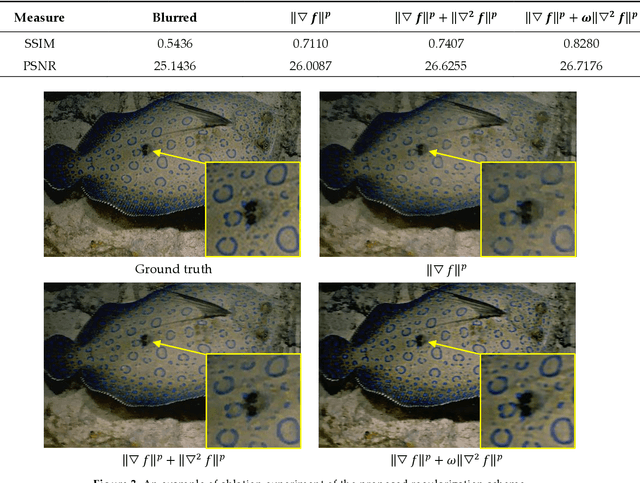
Image quality is the basis of image communication and understanding tasks. Due to the blur and noise effects caused by imaging, transmission and other processes, the image quality is degraded. Blind image restoration is widely used to improve image quality, where the main goal is to faithfully estimate the blur kernel and the latent sharp image. In this study, based on experimental observation and research, an adaptively sparse regularized minimization method is originally proposed. The high-order gradients combine with low-order ones to form a hybrid regularization term, and an adaptive operator derived from the image entropy is introduced to maintain a good convergence. Extensive experiments were conducted on different blur kernels and images. Compared with existing state-of-the-art blind deblurring methods, our method demonstrates superiority on the recovery accuracy.
Learning the Effect of Registration Hyperparameters with HyperMorph
Mar 30, 2022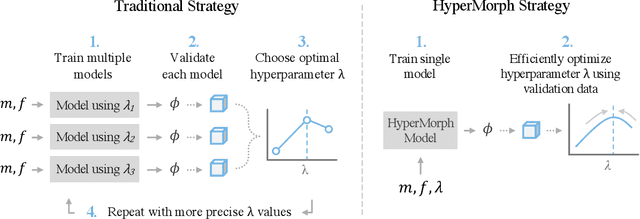
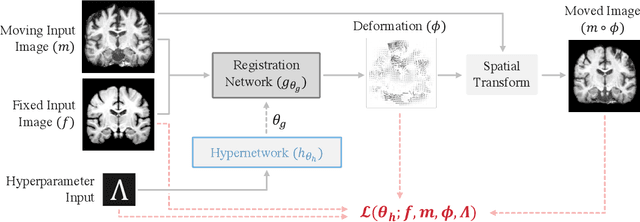

We introduce HyperMorph, a framework that facilitates efficient hyperparameter tuning in learning-based deformable image registration. Classical registration algorithms perform an iterative pair-wise optimization to compute a deformation field that aligns two images. Recent learning-based approaches leverage large image datasets to learn a function that rapidly estimates a deformation for a given image pair. In both strategies, the accuracy of the resulting spatial correspondences is strongly influenced by the choice of certain hyperparameter values. However, an effective hyperparameter search consumes substantial time and human effort as it often involves training multiple models for different fixed hyperparameter values and may lead to suboptimal registration. We propose an amortized hyperparameter learning strategy to alleviate this burden by learning the impact of hyperparameters on deformation fields. We design a meta network, or hypernetwork, that predicts the parameters of a registration network for input hyperparameters, thereby comprising a single model that generates the optimal deformation field corresponding to given hyperparameter values. This strategy enables fast, high-resolution hyperparameter search at test-time, reducing the inefficiency of traditional approaches while increasing flexibility. We also demonstrate additional benefits of HyperMorph, including enhanced robustness to model initialization and the ability to rapidly identify optimal hyperparameter values specific to a dataset, image contrast, task, or even anatomical region, all without the need to retrain models. We make our code publicly available at http://hypermorph.voxelmorph.net.